Watson DiscoveryのPremiumプランで提供されている機能を使ってみました。
今回はコンテキスト・ビューというコンテンツ・マイニング用の機能です。
コンテキスト・ビューの活用場面
構造化されたデータと複数の非構造化データを対象に分析する場合に使うことがあります。
多くの場合、非構造化データは1つですが、中には複数の非構造化データが存在する場合があります。
例えば、
例1)
「日付」「都道府県」「性別」などは、構造化されてたテキストデータ。
「結果内容」が自然言語で書かれた文章で非構造化データ。
| 日付 | 都道府県 | 年齢 | ・・・ | 結果内容 |
|---|---|---|---|---|
| 2021/01/1 | 東京 | 20代 | ・・・ | 結果の内容が自然文で書かれている。 |
例2)
「結果内容」に加えて「原因」も自然言語で書かれた文章で非構造化データ。
| 日付 | 都道府県 | 年齢 | ・・・ | 結果内容 | 原因 |
|---|---|---|---|---|---|
| 2021/01/1 | 東京 | 20代 | ・・・ | 結果の内容が自然文で書かれている。 | 原因が自然文で書かれている。 |
今回紹介するコンテキスト・ビューは、例2 にあるような結果と原因や、質問と回答など、自然文のフィールドが複数あるデータを分析する時に役に立ちます。
コンテキスト・ビューを活用することで、構造化データと複数の非構造化データを同時に分析できたり、特定の非構造化データに絞って分析できたり、分析の柔軟性が増します。
コンテキスト・ビューを利用しない場合は、「構造化データ+結果内容」のデータ、「構造化データ+原因」のデータを準備し、それぞれ別々のコレクションを作成する必要があり、分析する時もコレクションを切替る必要がありちょっと手間ですね。
(参考):「コンテキスト・ビュー」タブ
やってみた
前提
- Discovery Premiumにコンテント・マイニング用のプロジェクトを作成しデータ投入済み。
