メモです。
所感
WebGPUを勉強していると「お前に私が使いこなせるかな?」と問われている感じになる。
学習サイト
最初にこちらの記事で、大まかな雰囲気を掴んで、
WebGPUでガチリアルタイムレンダリングの世界が見えてきた
WebGLからWebGPUにステップアップしよう!
こちらで手を動かして実践します。
WebGPU入門
そして、こちらを読み込むのが良さそうです。
WebGPU Fundamentals
実装サンプルはこちら。
WebGPU Samples
周辺ライブラリ
Typescript Type Definitions for WebGPU
Typescriptを使用する場合に、現在(2024.10.06時点)ではWebGPUの型定義がされていないので、こちらを使用して型情報を追加してあげる必要があります。
webgpu-utils
Attribute,Uniform,Textureなどの生成や設定(特にメモリレイアウト)を簡潔にしてくれるライブラリ。
wgpu-matrix
WebGPUで使える、MatrixやVector等を揃えたライブラリ。WebGLで言うところのgl-matrixです。
ほとんどの他の3D数学ライブラリは、WebGL向けに設計されており、WebGPUには最適化されていません。WebGPUはクリップ空間のZ軸が0から1の範囲であるのに対し、WebGLでは-1から1の範囲です。そのため、正射影、透視投影、視錐体の計算が異なります。また、WebGPUのmat3は12の浮動小数点数(パディングあり)で構成されているのに対し、WebGLでは9の浮動小数点数です。
wgpu-matrix README 抜粋
vite-plugin-glsl
開発環境にViteを使う場合は、こちらのプラグインを使うことによって、shader内で他のwgslファイルをモジュールとして参照できます(実際には置換マクロです)
#include './noise.wgsl'
@frangmet fn fs(@location(0) uv: vec2f) -> @location(0) vec4f {
let color: vec3f = noise(uv, time);
return vec4f(color, 1.0);
}
shaderファイルをstringとしてimportする機能も備えています。
ただ、それをしたいだけであれば、プラグインは使わずに?rawを付けるだけでOK。
import shader from './hoge.wgsl?raw';
WebGPUをいつ学ぶのか
2024.10.06現在、WebGPU自体まだSafariやFirefoxが対応できていないので、学ぶのはもう少し後でもいいかもしれません。
ただ、WebGL API(の使い方的なところ)や、3DCGの考え方をまったく知らない人が、WebGPUからいきなり学習を始めるのは、WebGLから学習を始めるよりはるかに難易度が高いと思います。(他に、GPU APIを使った経験があれば別です)
今後、数年内にWebGPUはモダンブラウザで全サポートされて、徐々にWebGL < WebGPUとなっていくでしょう。そうなったときに、WebGPUを勉強するためにWebGLから勉強するのは、非効率だしモチベもわかないと思います。
なので、Webでの3DCG表現や、GPUをつかった計算(compute shaderを使った機械学習)に興味があれば、今からWebGLを学んでおくのがいいと思います。
幸いWebGLであれば、ネット上にたくさんの情報があり、またオンラインスクールや講座もあるので、学ぶ環境がかなり整っていると思います。
毎年開催されているWebGLスクールがおすすめです。(※講師の方が事実上毎年やられていますが、そう決めているわけではないみたいです。なので、開催されなくても悪しからず)
挑戦することからすべては始まる! WebGL スクール第11期募集開始(リモート開催)(2024年開催分)
日本語の講座ではないですが、Three.jsの↓の講座もおすすめです。
Three.js Journey
雑記
学習記録です。
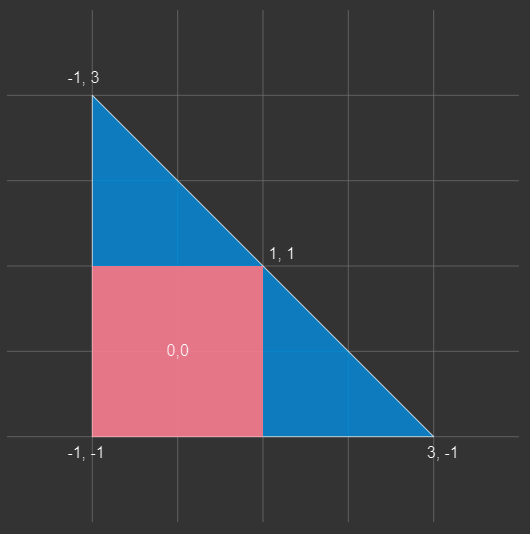
画面いっぱいに面を張る(ポストプロセスとかで使う)
もはや、頂点属性すらいらない。
- 三角形を
-1 ~ 3の範囲で作る。 -
-1 ~ 1は矩形領域となるので、それに合わせてtexcoordを変換する。
struct VSOut {
@builtin(position) position: vec4f,
@location(0) texcoord: vec2f,
}
@vertex fn vs(@builtin(vertex_index) vertexIndex: u32) -> VSOut {
let pos = array(
vec2f(-1, -1),
vec2f( 3, -1),
vec2f(-1, 3),
);
var out: VSOut;
let xy = pos[vertexIndex];
