GCIデータサイエンティスト育成講座
「GCIデータサイエンティスト育成講座」は、東京大学(松尾研究室)が開講している"実践型のデータサイエンティスト育成講座およびDeep Learning講座"で、演習パートのコンテンツがJupyterNoteBook形式で公開(CC-BY-NC-ND)されています。
Chapter4は「確率と統計の基礎」で、確率と統計の基礎知識を習得していきます。
日本語で学べる貴重で素晴らしい教材を公開いただいていることへの「いいね!」ボタンの代わりに、解いてみた解答を載せてみます。間違っているところがあったらご指摘ください。
Chapter4 確率と統計の基礎
4.1 確率・統計の基礎
4.1.1 確率
<練習問題 1>
コインの表裏をそれぞれ0と1に対応させるデータを作成してください。また、コイン投げの試行を1000回した時の、表裏のそれぞれの出る確率を実装してください。
from numpy import random
random.seed(0)
coin_data = np.array([0,1])
toss_steps = 1000
all_coin_data = random.choice(coin_data, toss_steps)
print(len(all_coin_data[all_coin_data==0])/len(all_coin_data))
print(len(all_coin_data[all_coin_data==1])/len(all_coin_data))
> 0.496
> 0.504
<練習問題 2>
くじ引きの問題を考えます。1000本のくじの中に、100本のあたりがあるとします。AくんとBくんが順にくじを引き、AくんとBくんともにあたりを引く確率を求めてください。ただし、引いたくじは戻さないとして、それぞれ1回のみ引きます。(これは手計算でも大丈夫です。)
(1) 理論値
Aくんがあたりを引く確率 = \frac{100} {1000} = \frac {1} {10}\\
Bくんがあたりを引く確率 = \frac{100} {1000} \times \frac{99} {999} + \frac{900} {1000} \times \frac{100} {999} = \frac {1} {10}
(2) シミュレーション
from numpy import random
kujiStepNum = 100000
Akun_atariNum = 0
Bkun_atariNum = 0
kujiChecker = lambda x: 1 if x < 100 else 0
for i in range(kujiStepNum):
random.seed(i)
kuji_data = np.arange(1000)
Akun_kuji = random.choice(kuji_data)
Akun_atariNum += kujiChecker(Akun_kuji)
kuji_data = np.delete(kuji_data, Akun_kuji)
Bkun_kuji = random.choice(kuji_data)
Bkun_atariNum += kujiChecker(Bkun_kuji)
print("Aくんがあたりを引く確率: ", Akun_atariNum / kujiStepNum)
print("Bくんがあたりを引く確率: ", Bkun_atariNum / kujiStepNum)
> Aくんがあたりを引く確率: 0.09981
> Bくんがあたりを引く確率: 0.0988
<練習問題 3>
日本国内である病気(X)になっている人の割合は、0.1%だとします。Xを発見する検査方法について、次のことがわかっています。
・その病気の人がその検査を受けると99%の人が陽性反応(病気であることを示す反応)を示します。
・その病気でない人がその検査を受けると3%の人が陽性反応を示します。(誤診)
日本に住んでいるある人がこの検査を受けたら陽性反応を示しました。この人が病気Xである確率は何%でしょうか?(これは手計算でも大丈夫です。)
# A1: 罹患率
# A2: 非罹患率
# B1: 陽性率
# B2: 陰性率
A1 = 0.001 # 罹患率
B1_A1 = 0.990 # 罹患者の陽性率
B1_A2 = 0.030 # 非罹患者の陽性率
# 陽性率
B1 = (A1 * B1_A1) + ((1 - A1) * B1_A2)
# 陽性者の罹患率
# A1_B1 = (B1_A1 * A1) / (B1_A1 * A1 + B1_A2 * (1 - A1))
A1_B1 = (A1 * B1_A1) / B1
print("被験者が病気Xを罹患かつ陽性の確率:", A1 * B1_A1)
print("被験者が病気Xを罹患していないかつ陽性の確率:", (1 - A1) * B1_A2)
print("陽性反応を示した被験者が病気Xを罹患している確率:", A1_B1)
> 被験者が病気Xを罹患かつ陽性の確率: 0.00099
> 被験者が病気Xを罹患していないかつ陽性の確率: 0.02997
> 陽性反応を示した被験者が病気Xを罹患している確率: 0.03197674418604651
4.1.2 確率変数と確率分布
<練習問題 1>
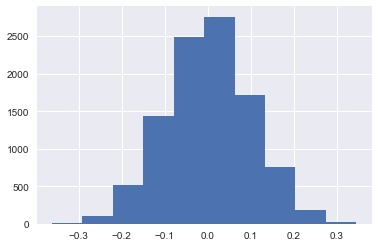
平均0、分散1の正規分布からn=100の標本抽出を10000回繰り返して、標本平均$\overline{X}=\frac{1}{n}\sum^n_{i=1}X_i$の標本分布(ヒストグラム)を描いてください。
random.seed(0)
x_barList = np.array([])
for i in np.arange(10000):
x = np.random.normal(0, 1, 100)
x_barList = np.append(x_barList, x.mean())
plt.hist(x_barList)
plt.grid(True)
<練習問題 2>
上記と同じく、対数正規分布の場合を実装してください。
random.seed(0)
x_barList = np.array([])
for i in np.arange(10000):
x = np.random.lognormal(0, 1, 100)
x_barList = np.append(x_barList, x.mean())
plt.hist(x_barList)
plt.grid(True)

<練習問題 3>
