FGOではないです。
はじめに
- アドベントカレンダーにとりあえず登録したものの、元々書こうと思っていた内容を別のアドベントカレンダーに書いてしまったのでネタが思いつかない。
- 最近社内でAutoMLの話がちらほら聞こえてくる。
- AutoML触ったこと無かったのでAutoML Vision試してみることにする。
- 自分で手軽に試せる内容ということで、自分がプレイしているスマートフォンゲームのキャラクターイラストからゲームのクラス等を予測するモデルを学習させてみた。
なお、AutoMLの手順等については書き忘れたので先人たちの記録がたくさん転がっているのでこちらでは省略したいと思います。
データセット
今回はデータとしてきららファンタジアというゲームから、私がプレイしているアカウントで所持している☆4, ☆5のキャラクターの進化前後のスクリーンショットを利用します。
実装されていても私が持っていないキャラクターの画像は含まれません。
ラベル
各キャラクターはレアリティ, クラス, 属性, 進化のそれぞれについて下記のいずれか一つのラベルが付与されます
- レアリティ:
☆4,☆5 - クラス:
戦士,ナイト,僧侶,魔法使い,アルケミスト - 属性:
火,水,土,風,陽,月 - 進化:
進化前,進化後
データの内訳
| 進化前 | 進化後 | 合計 | |
|---|---|---|---|
| ☆4 | 152 | 152 | 304 |
| ☆5 | 55 | 51 | 106 |
| 戦士 | ナイト | 僧侶 | 魔法使い | アルケミスト | |
|---|---|---|---|---|---|
| ☆4 | 60 | 58 | 62 | 62 | 62 |
| ☆5 | 18 | 14 | 32 | 30 | 12 |
| 火 | 水 | 土 | 風 | 陽 | 月 | |
|---|---|---|---|---|---|---|
| ☆4 | 50 | 58 | 60 | 48 | 44 | 44 |
| ☆5 | 18 | 26 | 20 | 13 | 16 | 13 |
データの特徴/実例
全体の画像例としては下記のようになります。

また、下記のように☆5キャラクター(右)は背景も含めた一枚絵のイラスト、☆4(左)はキャラクターのみのイラスト(背景はゲーム画面で共通)といった違いがあります。
(その関連で余白のスペースも☆4, ☆5で異なります)
この辺の前処理をサボっているのでレアリティの判定自体は100%に近い性能が出るのではと思っています。
キャラクターのイラストからのレアリティ予測を真面目にやるなら、背景切り取ってランダムに適当な背景くっつけるとか余白のトリミングとかデータセットの作成を工夫する必要がありそうです。


