new-masaです。
前半の投稿では、私が社会人の学び直しでプログラミングを学ぶことにした経緯を記しましたが、後半では、お世話になったプログラミングスクールの最終到達目標である「AIアプリ」の制作について、苦労した点や、自分なりに工夫してみた点、学び直しを通して得られたものなどをご紹介させてください。
目次
前編/経緯編
後編/技術編
実行環境の紹介
データ前処理
データ水増し
ディープラーニングによる機械学習モデルの作成
機械学習モデルの精度向上
転移学習という技術
ついに機械学習モデル完成
未経験者の私が苦労したこと
学び直しで得られたこと
学び終えてこれから
実行環境の紹介
以下は、今回私がAIアプリを作成した実行環境の情報を記述しておきます。
これらについても、ひとつひとつが初めて触れるサービスやシステムでしたので、都度講師の方に教えていただきながら、度重なるエラー表示を乗り越え完成に辿り着きました。
・AIモデル作成:
python-3.8.14
Google Colaboratory
・機械学習用画像の入手先:
Kaggle
・HTML/CSS作成(ネット公開用のビジュアル作成):
Visual Studio Code
・ネット公開(アプリ公開先のクラウドプラットフォーム):
Heroku
データ前処理
では、いざAIアプリの制作を始めます!
まずは学習にも使用する「画像データの収集」です。
今回は、Kaggleという機械学習用の画像を提供しているサイトから、犬・猫の画像がセットになったデータをダウンロードしました。これをローカル環境から機械学習を行うGoogle環境上にアップロード。機械学習では、学習に使うトレーニングデータ(trainデータ)と、学習させたモデルの精度を確認するために使うテストデータ(testデータ)を準備する必要があるのですが、Kaggleでは、これがセットになった画像データが提供されており、今回はそれを活用させていただくことにしました。
受講生の中には、この画像の収集から自身で行った強者もおられるようで驚きました。ただ、今後の活用シーンをイメージする限り、必要なデータは、一般に公開されているようなものだけでなく、むしろ企業であれば、自社内に蓄積されたデータを活用するようなシーンが多いと想像できるため、今回は「時短」で対応した「データの前処理」に関しても、本当はもっと大変なようです。ちなみに、機械学習において、データの前処理には時間がかかるものだというのが当たり前だそうで、全体の7割以上の時間・労力が、この「データの前処理」に費やされると言われているそうです。
データ水増し
今回、データの前処理のうち、どうしても自分自身でチャレンジしておきたくてやってみたのが「データ水増し」でした。私のような人間だと、「水増し」と聞くと、不正に絡むようなネガティブな印象しか湧いてきませんが、機械学習の世界で行われる「水増し」というのは、決してネガティブな言葉ではなく、少ないデータ量からでも、機械学習を成立させるための、ひとつの手法ということなんですね。今回、Kaggleからダウンロードした画像セットのtrainデータは約2.5万枚でしたので、これを白黒にしてみたり、反転させてみたりと、1つの画像から複数枚の画像を生成するという事に挑戦。
これが、人生で初めて自分で書いたプログラムでしたが、実行してみると…エラーで全然動かない!!講座の中で学んだ内容を活かしながらではあったものの、当然応用しなければならず、自分自身の理解不足も痛感しながら進めることに。
結局、画像の水増しのコードの修正を、講師の方々の助けを受けながら、エラー箇所を見つけては修正を繰り返し、ようやくエラーなく実行できるようになったころには、画像の水増しだけで4日もかかってしまった…。ただエラーなく実行結果が返ってきた時は、本当に嬉しかった!!
