はじめに
前回の記事で、デプロイに失敗しており、まだWebアプリ化が終わっていないという話をしたと思う。
その後、諸々のバージョンを変更したり書き換えたりしてはプッシュしている内に、GitLFSが使えなくなった。
C:\dog_or_cat>git push origin main
Uploading LFS objects: 0% (0/2), 0 B | 0 B/s, done.
batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access.
error: failed to push some refs to 'https://github.com/username/dog_or_cat_app.git'
もはやプッシュすらさせてもらえないのは、これまでのエラーとは違った。
あまり意味が分からないまま、調べていると、GitLFSにも制限があるらしい。
1GB/月……なるほど。
エラーを解消しようと何度も何度もプッシュしたことで、解決策が見えてきたころには使い切っていたわけか。なるほど。
まあ良い機会だ。50MB以内で性能の良いモデルを作ってみようじゃあないか。
事業をやっているわけじゃないので、課金はしない。この条件下でやってやろう!
目標
- 50MB以下の犬猫分類モデルのh5ファイルを作る
- 予測精度はバリデーションデータで100%
- 予測精度はテストデータ20枚で95%以上
- 今度こそWebアプリを実装する
モデル変更の検討
まず、そもそも前の記事でモデルの比較を行ったわけだから、より小さいモデルを検討した。だが、モデルを変更することによって、他ファイルの書き換えも必要になるため、今回はとりあえずEfficientNetB0で、どこまで小さく正確なモデルを作れるか、戦ってみることにした。
簡単にモデルファイルを小さくする方法
比較的容易にモデルファイルを小さくすることができる方法を考えてみた。
まず、取り扱う画像の数・サイズだ。この二つは大きく影響が出そうだと思って試してみた。
結論から言うと、取り扱う画像の数(計1000枚)については、精度への影響が大きくてやめた。他を調整して精度の向上を試みたが、なかなか簡単にいかなさそうなのと、その割にファイルサイズに対する影響が小さかったからだ。
では、画像サイズ(リサイズする大きさ)を小さくしてみよう!
-
元のサイズ
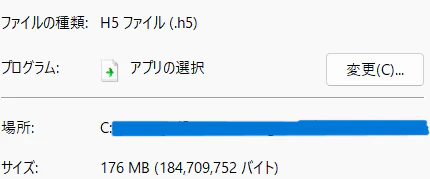
-
画像サイズを少し縮小

100MB近く小さくなった……!
ただし、予測精度は低くなったし、サイズもまだ50MB以上ある。
でも、画像サイズを小さくしながら、精度を上げていく方向性で良さそうだ。
予測精度
問題はこれだ。モデルのサイズを小さくするには、画像のリサイズを小さく小さくしていけば良いだろう。しかし精度が犠牲になる。それは困る。
-
画像サイズ100×100
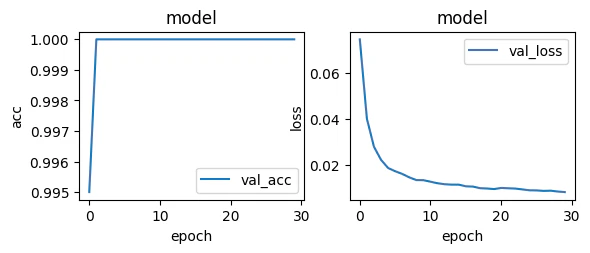
-
画像サイズ80×80

他を同じ条件にしたときの差だ。
今回は100×100を一つの目安にして調整していこう。
ちなみに、100×100での時にモデルサイズは80.469MBで、予測精度はクリアしていた。ただ、過学習疑惑もあり、モデルサイズもクリアしていないので、他の部分を調整していく。
バッチサイズ
これは予測精度を上げたり、過学習っぽさを軽減するために行った。特に今回は過学習っぽさが付いて回っていたので、小さくしてみた。様々経て、50にしていたのを10程度へ変更することを基準にしながら微調整を行った。
ユニット数
これは精度の向上にも過学習の抑制にもつながるので、reluもDropoutも調整してみた。今回はモデルの大きさにはさほど影響はなかった。
エポック数
これは予測精度にしっかり影響するし、過学習も考えられるから、よく観察しながら調整したが、元々10だったところから、画像サイズ縮小による変化を鑑み、基準値として30を検討して調整した。
そんなこんなで試行錯誤していると、このあたりまでは精度を維持しながらどうにか縮小できるようになった。
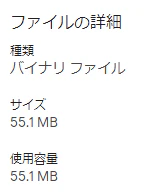
しかしあと一息(5MBちょっと)を求めると、急にファイルサイズは30MB台まで絞れるものの、精度が一気に落ちるようになった。
