SMTソルバと情報量(エントロピー)計算を組み合わせたWordleソルバ
最近流行の単語当てゲームWordle(ちょっと乗り遅れた?)について,SMTソルバと平均情報量を用いる,ヒューリスティクスに頼らない手法でナイーブに書いてみた。ざっと日本語で検索した限り,同じような手法を使っている例が見つからなかったので,簡単にここに記しておく。
なお,Wordleのソルバに関する情報は,以下のリンクを参照
- https://xcloche.hateblo.jp/entry/2022/01/24/212558
- https://gigazine.net/news/20220129-the-best-strategies-for-wordle/
アルゴリズムの概要
前提として,
- 答えとなる単語 $A_i (1\leq i\leq 2315)$, 入力可能なすべての単語 $W_i(1\leq i\leq 12972)$は既知のものとする。
-
これまでのトライと得られたヒントの一覧を用いて,現時点(第$n$ラウンド)で答えの可能性がある単語リスト $C (\subset A)$を,SMTソルバ(Z3を使う)で求める。
-
あるトライ(単語の入力)に関して,トライから得られるヒント(黒・黄・緑の色分けの情報)の平均情報量(エントロピー)が最大となるようなトライ $w$ を一つ,入力可能なすべての単語から選択する($w \in W$)。エントロピー$E$とは,ヒントのすべての可能性$H_i (1 \leq i \leq 3^5)$ (「黒黒黒黒黄」,「黒黒緑黄黒」など,全部で$3^5$通り) について以下の和で定義される。
E=-\sum_{x \in H_i}p_i \log_2 p_i
ここで$p_i$は,今回のラウンドにおいてヒント$H_i$が得られる確率($C$のうち,ヒント$H_i$を与えるような単語数)/($C$のすべての単語数)である。このステップは要するに,得られるヒントによって振り分けが最も効率よくできるようなトライを選択する,ということである。
3. $w$を入力して,ヒントを得る。
1-3を繰り返すことで絞り込みを行う。
コード
コード(Python)の主要部分は以下のようになる。SMTソルバとしてZ3を使用している。
(こちらのGistに全ソースコードを掲載。)
from z3 import *
RIGHT = "o"
MISPLACED = "-"
WRONG = "x"
def calculate_entropy(counts):
vs = np.array(list(counts.values()))
probs = vs / np.sum(vs)
e = np.sum(-probs * np.log2(probs))
return e
def get_candidates(s, v):
res = s.check()
if res == unsat:
# print('No answer')
return []
answers = []
while res == sat:
m = s.model()
answer = to_s(m, v)
answers.append(answer)
block = []
for i in range(5):
block.append(v[i] != m[v[i]])
s.add(Or(block))
res = s.check()
return sorted(answers)
def get_counts(candidates, guess):
counts = {}
func = calculate_hint(guess)
for answer in candidates:
s = func(answer)
if s not in counts:
counts[s] = 0
counts[s] += 1
return counts
def get_entropies_for_guesses(candidates_for_guessing, candidates_for_answer):
entropies = []
for guess in candidates_for_guessing:
counts = get_counts(candidates_for_answer, guess)
e = calculate_entropy(counts)
entropies.append([guess, e, counts])
entropies = sorted(entropies, key=lambda a: -a[1])
return entropies
def get_recommended_try(response_history, verbose=False):
global all_answers_words5, all_possible_words5
solver, vals = create_solver(all_answers_words5, response_history)
candidates = get_candidates(solver, vals)
print(
"Total %d candidates" % len(candidates)
+ (": " + ", ".join(candidates) if len(candidates) <= 100 else "")
)
if len(candidates) == 1:
print("Found answer: ", candidates[0])
return None
entropies1 = get_entropies_for_guesses(candidates, candidates)
if verbose:
print()
print("Entropies top 3 from possible answer words")
for e in entropies1[0:3]:
print(e)
entropies2 = get_entropies_for_guesses(all_possible_words5, candidates)
if verbose:
print()
print("Entropies top 3 from all words")
for e in entropies2[0:3]:
print(e)
# candidatesとall_possible_words5の中から,エントロピーが最大になるものを選ぶ
# エントロピーがほぼ同じだったら,正解になり得る単語 candidates を優先
suggested = (
entropies2[0][0]
if entropies2[0][1] > entropies1[0][1] + 0.001
else entropies1[0][0]
)
return suggested
def main():
global initial_guess, all_answers_words5, all_possible_words5
response_history = []
if initial_guess is None:
initial_guess = find_initial_guess()
suggested = initial_guess
count = 0
while True:
count += 1
print("Round %d:" % count)
guess = input_actual_try(suggested)
hint = input_hint()
if hint == RIGHT * 5:
print("Answer found.")