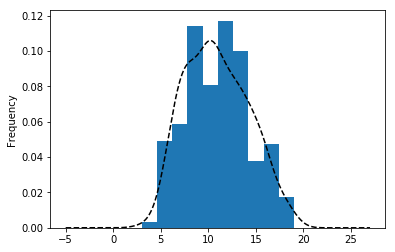
3章で用いたデータを使い、学生のデータの数学一期目の成績G1のヒストグラムとカーネル密度推定を描いてください。
student_data_math = pd.read_csv("student-mat.csv", sep=";")
student_data_math.G1.plot(kind='kde', style='k--')
student_data_math.G1.plot(kind='hist', density = True)
4.1.3 (応用)多次元確率分布
4.1.4 標本分布
<練習問題 1>
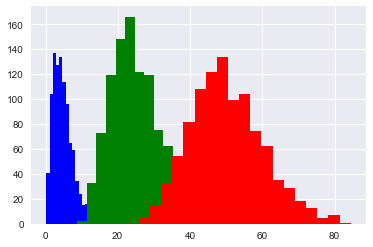
自由度5、25、50のカイ二乗分布からの乱数をそれぞれ1000個発生させて、ヒストグラムを書いてください。
random.seed(0)
for df, c in zip([5, 25, 50], "bgr"):
x = random.chisquare(df, 1000)
plt.hist(x, 20, color=c)
<練習問題 2>
自由度100のt分布からの乱数を1000個発生させて、ヒストグラムを書いてください。
random.seed(0)
x = random.standard_t(100, 1000)
plt.hist(x)
plt.grid(True)

<練習問題 3>
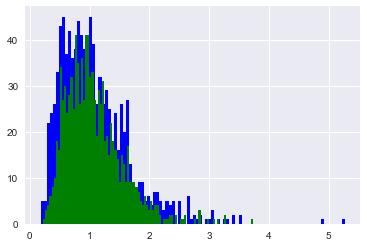
自由度(10, 30)、(20, 25)のF分布からの乱数をそれぞれ1000個発生させて、ヒストグラムを書いてください。
random.seed(0)
for df, c in zip([(10, 30), (20, 25)], "bg"):
x = random.f(df[0], df[1], 1000)
plt.hist(x, 20, color=c)
4.1.5 統計的推定
<練習問題 1>
平均 𝜇 で分散 𝜎2 の正規母集団から大きさnの標本から作った標本平均は、母平均であることが望ましく、この不偏性を示してください。(手計算で大丈夫です。)
(1) 証明
標本平均の期待値は母平均に一致する
(2) シミュレーション
random.seed(0)
heikin = 0
bunsan = 1
N = 10**5
n = 10**4
def getBoHeikinHyohonHeikin(heikin, bunsan):
boSyudan = random.normal(heikin, bunsan, N)
boHeikin = boSyudan.mean()
hyohonHeikin = []
for i in [1, 2, 3, 4, 5]:
random.seed(i)
hyohon = random.choice(boSyudan, n)
hyohonHeikin = np.append(hyohonHeikin, hyohon.mean())
return boHeikin, hyohonHeikin
boHeikin, hyohonHeikin = getBoHeikinHyohonHeikin(heikin, bunsan)
print("母平均: ", boHeikin)
print("標本平均: ", hyohonHeikin)
母平均: 0.0015767005081253399
標本平均: [-0.001 0.007 0.011 0.008 -0.011]
<練習問題 2>
あるコインを5回投げたとして、裏、表、裏、表、表と出ました。このコインの表が出る確率を 𝜃 として、これを推定してください。(手計算で大丈夫です。)
coin_examData = np.array([0,1,0,1,1])
print("確率θ: ", coin_examData.sum()/len(coin_examData))
確率θ: 0.6
<練習問題 3>
母集団が以下の指数分布に従っている時に、そこから大きさnの標本${X_1, X_2, ...X_n}$を得たとして、母数${\lambda}$を最尤推定してください。(手計算で大丈夫です。)
$f(x|\lambda) = \lambda \mathrm{e}^{-\lambda x}$
なんやかんや積分するらしい
\lambda = \frac{n}{\sum^n_{i=1}x_i}
4.1.6 統計的検定
<練習問題 1>
上記と同じデータで、数学とポルトガル語の成績のG2のそれぞれの平均について、差があると言えるでしょうか。また、G3はどうでしょうか。
t2, p2 = stats.ttest_rel(student_data_merge.G2_math, student_data_merge.G2_por)
t3, p3 = stats.ttest_rel(student_data_merge.G3_math, student_data_merge.G3_por)
print( "G2 p値 = ", p2, " (<<0.05)")
print( "G3 p値 = ", p3, " (<<0.05)")
> G2 p値 = 4.0622824801348043e-19 (<<0.05)
> G3 p値 = 5.561492113688385e-21 (<<0.05)
4.2 総合問題
4.2.1 推定と検定の問題
4.1.6 統計的検定で使用したデータ(student_data_merge)を使って、以下の問いに答えてください。
(1)それぞれの欠席数については、差があるといえるでしょうか。
(2)それぞれの勉強時間についてはどうでしょうか。
# (1)
t_absences, p_abcences = stats.ttest_rel(student_data_merge.absences_math, student_data_merge.absences_por)
print( "欠席数 p値 = ", p_abcences, " (<<0.05)")
# (2)
t_studytime, p_studytime = stats.ttest_rel(student_data_merge.studytime_math, student_data_merge.studytime_por)
print( "勉強時間 p値 = ", p_studytime, " (>0.05)")
欠席数 p値 = 2.3441656888384195e-06 (<<0.05)
勉強時間 p値 = 0.5643842756976525 (>0.05)