ここ数年、Qiita上ではもっぱらポエムを生業としつつあります。@emadurandalです。こんにちは。
本記事ではWebGPUのWeb3Dにもたらす意味や効果について語っていこうと思います。とってもポエミーです。よろしくお願いします。
(なお、現時点でのWebGPUでは未対応で、将来的なサポートが議論されている未来の機能を前提にした話もしています)
なぜWebGPUが必要とされているのか
そもそもなぜ、WebGPUなのでしょうか。別にWebGLのままではいけないのでしょうか。
OpenGLは4.x世代が引き続きアップデートを続けていますし、OpenGL ESも3.x世代がコンピュートシェーダーを獲得するなど進化を続けています。それをベースにWebGL2とかWebGL3とかで順当にアップデートしていけば良いのではないでしょうか? そう思う方も多いでしょう。
しかし世の中を見渡すと、WebGPUやらVulkanやら、潮流が低レベルAPIの方向に流れているようです。何故なのでしょうか。
3DAPIが低レベル化している理由
その1:性能!性能!
理由の一つに、GPUの性能向上がCPU以上に速いことが挙げられます。
近年、性能向上が著しく、応用の場も広がって注目が集まるGPUですが、CPUの指令なしでは動作できません。CPU側がボトルネックになってはGPUがただ命令を待って空転してしまうのです。
これはCPUというハードウェアだけでなく、それを駆動するプログラム側も効率的な実装でなければGPUを遊ばせてしまうことを意味しています。
CPUプログラム側でキーとなるのは3DAPIです。GPUとの連絡役である3DAPIが高効率なものでなければGPUの活用率が落ちてしまうことは容易に想像がつくでしょう。
その点において、OpenGLやWebGLなどのいわゆるGL系APIは大きな問題を抱えています。VulkanやDirect3D 12、Metalといった今日のAPIの方がより高効率であり、WebGPUはその流れを汲むものです。
これらのAPIの特徴は低レベルであること。つまり抽象化の層が薄く、よりハードウェアに近い制御が可能である点です。そしてCPUのマルチスレッドからの制御に対応していること。どちらもOpenGLにはない特徴です。
こうした低レベルAPIは、何も近年になって初めて登場したわけではありません。コンソールゲーム機の世界ではむしろ昔から低レベルな3DAPIが普通でした。ゲーム機は同じメーカーの同じ世代の製品であれば、ハードウェア仕様がすべて同一です。そのためそのゲーム機のために用意される3DAPIはハードウェアの仕様を抽象化する必要がほとんどなく、無駄な処理を殆どしない高速かつ細かい制御が可能な仕様になっています。
そんな、長らくコンソールゲーム機の専売特許と思われていた低レベル3DAPIが、近年になってパソコンやスマートフォンにももたらされる様になり、これらの一般機器でもGPUハードウェアの性能を高いレベルで引き出せるようになってきました。
AMD社のMantleというVulkanの原型となったAPIからその潮流は始まりましたが、この動きにはいくつかの背景があります。
その2:各社のGPUの機能や設計が似てきた
これらの低レベルAPIは、GPU製品・アーキテクチャ間の差異を吸収する層も薄いものになっています。逆に言えば、薄くてもなんとかなるくらい、各社のGPUの仕様は近年、かなり似通るようになってきています。
これは、主にMicrosoft社がDirect3Dをベースに各GPUメーカーを巻き込み、進化の路線を主導しつづけてきたことが大きな理由として挙げられます。Windows PCは古くからゲームプラットフォームとしても力を入れており、Microsoft社は3Dゲーム開発を推進するため、WindowOSのメインレイヤーを回避してハードウェア層に近い部分を叩けるAPI DirectXを生み出しました。(※DirectXのうち3D機能部分がDirect3Dですが、本記事ではDirect3Dに表記を統一します)
