はじめに
2011年の東日本大震災、これから来ると言われる南海トラフ地震などの大規模な災害や事故に備えるために、災害復旧(DR)が可能なシステムと、その実現手段としてAWSを始めとしたクラウドが長年注目されています。
このDRに関連して、近年「レジリエンス」という言葉が注目を集めるようになりました。
レジリエンスとは、回復力、復元力、弾力などの意味を持つ英単語。IT分野では、情報システムがシステム障害や災害、サイバー攻撃などの問題に直面したとき、迅速に被害からの回復を図り正常な状態に復旧・復元する能力(の大きさ)をこのように呼ぶ。
https://e-words.jp/w/%E3%83%AC%E3%82%B8%E3%83%AA%E3%82%A8%E3%83%B3%E3%82%B9.html
AWSでは、2019年8月に大規模障害が発生したことがあり、この時もAZ障害が起きた時に取り得る対策が議論の対象になりました。
あれから3年が経過し、AWSではこの手の障害の影響を緩和したり、回復力を高めるためにできることが増えてきています。
本記事では、AWSで障害に強いアーキテクチャを作る方法にフォーカスしつつ、 AWS re:Invent 2022 で発表された新しいサービスをキャッチアップし、障害に強いレジリエンスと呼べるシステムをAWSで実現する方法についてまとめます。
なお、内容を理解しやすいように、シンプルなアーキテクチャの説明から始め、徐々に複雑にしていきます。
単一障害点を解消する
サーバ1台構成の課題
まずは、AWSでEC2インスタンスを1台構築して、Webアプリケーションをインターネットに公開することを考えてみます。
要件を実現するシステムのアーキテクチャは以下の通りで、非常にシンプルです。
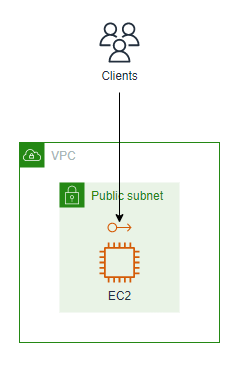
この唯一のEC2インスタンスが何らかの原因で 「サーバダウン」 すれば、その時点でアプリケーションの提供が継続できなくなり、障害となります。
言い換えると、EC2インスタンスが1台しかないことが、システムの単一障害点になっていると言えます。
レジリエンス、すなわち回復力が高いシステムを実現する最も基本的な考え方として、この単一障害点をいかに無くせるかがポイントとなります。
サーバ複数台で構成する
前のアーキテクチャでは、EC2インスタンスが1台であることが、単一障害点でした。
そこで、EC2インスタンスの台数を増やし、アプリケーションを複数のEC2インスタンスで実行するように変更します。
