注意: 以下のクエリはPostgreSQLにより動作確認を行っています。
postgres=# select version();
version
-------------------------------------------------------------
PostgreSQL 9.6.1, compiled by Visual C++ build 1800, 64-bit
(1 行)
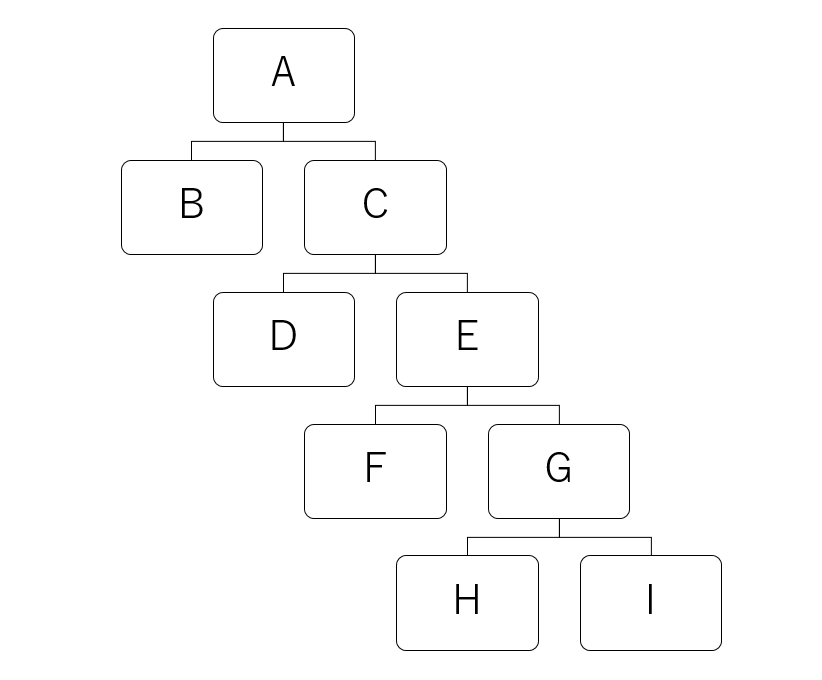
上のような木構造のデータを次のように表現したとします。
id | parent
------------+------------
A |
B | A
C | A
D | C
E | C
F | E
G | E
H | G
I | G
つまり自分自身と自分自身の親を示す情報を隣接リスト風に持っておくわけですね。__このような構造のテーブルはナイーブツリー(Naive Tree)などと呼ばれ、有名なアンチパターンのひとつ__なのですが、アンチパターンだからといって設計を見直したりなどできないのが「システムエンジニア」の悲しいところ。それはさておき、親や子を再帰的に取得するクエリは「再帰クエリ」(with-recursive)を利用して次のように書くことができます。
-- treeテーブルを生成&初期化する。
create table tree (
id char(10) not null primary key,
parent char(10)
);
insert into tree values
('A', null),
('B', 'A'),
('C', 'A'),
('D', 'C'),
('E', 'C'),
('F', 'E'),
('G', 'E'),
('H', 'G'),
('I', 'G');
-- id = 'I'の先祖をたどるクエリ。
with recursive ancestor (depth, id, parent) as (
select 0, tree.id, tree.parent from tree where tree.id = 'I'
union all
select
ancestor.depth + 1,
tree.id,
tree.parent
from ancestor, tree
where ancestor.parent = tree.id)
select depth, id from ancestor order by depth;
/*
depth | id
-------+------------
0 | I
1 | G
2 | E
3 | C
4 | A
(5 行)
*/
-- id = 'C'の子供の一覧を取得するクエリ。
with recursive child (depth, id, parent) as (
select 0, tree.id, tree.parent from tree where tree.id = 'C'
union all
select
child.depth + 1,
tree.id,
tree.parent
from tree, child
where tree.parent = child.id)
select depth, id from child order by depth;
/*
depth | id
-------+------------
0 | C
1 | D
1 | E
2 | F
2 | G
3 | H
3 | I
(7 行)
*/
今回は単なるselectだったので、簡単にクエリを書くことができましたが、updateやdeleteとなると途端に複雑化します。また再帰を利用するため、階層が深くなってくるとパフォーマンスのことも考える必要がありそうです。一見するとシンプルだが、実際の運用はかなり大変。このあたりがアンチパターンたるゆえんでしょうか。
なおMySQLのように「再帰クエリ」をサポートしていないDBMSを利用している場合は――あきらめましょう(´・ω・`) とはいえ「再帰クエリ」は標準SQLの反中なので、将来的サポートされる可能性が高い構文ではあります。