MicrosoftのDirect3Dの求心力は強く、各GPUメーカーはこぞって自社製品をDirect3D APIに対応させました。Microsoft社は各GPUメーカーと緊密に協力し、Direct3Dの機能仕様を拡張し続けます。各GPUメーカーが独自の機能を搭載することも時にはありましたが、それもDirect3Dの機能仕様に取り込まれると、対するライバルメーカーもその機能を次の製品で搭載します。
こうした動きもあり、各社のGPUの仕様や進化の方向性は、Microsoftが主導する形で進化の方向が長らく一本化されてきたと言えます。
一方で、この動きに長い間取り残されてしまったのがWebGLの前身であるOpenGLです。OpenGLの長い歴史を辿ると、かつての3D業界の雄、SGI社のワークステーションで動くIrisGLというグラフィックスAPIに行き着きます。このIrisGLを元に仕様をオープンにして仕切り直したものがOpenGL APIです。Direct3Dが登場するよりしばらく前の出来事でした。
Direct3D登場以前、OpenGLが出てきた当時は、当時一斉を風靡したGPUメーカー(当時はまだGPUという呼称はありませんでしたが)Voodoo社の3D API「Glide」やApple社による3D API「QuickDraw3D」など、各社が自由に3D仕様を策定していた時代でした。
今では当たり前のプログラマブルシェーダーやハードウェアで頂点処理を行うHardware T&L機能なども存在せず、ラスタライズ以降のピクセル計算しかGPU(という用語すら存在せず、当時はビデオカードと呼ばれていました)は処理を担当していませんでした。当時のハードウェアの3D実装仕様は多種多様だったのです。そんな当時のハードウェア群を抽象化しなければならなかったOpenGLが、どれだけ分厚いオーバーヘッドを抱えてきたか想像してみてください。
そんなGL系が色々辛い
前述の通り、多くのプラットフォームで動かせるように配慮したためなのかどうかはわかりませんが、OpenGLは異常系の挙動・仕様などがあまり細かく規定されておらず、そうした部分の実際の挙動は各社のドライバ依存(各社のOpenGLで挙動が微妙に変わってしまうかもしれない)の部分が多くありました(参考記事)
このOpenGLの性質は現在も続いており、WebGLを実際に駆動するときのネイティブレイヤーが複雑化する要因にもなっています。OpenGLだけでWebGLを実装できればよいのですが、プラットフォーム間の挙動の違いなどもあり、比較的仕様・挙動が厳格なDirect3Dも併用して実装される(具体的にはANGLEというプロダクトです)ような現状です。
この間、Direct3Dはバージョン1から最新の12に至るまで、各世代で大きく仕様を作り直しています。その度にソフトウェアメーカーは苦労もしましたが、逆に言えば古い仕様を引きづらずにDirect3Dはその世代世代で一番洗練された仕様であり続けることができました。
対するOpenGLは、組み込み向けのOpenGL ESやOpenGL 3.xのタイミングで、古い仕様のいくつかを捨ててAPI体系を多少整理する機会が1度か2度はあったものの、Direct3Dほど抜本的な仕様の刷新はできずにいました。これは、Direct3Dが市場でいうなら生鮮食品に近く変化の激しいゲーム市場を主なターゲットにしていたのに対し、OpenGLは3DCGや3DCADなどの、互換性を大事にする比較的保守的な市場で多く使われていたことが関係しています。
GL系はマルチコア・マルチスレッド時代に合わない
GL系APIはマルチスレッド処理に殆ど対応できません(一部、テクスチャのGPUへのロードなどは並行してできたりもしますが、その程度です)。そうした点もすでに時代遅れになってきています。
現世代低レベルAPIでは、描画コマンドを複数のスレッドから作成してキューイングすることができます。
そもそも、GL系は一つのGLコンテキストを通じてすべての操作(GPUリソース作成、描画指示、ステート変更など)を行う必要があり、各種リソースはすべての使用中のGLコンテキストに拘束されてしまっています。そしてそのGLコンテキストは現在のメインスレッドに拘束され、他のスレッドから正しく利用できないのです。
Vulkan, Direct3D12, Metal, WebGPUなどの低レベルAPIでは、操作の種類によって、コンテキストオブジェクトが分かれています。
