はじめに
Amazon S3 Vectorsとは
Amazon S3 Vectorsは、Amazon S3上でベクトルデータを効率的に保存・検索できるマネージドサービスだ。従来、ベクトル検索を行うには専用のベクトルデータベース(AWSならAmazon OpenSearch ServiceやAmazon Aurora PostgreSQL互換のpgvector拡張、SaaSならPinecone、Weaviateあたりが候補になる)を構築する必要があったが、Amazon S3 Vectorsを使うことで、Amazon S3の低コストなストレージ上でベクトル検索が可能になる。また、他のAmazon S3のサービスと同じレベルでフルマネージドに扱えるというのも魅力の一つだ。
なお、pgvectorの構築方法は過去の記事参照
Knowledge Bases for Amazon Bedrockとは
Knowledge Bases for Amazon Bedrockは、RAG(Retrieval-Augmented Generation)を簡単に実装できるマネージドサービスだ。ドキュメントをアップロードするだけで、自動的にチャンク分割、ベクトル化、インデックス作成を行い、LLMからの質問に対して関連情報を検索して回答を生成できる。
今回は、このベクトル化した情報を格納する先として、Amazon S3 Vectorsを利用する。
構成図
構成図は以下のようになる。
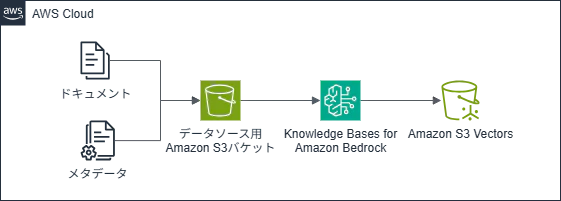
いつも通り、各リソースはTerraformで自動構築する。
IaC
Amazon S3 Vectors
Amazon S3 Vectorsでは、
- aws_s3vectors_vector_bucket
- aws_s3vectors_index
の2つのリソースを作成する。
resource "aws_s3vectors_vector_bucket" "bedrock_knowledge_base" {
vector_bucket_name = local.s3_vectors_bucket_kb_name
force_destroy = true
}
resource "aws_s3vectors_index" "bedrock_knowledge_base" {
vector_bucket_name = aws_s3vectors_vector_bucket.bedrock_knowledge_base.vector_bucket_name
index_name = local.s3_vectors_bucket_kb_index_name
data_type = "float32"
dimension = 1024
distance_metric = "euclidean"
metadata_configuration {
non_filterable_metadata_keys = [
"x-amz-bedrock-kb-document-metadata",
"AMAZON_BEDROCK_TEXT",
"AMAZON_BEDROCK_METADATA",
]
}
}
ポイントは以下の通り。
-
dimensionは埋め込みモデルの次元数に合わせる(cohere.embed-multilingual-v3は1024次元) -
distance_metricはベクトル間の距離計算方法を指定(euclidean、cosineから選択) -
metadata_configurationでAmazon Bedrockが使用するメタデータキーをフィルタリング対象外に設定。
ここで注意しなければいけないのが、AMAZON_BEDROCK_TEXT, AMAZON_BEDROCK_METADATAをフィルタリング除外対象に入れておくという点だ。この2つのメタデータはデフォルトで含まれるが、非常に大きなデータであるため、フィルタ対象から外すようにしておかないと、この後のインデックス作成が失敗する。
Amazon S3バケット
Knowledge Bases for Amazon Bedrockがデータソースとして参照するドキュメント格納用のAmazon S3バケットを作成する。
もちろん、Amazon S3バケットを一般公開しないためのセキュリティ設定は入れておく。
resource "aws_s3_bucket" "bedrock_knowledge_base_datasource" {
bucket = local.s3_bucket_kb_source_name
force_destroy = true
}
resource "aws_s3_bucket_ownership_controls" "bedrock_knowledge_base_datasource" {
bucket = aws_s3_bucket.bedrock_knowledge_base_datasource.id
rule {
object_ownership = "BucketOwnerEnforced"
}
}
resource "aws_s3_bucket_public_access_block" "bedrock_knowledge_base_datasource" {
bucket = aws_s3_bucket.bedrock_knowledge_base_datasource.id
block_public_acls = false
block_public_policy = false
ignore_public_acls = false
restrict_public_buckets = false
}
Knowledge Bases for Amazon Bedrockに指定するIAMロール
Knowledge Bases for Amazon BedrockがAmazon S3バケットやAmazon BedrockにアクセスするためのIAMロールが必要になる。以下のような権限を付与しよう。
resource "aws_iam_role" "bedrock_knowledge_base" {
name = local.iam_role_bedrock_kb_name
assume_role_policy = data.aws_iam_policy_document.bedrock_knowledge_base_trust.json
}
data "aws_iam_policy_document" "bedrock_knowledge_base_trust" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = [
"bedrock.amazonaws.com",
]
}
actions = [
"sts:AssumeRole",
]
}
}
resource "aws_iam_role_policy" "bedrock_knowledge_base_custom" {
name = local.iam_policy_bedrock_kb_name
role = aws_iam_role.bedrock_knowledge_base.id
policy = data.aws_iam_policy_document.bedrock_knowledge_base_custom.json
}
data "aws_iam_policy_document" "bedrock_knowledge_base_custom" {
statement {
effect = "Allow"
actions = [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
]
resources = [
data.aws_bedrock_foundation_model.cohere_embed_multilingual.model_arn,
