この記事は Opt Technologies Advent Calendar 2019 2日目の記事です。公開は諸事情により7日目です。
弊社では毎年開発合宿(去年の様子)でエンジニアがYATTEIKIを発揮します。最近はビジネスサイド参加者が増えていて活発っぽい。時代はAIバブルですが Google の Cloud autoMLを触ってみたら楽にAIな開発ができたので、機械学習なんもわからんマンでもできる実装手順を紹介します。
はじめに
〜ランチ中〜
弊社データサイエンティスト「kaggle のachievement機能みたいに社員を格付けしたい」
私「どうして」
弊社データサイエンティスト「人類は評価されると嬉しいから」
私「天才」
アイデア
コンペ資料など社内知見共有をするwebアプリケーション(Quarry1)を利用し、アップロードした資料につく「いいね」「お気に入り」「ダウンロード数」「カテゴリ」「タグ」情報から以下の機能を考えました。
-
AutoMLによる投稿時のカテゴリ(投稿種別)の自動付与 - 投稿のレコメンド
- ユーザーのランク付けによる投稿動機付け
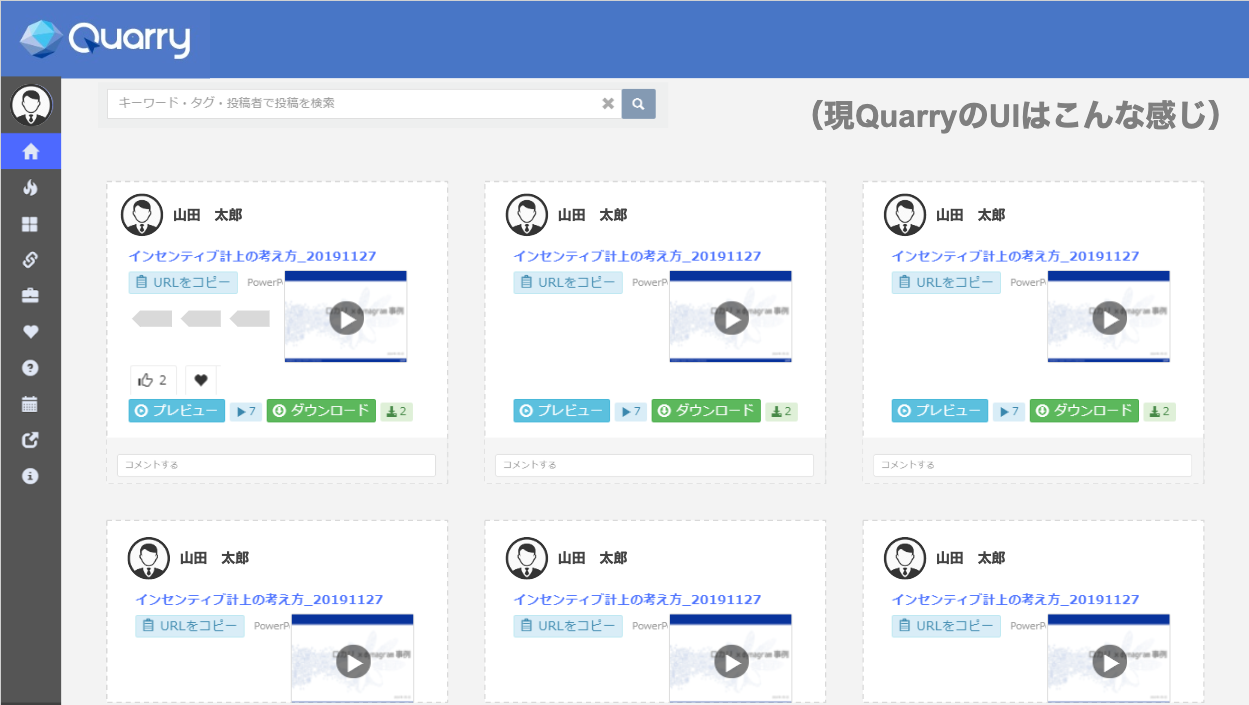
↑をもとに作った↓
※ステージング環境のデータベースとはいえ(コンプライアンス的に)完全アウトなのでモザイク
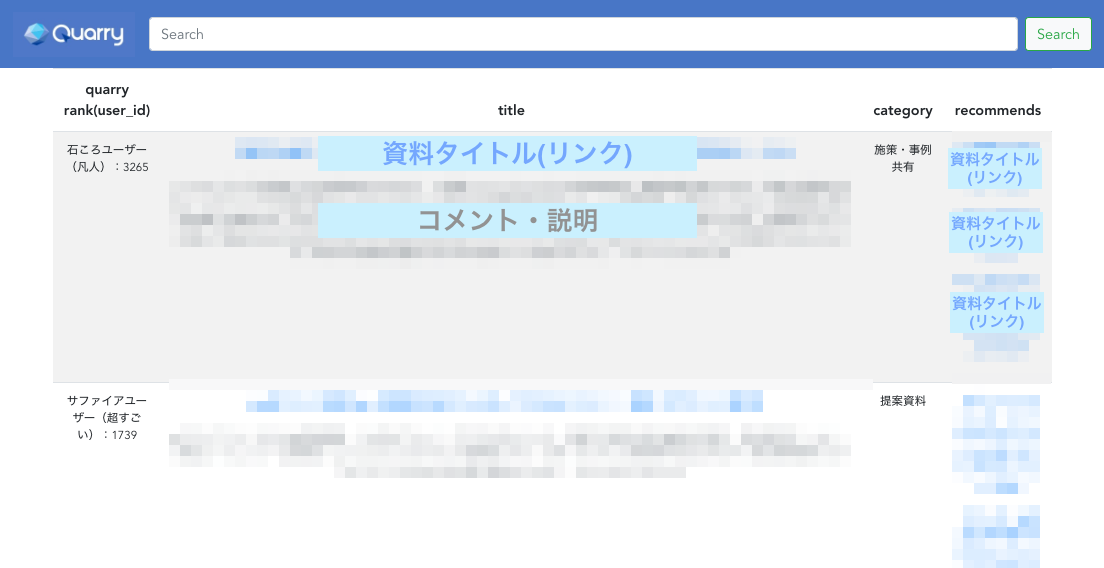
主なポイントは
- 採石場という意味のQuarryにちなんでユーザランクは
石ころ<<<<<サファイヤまで - recommendsカラムにアイテム(資料)を3つサジェスト表示
の2点です。アプリケーションの構成技術スタックは flask + Vue.js で実装しました。