WebGPUならGPUDeviceがリソース管理を、GPUCommandEncoderが描画コマンドの生成を、GPUQueueがGPUへのコマンド列送信を行います。これらはそれぞれ別のスレッドから行えるのです(WebGPUもおそらく最終的にそうなってくれるはずです)。
さて、前置きが長くなりましたが、WebGPU登場の背景には「3D処理をより高速化したい」「それができる環境が揃ってきた」「OpenGLは多様な黎明期を支えるために欠点を多く背負わざるをえなかった(WebGLにも続いている)」といった事情があったことがおわかりいただけたかと思います。
GL系ではGPUが不意にストールすることがある。
これは、APIの設計世代の話でもあるので、DirectX11以前にもある程度当てはまるかもしれません。
レンダリングに関係する各種の設定をGL系では一つのコンテキスト(WebGLならglオブジェクト)を通じていくつも行っていますが、実は一部の設定を変更しただけで、GL系はすでにコンパイルが済んでいたシェーダーを再コンパイルすることがあるようです。
シェーダーの再コンパイルまでいたらない場合でも、一部の設定変更がGPUの大きな状態変更にまで波及することがあります。
そうしたことがおきると、GPUはパイプラインをストール(データ処理が止まり、途中までのデータを廃棄、やり直さなければならない現象)させてその状態変更に対応しなければならないのです。
しかも、そのGPUをストールさせるほどの内部処理を行う必要性は、ドローコール(gl.drawElementsなど)を発するまでわからない場合があるといいます。それもある程度規則性があればともかく、GPUの世代やベンダー、OS環境によっても異なるというのですからたちが悪いです。予測不能なGPUストールなど、ハイパフォーマンスが必要な用途には心もとないでしょう。
Vulkan, Direct3D12, Metal, WebGPUなどの低レベルAPIでは、こうした各種設定を「パイプラインステート」という大きな設定オブジェクトにまとめています。逆に言うと、パイプラインステートを変更したときが、GPUストールが起き得るという、わかりやすい状況になりますし、パイプラインステートは作り置きして再利用することも可能です。これらは、当然前述した高性能の実現に繋がっているわけですね。
その3:ほとんどの開発者(ライブラリ・エンジン開発者以外)にとって3DAPIを直接触らなくても目的を達成できる3Dソリューションが普及した
ご想像の通り、UnityやUnreal Engine、WebGLでいうならThree.jsなどのことですね。これらを使えば手っ取り早く目的を達成でき、また殆どのケースでは、3DAPIを生で扱うのに比べて、出来ることが制限されるわけでもありません。
そうした背景もあり、これからの3DAPIはライブラリ・エンジン開発者のみが触るもの、とみなしてしまっても良い時代背景となり、MicrosoftやKhronosといった3DAPI策定企業・団体は、低レベルAPIに方向性を全振りしやすくなったと言えるでしょう。
WebGPUのAPIは軽量で、多くの必要なデータを前もって作り置きできる
OpenGL/WebGLでは、各GL命令の内部で様々なデータが生成され、しかもそれらを接合させるためのチェック処理が走ります。
WebGPUでは、描画に必要な各種の設定データは前もって作成することができ、しかもその多くは使い回すことが可能です。
例えば、WebGLでは描画の際、以下のようなGL命令を実質的に毎フレーム必ず呼ばなければなりません1
- シェーダープログラムの使用開始(gl.useProgram)
- レンダーターゲットの設定(gl.bindFramebuffer, gl.drawbuffers)
- アルファブレンドの設定(gl.blendFuncSeparate)
など
WebGPUでは、これらの設定は予めRenderPipelineという設定オブジェクトとして事前生成し、使い回すことができます。
(下記、勝手ながら @cx20 さんの1日目の記事のコードから引用させていただきました。)
const pipeline = device.createRenderPipeline({