シンプルに考えれば、複数台にすれば良いのですから、アーキテクチャは以下の通りとなります。
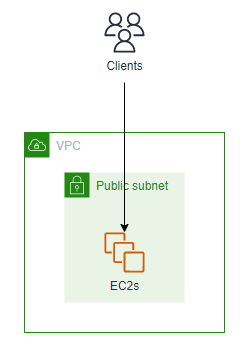
ここで、アプリケーション開発の目線で見ると、デプロイをきっかけとした障害の発生が考えられます。
コード変更などの何かをきっかけとしてアプリケーションのデプロイを行う場合に、EC2インスタンスが複数ある場合、1回のデプロイで同時かつ迅速に展開する必要があります。
1回のデプロイの範囲が全体に及ぶため、もしバグを修正しきれていなかった場合には、その影響範囲も全体に及びます。
この時、EC2インスタンス1台ずつの単位でデプロイする方法も考えられますが、デプロイ中にシステムとしての可用性が下がることを許容する必要があり、可用性を維持してデプロイしようとすると、同時に全体にデプロイするしかないと言えます。
これを言い換えれば、デプロイ自体が単一障害点と呼べてしまう状況と言え、さらに言い換えればシステムの変更を行うためのデプロイが1回でなければならないような構成を解消すべきと言えます。
アプリケーションを複数セットにする
システム全体に1度のデプロイで変更することを避けるようにします。
前のアーキテクチャを変更し、EC2インスタンス複数台で動くアプリケーションを複数セットにすることを考えます。
シンプルに考えれば、アーキテクチャは以下の通りとなります。
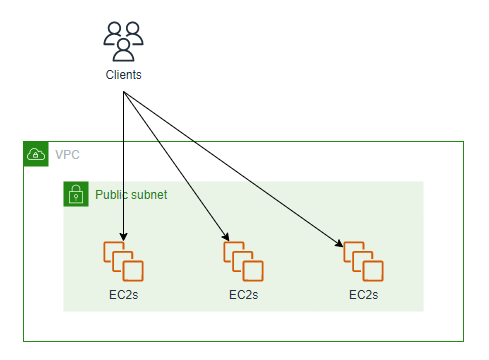
あるセットに対してアプリケーションのデプロイを行って正常であることを確認し、その後、別のセットにデプロイを行います。
もし最初のセットへのデプロイで問題が発生しても、他のセットへの影響がなく、問題が発生したセット全体を切り離すだけで復旧が可能となります。
(問題が発生したセットを切り離すことが暫定復旧で、そのセットでロールバックを完了して再度接続することが完全復旧)
ここで、インフラ開発者の目線で見ると、全てのアプリケーションのセットが同じAZで動いている場合、ハードウェア、ネットワーク、電源などのファシリティの障害が発生した場合に、AZ全体に影響が及び、全てのセットが利用不能になる可能性が考えられます。
洪水や、冒頭で書いた地震などの自然災害も、このAZ障害の原因となり得ます。
Multi-AZにする
AZの単一障害点を解消するために、前のアーキテクチャを変更し、アプリケーションの各セットをそれぞれ別々のAZにデプロイします。
シンプルに考えれば、アーキテクチャは以下の通りとなります。