ちなみに、何日もかけて画像水増しができたのですが、本来はAIモデルを構築するプログラムの中で水増しも同時に行うような形になるようで、実はここでかけた労力は「学び」以外においては、少し無駄な作業になってしまいました…。全体の流れが掴めていないと、そんなことも発生するのですね。(画像水増しのコードの紹介は後ほど)
ディープラーニングによる機械学習モデルの作成
データの前処理も済み、いよいよ一番大事なAIモデルの作成に突入です。ここでも講座で学んだコードを活かしながら、モデルのプログラムをコーディングしていきました。当然ですが、ここでも実行エラーとの戦いの連続です(涙)
また、今回はディープラーニングの「教師あり学習」という手法でAIモデルを作成することにしたので、学習用に準備したトレーニングデータ(trainデータ)、これは「教師データ」とも呼ばれるのですが、この教師データに対して、画像ごとに正解のラベル(この画像は「いぬ」です、「ねこ」ですというラベル付け)が必要となり、そのラベル付けの概念がいまいち腑に落ちず、苦労することになりました。Kaggleからダウンロードした教師データには、画像ごとに「dog」や「cat」がご丁寧にファイル名に入っているものの、これ自体がラベルではないのです。
今回はファイル名にいぬ・ねこを識別できる情報が入っていたので、それを活用しながら進める方法をアドバイスしてもらい前進しましたが、これが画像ファイルに「dog」「cat」記載がなければ、識別する方法を見つけ出すか、最後は力技で時間をかけてやる必要があり、あらためて前処理の大変さを痛感しました。
そして完成させてコードが以下のものです。
import os
import re
import pandas as pd
import numpy as np
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input, Conv2D, MaxPooling2D, Activation
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
path = '/content/drive/MyDrive/dogs-vs-cats/train/'
# trainフォルダに入っているファイル名のリストを取得
file_path = os.listdir(path)
print(file_path)
# 犬のファイル名と猫のファイル名を入れる空のリストを準備
path_dog=[]
path_cat=[]
# ファイル名のリストからファイル名を一つ一つ取り出す
for file in file_path:
if re.search('dog', file):
# ファイル名に'dog'と書かれているファイル名をpath_dogリストに追加
path_dog.append(file)
else:
# 'dog'と書かれていないファイル名をpath_catリストに追加
path_cat.append(file)
# 犬の画像データと猫の画像データを入れる空のリストを準備
img_dog=[]
img_cat=[]
for i in range(len(path_dog)):
#画像の読み込み
img=cv2.imread(path+path_dog[i])
#画像のリサイズ
img=cv2.resize(img,(50,50))
#画像の追加
img_dog.append(img)
for i in range(len(path_cat)):
#画像の読み込み
img=cv2.imread(path+path_cat[i])
#画像のリサイズ
img=cv2.resize(img,(50,50))
#画像の追加
img_cat.append(img)
#犬・猫の画像をnumpy配列にひとまとめにし、教師ラベルを作成
X=np.array(img_dog+img_cat)
y=np.array([0]*len(img_dog)+[1]*len(img_cat))
# 画像の正規化(値の範囲を0-255から0-1に変換)
X = X / 255.
# 学習用と検証用に分割する
rand_index=np.random.permutation(np.arange(len(X)))
X=X[rand_index]
y=y[rand_index]
#データの分割(訓練データ6割、検証(バリデーション)データ4割)
X_train=X[:int(len(X)*0.6)]
y_train=y[:int(len(y)*0.6)]
X_test=X[int(len(X)*0.6):]
y_test=y[int(len(y)*0.6):]
#正解クラスをone-hotにして出力するための設定
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
#モデルの定義
model=Sequential()
model.add(Conv2D(input_shape=(50,50,3),filters=16,kernel_size=(2,2),strides=(1,1),padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=16, kernel_size=(2, 2), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(2))
model.add(Activation('softmax'))
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4,momentum=0.9),metrics=['accuracy'])
#学習の実行
model.fit(X_train,y_train,batch_size=32,epochs=10)
#精度の評価
scores=model.evaluate(X_test,y_test,verbose=1)
print('Test loss:',scores[0])
print('Test accuracy:',scores[1])
model.summary()
機械学習モデルの精度向上
完成したAIモデルでいざ機械学習を実行。
初めてエラーなく実行が完了し、結果が表示された時は本当に嬉しかったですね。
完成したAIモデルの最初に設定した学習の条件だと、Test accuracy(モデルに対する検証データでの正解率)は「66.4%(0.664…)」。Test loss(損失関数)は「61.2%(0.612…)」。このTest lossは私には難しい概念で、まだまだ正確な理解は追い付いていないですが、学び過ぎて(過学習)、トレーニングデータでは高い正解率を出せるのに、テストデータでは応用が利かず、正解率が上がらなくなる現象を掴むための指標だそうです。問題集をひたすら説いて、答えを覚えるくらいになっても、少し視点の違う形で問題を出されたら、途端に間違ってしまうような、そんな感じでしょうかね。
実際に、このモデルで未知の画像(機械学習で使用していない、いぬ・ねこの画像)を判定させたところ、6枚正解で、4枚不正解の結果に。ほぼTest accuracy通りの結果になることに驚き!!