layout: 'auto',
vertex: {
module: device.createShaderModule({
code: vertexShaderCode,
}),
entryPoint: 'main',
buffers: [{
arrayStride: 12, // 3 * 4bytes
attributes: [{
shaderLocation: 0,
offset: 0,
format: "float32x3"
}]
}]
},
fragment: {
module: device.createShaderModule({
code: fragmentShaderCode,
}),
entryPoint: 'main'
},
primitive: {
topology: 'triangle-list',
}
});
WebGPUで事前に作成することになるこれらの設定オブジェクトは、GPUがネイティブ動作として必要とするデータの依存関係に近い仕様になっています。そのため、WebGLのように命令が呼ばれる度に、今まで呼ばれたGL命令の設定値を実際のGPUが必要とするデータの依存関係に直したりチェックしたりする内部処理が必要ありません。その関係で各API関数も非常に動作が軽いものとなっています。
WebGLではあまり推奨できなかった、多くの描画命令を発行してもWebGPUでは性能的に負荷になりづらい理由の一端です。
また、WebGPUではRenderBundleという、レンダリングコマンドを再利用できるコマンドオブジェクトも存在します(OpenGLでいうところのディスプレイリストに相当)。RenderBundleを用いること、毎回コマンドを再作成するコストを省くことができます。
比較的今どきのGPU機能が使える
たくさんあるのですが、代表例を上げれば、以下の2つでしょう。
- Indirect描画
- Compute Shader
Indirect描画は、描画で必要となる各種描画パラメータをGPU内で生成して利用できる、GPUドリブンの描画アプローチです。説明がなかなかむづかしいので、これの説明は別の機会としましょう。
Compute Shader
また、Compute ShaderはGPUを汎用的な計算に用いることができます。
今までもピクセルシェーダーや頂点トランスフォームフィードバックで限定的には汎用計算ができました。
しかし、ピクセルシェーダーや頂点トランスフォームフィードバックでは、データのギャザーができてもスキャターができません。
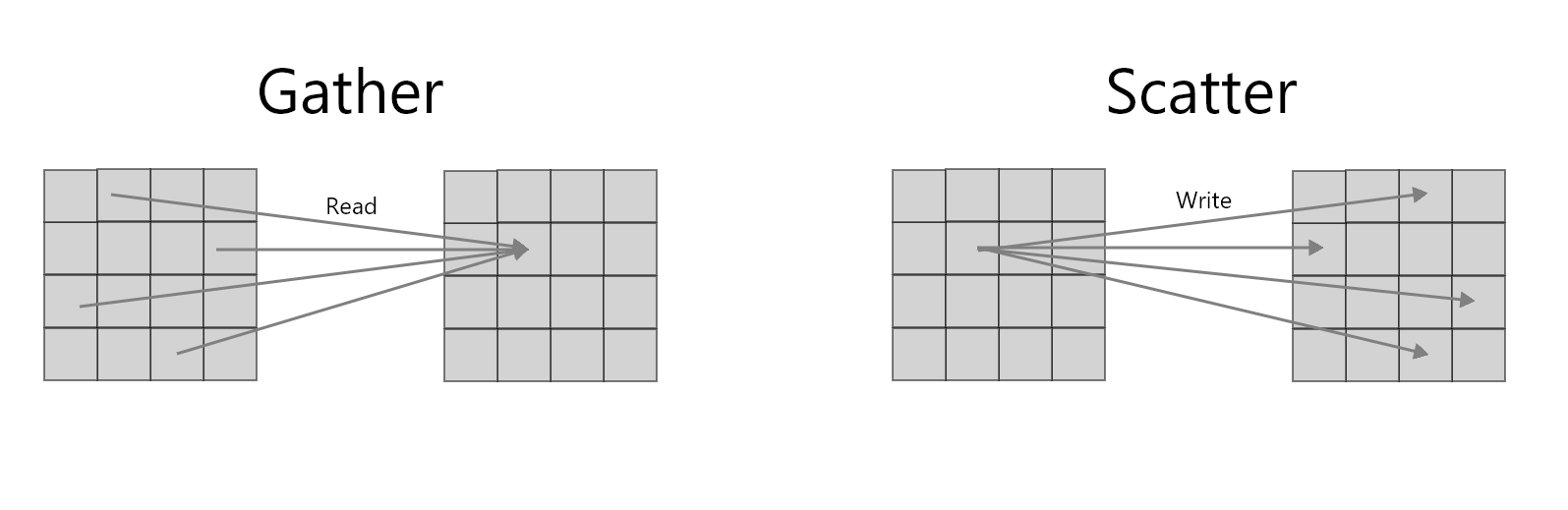
データのギャザーとは、ある処理単位において複数のメモリ位置から複数のデータを取得するデータ操作です。ピクセルシェーダーや頂点トランスフォームフィードバックでは、Uniform配列やUBO、テクスチャなどからそうした操作ができますね。
一方、データのスキャターは、ある処理単位から、データを複数のメモリ位置に書き込むデータ操作です。ピクセルシェーダーでは、基本的にラスタライズされたフラグメントが処理単位となり、その計算の出力は、レンダーバッファの対応するピクセル位置に一対一となり、複数箇所への書き込みができません。トランスフォームフィードバックにしても、自分の頂点のデータを変更できるだけです。つまり、どちらもスキャターができないわけですね。2
でもComputeShaderなら、スキャターができます。
また、WebGLのピクセルシェーダーではレンダーターゲットにしているテクスチャを同時にピクセルシェーダーで読み込むことはできません。つまり、同一のメモリリソースに対して読み込みと書き込みを同時に行うことができず3、どうしてもやりたい場合はダブルバッファリングテクニック4 を行う必要があります。
ComputeShaderなら、シェアードメモリと呼ばれるスレッド間共有型の一時メモリ領域やShader Storage Buffer Object(SSBO)というメモリ領域に対して、読み込みと書き込みを何度も自由に行うことができます。
つまり、CPUに近い一般的な汎用計算が可能になるということです。5
頂点ステージ系シェーダーについては…?