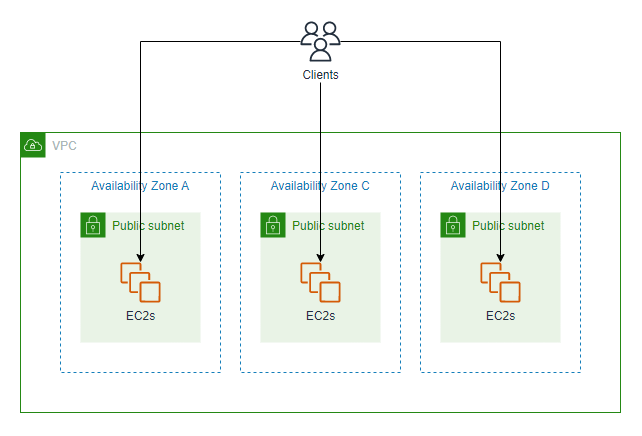
仮にAZ-Aで障害が発生したとしても、AZ-Aのアプリケーションのセットを先ほどと同じ考えで切り離すことにより、AZ-CやAZ-Dでアプリケーションの提供を継続できます。
(参考) 複数のセットで同時障害が起きるその他の要因
Multi-AZ化を完了した時点で、複数のセットをまたぐ同時障害が発生する可能性は小さくなっていますが、いくらか原因になり得る事象も考えられます。
(1) CPU/メモリ/ストレージ不足の同時発現
アプリケーションの各セットが完全に同じ構成であり、あらゆる条件で均等に負荷分散していると仮定すれば、あるセットで起きた高位レイヤーの障害は、同じく別のセットでも発現する可能性があると言えます。
このリスクを避ける方法としては、セットごとにインスタンスタイプを変えたり、ストレージの容量を増やしたり、ヒープ領域の設定を変えたりする対策が考えられます。
(2) TLS証明書が同時に有効期限切れ
証明書をまとめて購入してインストールしている場合、有効期限が切れると、全体に影響が及びます。
このリスクを避ける方法として、証明書の有効期限を分散させる方法が考えられます。
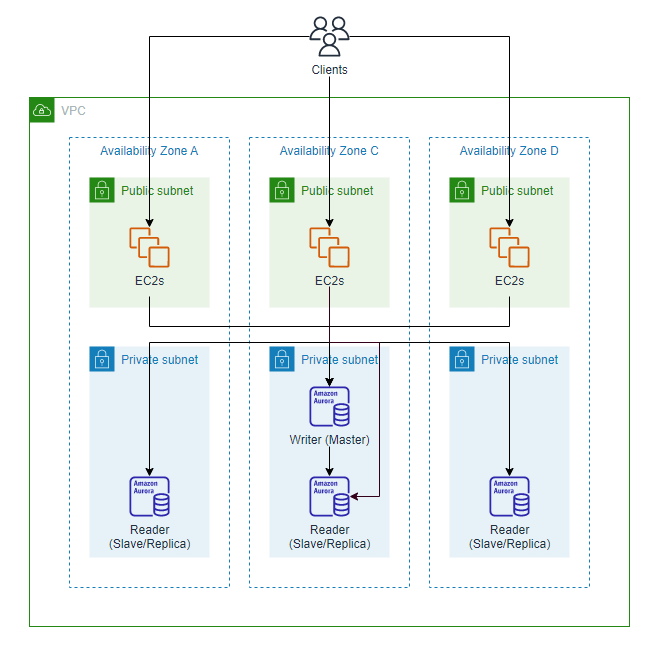
データベース層を分離して高可用化する
ここまで敢えてスルーしてきましたが、アプリケーションの各セットで扱うデータの保管を一貫するため、全台が共通して読み書きするデータベースをEC2インスタンスの外に配置します。
さらに、このデータベース自体の高可用性を確保するために、RDSまたはAuroraのMulti-AZ構成を採用します。
AuroraではAZをまたいでリードレプリカを最大15個構築して読み取りの負荷を分散できるため、この点でRDSのMulti-AZ DB clusterより優れています。
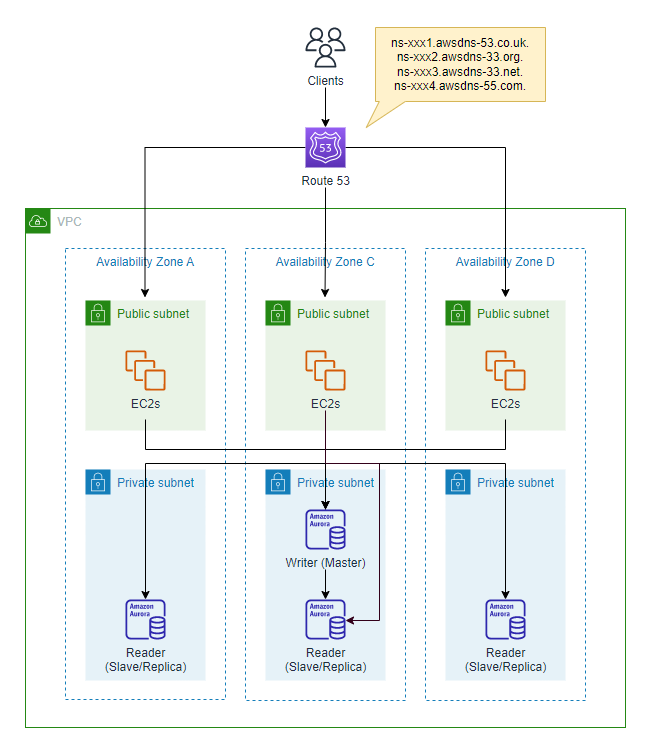
名前解決を実装する
クライアントがインターネットを経由してシステムに接続するために、名前解決を行いますが、この名前解決における障害について考えていきます。
AWSではRoute 53というサービスがありますが、このRoute 53でホストゾーンを作成すると、以下のように4台(4セット)のネームサーバが提供されます。
ns-xxx1.awsdns-53.co.uk.
ns-xxx2.awsdns-33.org.
ns-xxx3.awsdns-33.net.
ns-xxx4.awsdns-55.com.