今回、限られた時間の中でのAIアプリ作成であったため、講師と相談し「80%のTest accuracyをめざそう」ということになり、ここから学習の条件を色々変えて、どのようなTest accuracy、Test lossの変化が起こるのか確認していくことに。今回の学び直しの期間中、ここが一番私にとっては面白かったですね。学習自体はコンピュータが行うので、私たちが操作できるのは、どのような学習の方法をとるか指示するこのプログラムのコーディングの部分なので、時間をかけて「実験」。(後でこの色々試した姿勢を、講師の方からとても褒めていただいたというか喜んでいただきました)
操作したのは、そもそもの学習させる画像の数。今回は画像水増しの学んだ内容を使って、倍の5万枚にしてみることに。他にはトレーニングデータとテストデータの割合を変えたり、ニューラルネットワークモデルの構成を少し変えてみたり(filters、kernel_size)、学習の回数(epochs)を変えたりしてみました。まだまだ操作できる方法はあるのですが、私の頭が追い付かなくなってしまうため、今回は絞って検証。
画像の水増しは、画像の読み込みを行ったあと、「犬・猫の画像をnumpy配列にひとまとめにし、教師ラベルを作成」する前の段階で、以下の様に追加しました。
# データクレンジングの水増しコード
def scratch_image(img, flip=True, thr=False, filt=False, resize=False, erode=False):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# 画像のサイズを習得、収縮処理に使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
#画像の左右反転のlambda関数を書いてください
lambda x: cv2.flip(x, 1),
#閾値処理のlambda関数を書いてください
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
#ぼかしのlambda関数を書いてください
lambda x: cv2.GaussianBlur(x, (5,5), 0),
#モザイク処理のlambda関数を書いてください
lambda x: cv2.resize(cv2.resize(x, (x.shape[1]//5, x.shape[0]//5)),(x.shape[1], x.shape[0])),
#収縮するlambda関数を書いてください
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# 犬の画像の水増し
# 水増し画像を保存する空のリストを用意
scratch_dog_images = []
for im in img_dog:
# flipのみ実施してみる
tmp = scratch_image(im, flip=True, thr=False, filt=False, resize=False, erode=False)
scratch_dog_images += tmp
# 猫の画像の水増し
# 水増し画像を保存する空のリストを用意
scratch_cat_images = []
for im in img_cat:
# flipのみ実施してみる
tmp = scratch_image(im, flip=True, thr=False, filt=False, resize=False, erode=False)
scratch_cat_images += tmp
# 水増しした犬・猫の画像をnumpy配列にひとまとめにし、教師ラベルを作成
X=np.array(scratch_dog_images+scratch_cat_images)
y=np.array([0]*len(scratch_dog_images)+[1]*len(scratch_cat_images))
その結果は以下の通りでした。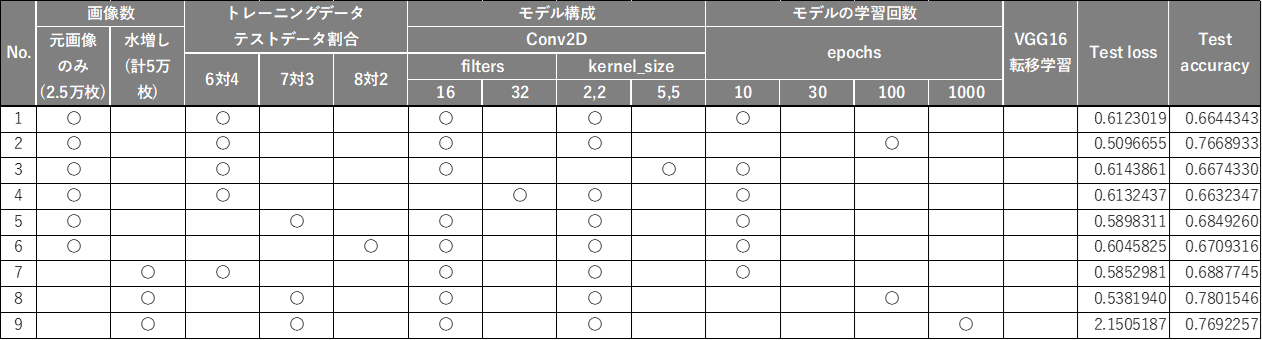
学習の条件を変えた中で、大きな正解率の向上が見られなかったのが、今回の検証では「画像数」「トレーニングデータ・テストデータの割合」「モデル構成(filters、kernel_sizeの変更)」でした。特に画像の数に関しては、もう少し変化があるものと期待していただの、ここは実験を通しての発見でした。
一方大きな正解率の向上が起こったのが、「モデルの学習回数」でした。他の項目を調整した際には正解率(Test accuracy)が70%を超えることはありませんでしたが、モデルの学習回数(epochs)を増やした際には、一気に正解率が70%を超えてきました!しかし惜しくも目標の正解率80%のモデル構築に到達しません…。