ちなみに、ジオメトリシェーダーやテッセレーションシェーダーへの対応は現在まだ見送りとなっています。コンピュートシェーダーなどと比べれば重要性で幾分落ち、またGPU各社でここらへんの頂点系シェーダーパイプラインの動向が不透明な部分6 がある以上、しばらく様子見なのかもしれません。
Goodbye Immediate Rendering. Hello Delayed Rendering!
低レベル3D APIが高速な理由のうち、以下の3つは説明してきました。
- 抽象化層が薄いため、API関数が無駄な処理をしない。
- 多くの設定データをあらかじめ作り置きし、使い回すことができる。
- マルチスレッドをサポートしている。
もう一つの理由として、「きめ細かい制御ができる」点も言及しておきましょう。
細かい制御といっても、同期周りやリソース管理など、命令の発行タイミングなど、様々あるのですが、実例の一つとして「Delayed Rendering」を紹介します。
即時レンダリング(Immediate Rendering)
3Dリアルタイムレンダリングにおいては、レンダリングループを回す必要があります。このレンダリングループは通常、ディスプレイの画面のリフレッシュタイミングであるVSYNC(垂直同期)と同期しています。WebでいうならrequestAnimationFrameがそれに近いかもしれません。
ここでキーとなってくるのが、CPUの描画命令とGPUの命令実行タイミングです。
WebGPUでは、VulkanやDirect3D 12、Metalなどと同様に、描画コマンド(コマンドバッファ)を生成してコマンドキューに詰め込み、好きなタイミングでそのコマンド群をGPUに対して実行させることができます。
WebGLでも、実際に駆動しているネイティブ3DAPIのさらにドライバ層では、描画コマンドが積まれてGPUにそれが送られるのですが、そこはブラックボックス動作になっており、制御することができません。
この違いは大きいです。というのも、後者ではCPUの描画命令とGPUの命令実行のタイミングは処理系依存になります。仮に、レンダリングループN回目の時にCPUで発行した描画命令を、そのN回目のループ中にGPUが即座に実行するのであれば、それはImmediate Rendering(即時レンダリング)と呼ばれます。
Immediate Rendering(即時レンダリング)はパフォーマンス上一般的には不利な動作モードです。理由は後述します。
低レベルAPIで行える遅延レンダリング(Delayed Rendering)とは
低レベルAPIの場合は、GPUが命令を実行するタイミングも細かく制御することができます。その制御をうまく利用した方法として、遅延レンダリング(Delayed Rendering)というものがあります。7
作った描画コマンドをなにもその時のレンダリングループ中でGPU処理する必要はない、それがこのアプローチの発想の元です。
言い換えるとn回目のレンダリングループの時、CPU側の処理は様々なロジック処理を行ってそれらを元に描画コマンドを作りますが、それは次のn+1回目のループの時にGPUに実行させる(別の言い方をすれば、n回目ループではGPUはn-1回目にCPUが作った描画コマンドを実行している)、ということができます。
言葉だけだと分かりづらいので図にしてみました。
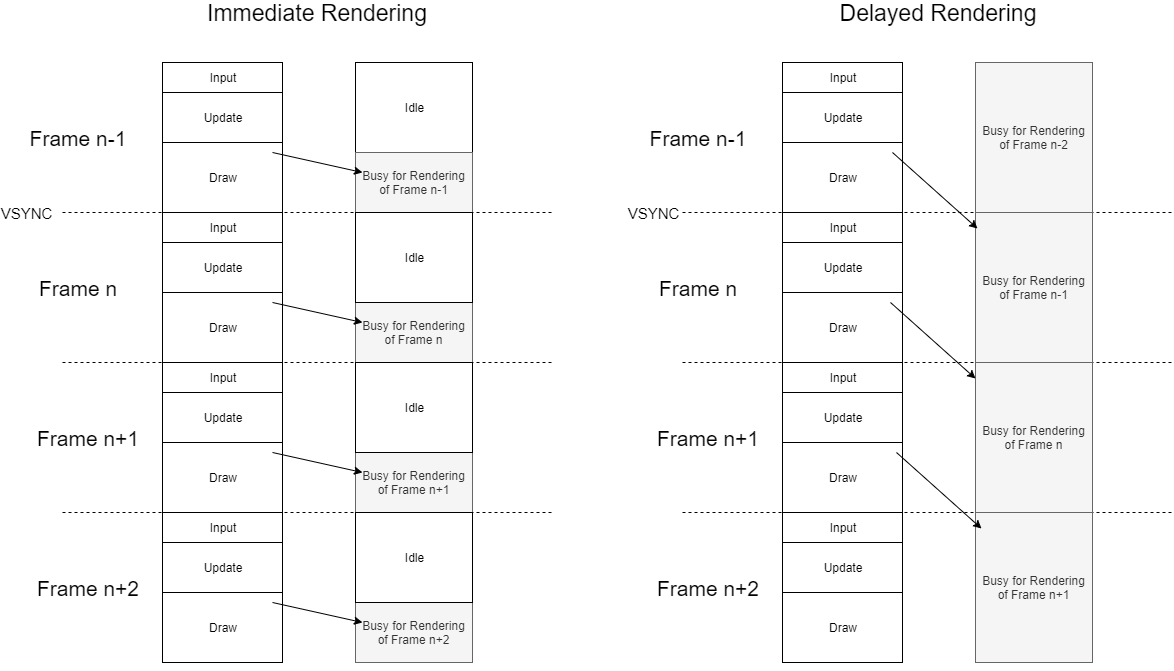
こうしたDelayed Renderingは、実はPS4などのコンソールゲーム機でよく見られるものです。この遅延レンダリング、なんだか面倒そうですが、何がメリットなのでしょうか。図をもう一度見てください。
即時レンダリングの弱点