今回は2番目のサジェスト機能で利用した AutoML Text Classification にフォーカスします。
AutoMLって
冒頭でも紹介しましたが、現在(2019/12)Google Cloud Platform がβ版で公開している機械学習APIです。
今回利用した Cloud Natural Language API だけでなく、画像や翻訳など各分野のAPIが展開されています。
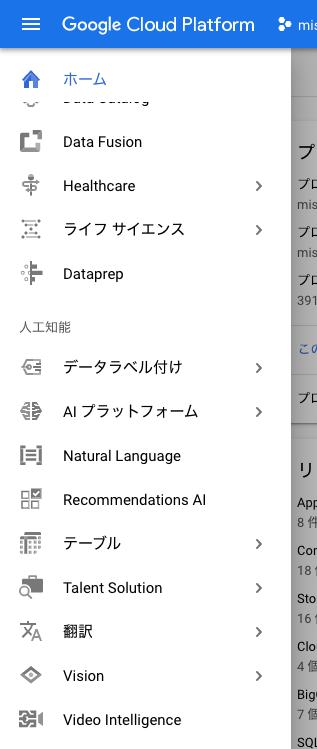
今回は、資料のファイル名とそれに紐づくカテゴリデータ(タグもある)をもとにレコメンドモデルを生成したいので、Natural Language をクリックします。
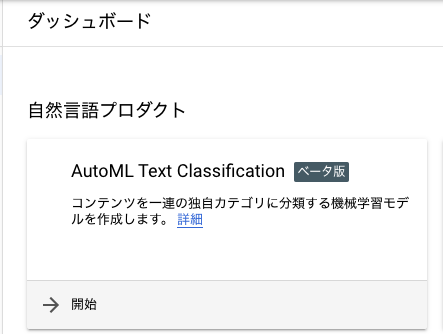
すると自然言語系のプロダクト一覧がダッシュボード画面に表示されます。
カテゴリ分類を行う機械学習モデルを作成する AutoML Text Classification を利用します。
前処理
機械学習といえば前処理。前処理を制する者は人類を制す。それは言いすぎかも。
普通に jupyter notebook (今後Jupyter labに移行予定らしい2)でQuarryのDBから対象データを抽出していきます。
必要なライブラリ等諸々。
import csv
import os
import pandas as pd
import mysql.connector
from flask import Blueprint, request, jsonify
ステージングのDBと接続します。
# DB connection func.
def get_connection():
conn = mysql.connector.connect(
host='quarry-staging.hoge.ap-northeast-1.rds.amazonaws.com',
port=3306,
user='hogest',
password='sayhoge',
database='db_name',
)
return conn
mysql-connector-python(sqlight3でも良い)を使って欲しいテーブルやカラムをSQLで execute していきます(一例)。
db_name = Blueprint('db_name', __name__, url_prefix='/api/db_name')
# メッセージリスト
def list_message_query():
"""
"id",
"user_id",
"message_div",
"scope_div",
"title",
"message",
"url_flg",
"link_url",
"link_url_kind",
"thumbnail_url",
"update_user_id",
"status",
"created",
"updated",
"""
conn = get_connection()
cur = conn.cursor()
cur.execute(f"""
select id, user_id, title, message, updated, created
from messages
where status = 0
""")
return cur.fetchall()
あとはリストを作って map 関数とlambda式で要素を変更しながら各テーブルごと同様の加工をします。
massage_list = list(map(lambda x: {
"id": x[0], "title": x[2], "message": x[3]
}, list_message_query()))
ラベルに使う category_id(カテゴリ番号) を抽出します。
df_raw_cid = pd.DataFrame(category_list, columns=['id', 'category_id'])
はじめはtitle(資料名)とmessage(資料のコメント)をくっつけて学習しようとした日もありました。
body_str = add_categoryId['title']+add_categoryId['message']
# cid を Series -> df に変換
df_body_str = pd.DataFrame(body_str, columns = ['title_message'])
type(df_body_str)
コメントの文字列に改行や特殊文字など扱いにくい文字列がたくさんあるとわかったので、やっぱり message カラムいらない、、、みたいな紆余曲折。
drop_col_message = ['message']
df = add_categoryId.drop(drop_col_message, axis=1)