なんで明らかに犬なのに猫に分類しちゃうの……もはや猫に見えてきた。
結論・まとめ
いきなりかもしれないが、50MBと30MBを行ったり来たりしているうちに、一つの結論にたどり着いたため、まとめに入る。
精度を維持しようとすると、ギリギリ50MBを切れない。急に30MB台になったと思ったら、精度が落ちる。つまり、50MB以内のモデルサイズで分類できる精度には限界があるのでは?
というわけでたどり着いたのが、目標を下げようということだ。今回はとりあえず、自分の経験として、アプリの実装を行いたい。精度をある程度犠牲にして、50MBを切るサイズのモデルを作り、それでアプリの実装経験をしよう。
ただ、あきらめたわけではない。
今回は、このモデル作り直しに至るまでに(デプロイの度重なる失敗やそこに合わせた調整等の)試行錯誤をかなりしたため、一度手間を惜しんでEfficientNetB0での作り直しにこだわった。
しかし、手間を惜しまずVGGシリーズで試してみれば、他のファイルの書き換えが必要であっても、小さくても正確なモデルを作れるかもしれないので、時間があるときにやってみようと思う。
あるいは、GitLFSが復活すれば、当初の予定のビッグサイズなモデルを使えるだろう。これはこれでやりたい。正確性を捨てずにやれるならそれに越したことはない。
今回はバリデーションデータで99.5%、20枚のテストデータで90%の精度を出した物を実装することとした。モデルのサイズは38.6MBと、かなりの縮小には成功した。
時には何かを得るために何かを捨てることもある。
とはいえ、これは無料の範囲でできることであり、有料版なら事情が違った。しかし、企業で何かをするときにはなんだかんだコスト削減と言われるだろう。
そう考えると、今回の経験は、限られたリソースでできる限りのことをする≒コスト削減への試みととらえることもできる。
全然違うことで困っているうちに、別の問題について考えることができた。
最終的なコード
今回変更した点をコメントアウトした。
from tensorflow.keras.layers import Dense, Dropout, Input, Flatten
from tensorflow.keras.applications.efficientnet import EfficientNetB0 as Efb0
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# 画像サイズは250*250から95*95に変更
base_model = Efb0(weights='imagenet', include_top=False, input_shape=(95, 95, 3))
top_model = Sequential()
input_layer = Input(shape=base_model.output_shape[1:])
top_model.add(Flatten())
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='sigmoid'))
model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
for layer in model.layers[:-1]:
layer.trainable=False
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# バッチサイズは50から15に、エポック数は10から25に変更
history=model.fit(X_train, y_train,
batch_size=15,
epochs=25,validation_data=(X_test, y_test))
おまけ
前回今回と犬と猫の分類をテーマに深堀したわけだが、何故かどんなに何を変更しても、猫はかなりの精度で分類する。何か理由があるのだろうが、今の私にはそこを調べるほどの技量がない。学習を続け、そのあたりもわかるようになれば、限られたリソースの中で効率よく精度を上げることができるようになるかもしれない。
デプロイ完了したアプリにチワワっぽい画像を入れたら、しっかり猫と判定してくれた。
犬だよ。