即時レンダリングでは、レンダリングループが回る中、描画ライブラリの内部処理(シーングラフの更新やら物理計算やら)が終わって、ようやく描画命令(GL系ならglDrawElements呼び出しなど)に入ります。しかも、それらの描画命令がGPUに送られて実行されるのは、glFlushやglFinishを呼ぶか、バッファがスワップされる直前のタイミングになってからです。大抵、ここまでで数~十数ミリ秒は時間がかかります。仮に60FPSでの動作が期待されるとしましょう。60FPSの場合、1フレームは約16.6ミリ秒(msec)です。前述のお膳立て処理に10msecかかっていたとしたら、残り6.6msec位でGPUは処理を完了させないと60FPSを達成できなくなってしまいます。
つまりImmediate Renderingでは、描画をするための「お膳立て処理」(入力処理やアプリケーションロジック処理など)はさっさと終えないと、その間GPUが命令待ちのアイドル状態になってしまい、描画に取り掛かる頃にはフレームレート維持のための残り時間が不足してしまうのです。
遅延レンダリングの強み
一方で、Delayed Renderingでは、あえて描画をループ一周遅延させることで、ループの開始時点にすでに必要な描画命令データがはじめから揃っている状況を作り出せます。
ここで出てくるのが、「フレーム」という概念です。FPS(フレーム・パー・セカンド)のフレームですね。
一般的な低レベルAPIでは作成したコマンドバッファをフレーム間をまたがって利用することができます。
Delayed Renderingではある程度のフレーム遅延を許容することで、CPU側は「描画のためのお膳立て処理」のために、遅延フレーム分の時間的余裕を獲得できます。また、GPUにとってみても命令をただ待つだけのアイドル時間が消滅し、ほぼ1フレーム分まるまる描画処理に専念することができます。
つまり、Delayed Renderingでは、CPUとGPUをあわせた全体のスループットが向上することになるわけです。
さっきの図をもう一度見てみましょう。
具体的には、未来であるn+1フレーム目(n+1回目のレンダリングループ)で描きたいシーンの描画コマンドを、現在のnフレーム目のCommandBufferとして作っておくのです。そしてn+1フレーム目の最初でCommandBufferをコミットしてGPUに(nフレーム目の内容の)描画を実行させます。
このアプローチ、1フレームの遅延ならまるまる1フレーム分(60FPSなら約16.6msec)お膳立て処理に時間を費やせるといって良いでしょう。もし、2フレーム分の遅延でも許容できるなら……? 2フレーム分も描画までに猶予時間を持ってCPU処理を行えますね(ただし、2フレーム以上遅れる場合は、マルチコアを活用して各フレームの処理を時間差で同時にこなすべきでしょう。一種のパイプライン的処理ですね)。
8
さて、WebGPUでは、プログラマが描画命令をコマンドバッファという「データとして直接扱える」性質上、このDelayed Renderingの仕組みを意図的に作れる可能性を秘めています。
可能性、と言いましたが、実は現時点のWebGPUで試したところ、まだCommandBufferレベルでは駄目でした。というのも、今のWebGPUでは作成したCommandBufferのrequestAnimationFrameループの回数をまたいだ利用をしようとするとエラーになってしまいます。私のWebGPU APIの仕様への理解不足か、Chromeの実装がまだ安定していないかはわからないのですが、いずれできるようになるといいですね。あるいは、CommandBufferの再利用がサポートされる必要があるのかもしれません。
