Fisher情報量と共分散行列
本稿では、「Practical Statistics for Astronomers」の第6.1節に基づき、データがパラメータについてどれほどの情報を持っているかを表すFisher情報量の概念をわかりやすく導入します。
そして、それが最尤推定量のばらつき(共分散行列)とどのように結びついているのか、その美しく自然な数学的構造を追っていきます。
データ分析において未知のパラメータを推定する「最尤推定(Maximum Likelihood Estimation)」は基本かつ強力なツールです。しかし、推定値を求めて終わりではありません。
観測データには必ずノイズが含まれるため、この推定結果はどれくらい信用できるのかを知ることは、推定そのものと同じくらい重要です。
本記事では、データがパラメータについてどれほどの情報を持っているかを表すFisher(フィッシャー)情報量の概念と、それが最尤推定量のばらつき(共分散行列)とどのように結びついているのか、その概要を解説します。
詳細な解説資料のご案内
厳密な数式展開や、ガウス分布を用いた分かりやすい具体例など、より深い内容については以下のPDFにまとめています。詳細を知りたい方はぜひこちらをご覧ください。
👉 PDF:Fisher情報量と共分散行列
1. スコア関数とFisher情報量
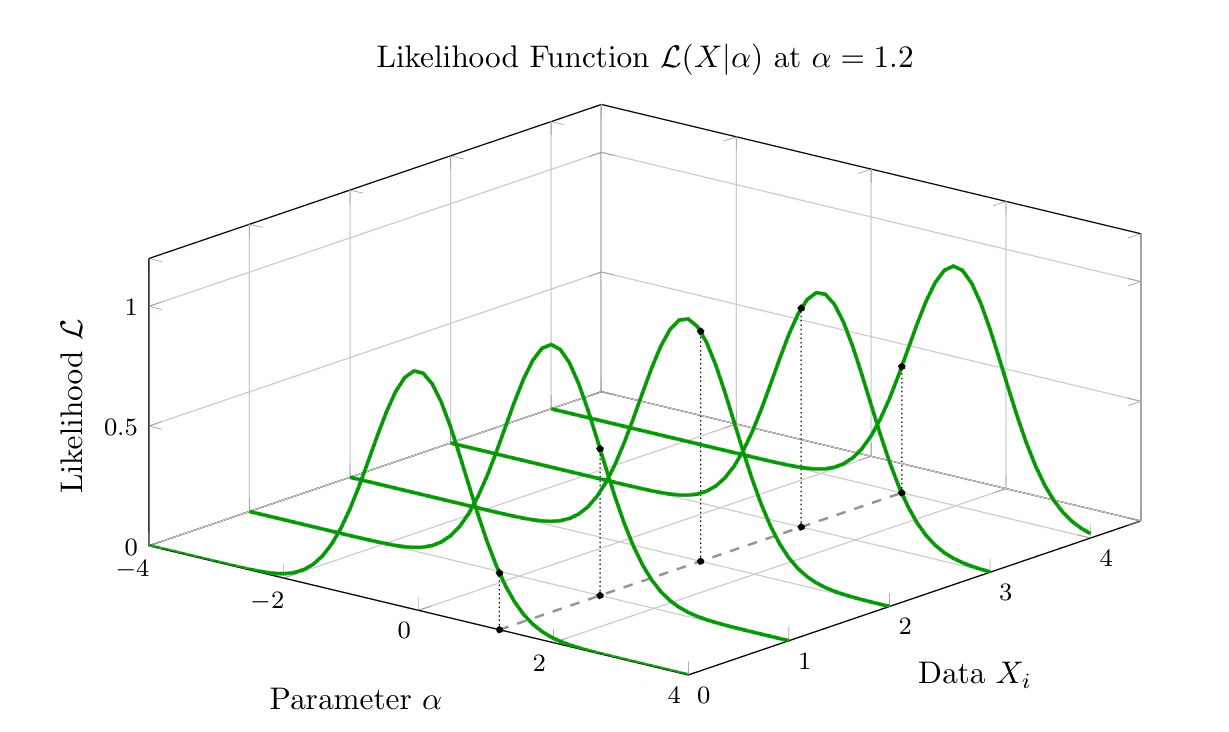
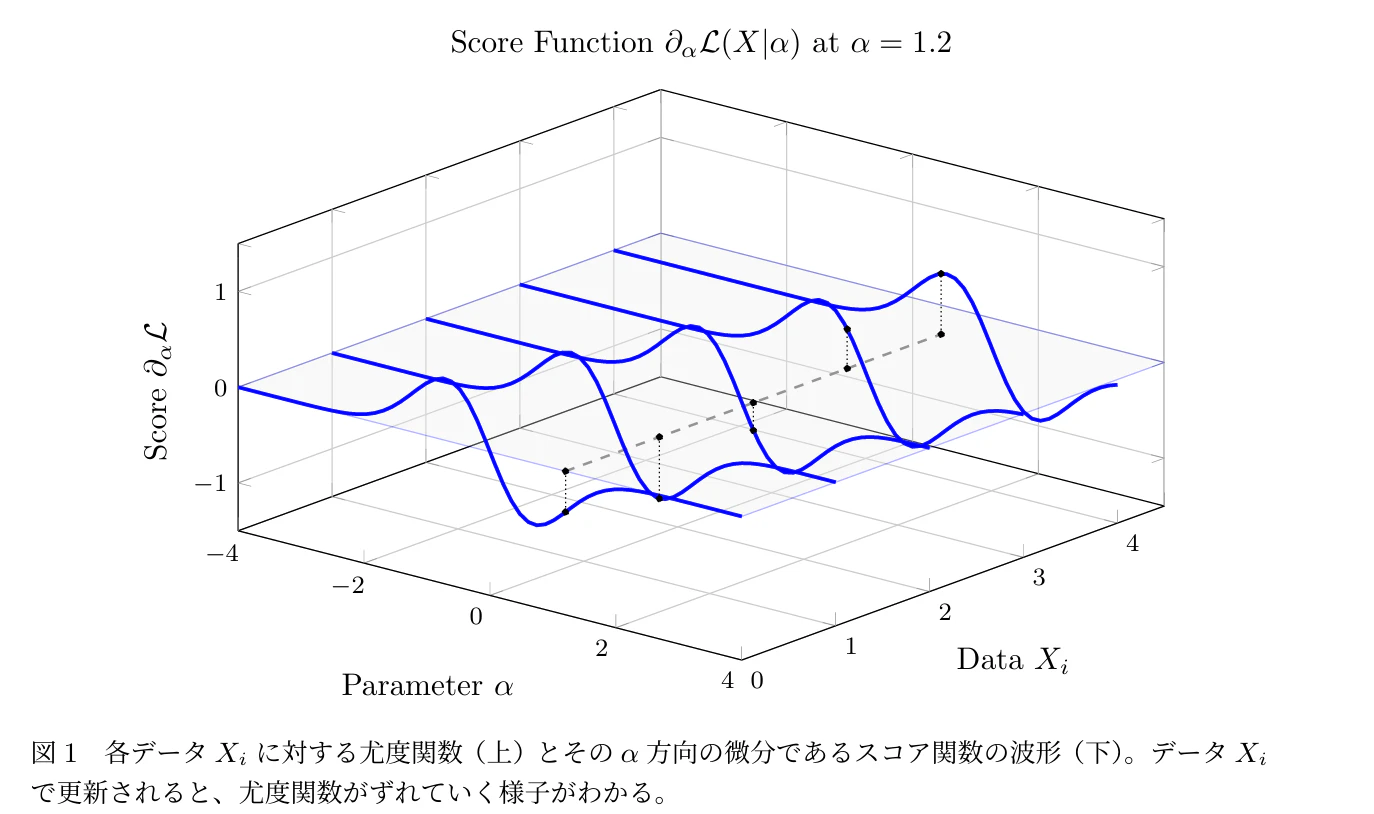
あるデータ $X$ が得られたとき、未知パラメータ $\vec{\alpha}$ の「もっともらしさ」を表すのが尤度関数です。この山の頂点(最大値)を探すため、対数尤度関数の1階偏微分をスコア関数(Score function) $s_j$ と定義します。
$$
s_j(X_i) = \frac{\partial \ln P(X_i | \vec{\alpha})}{\partial \alpha_j}
$$
スコア関数は「パラメータを増やすべきか減らすべきかの道標(傾き)」です。理論上、このスコア関数の期待値(平均)はゼロになります。
しかし、データがパラメータについて「多くの情報を持っている」状態、すなわち尤度関数の山が鋭い状態では、少しパラメータを動かしただけで傾きが激しく変動します。このスコア関数の分散こそが、Fisher情報量の定義です。