加えて、同一キャラクターの☆4/☆5間ではクラスは共通ですが属性が異なるという特徴があります。
属性については上記の画像(左は水属性、右は土属性)のように人手でも分類不可能なものが多数なので、基本的には非常に低い結果になることが予想できます。
訓練
マルチラベル分類
まずはマルチラベル分類として学習させてみました。
結果
結論から言ってしまうと、ほぼ全てのラベルで散々な結果になりました。
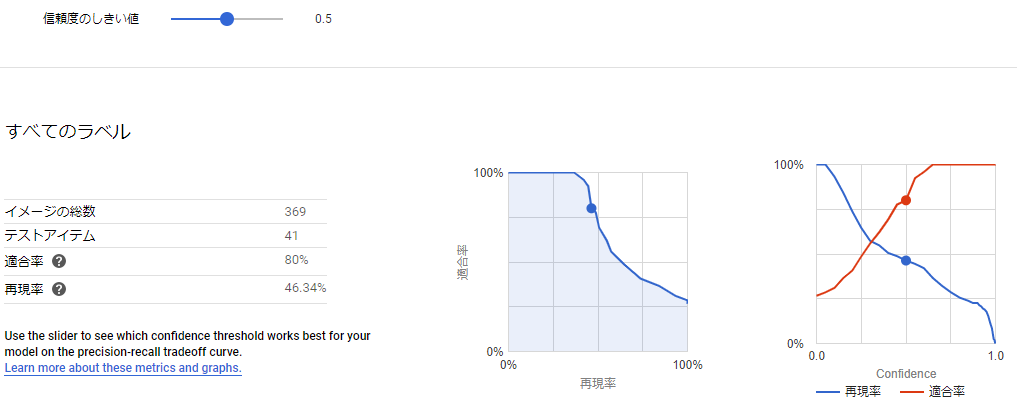
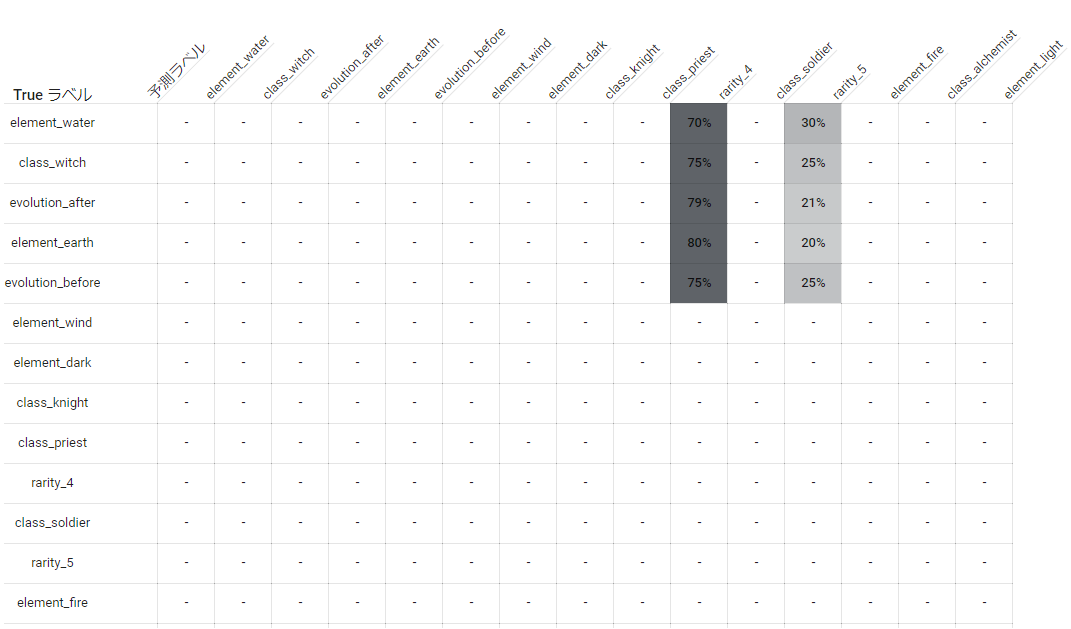

パフォーマンスを見て分かる通り、ごく一部のラベルを除いてひどい結果でした。
レアリティについては前述したとおりなので、予想通り非常に高いパフォーマンスが出ました。
属性についても予想通りですが火属性が極端に低く、月属性は比較的マシなど結構属性ラベル内でも差があるのは気になる点です。
クラスのラベルについてはもう少し高いパフォーマンスが出ることを期待していたのですが、予想に反して属性ラベルと似たような結果になってしまいました。
進化前後についてのラベルがそこそこ高いのは以外でした。
マルチラベル分類として解くにはデータ数が足りていないのは明らかなので、次にレアリティ, クラス, 属性, 進化の4つの単一ラベル分類に分けてそれぞれ学習させたときに結果が変化するか実験してみます。
単一ラベル分類
レアリティ分類
予想通り100%の結果が出てしまいました。
これは完全に前処理サボったせいなので、特に言及することはないです。

クラス分類
僧侶については比較的マシな結果ですが、全体としては閾値0.5でprecision, recallともに0.55と微妙な結果でした。
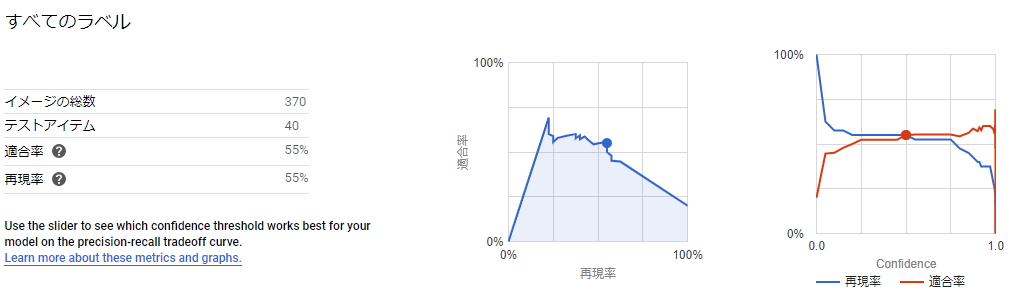
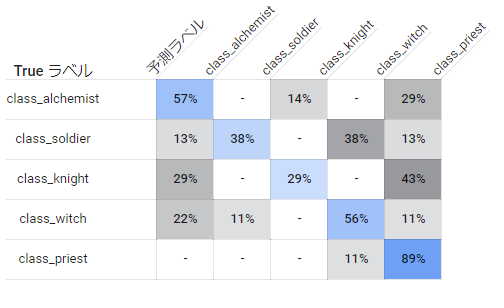
とはいえ前述した属性の件と同様に、例えば下の魔法使いの偽陰性の結果のように人手でも正しく分類するのが困難な画像が少なからず含まれているので妥当といえば妥当な結果ではあります。