結局必要なカラムだけをとった df_title と df_cid を concat してCSVに吐きました。Dataframeで作成したので勝手についてしまうindexは index=False することを忘れないでください、AutoMLのデータセットに不要なようです。
dataset_tc = pd.concat([df_title, df_cid], axis=1)
dataset_tc.dropna(how='any')
dataset.to_csv('data/dataset_tc.csv', index=False)
データセットのインポート
- 「新しいデータセット」からデータセット名とモデルを選択。
今回のデータセットは資料名とカテゴリ番号なので単一ラベル分類を選択しました。
- 該当するファイルのアップロード(今回は jupyter notebook でデータ整形をしたので「パソコンからCSVファイルをアップロード」した)。
...なんとこれだけで学習モデルの作成がスタートします。
考察
トレーニング結果
以下のようなデータセットが作成されました。

対象データのアイテム数とカテゴリラベルなど詳細は以下です。
ちなみに学習が終わるまで2時間くらいかかりました。モデル生成に時間はかかりますが、あとは学習済みのモデルをAPIで使うだけなので、毎回この時間がかかるわけではありません。

| アイテム数 | |
|---|---|
| 全てのアイテム | 9416 |
| ラベル付き | 8151 |
| ラベルなし | 1267 |
| トレーニング | 6522 |
| 検証 | 816 |
| テスト | 813 |
評価
トレーニングが終了したら生成モデルの評価を行います。分類精度として適合率(Precision)と再現率(Recall)の2つを指標とします。お互いにトレードオフの関係であるため、ケースによってどちらを優先するべきか判定する材料となるわけです。
アイテムの嗜好に適合させたい今回のケースはレコメンドエンジンとして評価したいので、適合率を優先します。反対に、よく例に出てくる癌予測のケースでは再現率を優先して病気の見逃しをできるだけ減らすことに注視します。
(TP=真陽性,FP=偽陽性,TN=真陰性,FN=偽陰性)
$$ Precision = \frac{TP}{FP+TP} $$
$$ Recall = \frac{TP}{FN+TP} $$
陽性(True)と予測した結果によって、実際に陽性だった結果を真陽性(True-Positive)、違った結果を偽陽性(False-Positive)と定義しそれぞれの指標をします。陰性(Negative)の場合も同様に真陰性(True-Negative)と偽陰性(False-Negative)と表します。

また、正解ラベルと実際の予測結果を行列で表現する混同行列(Confusion matrix)も評価指標となります。
各行(列)で高い予測割合が右斜め下にクロスしていればよいモデルと判断できます。
適合率,再現率(Precision, Recall)の結果
 閾値(Confidence thresholdの調整バーで設定)の時点で適合率が高く性能としては良さそうです。
閾値(Confidence thresholdの調整バーで設定)の時点で適合率が高く性能としては良さそうです。
混同行列(Confusion matrix)の結果
 ラベル5,10はもともとアイテム数が少なく割合が低くなってしまいました。アイテム数が0のラベル6はしっかりはじかれていることがわかります。
ラベル5,10はもともとアイテム数が少なく割合が低くなってしまいました。アイテム数が0のラベル6はしっかりはじかれていることがわかります。
カテゴリラベルごとの結果
| ラベル | アイテム数 | 適合率(%) | 再現率(%) |
|---|---|---|---|
| 1.媒体資料 | 660 | 68.57 | 36.36 |
| 2.提案資料 | 2701 | 89.95 | 66.3 |
| 3.施策・事例共有 | 3058 | 84.36 | 75.82 |
| 4.機能・テクニック | 363 | 100 | 19.44 |
| 5.業務効率化・改善 | 214 | 100 | 0 |
| 6.タスク・スケジューリング管理 | 0 | null | null |
| 7.業界・市場・競合調査 | 554 | 84.09 | 67.27 |
| 8.セミナー・勉強会 | 473 | 58.62 | 36.17 |
| 9.連絡 | 92 | 100 | 44.44 |
| 10.教本・基礎 | 36 | 100 | 0 |
AutoML Text Classification は、設定したラベルごとのF値(しかもTP,FP,TN,FNごとに)の結果を出してくれています、すごい(KONAMI)。

最もスコアが高いラベル2の中でも、正しく予測できなかったアイテムが一覧で確認できるので何が原因だったのか考察することができます。