仮にネームサーバが1セットだけダウンしたとしても、他の3セットのネームサーバが名前解決を継続します。
これを言い換えると、Route 53のネームサーバもまた、ここまで説明した方式で各ドメインにネームサーバのセットが提供されることで、回復力が高く、レジリエンスであると言えるでしょう。
リクエストを負荷分散する
次に、具体的に各アプリケーションのセットの中で、どのようにリクエストをルーティングするかを考えていきます。
NLBを作成して、NLBの下にアプリケーションのセットを構成するEC2インスタンスをターゲットとして配置し、負荷を分散します。
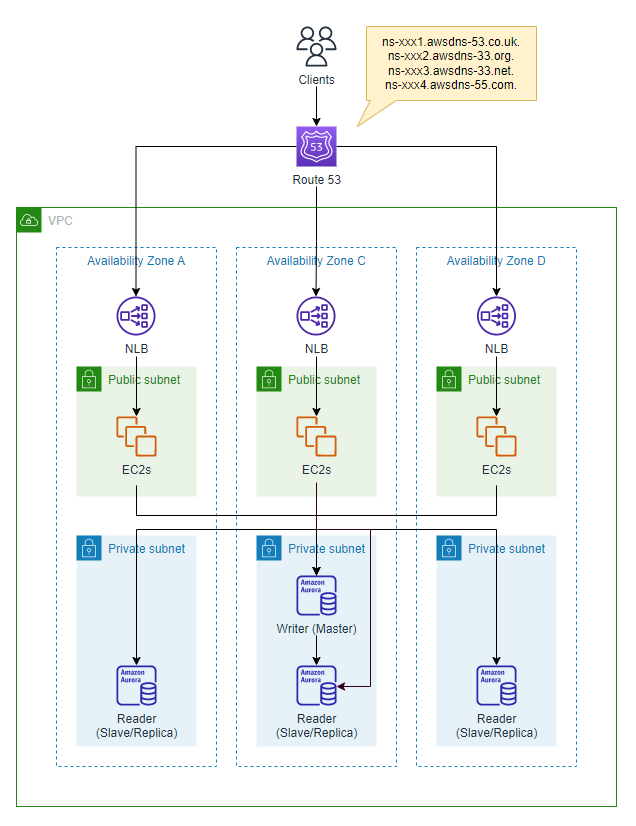
この時に考えられる障害パターンを見ていきます。
各セットでEC2インスタンスに障害が発生する場合
NLBはどのEC2インスタンスにリクエストをルーティングするのかを決定するため、ヘルスチェックを定期的に実行します。
ヘルスチェックに不合格となったEC2インスタンスは、ルーティング対象から除外されるため、システム全体として健全であり続けます。
1つのセット全体で障害が発生する場合
より大きな単位で、あるNLBの配下全てでインスタンスが応答しない場合を想定します。
この規模の障害を想定する場合、どのNLBにリクエストをルーティングするのかを決定するため、Route 53のヘルスチェックを定期的に実行します。
不合格となったNLBは、DNSから削除 (ルーティング対象から除外) されるため、システム全体として健全であり続けます。
定義が曖昧な障害 (Gray Failure) を解消する
単一障害点を解消し、負荷分散を適切に実装したことで、各レイヤーのヘルスチェック機能によって、常に正常なインスタンスにリクエストがルーティングされるように見えます。
ここで、ヘルスチェックに応答する=障害ではないと言えるかどうかがポイントですが、現実問題として、ヘルスチェックには応答するが障害と見なされるケースは山のようにあります。
例えば 「ヘルスチェックのレスポンスは返るが非常に遅くなっている」「ヘルスチェックはたまに失敗するが成功もする」「内部ではエラーが発生しているのにヘルスチェックのレスポンスだけは返している」 というケースが分かりやすく、これらをヘルスチェックだけで検出することは困難で、動作がおかしいEC2インスタンスにリクエストが送られ続けます。
このような障害は海外で 「Gray Failure」 と呼ばれており、このGray Failureを引き起こす主な原因として、以下が挙げられます。
- ソフトウェアのバグによるクラッシュ/再起動
- 設定変更ミス
- 一時的なキャパシティ不足
- 一時的な冗長性の欠如
- パケットロスまたは遅延
これらは悪化しては改善することを繰り返すことがあり、ヘルスチェックだけで検知することが困難な事象と言えます。
また、これらの事象が起きた時に障害と見なすかどうかは、システムによって異なると考えられます。
分かりやすい例えを出すと、インフラ開発者の場合、pingが1回エラーとなっただけで障害扱いしてしまい、確かにそれはエラーなのですが、実際は業務上どこにも被害がないのに、対応に時間をかけてしまう、などといったケースがあります。
このような事象に対する判断は、曖昧となりがちです。
このような「Gray Failure」を解消することを考えていきます。
(1) ディープヘルスチェック
NLBのヘルスチェックのロジックを変更して、業務レベルの正常性を確認できるようにします。
例えば、アプリケーションにヘルスチェック用のクエリパラメータを用意し、アプリケーションに接続すると、階層(依存関係)を辿ってデータベースまで接続し、レスポンスが返ることを確認します。