左から2番目は魔法使い的な帽子を被っているため人手なら魔法使いと判別付く可能性もありますが、それ以外の3枚は人手でもどのクラスか判別できません。
また、☆5キャラクターの誤りが魔法使い, 僧侶の2つに固まっていますが、前述のデータ数の通り☆5のクラスの割合で魔法使いと僧侶の数が他クラスの約2倍存在することが影響しているのではないかと思います。
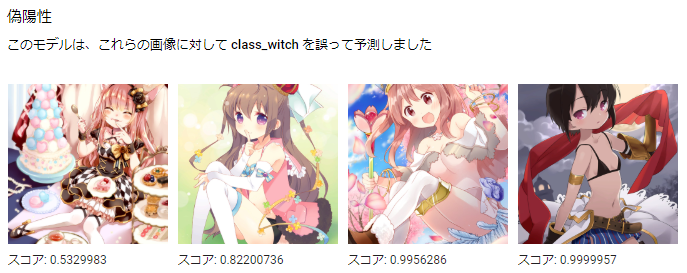

結果を見ていてい興味深かったものとして、下記左は約0.99のスコアでナイトと正しく予測されたのに対して、右は約0.98のスコアでアルケミストと予測されていたりしました。


人間的にはいずれも右手に武器っぽいなにかを持っていて左手に盾っぽいなにかを持っているのでどちらもナイトだと高い確率で判断できるように思います。
そこで元のデータになにか特徴がないかアルケミストラベルのデータを確認したところ、他のクラスのラベルと比較して紫系の色を含むキャラクターが多い印象でした。
仮にキャラクターの色を特徴量として重視しているのであれば、モノクロにしたデータや輪郭のみを抽出したデータで学習させた結果と比較すると面白いかもしれません。

