はじめに
ECSで起動しているタスク内のメインアプリコンテナのGracefulShutdownを実装したのですが、実現に苦労をしたので共有します。
今回はどのような仕組みを実現したのかと、考え方について記述していきます。
GracefulShutdownとは?
アプリを突然落とさずに安全に停止する仕組み。
アプリが急に落ちてしまうとユーザにエラーが返ってしまったり、処理中のデータが消えてしまうというトラブルが起きやすいため、保持している処理を終了させてから停止しよう、という考え方です。
ECSタスク停止の流れ

ECSのタスク停止は以下の流れで進みます。
①タスクスケールイン or 必須コンテナ停止
タスクのスケールインや、必須コンテナ(タスク定義でessential:trueのコンテナ)が停止するなどのイベントによりタスクの停止が始まる。
②タスク内コンテナ全体にSIGTERM
タスクが停止を始めると、ECSからコンテナにSIGTERMが送られる。
GracefulShutdownの観点で見ると、第1プロセス(PID1)のアプリプロセスにSIGTERMが渡ると即座にコンテナが落ちてしまうので、SIGTERMをハンドリング(後述)して、SIGTERMが渡されてもすぐに落ちないようにする必要がある。
③タスク内コンテナ全体にSIGKILL
タスク定義のstopTimeoutパラメータで設定した秒数が経過すると、ECSからSIGKILLが送られる。その時点にタスク内で動いているすべてのコンテナが強制停止する。
💡用語
SIGTERM : ECSが送る、コンテナを安全に終了してねというシグナル。コンテナが受け取ると終了処理が始まる。
SIGKILL : ECSが送る、強制終了シグナル。これを受け取ると生きているコンテナはどのような状態でも即座に停止する。
SIGTERMハンドリングとは?
コンテナは第1プロセス(PID1)= 本体として動作するため、そのプロセスが落ちるとコンテナが停止します。
また、前述のように、特別な処理を実装していなければ基本的にSIGTERMがアプリプロセスに渡されると即座にアプリプロセスは落ちてしまいます。
そして、アプリを動かすコンテナではアプリプロセスがPID1であることが多いです。
そのため、SIGTERMがアプリプロセス(PID1)に渡されるとアプリプロセスが落ちる=コンテナが即座に停止ということになります。
このSIGTERM を受け取り、処理の終了タイミングを制御する仕組みが、SIGTERMハンドリングの考え方です。
実装方法は調べてみるといろいろあるのですが、以下でAWS公式がサンプルコードを出しているので参考になります。
今回のケース
今回実際に発生した構成と課題を整理します。
大きなニーズは以下の2点です。
①SIGTERMを受けてからSIGKILLでコンテナが強制終了してしまうまでの間できるだけコンテナを生かしたい。
②SIGTERMを受けたあとは新規リクエストを受け付けないようにしたい。
- ALB→ECSの構成
- 同じタスクの中でメインのアプリコンテナと、アプリコンテナをサポートする機能を持つサイドカーコンテナを起動している。(すべて
essential:trueの必須コンテナ) - サイドカーコンテナが落ちた際にタスク全体にSIGTERMが渡されると、メインのアプリコンテナも即座に落ちてしまう。(ので、SIGTERMハンドリングが必要。)
- 急にアプリが落ちてしまうと、アプリのユーザからのリクエストでエラーを返してしまう/処理中のデータが消えてしまう可能性があるので、できるだけ処理を終了させてからコンテナを落としたい。
- (追加要件として)SIGTERMを受けた後に新しいリクエストを受け付けてしまうと、コンテナが落ちるまでに処理しきれなくなってしまうので、できるだけ早くALBからECSを外して新規リクエストを受け付けないようにしたい。

実現方針
上記2つのニーズをどのように満たしたかを説明します。
SIGTERMハンドリング(上記ニーズ①に対応)
SIGTERMハンドリングの記述を追加した起動時スクリプトを第1プロセスとしてコンテナを起動しました。
起動時スクリプトの流れ:
①SIGTERMを受ける
②設定した一定時間待機
③SIGKILLが渡される直前にアプリプロセスにSIGTERMを渡す
アプリは同じく起動時スクリプトの中で別プロセスとして起動しているため、コンテナがSIGTERMを受けてもアプリプロセスには渡らず、アプリは落ちないという仕組みになっています。
ALBのdrain制御(上記ニーズ②に対応)
ALBはヘルスチェックに失敗するとターゲットにリクエストを送らないようになります。
そのため、以下のようにJavaのプラグインを実装し、SIGTERMを受けてからできるだけ早くALBのヘルスチェックを失敗(Unhealthy)にさせ、リクエストを受付停止するようにしました。
流れ:
①SIGTERMを受けると、起動時スクリプトがフラグファイル①を作成
②フラグファイル①を検知し、ヘルスチェックパスのリクエストを503で返す。
③ヘルスチェックパスリクエストが閾値に達するとヘルスチェック失敗→フラグファイル②を作成
③全リクエストに503で返す(ALBからリクエストは来ないが念のための実装)
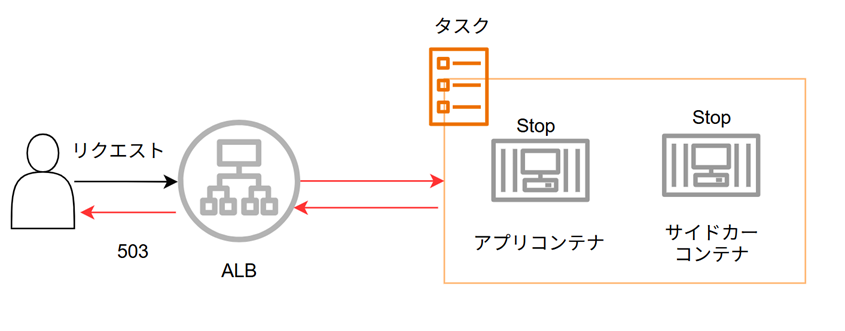
GracefulShutdownの流れ
上記を実装したGracefulShutdownの流れは以下になります。
①アプリコンテナがSIGTERMを受ける

②ALBでUnhealthyになるまでヘルスチェックパスのリクエストだけ503を返す

③ 全APIに対して503を返す(新規リクエスト受付完全停止)

④ 最大120秒待ってコンテナ終了
まとめ
- ECS では、タスク停止時にコンテナの PID1 に SIGTERM → SIGKILL が送られる
- アプリコンテナ・サイドカーを含むタスク構成でのGracefulShutdownを実装
- 本記事では、
- SIGTERM ハンドリングによるアプリ停止タイミングの制御
- ALB のヘルスチェックを利用した新規リクエスト遮断
の2点を組み合わせることでGracefulShutdownを実現
起動時スクリプトや、ALBのヘルスチェック制御のためのプラグイン実装の中身に関しては、長くなってしまったので別の記事として紹介できればと思います!