転移学習という技術
そこで「転移学習」という技を繰り出します。もちろん講座で学んでいて、後に残しておいた必殺技のようなものですね。転移学習というのは、既に同じような学習モデルを構築された方が公開してくださっている機械学習のモデルを使うことで、その学習成果を取り込むことができるというものだそうなんです。
「転移学習」、文系的に言うなればなんでしょうか、「名著を読む感じ!?」。本来ならば大変な経験をして辿り着く境地であるものを、自身は実際には経験せずとも、読書を通じて疑似体験し、あたかも経験したかのような境地に辿り着けるもの、とでも言えばよいでしょうか。他人の頭脳を取り込めるようなものですよね。すごい仕組みだと思いました。
コードでは、ニューラルネットワークの前後に、VGG16のImageNetから転移学習をさせ、
自分で作ったモデルと合体させるためのコードを加えます。
#VGG16インスタンスの生成
input_tensor=Input(shape=(50,50,3))
vgg16=VGG16(include_top=False,weights='imagenet',input_tensor=input_tensor)
#モデルの定義
top_model=Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256))
top_model.add(Activation('relu'))
top_model.add(Dense(128))
top_model.add(Activation('relu'))
top_model.add(Dense(2))
top_model.add(Activation('softmax'))
#vgg16とmodelの連結
model=Model(inputs=vgg16.input,outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable=False
model.summary()
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4,momentum=0.9),metrics=['accuracy'])
#学習の実行
history=model.fit(X_train,y_train,batch_size=32,epochs=10,validation_data=(X_test, y_test))
するとどうでしょう。ついに目標であった正解率(Test accuracy)80%の壁を越えることができました!(下図No.10)
ということは、先の検証で正解率の向上に大きな影響を与えていた「モデルの学習回数(epochs)」を増やせば更に良いモデルになるのではないかと考え、epochs=100のモデルで検証してみます。すると、上図No.12の通り、思ったほど正解率があがってくれず、代わりにTest loss(損失関数)が急上昇。これが、いわゆる「過学習」だという事は、後に講師にも確認し理解。epochs=30に調整しましたが、それでも高いTest lossを示したため、今回の私のAIモデルは、上図でいうNo.10のこのモデルを採用して、アプリ化することとしました。
No.10に未知の画像で判定させたところ、10枚では「9枚正解、1枚不正解」、100枚で試したところ「85枚正解、15枚不正解」という結果に。まさに正解率(Test accuracy)通りの結果になることにあらためて驚きました。
ちなみに過学習だと言われた上図No.12のモデルだと、10枚で「全問正解」、100枚で「84枚正解、16枚不正解」という結果に。過学習モデルだともっと大幅に正解率が下がって、「これが過学習」か!と理解したかったのですが、これだと正直No.12を最適モデルにしても良かったのか、とも正直迷いましたが、講師の方にお聞きすると、「間違いなく過学習モデルなので、採用するならNo.10の方が良い」とのことでした。もう少し多くの未知の画像を答えさせ検証すれば、差がでたのかもしれません。
ついに機械学習モデル完成
AIモデルを完成させ、あとはインターネットへの実装。と言っても、ここからのネットで表示させる文字や絵の調整で、HTMLやCSSを記述するのですが、これらもすべて初めての体験なので、苦労の連続。とはいえ、本講座の本質とは離れるので、ここでの振り返りは割愛させていただきます。ただ、初心者は、本題のAIアプリを作り上げても、その後も意外と大変だという事はお伝えしておきたいと思います(苦笑)
そして完成させネットに公開したAIアプリがこちらです!!