EC2インスタンスに配置したヘルスチェック用静的ファイルに接続してレスポンスコードが200であることのみ確認するヘルスチェックに対して、このような確認は「ディープヘルスチェック」と呼ばれています。
ディープヘルスチェックの詳細は、Amazon Builders' Libraryの以下の記事に詳しく書かれています。
難解ですが、一度は目を通して、どんなヘルスチェック戦略が取れるのかを見ておくと良いでしょう。
(2) ELBの正常ターゲット数で閾値を設定
先ほどのGray Failureの中に「一時的な冗長性の欠如」という項目がありましたが、分かりやすい例を出すと、NLB配下の正常(Healthy)なターゲット(EC2インスタンスの台数)が減っている状況では、1台あたりのEC2インスタンスが高負荷となり、レスポンスを返せないなどの異常が連鎖し、カスケード障害の原因にもなります。
このような障害の影響を緩和する方法の1つとして、2022年11月にリリースされたELBの機能を利用して、NLBで最小の正常ターゲットの数または比率に関してしきい値を設定する方法があります。
(ALBでも設定可能)
このしきい値を超えてAZ内の正常ターゲット数が減少した場合、NLBは障害が発生しているAZのターゲットへのルーティングを自動的に停止するため、一部のEC2インスタンスがヘルスチェックに応答しているような状況でも、早めにAZ全体を切り離して影響を回避することが可能となります。
この機能を利用して、これまでGray Failureだった障害の定義を明確にできると言えます。
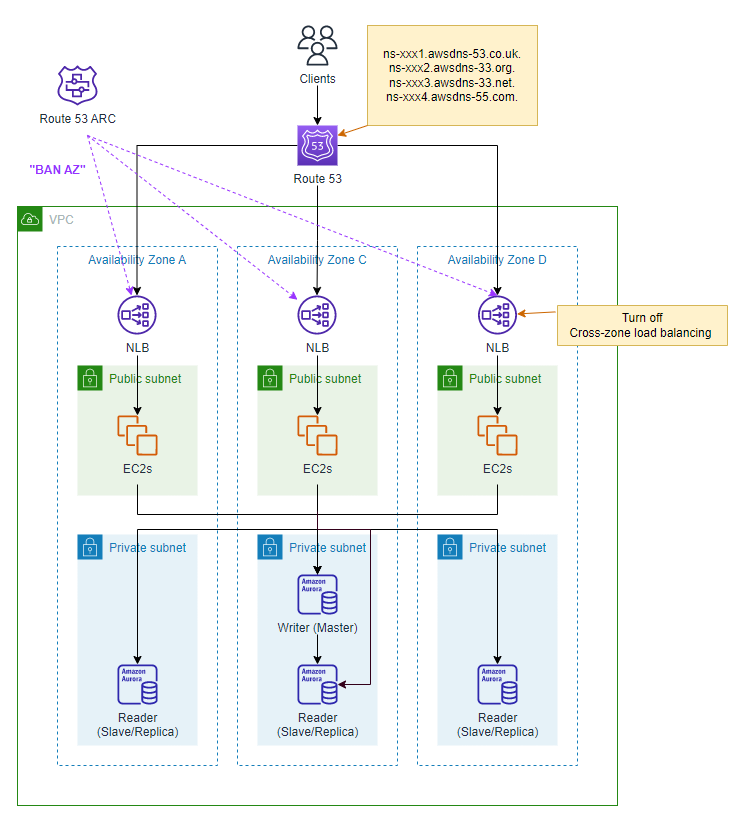
(3) ゾーンシフト機能
AWS re:Invent 2022でリリースされた、Amazon Route 53 Application Recovery Controllerのゾーンシフト機能を使用すると、異常が発生したAZに対するリクエストのルーティングを停止できます。
この機能を利用するには、NLBのクロスゾーン負荷分散を無効にする必要があります。
クロスゾーン負荷分散を無効にする
先ほどまでの構成図は既にそのような絵になっていますが、各AZのアプリケーションのセットの単位で独立してリクエストを処理するイメージとなります。
クロスゾーン負荷分散を無効にした時にリクエストがどうルーティングされるかのイメージは、以下の解説が大変分かりやすいです。
クロスゾーン負荷分散が有効の時
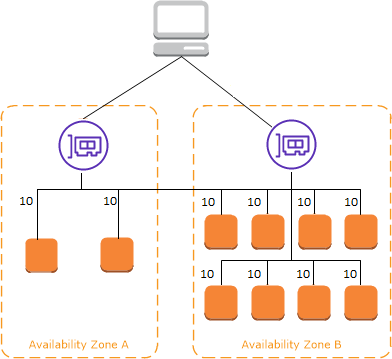
引用: Elastic Load Balancing の仕組み
全てのAZのEC2インスタンスのリソースを無駄なく使えますので、何事もなければこちらが良いです。
次にクロスゾーン負荷分散が無効だとどうなるかを見ていきます。
クロスゾーン負荷分散が無効の時
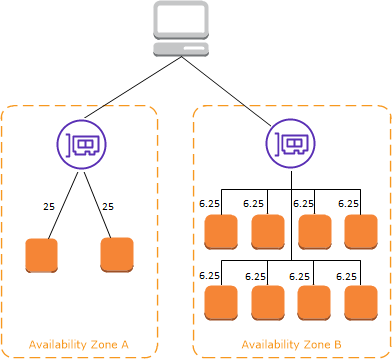
引用: Elastic Load Balancing の仕組み
上記でイメージが掴めますが、クロスゾーン負荷分散を無効にする場合、各AZのロードバランサーノードにリクエストが到達した時点で、他のAZに出ることがなくなります。
全てのトラフィックが各EC2インスタンスに均等に分散されるためには、各アプリケーションのセットが同じ(均一な)構成である必要があります。
また、クロスゾーン負荷分散が無効の場合は、ターゲットグループに正常なインスタンスが1台もいない場合に、ロードバランサーノードのDNS名が解決できなくなるため、AZごと切り離すことができます。