- サンプルデータは、「事故情報データバンクシステム」(消費者庁・国民生活センター)(https://www.jikojoho.caa.go.jp/ai-national/) を加工して作成したものを使用。
データ構造のイメージはこんな感じ。
| 発生年月日 | 種別 | ・・・ | 事故の概要 | 事故原因 |
|---|---|---|---|---|
| 2011年01月11日 | 危険情報 | ・・・ | 〜をしてたところ〇〇が発生して△△となった。 | XXの不良で、YYが不十分だったため、ZZが発生した。 |
| : | : | : | : | : |
複数のフィールドを分析対象(Analyzable text content)に設定する方法
Discoveryでは Analyzable text content に設定されているフィールドに対して形態素解析が行われます。
デフォルトは1つのフィールドのみに設定されます。
今回、自然文のフィールドが2つ(「事故の概要」と「事故原因」)あるため、複数のフィールドに対して設定する必要があります。
方法は2つあります。
- 初期データ投入時に設定する
- 後から設定する
1.初期データ投入時に設定する場合
まず、1つ目の方法です。
コレクションを作ると同時にデータ投入する最後の画面で「Open the collection to configure advanced options」を選択し「Save」をクリックします。
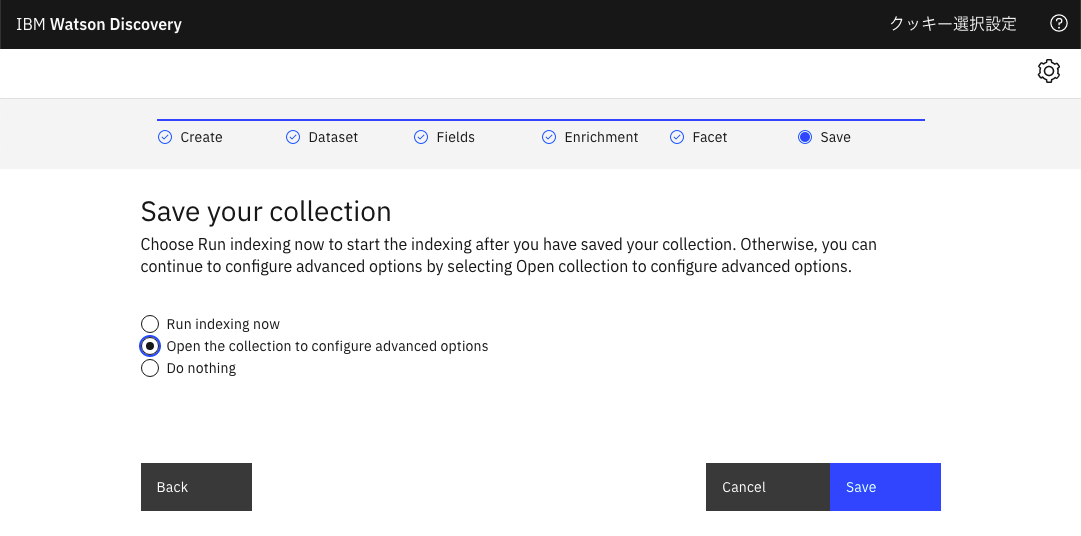
Fieldsタブに移動して、Analyzable text content に設定したい項目を選び「Save」するだけです。
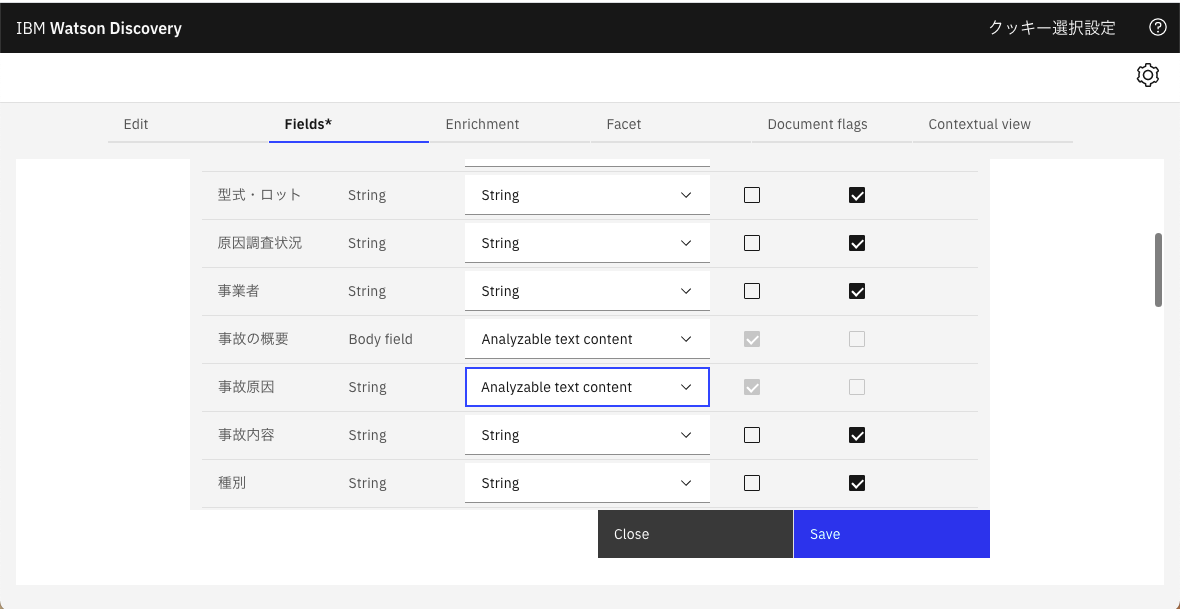
索引を再作成する必要がある旨のメッセージがでるので「OK」。
後は索引付けが完了するまで待ちます。
2.後から設定する場合
後から設定する場合は、コレクションの右上にある「:」をクリックし「Edit collection」をクリックします。