]
}
statement {
effect = "Allow"
actions = [
"s3:GetObject",
"s3:ListBucket",
]
resources = [
aws_s3_bucket.bedrock_knowledge_base_datasource.arn,
"${aws_s3_bucket.bedrock_knowledge_base_datasource.arn}/*",
]
}
statement {
effect = "Allow"
actions = [
"s3vectors:PutVectors",
"s3vectors:GetVectors",
"s3vectors:DeleteVectors",
"s3vectors:QueryVectors",
"s3vectors:GetIndex",
"s3vectors:PutIndex",
]
resources = [
aws_s3vectors_index.bedrock_knowledge_base.index_arn,
]
}
}
ナレッジベースの作成
S3 Vectorsをストレージとして使用するナレッジベースを作成する。
Terraformリソース名はaws_bedrockagent_knowledge_baseだ。
locals {
model_id = "cohere.embed-multilingual-v3"
}
data "aws_bedrock_foundation_model" "cohere_embed_multilingual" {
model_id = local.model_id
}
resource "aws_bedrockagent_knowledge_base" "example" {
name = local.bedrock_kb_name
role_arn = aws_iam_role.bedrock_knowledge_base.arn
knowledge_base_configuration {
type = "VECTOR"
vector_knowledge_base_configuration {
embedding_model_arn = data.aws_bedrock_foundation_model.cohere_embed_multilingual.model_arn
}
}
storage_configuration {
type = "S3_VECTORS"
s3_vectors_configuration {
index_arn = aws_s3vectors_index.bedrock_knowledge_base.index_arn
}
}
}
ポイントは以下。
-
knowledge_base_configuration.vector_knowledge_base_configurationでは、ベクトル化に使用する埋め込みモデルを指定する。今回は、日本語ドキュメントを対象にすることを前提に、多言語に強い埋め込みモデルであるcohere.embed-multilingual-v3を使用する。 -
storage_configurationでtype = "S3_VECTORS"を指定することで、Amazon S3 Vectorsをベクトルストアとして使用できる。
データソースの設定
Amazon S3バケットをKnowledge Bases for Amazon Bedrockのデータソースとして登録する。
resource "aws_bedrockagent_data_source" "example" {
name = local.bedrock_kb_source_name
description = "Example knowledge base."
knowledge_base_id = aws_bedrockagent_knowledge_base.example.id
data_source_configuration {
type = "S3"
s3_configuration {
bucket_arn = aws_s3_bucket.bedrock_knowledge_base_datasource.arn
}
}
data_deletion_policy = "DELETE"
}
data_deletion_policy = "DELETE"を指定することで、Amazon S3バケットからファイルが削除された際に、ナレッジベースからも自動的に削除されるようになる。
いざ、動かす!
terraform applyでリソースをデプロイしたら、実際にドキュメントをアップロードして動作確認をしてみよう。
ドキュメントのアップロード
データソース用のAmazon S3バケットにドキュメントをアップロードする。
aws s3 cp sample.txt s3://<データソース用バケット名>/
なお、併せてファイル名.metadata.jsonという名前で以下のようなメタデータを格納しておく必要がある。
メタデータなので属性は何でも良い。これを使って後でフィルタリングが可能になるため、たとえば、以下のようにしておくことで、「同じorg_nameの人だけにRAG可能にする」といった制御が可能になる。
{
"metadataAttributes": {
"org_name": "example_org",
"knowledge_name": "example_knowledge"}
}
aws s3 cp sample.txt.metadata.json s3://<データソース用バケット名>/
同期の実行
ドキュメントをアップロードしたら、Knowledge Bases for Amazon Bedrockで同期を実行する。
ナレッジベースIDとデータソースIDは、Terraformのtfstateで確認しよう。それぞれaws_bedrockagent_knowledge_base.example.id、aws_bedrockagent_data_source.example.data_source_idで参照可能だ。
aws bedrock-agent start-ingestion-job \
--knowledge-base-id <ナレッジベースID> \
--data-source-id <データソースID>
同期が完了すると、ドキュメントがベクトル化されてAmazon S3 Vectorsに格納される。
検索の実行
Knowledge Bases for Amazon Bedrockに対してクエリを実行してみよう。
import boto3
bedrock_agent = boto3.client(
'bedrock-agent-runtime',
region_name='ap-northeast-1',
)
response = bedrock_agent.retrieve(
knowledgeBaseId='<ナレッジベースID>',
retrievalQuery={
'text': '検索したい内容'
},
retrievalConfiguration={
'vectorSearchConfiguration': {
'filter': {
'equals': {
'key': 'org_name',
'value': 'example_org',
},
},
},
},
)
for result in response['retrievalResults']:
print(result['content']['text'])
sample.txtの中身が(一部分)表示されれば、RAGの検索成功だ。
なお、上記のフィルタの example_org を example_org2 に変更すると、フィルタ結果が変わってRAGの結果が取得できなくなる。
これで、Amazon S3 Vectorsを使った格安・お手軽RAGが構築できた!