数学的な変形(※詳細はPDF参照)により、1つのデータが持つFisher情報量 $i_{jk}$ は、対数尤度関数の2階微分(曲率)の期待値として表すことができます。
$$
i_{jk} = - E\left[ \frac{\partial^2 \ln P}{\partial \alpha_j \partial \alpha_k} \right]
$$
2. データセット全体への拡張とヘッセ行列
実際の観測では、$N$ 個の独立なデータセットを得ます。全データから計算される対数尤度関数の2階微分をヘッセ行列(Hessian matrix)$\mathcal{H}$ と呼びます。これは「実際の尤度の山の曲率」そのものです。
全データのヘッセ行列の期待値(の符号反転)をとると、データセット全体が持つFisher情報行列 $F$ と等しくなります。
$$
F_{jk} = -E[\mathcal{H}_{jk}]
$$
情報量は、データを集めれば集めるほど増えていくという直感的な結果を示しています。
3. Fisher情報行列の逆行列が共分散行列になる
データ数が十分に大きいとき、最尤推定量は真のパラメータの周辺に多変量ガウス分布としてばらつきます(中心極限定理・ラプラス近似)。
対数尤度関数をピーク付近でテイラー展開し、ガウス分布の確率密度関数の定義式と比較すると、非常に美しい結論が導かれます。我々が知りたいパラメータ推定値の誤差(共分散行列 $C$)は、Fisher情報行列 $F$ の逆行列になるのです。
$$
C = F^{-1} = (-E[\mathcal{H}])^{-1}
$$
尤度関数のピークが鋭い(Fisher情報量が多い)ほど、パラメータの推定誤差は小さくなります。これは、最尤推定量が理論上最も分散の小さい推定量であるという「クラメール・ラオの限界(Cramér-Rao bound)」の直感的な正当性を示しています。
さらに詳しく知りたい方へ
「なぜスコア関数の期待値はゼロになるのか?」「ラプラス近似から共分散行列を導出する過程はどうなっているのか?」「1次元ガウス分布の平均を推定する場合の具体例」など、数式の行間を丁寧に追った完全版は、以下のPDFで公開しています。
PDF:Fisher情報量と共分散行列