もちろん私が作った初AIアプリです!!
↓こちら。是非試してみてください!
いぬ・ねこをみわけるAI
※スマホ対応までしきれなかったため、スマホでご覧になられる場合は、横に倒してご覧いただけると助かります(汗)
未経験者の私が苦労したこと
なにもかも初めて学ぶことばかりでしたので、面白くはあるものの、本当に力がついているのかわからないまま進む事にとてもストレスを感じる日々でもありました。ただ途中で心が折れそうになった時に、講師の方に相談した際に、「わからなくても止まらず学びを先に進めてください」と言われ、納得しきれないまでも、立ち止まっている暇はないと前進していました。
この講座は、最後に自分で考えてAIアプリを一から作ります。何がわかっていないのか、どこが腑に落ちないのか、講座を学んでいる最中はなかなか言語化しにくく、「とにかくよくわからない」そんな感じでした。
でも、いざAIアプリを作るために動き出せば、どこがわからないかがわからないと先に進めないので、わかるところを自分で作り上げ、「ここがわからない、理解できない」と言えるようになっているのです。同じような境遇におられる方が読んでくださっている場合は、こう言わせてください。今は真っ最中なので、このまま進んでいいのか不安で不安で仕方がないと思いますが、おそらく繰り返し繰り返し、実務のような中で繰り返していかない限りは身に付かないですから、まずは、置かれた環境で、最善のサポートを受けながら、ゴールまで走り切ってみてください。
学び直しで得られたこと
あっという間の学習期間ではありましたが、無事に自身のAIアプリを完成させられたこと、これが目に見える形での一番大きな成果ではありますね!では、今後はガンガン実務で活かせますね!と言うと、「う~ん」という感想です。
でもそれはそうです。まだようやくスタートラインに立ったばかりですから。正直、AIアプリを作り上げた現在においても、エラーが出ると自分一人では解決できないことがほとんどです。優秀な講師陣の方々の支えなくしては、ゴールにも辿り着けていなかったでしょう。
私がこの講座の学び直しで得た一番大きなものは「甘くないという現実」と「最初の一歩を踏み出した事実」です。「甘くないという現実」は先述した通りで、自分の現在地を嘆きたくもなりますが、千里の道も一歩からと言うじゃないですか!!今回お世話になった講師の方々にも、その一歩を踏み出した日があったわけで、何年もの苦労・経験を重ねて今日があるんだということも教えていただきました。だから、この「最初の一歩を踏み出した事実」、私はこれを大事にしたいと思います。
学び終えてこれから
想いが溢れてしまい、こんな長々とした記事を最後まで読んでくださった皆様、本当にありがとうございます。
無事に講座のゴールまで辿り着き、次は転職活動だ、ということで、当初は、今回学んだことを100%活かせる仕事への転身も考えていたのですが、突きつけられた現実もあり、急ハンドルは身体にも悪いだろうと(苦笑)、これまでの長年の経験と、今回学んできた内容をハイブリッドで活かせる職場を探してみるつもりです。
間違いなくこれからは、今回学んだ考え方が、どのような会社や部署にいたとしても必要になってくると考えていますので、興味のあった自然言語処理の方も含めて、今後は働きながらにはなりますが、学習を継続していきたいと思っております。
最後に、自分にとっては、38歳にして長い夏休みがやってきました。とはいえ、逆に言うと休日なんてない学びの日々でしたので、とても大変でしたが、決断し、時間を確保してでも、一歩を踏み出したことは後悔しておりません。
この夏の決断を受け入れてくれた家族、そして前職での上司や先輩・仲間には驚かれながらも応援していただいたこと忘れません。そして、チャレンジして良かったなと言われるような結果で恩返しさせていただきたいと思っております。
38歳、夏、プログラミング挑戦。
この決断が成功だったかどうかは、未来が来るまでわかりませんが、私の経験が、悩みの中におられる方の参考になることを祈っております。
2022.9 new-masa