ゾーンシフトを実行する
ゾーンシフトはマネジメントコンソールまたはCLIを利用して実行(発動)するため、何を持ってそのAZが異常と見なすかを決めておく必要があります。
例えば、以下の方法となります。
- 各アプリケーションのセット(AZ)ごとのNLBのDNS名に対し、CloudWatch Syntheticsでリクエストを送って監視
- AWS Health DashboardでAZ障害の有無を監視
また、ゾーンシフト機能では有効期限を1分から3日(72時間)までの範囲で設定する必要があります。
無期限で設定することはできません。
この特徴は非常に重要で、ゾーンシフトはAZ障害における一番最初の暫定復旧に使う機能であると覚えておく必要があります。
戦略としては、ゾーンシフトを発動するタイミングで障害原因がはっきり分かっている必要はなく、あるAZだけリクエストの成功率が悪いという顕著な特徴が現れた時に、迅速にそのAZを切り離すために使用すると覚えておくのが良いでしょう。
また、もう1つの重要なポイントとして、ゾーンシフト機能によってあるAZへのルーティングが停止されたとしても、リクエスト全体を処理できるだけのキャパシティは必要です。
ゾーンシフトを発動する前に、各AZのリソースに余裕があることを良く確認しておく必要があります。
まとめ
これまでの話をまとめると、障害に強く、レジリエンス、すなわち回復力の高いシステムを作るために、我々は大きく以下の2点を考えることができます。
- 単一障害点をなくすこと
- AZごとに複数台のEC2インスタンスを配置
- AZをまたいで冗長性や可用性を確保する
- 複数のレイヤーでフェールオーバーできる仕組みを実装する
- 異常が起きたインスタンスやAZを素早く切り離すこと
- クロスゾーン負荷分散をOFFにする
- 正常なインスタンスが0台になる前にAZごと切り離してしまう
- 緊急退避的にゾーンシフトできるようにする
これらを実現する仕組みが実装されていなければ、そもそも障害からの回復が困難になるケースがあることを意識する必要があるでしょう。
回復性や冗長性を確保しようとすればコストが発生しますが、そのコストが必要だと判断することがまず大事であり、一番最初にすることです。
システムの規模や重要度によって、どこまで実装するかを決めることになります。
また、障害対応とは、まず暫定復旧に始まり、その後に根本原因の特定という流れになります。
大事なことはまずとにかく業務やサービス提供を回復させることです。
冷静に考えることと、枝葉に捉われすぎないことが大変重要となります。
参考文献
- 2019/8/23のAWS東京リージョン大規模障害の経過と原因まとめ
- レジリエンス【resilience】レジリエント / resilient / レジリエンシー / resiliency
- Amazoon Aurora アーキテクチャ概要
- Amazon Builders' Library ヘルスチェックの実装
- Elastic Load Balancing 機能でアプリケーションの可用性を向上
- Cross-zone load balancing for target groups
- Zonal shift
- Elastic Load Balancing の仕組み
- Best practices for Amazon Route 53 Application Recovery Controller
- AWS re:Invent 2022 - Operating highly available Multi-AZ applications (ARC329)