同じような画面が表示されるため、「Fields」タブから Analyzable text content に設定します。
「Save」すると、索引再作成のメッセージが出るため「OK」。

コンテキスト・ビューの作成
コレクションの設定画面から「Contextual view」タブに移動します。
「Add view」をクリックします。

Name:任意のビュー名前(日本語可能)
Id:任意のフィールドID(ただし英数字と_のみ)
Fields: プルダウンからビューに含めるフィールドを選択
最後は「Apply」。

同様の手順で、個別のフィールドのビューや全部入りのビューを作成します。
最後に「Save」。

Saveすると索引再作成のメッセージが出るので「OK」をクリックし、完了するまで待ちます。
分析画面での設定
続いて、分析画面でコンテキスト・ビューを使う方法です。
「Show documents」から文書を表示し、鉛筆マークをクリックします。
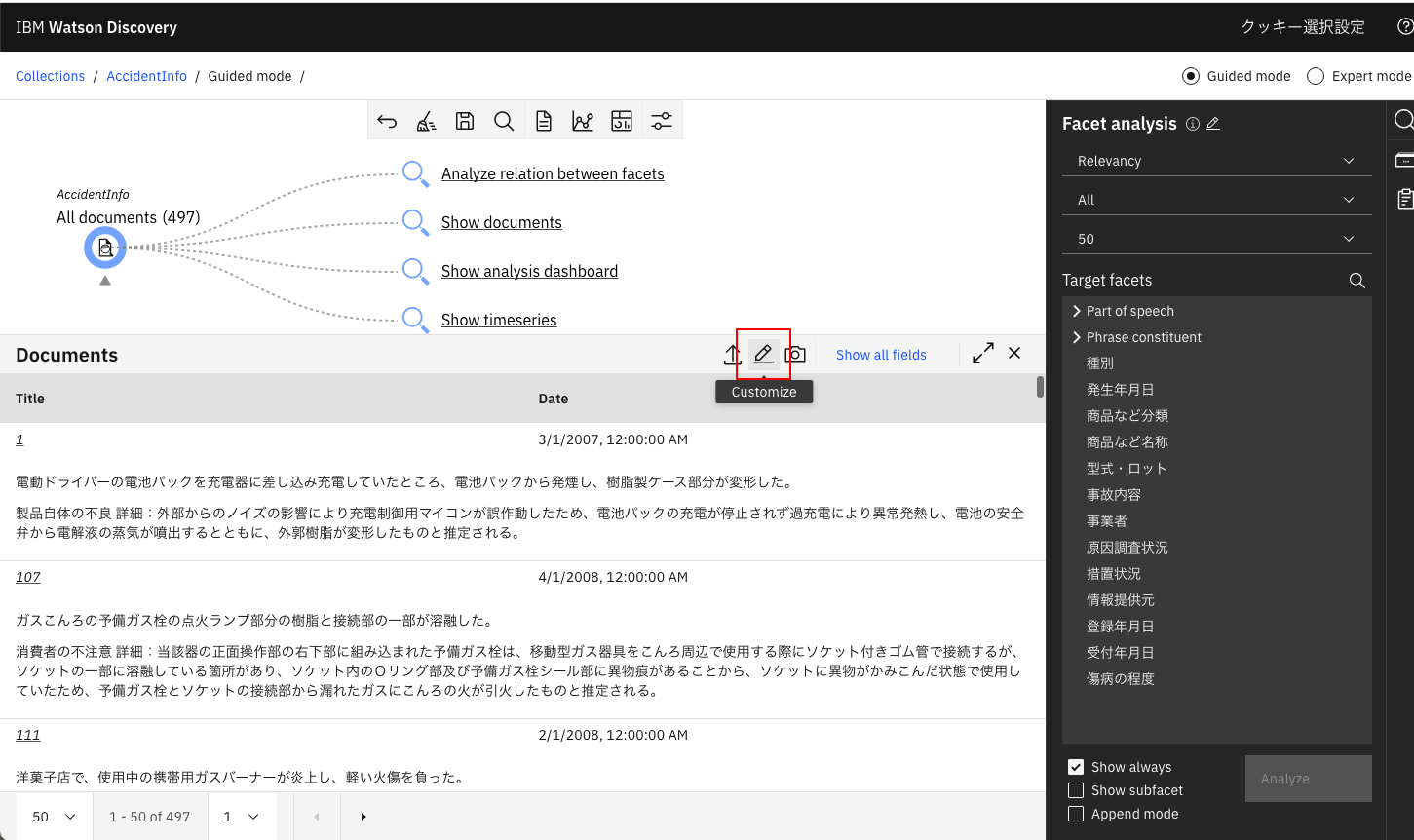
この画面で一番下の「Display mode for document contents:」のプルダウンから「Show document content with name」を選択して「Apply」します。

すると、どの項目の文章なのかが表示されるようにあります。
先程の画面と見比べても、わかりやすくなりましたね。
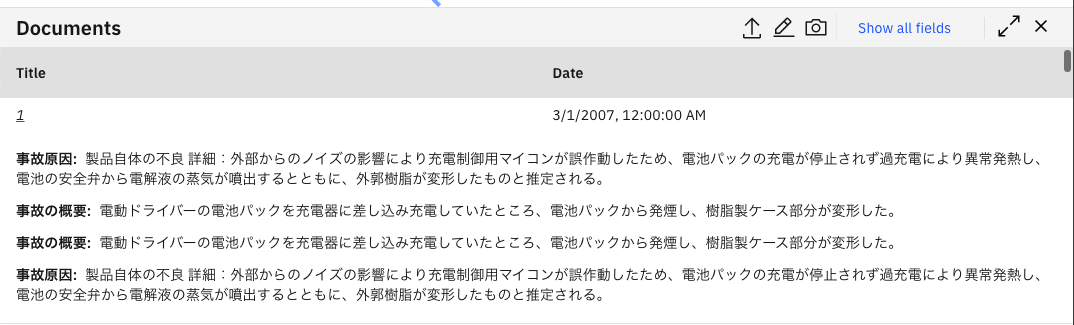
この状態で、例えば「Noun](名詞)をリストすると以下のような感じになります。

次に、右にある「Facet analysis」の「All」プルダウンから個々の項目を選択してみましょう。
(余談)ここで気づきました。全てのビューは既にあった(All)のでわざわざ作る必要ありませんでしたね。。。

「事故の概要」のみを対象とした名詞はこんな感じ。
概要なので「アダプター」や「ケーブル」など品名が出てきますね。

「事故原因」のみを対象とした名詞はこんな感じ。
原因が書かれているので「不良」や「抵抗」などの言葉がありますね。

分析準備完了
あとは色々なビューを活用して、色々な方向から、データを分析し、新しい発見や気づきを得るのみ!
お断り
このサイトの掲載内容は私自身の見解であり、必ずしも所属会社の立場、戦略、意見を代表するものではありません。 記事は執筆時点の情報を元に書いているため、必ずしも最新情報であるとはかぎりません。 記事の内容の正確性には責任を負いません。自己責任で実行してください。