冒頭
初めに、ベンチマークとは性能や品質を測るための「基準」や「指標」のことです。
AIモデルの特徴を示す様々なベンチマークがありますが、それらの意味や見方がよくわからなかったので調べました。
本記事はHugging Faceで見かけるLLMのベンチマークの一部について触れています。
目次
🎯 基盤となる考え方
AIモデルのベンチマークは「正解率(Accuracy)」「バランス(F1スコア)」「生成品質(BLEU/ROUGE)」の3つが基本となっています。
- Accuracy: 100問中何問正解したかをパーセントで表したもの
- F1スコア: 何を正解と見なしたか(適合率)と、見逃さずに判定できたか(再現率)のバランスを取ったもの
- BLEU/ROUGE: AI作成の文章が人間による正解文章とどれくらい似ているかを表したもの
これらを基盤として、様々な目的用途に特化したモデルが作られていると思われます。
また、ベンチマークの結果は、間違った知識を学習する「データ汚染」や学習データの癖やノイズまで記憶してしまう「過学習」の影響を受けやすいので人間評価も重要です。
🤗 Hugging Faceでモデル比較:ベンチマークの詳細説明
Hugging Faceは、AIや機械学習のモデルを共有・活用できる世界最大級のオープンソースプラットフォームです。LLMのベンチマーク比較時に便利で、モデル選びの参考になります。
2025年12月現在、モデル比較の際に便利なOpen LLM Leaderboardで使用されている各ベンチマークを解説します。
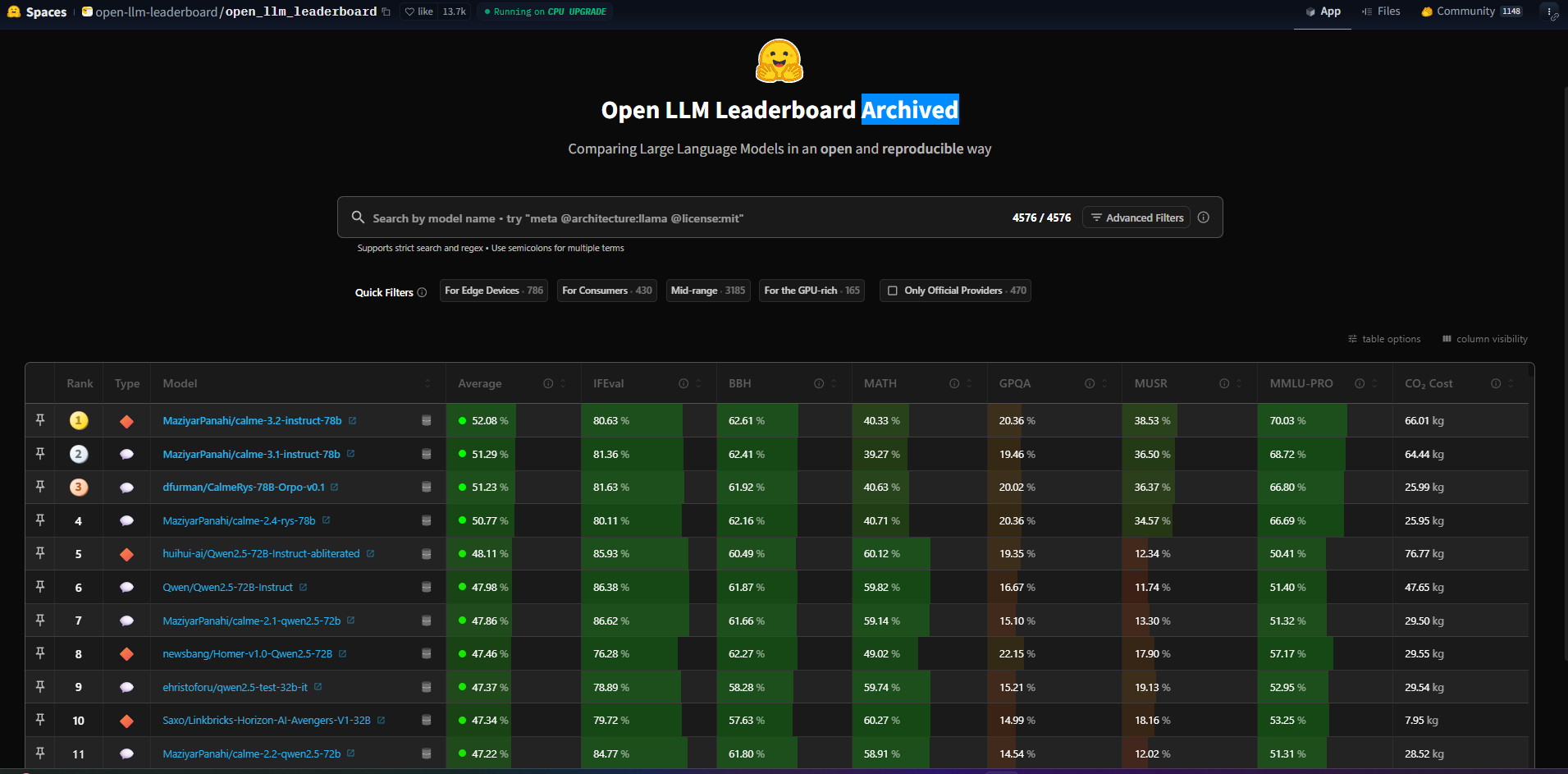
📊 Open LLM Leaderboard 2025年12月:ベンチマーク説明
IFEval(Instruction Following Evaluation)
- 概要: モデルが与えられた指示(instruction)を正確に守れるかを評価
- 目的: プロンプトに忠実に従う能力、正確性、忠実度を測る
- 評価方法: 指示通りの回答の正解率
BBH(Big-Bench Hard)
- 概要: Big-Bench(特に難しい問題を集めたテスト)の中でも特に難しい問題を解く能力を評価
- 目的: モデルの高度な推論や複雑なタスク対応力を測る
- 評価方法: 難問セットの正解率
MATH
- 概要: 競技数学レベルの問題を解く能力を評価
- 目的: モデルの数学的推論・解法能力を測る
- 評価方法: 数学問題の正解率
GPQA(General-Purpose Question Answering)
- 概要: 研究レベルの質問に答える能力を評価
- 目的: モデルの専門知識や研究QA能力を測る
- 評価方法: 研究QA問題の正解率
MUSR(Multi-step Reasoning)
- 概要: 複数のステップを経て推論する能力を評価
- 目的: モデルの複雑な論理的思考力を測る
- 評価方法: 多段階推論問題の正解率
MMLU-PRO(Massive Multitask Language Understanding - PRO)
- 概要: MMLUのプロフェッショナルバージョン。より専門的・難易度の高い知識問題を評価
- 目的: モデルの専門知識や高度な知識理解力を測る
- 評価方法: 高難度知識問題の正解率
CO2 Cost
- 概要: モデルの学習や推論に伴う二酸化炭素排出量を評価
- 目的: モデルの環境負荷(Green AI)を定量的に測る
- 評価方法: 学習・推論時の電力消費からCO2排出量(環境負荷)を算出
🏷️ 分野別ベンチマーク