例えば、提案資料カテゴリの偽陰性一覧にあがっているアイテムで資料名に「提案資料」と入っているものが複数観測できました。これは「提案資料」の前後に別カテゴリに分類されそうな「施策」や他カテゴリに多い社名(固有名詞)が入っており、文脈による単語間の類似度計算かなにかがされていたりして(要出典)、「提案」とあっても分類されないケースもあるようです。
テストと使用
ダッシュボード上でGCPから新たなデータをこのモデルに判定させることもできます。
Cloud Natural Language は API なので当然アプリケーションコードに組み込むことで推薦機能を実装できます。
まずは、
$ curl -X POST \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json" \
https://automl.googleapis.com/v1beta1/projects/391983214514/locations/us-central1/models/TCN1234567790hogehoge:predict \
-d @request.json
と curl を叩くと、
{
"payload": {
"textSnippet": {
"content": "YOUR_SOURCE_CONTENT",
"mime_type": "text/plain"
}
}
}
request.json が返ってきます。
GDC fileなら以下。
{
"payload": {
"document": {
"input_config": {
"gcs_source": {
"input_uris": "YOUR_GCS_FILE_URI"
}
}
}
}
}
Pythonの場合、 predict.py として以下のように書くことができます。
import sys
from google.api_core.client_options import ClientOptions
from google.cloud import automl_v1beta1
from google.cloud.automl_v1beta1.proto import service_pb2
def inline_text_payload(file_path):
with open(file_path, 'rb') as ff:
content = ff.read()
return {'text_snippet': {'content': content, 'mime_type': 'text/plain'} }
def pdf_payload(file_path):
return {'document': {'input_config': {'gcs_source': {'input_uris': [file_path] } } } }
def get_prediction(file_path, model_name):
options = ClientOptions(api_endpoint='automl.googleapis.com')
prediction_client = automl_v1beta1.PredictionServiceClient(client_options=options)
payload = inline_text_payload(file_path)
# Uncomment the following line (and comment the above line) if want to predict on PDFs.
# payload = pdf_payload(file_path)
params = {}
request = prediction_client.predict(model_name, payload, params)
return request # waits until request is returned
if __name__ == '__main__':
file_path = sys.argv[1]
model_name = sys.argv[2]
print get_prediction(content, model_name)
あとは
$ python predict.py 'YOUR_SOURCE_FILE' projects/391983214514/locations/us-central1/models/TCN1234566789hogehoge
と実行して確かめてみましょう。カンターン。
まとめ
院生時代、マシンを1週間並列処理(物理)したり論文に実験結果を載せようとscikit-learnでゴリゴリコード書いて混同行列とか作ったり、毎回偽陰性の定義を忘れては確認し(頑張れ)を繰り返していた日々を返して欲しい気もするし返して欲しくない気もしました。
-
JupyterLab will eventually replace the classic Jupyter Notebook.
https://github.com/jupyterlab/jupyterlab ↩