CommandBufferの再利用については、詳しくはWebGPUのこのIssueを御覧ください。
Issueを読むとわかりますが、Vulkan, Direct3D 12, Metal2では、コマンドバッファを再利用できる機能がそれぞれ備わっています。しかし全てのハードウェアで利用できるわけではありません。
WebGPUはWebブラウザという比較的ハード要件が保守的なプラットフォームですので、すぐにこれらをバックエンドにして採用できない事情もあると思われます。
しかし、時間の問題と言えるでしょう。いずれはこれらを抽象化したコマンドバッファの再利用を使えるようになるでしょう。
現時点で確約はできないですが、将来的にCommandBuffer単位でのDelayed Renderingも実装可能になる将来も近い と期待しています。9
2023/07/31更新
RenderBundleという形でコマンドバッファの再利用が可能になりました!
2021/07/20更新:「Delayed RenderingはWebGPUでサポートされない!?」
この節で訴求していることの訂正になります。7月13日に行われたWebGL + WebGPU Meetup 2021 Julyの動画セッションでZoom中に質疑応答の機会があり、「WebGPUで上記のフレーム非同期のDelayed Renderingは可能か、現在無理だとしたらいつできるようになるか」という質問をしたところ、ありがたくもWebGPUの策定を行っているコアメンバーの方が回答してくれました。
結論から言うと 「サポートされる見込みは今のところない」 という、この記事の意味が少々失われそうな残念な返答が返ってきてしまいました。
ネイティブAPIと異なり、ブラウザ上で実行されるWebGPUはHTMLとのコンポジット処理なども処理タイミングとして複雑に関係してくるため、プラットフォームやブラウザ種類によって実装が様々な現状において、実現には多くの技術課題が存在するとのことです。
そもそも、上記のようなネイティブコンソールゲームでのフレーム非同期Delayed Renderingについては、あまりWebGPU策定メンバーの関心事ではなさそうです。ということは、そのあたりを考慮しての策定(または少なくとも実装)自体がまだ行われていない可能性が高いと思われます。
このあたり、私が変に期待しすぎてしまったのかもしれません。この記事を見て「WebGPUすごい。もうゲーム機と同じじゃないか」と思った方、ぬか喜びさせてしまって申し訳ありませんでした。まぁDelayed Renderingについての意見も今回で伝わったと思いますし、いずれは検討がされていく可能性もあるとは思いますが、Web3Dがゲーム機と同じ土俵に足をつけるのにはもう少しかかりそうです。
WebAssembly, SIMD, Multi-Thread
ここまで説明してきたWebGPUですが、しかしこのWebGPUだけが出てもまだ片手落ちです。
WebGPUは現状まだJavaScriptからしか呼び出せないようですが、いずれはWebAssembly(WASM)から直接呼び出せる時代が来るでしょう。WebAssemblyによる高速・安定したコード実行性能、Multi-ThreadやSIMDなどが揃って、ようやくWebGPUにとっての足かせ(CPU側の遅さ)が取り払われるといっていいでしょう。WebGPUならば、複数スレッドからコマンドバッファをキューイングできるようにもいずれなるはずです。
WebGPUとそうした周辺環境が整って、Web3Dでもますますリッチなコンテンツ表現やサービスが実現可能になりそうです。希望的観測ですが、ゆくゆくは発展型の頂点系シェーダステージやハードウェアレイトレーシングの利用などもサポートされるようになっていくと思います。