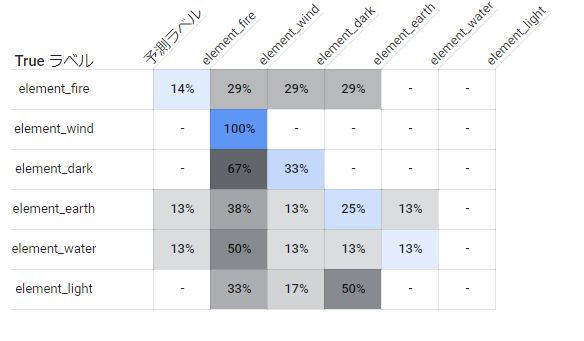
属性分類
属性の分類についてはマルチラベル分類の際と比べてパフォーマンスが低かったラベルが多少上昇していますが、全体としては特筆するほど変化が有りませんでした。
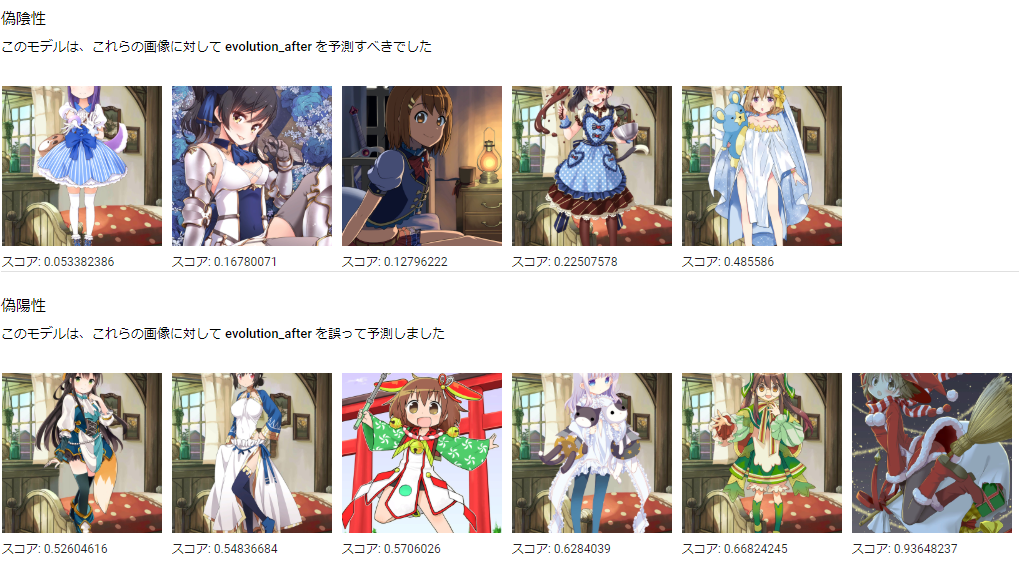
進化前後分類
今回試してみた中で個人的に一番いい感じの結果になってくれました。
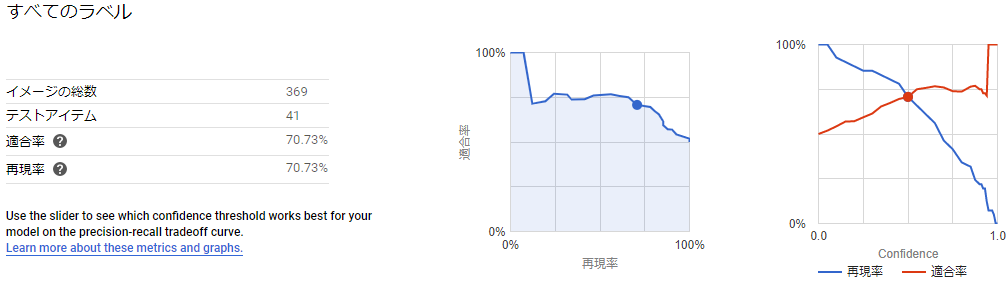
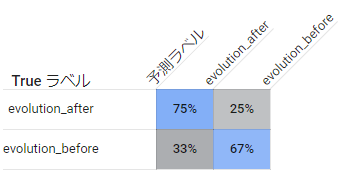
precision, recall共にいい感じのバランスかつそこそこ高い数値が出ました。
この分類については事前の予想ではクラスや属性ほどではないにせよ人手で分類が困難なものが結構あるのであまり高い性能は出ないと思っていたのですが、存外マシな性能が出て驚いています。
- 進化前

- 進化後

進化前後のイラストを比較すると進化前は武器や装飾が少なくポーズも普通に立っているものが多い印象ですが、進化後は武器のようなものを持っていたり動きのあるポーズのイラストが多いように見えます。
こういった特徴をうまく学習しているのかもしれません。
実際、偽陰性/偽陽性の内容を見ても比較的そのような傾向がある気が……しないでもないですね?
まとめ
今回はきららファンタジアのキャラクター画像をデータセットにAutoML Visionでレアリティ, クラス, 属性, 進化前/後についてマルチラベル分類と単一ラベル分類でそれぞれ学習を行ってみました。
全体としてはラベルごとに十分なデータが存在するものについてはマルチラベル分類/単一ラベル分類のいずれでもそこそこ高く、かつ同程度の性能となることが見て取れます。
一方で、データ数が十分でないラベルの分類に関してはマルチラベル分類よりも単一ラベルの分類タスクとして学習させたほうが、比較的マシな性能になりました。
今回はデータ数が全体的に少ないのでデータ数を増やすことでより高い精度で予測できるようになる可能性は大いにありますが、各ラベルに対するモデルの性能としては「機械学習は前処理と問題設定が命」、という当たり前の話を再確認する形となりました。
また、今回の内容でtrainingは1回2時間前後、料金は1回あたり4000~5000円前後でした。
思いついてからデータ集めてラベルつけて訓練させて結果を確認してこの記事を書くまで1日前後で終わったので、ちゃんと問題設定をすればこれくらいの手軽さでそこそこの精度が出るのは知識として知っていても非常に面白いです。
私自身は画像処理系の経験が全く無かったので雰囲気を体験する意味でも試してみてよかったと感じます。
普段はNLP関連のことをやっているので、そのうちAutoML NLも試してみたいですね。
ただし人手でのラベル付けはやはり苦行なのでうまく正解ラベル付きデータを収集する方法は別途考える必要がありますね。
おまけ
本当はDeepLearning4Jを使って今回のような内容をやろうと思っていたのですが、そこまで手が回らなかったのでこちらについては宿題としたいと思います。