GPU Accelerated K-means
既存のkmeansは遅すぎる
CPUでやった場合のkmeansはscikit-learnなどを使えるのですが、いかんせん遅すぎるのと、kmeansの多くは距離の定義がEuclidであって、word2vecなどのベクトル情報をクラスタリングする際には、あまり意図した通りのクラスタリングになりません
また、実際に、kmeansの学習ステップを見るとほとんどのクラスが安定して更新しなくなってしまっているのに、完全に更新が止まるまで繰り返してしまうので、かなり遅いです。
任意の距離関数を定義できて、GPUで高速化されており、十分な精度やイテレーションを繰り返した上で、停止できるように設計します
cupy
cupyはchainerのバックエンドで用いられているnumpyの一部互換ライブラリであり、行列の計算をGPUで高速に行うことができます
numpyの機能で高機能のものは、まだ使えない面も多いですが、最初にnumpy, cupy双方コンパチブルに動作させるようなことができる場合、CPUで計算させたほうがいい場合、GPUで計算させたほうがいい場合、双方の最適なコードを記述することができます
ベンチマーク
四則演算と、ノルムと、dot積などよく使う系のオペレーションを10回, 10000x10000の行列で計算するベンチマークを入れてみました
import sys
import time
import numpy as np
import cupy as cp
xp = np
if '--gpu' in sys.argv:
xp = cp
b = xp.random.randn(10000, 10000)
start = time.time()
for i in range(10):
m = b*b
d = b - b
a = b + b
de = b/b
xp.dot(b, b)
xp.linalg.norm(b)
inv = b**-1
print( 'now iter', i )
print('elapsed', time.time() - start )
CPU(Ryzen 1700X)で実行
numpyもマルチプロセスで動作するので、Ryzenのような多コアで計算すると、高速に計算することが期待できます
htopでCPUの使用率を見ると、16スレッド全て使い切っています。numpy優秀ですね

$ python3 bench.py --cpu
now iter 0
now iter 1
now iter 2
now iter 3
now iter 4
now iter 5
now iter 6
now iter 7
now iter 8
now iter 9
elapsed 304.03318667411804 #<- 5分かかっている
GPU(Nvidia GeForce GTX1700)で実行
cupyで実行します
cupyで実行する際には、Ryzenのコアは1個に限定される様子が観測できます

その代わり、GPUはフル回転している様子が観測できます
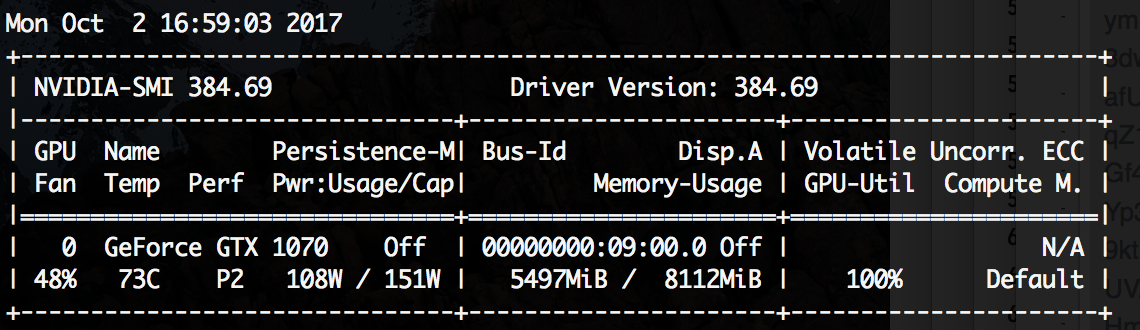
$ python3 bench.py --gpu
now iter 0
now iter 1
now iter 2
now iter 3
now iter 4
now iter 5
now iter 6
now iter 7
now iter 8
now iter 9
elapsed 102.1835367679596 # <- 100秒程度に短縮できた
Ryzenと比較しても3倍程度早くなることがわかりました
CPUはSingle Threadで動作するので、他の分析オペレーションを回すことができます
やりたいこと
word2vecやfastTextでベクトル化した単語について、コサイン類似度を取ると似たような意味の単語を取得することができます
今までscikit-learnのkmeansでやっていたのですが、scikit-learnsのkmeansにはいくつかの課題があります
- マルチコアやGPUの機能が発揮できずに、遅い
- 距離がEuclidしか使えない
これを今回作るプログラムではこのようにします
- cupyを使えるところには使うことで高速化する
- 距離関数をcosine similarityを使うことで、単語の意味の近い集合を作る
コード&パラメータ
gpu_kmeans.pyという実行ファイルの先頭部分に入力ファイル、クラス数、入力ベクトル数、最大イテレーション数などを定義することができます
# here is defines
vector_size = 100 # 入力ベクトルサイズ
cluster_num = 200 # クラス数
max_iter = 120 # 最大イテレーション数
input_file = './make_word_vector/index_meta.pkl' # 入力ファイル
入力ファイルのフォーマット
入力ファイルは、pickle形式でシリアライズされた以下のようなdict型のフォーマットになります
input_raw = {
0 : {'vec':[0.1, 0.2, ... 0.9], 'word':'something'},
1 : {'vec':[0.2, 0.3, ... 0.9], 'word':'anything'},
....
}
0,1...とインデックスが振られているのは、理由があって、numpy, cupy形式のアレーはその構造上、順序に意味があるのでこのようにしています
実行
$ python3 gpu_kmeans.py
出力として各クラスの所属が記載されたindex_result.jsonというファイルが出力されます
"167": {
"word": "世界",
"category": 182
},
"168": {
"word": "向け",
"category": 25
},
"169": {
"word": "企業",
"category": 110
},
"170": {
"word": "感じ",
"category": 169
},
"171": {
"word": "行わ",
"category": 126
結果
単語を200のカテゴリごとに分けるとこのように意味の近いだろう集合が見て取れる結果が得られました
['労働経済白書', '労働者', '労働者健康安全機構', '労働者災害補償保険', '労働金庫', '労災保険料', '労賃', '動産', '勤め人', '勤労', '勤労学生控除', '勤労者福祉施設', '勤労者財産形成促進法', '勤務先']
['ゲリーウェバーオープン', 'ゲリーウェバー・オープン', 'ゲリーウェーバー・オープン', 'ゲリー・ウェバー・オープン', 'ゲリー・ウェーバー・オープン', 'ゲームスコア']
['伊豆の国市', '伊豆の国市古奈', '伊豆の国市四日町', '伊豆の国市浮橋', '伊豆の国市田中山', '伊豆の国市田京', '伊豆ベロドローム', '伊豆市', '伊豆市']
['★★★★★★★★★★', '★★★★★★★★★☆', '★★★★★★★★☆☆', '★★★★★(']
['てるてる家族', 'とせ', 'とと姉ちゃん', 'となりの山田くん', 'とらドラ!', 'とりかへばや物語', 'どろろ', 'どんぴしゃ', 'ど根性ガエル']
簡単に高速化できたので、みなさんやるといいと思います
コードはこちらにあります