break
response_history.append([guess, hint])
suggested = get_recommended_try(response_history)
if suggested is None:
break
print("Done.")
if __name__ == "__main__":
main()
走らせてみるとわかるが,計算時間は合計数秒以内といったところで,実用上,十分に早い。
ソルバの成績
答えとなり得る全2315語について,何ラウンドで正解に達するかをテストした(使用したコード
)。
結果
正解までのラウンド数の分布は以下のようになった。平均3.4821回で,すべて5回以内,93%が4回以内に収まっている。
人が解いた成績 https://twitter.com/WordleStats よりは成績が良さそうだ。
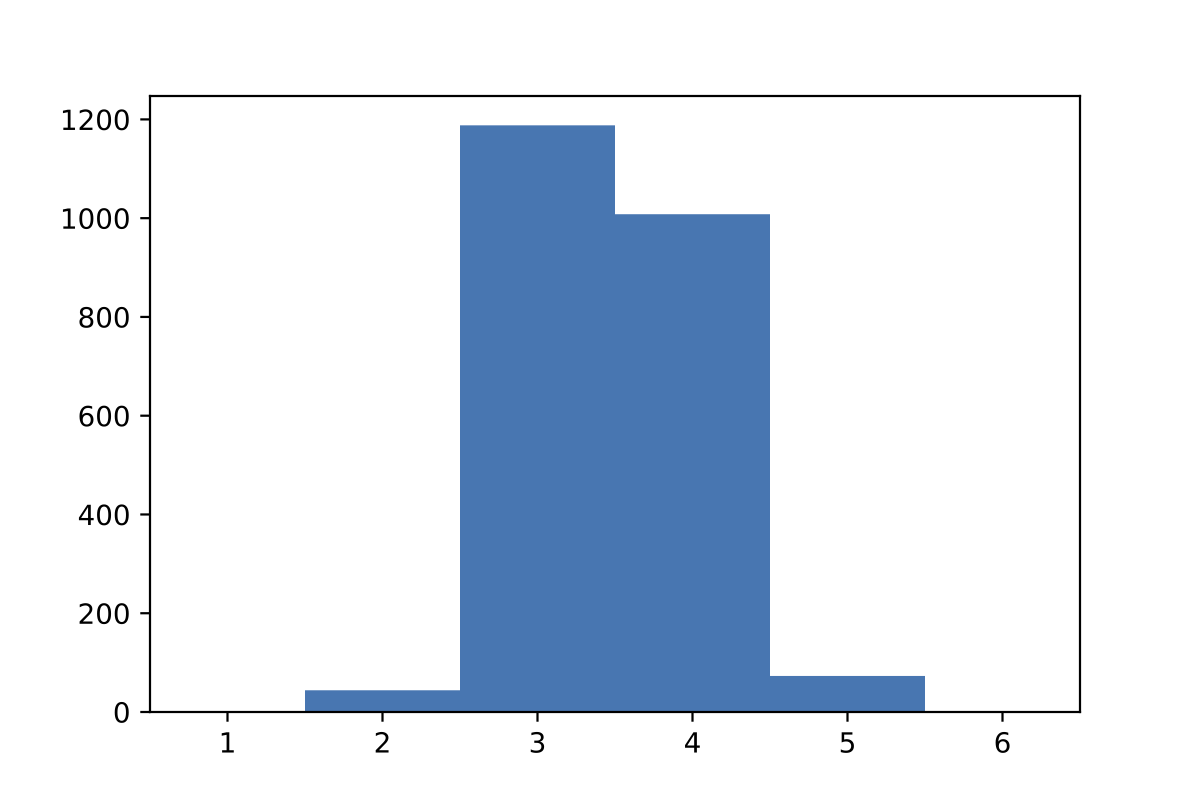
ちなみにこのアルゴリズムだと,初手はsoareとなるのだが,初手を適当に変えてみると,当然ながら多少成績も変わるだろう。それが以下の結果。
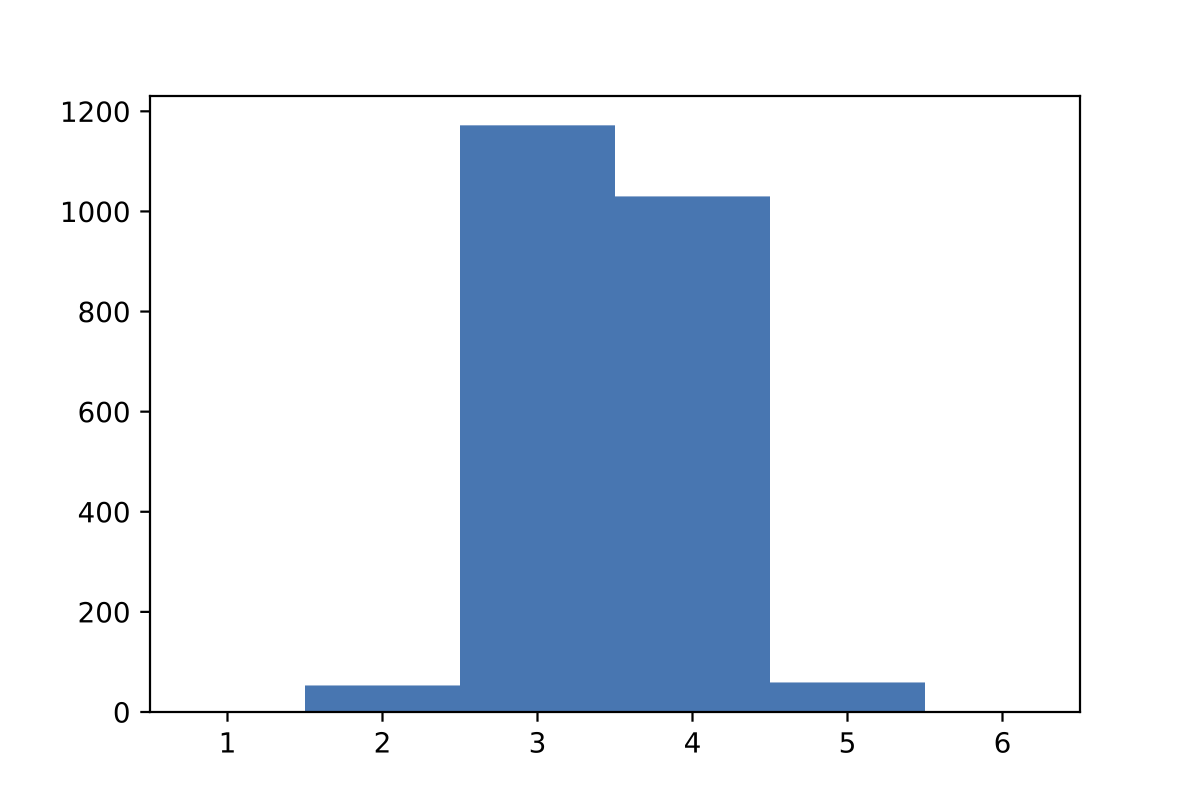
初手がtaresの場合
taresはこちらで求められた初手。
→ 平均3.4743回となった。上記のsoareよりわずかに成績が良くなった。
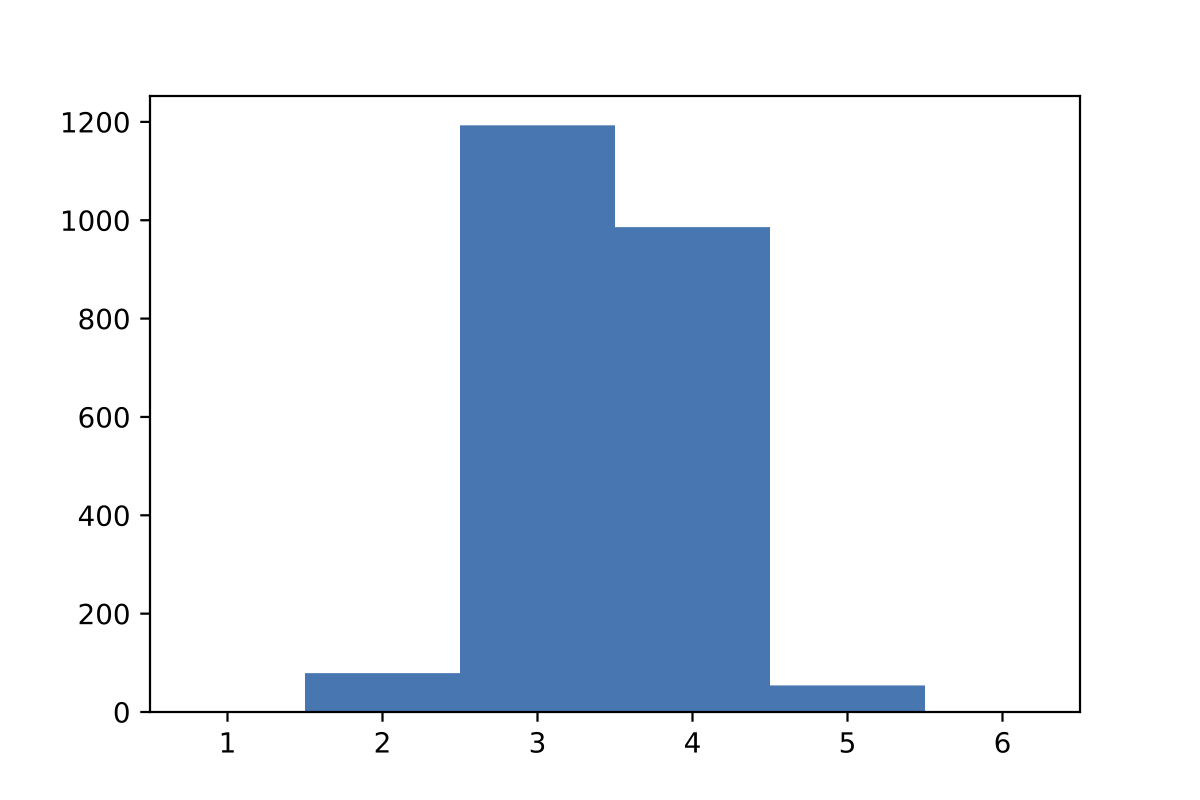
初手がsaletの場合
saletはここで紹介されている初手。
→ 平均3.4423回となった。さらに成績が良くなった。
ちなみにこのsaletを初手とした人のアルゴリズムも,平均3.42回とのことなので,それと比べてもナイーブな実装でもわりといい線を行っていると言える(初手の選択変更はこのアルゴリズム自体から導けないので,ちょっとズルになる。初手選択時にエントロピーが最大であるのがsoareだが,それ以外の上位数件について平均値を計算し,その中でベストのものを選ぶ,というのであればズルにはならない。)
まとめ・備考
SMTソルバによる候補の絞り込みと,エントロピー最大の候補を求めることを交互に繰り返すことで,そこそこ良い成績のソルバを作ることができた。
なお,今回アルゴリズムについては,先読み(一つ先のトライについての考慮)は行っていない。先読みするともう少し精度が上がりそうだが,先読みした場合のエントロピーの計算はどうしたらいいのか,また,計算量的に現実的なのかどうか,よくわからない。
ちなみに,ここにソルバのランキングも作られていた https://freshman.dev/wordle/#/leaderboard