out.position = vec4f(xy, 0, 1);
out.texcoord = (xy + 1.0) / 4.0 * 2.0;
return out;
}
@fragment fn fs(in: VSOut) -> @location(0) vec4f {
return vec4f(in.texcoord, 0.0, 1.0);
}
エラー表示
WebGLより手厚い印象あがります。WebGLのようにエラーハンドリングしなくても、エラーが起きた場所を教えてくれます。
また、device.create***系の関数では、labelを付けることができます。labelを付けることによって、より詳細にどのタイミングでエラーが出たのかを知ることができます。
const pipelineA = createPipeline(layoutA, sourceA, 'A');
const pipelineB = createPipeline(layoutB, sourceB, 'B');
function createPipeline(layout: GPUPipelineLayout, source: string, name?: string) {
const shaderModule = device.createShaderModule({
label: `create shader module ${name}.`,
code: source
})
return device.createComputePipeline({
label: `create pipeline ${name}.`,
layout,
compute: { module: shaderModule }
})
}
座標系
WebGPUは、左手座標系です。(DirectXと同じで、+zが奥側になります)
WebGLは、右手座標系です。(+zが手前側になります)
また、WebGPUではクリップ空間のZ座標が0 ~ 1で表されます。
buffer sizeのpadding
16byteを1セットとして考えるようで、それに満たない場合は自動的に拡張されるようです。
※拡張が必要なのはuniform buffer,storage bufferで、vertex bufferは拡張されない(必要がない)。
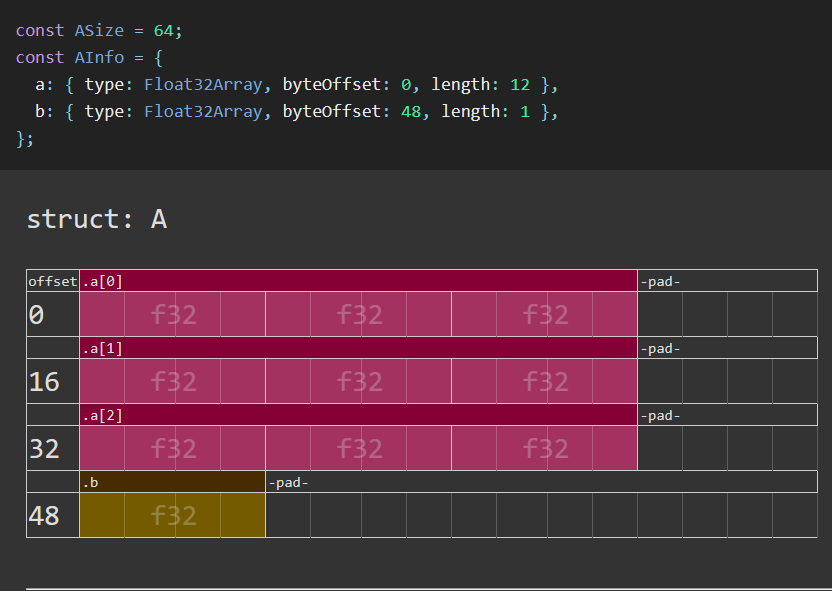
たとえば、以下のようにUniformを定義した場合、
struct Uniform {
time: f32,
color: vec3f,
matrix: mat4x4f,
}
timeは4byteだけど、bufferは+12byte分拡張されるので、colorのbyte offsetは16byteになる。
matrixのbyte offetは、
4byte(time) + 12byte(timeの拡張分) + 12byte(color) + 4byte(colorの拡張分) = 32byte
になる(はず)
インスタンス化に関するメモリ上限
Three.jsで言うところのinstancedMeshをやろうとした場合、それぞれのMeshのMatrix(instancedMatrix)を配列で定義して、Shaderに渡す必要があります。
例えば、100個のインスタンスを作る場合、以下のようにFloat32Arrayの配列を作成して、Bufferに書き込みます。
const instancedMatrix = new Array<Mat4>(100)
// Mat4 = mat4x4<f32> = 16 * 4 byte
Shaderでは、以下のように参照できます。
@vertex fn vs(@builtin(instance_index) instanceIdx: u32) -> VSOut {
let instancedMatrix = instanced.matrix[instanceIdx];
・・・
}
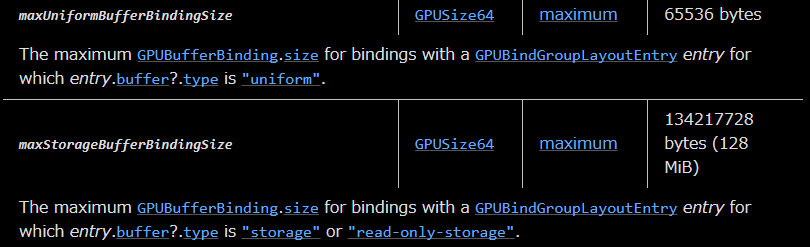
instancedMatrixをUniformで渡した場合、UniformのBufferの上限が65536 bytesなので、インスタンス化できる数は1024個が限界値になります。(実際には他のUniformも渡すので、もっと少なくなります)
上限値 / (Mat4x4 * flaot32)
65536 / (16 * 4) = 1024
storage bufferを使ってMatrixを渡す場合、storage bufferは上限が134217728 bytes (128 MiB)なので、およそ200万個分のMatrixを格納できます。
Compute Shaderに関する上限
例えば、10万個のinstance meshを作るとして、instanced matrixをcompute shaderで更新しようとした場合、
pass.dispatchWorkgroups(100,000)