最後に
能書きばかりで全く具体的でない、話題も極端に偏っているまさにポエム・オブ・ポエムが出来上がってしまい流石に頭を抱えています。ちっ、しかも今日はイブだぜ?orz
ま、まぁ……数年後、どれほどリッチな3DコンテンツをWebで体験できるようになるのか……今からワクワクしますね!(フォロー
-
WebGLでも単純な1つの物体を表示するだけ(マテリアルjや描画先を切り替える必要がない要件)なら、これらを毎フレーム呼ぶ必要はありません。しかし、ある程度の規模の一般的な3Dプログラムでは様々な描画条件を切り替える必要が発生しますから、実質的には毎フレーム呼ぶのが普通です。 ↩
-
念の為を言うと、裏技的な方法でWebGL1でも頂点シェーダーとピクセルシェーダーの合わせ技でスキャター操作ができます。しかし、ポイントプリミティブを使ったり、長方形の2D矩形を描画してアルファテストやアルファブレンディングを駆使したりして、レンダーターゲット上の必要なピクセルを上手く狙い撃ちして値を更新するという、かなりトリッキーな方法です。ComputeShaderが使えるようになりつつある今となっては消えゆく方法でしょう。また、OpenGL4.xのピクセルシェーダーでは低速ながらもスキャターができるという話を聞いたこともありますが、そのへんは私はあまり詳しく知りません。 ↩
-
最近のDirect3Dなどでは読み込みと書き込みを同時に行える機能もあるようです。残念ながら詳しくは私は知りません。 ↩
-
レンダーターゲットテクスチャを2枚用意して、片方を読み込み用、もう片方を結果の書き込み用にします。一度レンダリング(書き込み)が終わったら、それぞれの役割を交代してまたレンダリング(書き込み)します。これを繰り返すことでGPUによる計算を行えます。俗にピンポンテクニックとも呼ばれます。 ↩
-
ComputeShaderについては、WebGL2でもサポートが予定されているようですね。Indirect描画なども、おいおい入ってくるのかもしれません。 ↩
-
現時点のGPUの頂点パイプラインは、ステージ数が複雑になり、また途中の頂点の分割や生成過程を経て後段になるほどジオメトリ負荷が予想以上に大きくなるなど、改善の余地が残っています。実際、AMD社は従来の頂点パイプラインを整理・改善したPrimitive Shaderを提案し、また対するNVIDIAも2018年にMesh Shaderを提案しました。結局Direct3D12ではNVIDIAのアプローチであるMeshShaderが採用されています。 ↩
-
ここでいう「遅延」は、ライトを大量に処理することができるDeferred Shading(遅延シェーディング)技法や、モバイル端末GPUで採用されているGPUのレンダリング方式であるタイルベース遅延レンダリングとは別の意味ですので、誤解しないでください。また、APIの設計としてのImmediate ModeとRetain Modeの比較関係ともまた別の話です。 ↩
-
実は、映像の出力先である液晶ディスプレイやテレビなどにもフレーム遅延があります。現在のディスプレイは解像度変換や画質調整などの数々の高度な映像処理を行っており、その処理時間を確保するためそうせざるを得ないのです。ただ、遅延が大きいと即応性が求められるジャンルのゲームコンテンツのプレイなどに影響が出るため、ディスプレイ製品の中には「ゲームモード」といった低遅延モードを用意しているものもあります。 ↩
-
Issueにもありますが、再利用可能なコマンドバッファは、一度GPUのネイティブコマンドに変換された状態で再利用が可能という速度的なメリットもあります。 ↩