次は、実務でよく使用するドキュメントの要約や画像認識に特化しているモデルを知るためのベンチマークになります。
MITライセンスのsarashina2.2-Vision-3Bのモデルカードを基に各ベンチマークで比較し、用途別に適したモデルを考えてみます。
比較表
| Model | Params(B) | BusinessSlide VQA | Heron-Bench | JDocQA | JMMMU |
|---|---|---|---|---|---|
| Sarashina2.2-Vision-3B | 3.8 | 3.932 | 3.214 | 3.327 | 0.486 |
| Qwen2.5-VL-3B-Instruct | 3.8 | 3.516 | 2.000 | 3.019 | 0.450 |
| Qwen3-VL-4B-Instruct | 4.4 | 4.105 | 2.330 | 3.596 | 0.493 |
| InternVL3_5-4B | 4.7 | 3.311 | 1.893 | 2.626 | 0.437 |
| Sarashina2-Vision-14B | 14.4 | 3.110 | 2.184 | - | 0.432 |
| Stockmark-2-VL-100B-beta | 96.5 | 3.973 | 2.563 | 3.168 | - |
ベンチマーク説明
- Params(Billion単位): パラメータ数。複雑な処理をこなす能力
- BusinessSlide VQA: ビジネス資料(スライド)の画像から質問に答える能力
- Heron-Bench: 日本語画像を理解する能力
- JDocQA: 日本語ドキュメント(文書)の質問応答能力
- JMMMU: 日本語マルチモーダル(画像+テキスト)の理解力
見方のポイント
- 基本的には数値が高いほど性能が良いです。各ベンチマークで最も高い数値のモデルが、そのタスクに最も強いと言えます。パラメータ数(Params)に関してはスコアが高いものほどリソース消費が大きいので、使用の際は注意が必要です
適したモデル
- BusinessSlide VQAに特化したモデルQwen3-VL-4B-Instructは、ビジネス資料の理解に強い
- Heron-Benchに特化したモデルSarashina2.2-Vision-3Bは、日本語画像理解に強い
- JDocQAに特化したモデルQwen3-VL-4B-Instructは、日本語ドキュメント理解に強い
- JMMMUに特化したモデルQwen3-VL-4B-Instructは、日本語マルチモーダル理解に強い
Qwen3-VL-4B-Instructが総合的にパフォーマンスが高く、最も高い性能を発揮していると判断できますが、日本語画像理解を主とする用途であればSarashina2.2-Vision-3Bを選ぶといった考え方もできますね。
補足
-
ビジネス資料理解(BusinessSlide VQA)と日本語画像理解(Heron-Bench)は似ていますが、ビジネス資料理解特化モデルは、ビジネス文脈や専門用語、複雑な図表の解釈に強い設計となっています
対して、日本語画像理解特化モデルは、一般的な日本語画像(風景、食べ物、アートなど)を対象にしています -
日本語マルチモーダル理解は、画像とテキストの両方を同時に理解し、相互に関連付ける能力を評価します
まとめ
ベンチマークスコアはモデル選定の際に便利な指標となります。
様々な比較を行い、独自の要件に合ったモデルを探してみましょう。
モデル決定前には、公式ベンチマークとは別に独自データやタスクでの検証を行い、人の目による評価も行いましょう。
有償モデル使用の際は費用の試算も大事ですね!