としても、上限値65535に引っかかってしまいます。なので、dimensionに分割する必要があります。
細かいことはあまり考えず、requestNumInstances = 100,000とすると、以下のように計算できます。
const numInstancePerDim = Math.floor(Math.sqrt(requestNumInstances)) // 316
// 316 * 316 = 99,856
pass.dispatchWorkgroups(numInstancePerDim, numInstancePerDim)
また、workgroupを使うことで計算を高速化できるので、blockSize = 10とした場合、以下のように計算できます。
const numInstancePerDim
= Math.floor(Math.sqrt(requestNumInstances) / blockSize) * blockSize // 310
// 310 * 310 = 96,100
pass.dispatchWorkgroups(numInstancePerDim / blockSize, numInstancePerDim / blockSize)
// compute.wgsl
@workgroup_size(blockSize, blockSize)
maxComputeWorkgroupsPerDimension: 65535
実行コマンドdispatchWorkgroupsを呼び出すときの、1つの次元あたりの上限値。
maxComputeInvocationsPerWorkgroup: 256
shader内の@workgroup_sizeで指定する、各次元の積の上限値。
@workgroup_size(256, 1, 1) // ok
@workgroup_size(128, 2, 1) // ok
@workgroup_size(16, 16, 1) // ok
@workgroup_size(16, 16, 2) // bad 16 * 16 * 2 = 512
参考
WebGPU Compute Shader Basics
What size should you make a workgroup? The question often comes up, why not just always use @workgroup_size(1, 1, 1) and then it would be more trivial to decide how many iterations to run by only the parameters to pass.dispatchWorkgroups.
The reason is multiple threads within a workgroup are faster than individual dispatches.
For one, threads in a workgroup often run in lockstep so running 16 of them is just as fast as running 1.
ワークグループのサイズはどれくらいにすべきでしょうか?よくある質問として、なぜ常に
@workgroup_size(1, 1, 1)を使わないのかという点があります。そうすれば、dispatchWorkgroupsに渡すパラメータだけで何回のイテレーションを実行するかを決定するのがより簡単になります。その理由は、ワークグループ内の複数のスレッドが個別のディスパッチよりも速く動作するためです。
1つの理由は、ワークグループ内のスレッドはしばしばロックステップで動作するため、16のスレッドを実行するのも1つのスレッドを実行するのも同じくらいの速度で実行できるからです。
※ロックステップ
「ロックステップ」とは、複数のスレッドが同時に同じ命令を実行することを指します。これにより、スレッド間の同期がとれ、各スレッドが同じタイミングで計算を行うため、効率的に処理が進みます。
GPUのアーキテクチャでは、スレッドがロックステップで動作することで、メモリのアクセスパターンを最適化し、パフォーマンスを向上させることができます。たとえば、複数のスレッドが同じ命令を実行するとき、ハードウェアはその命令を一度だけ読み込むことで、効率的にリソースを使用できます。これが、ワークグループ内でのスレッドの動作が個別のディスパッチよりも速い理由の一つです。
Point Size
WebGPUでPointとして頂点を描画する場合、topologyにpoint-listを指定すると描画できます。ただし、サイズは1pxで固定です。
WebGLの場合、gl_PointSizeである程度大きさを持たせることができました。ただ、実行環境(ブラウザ)によってサイズ上限が異なり、これを排した仕様となっているそうです。
WebGPUでPointを配置したい場合は、Plane(正方形頂点)をtriangle-listとして配置します。
WebGPU Points