名前の性別を識別する問題で、AUCを計算する
偽陽性率、真陽性率のバランスをとることで、間違って判断してしまうリスクなどのバランスをとることで、誤って判別するリスクを最小化しながら、
正しく判別される率を担保することができます。
また、単純なAccuracyの観点からはカバーできない、非対称なデータセットなどについてもROC曲線を描き、AUCを計算することで評価可能です。
問題設定
アメリカの各州の出生した人の性別と、名前と、その年の集計表のデータセットを利用します。
kaggleのopen dataで公開されており、誰でも参照利用することができます。
LightGBMで名前のcharactor levelのベクトルと、州、年を特徴量として、分類してみましょう。
この問題設定ではAUCを手計算することで、AUCが一体何なのかの理解を促進することを目的としています。
データをどうするか
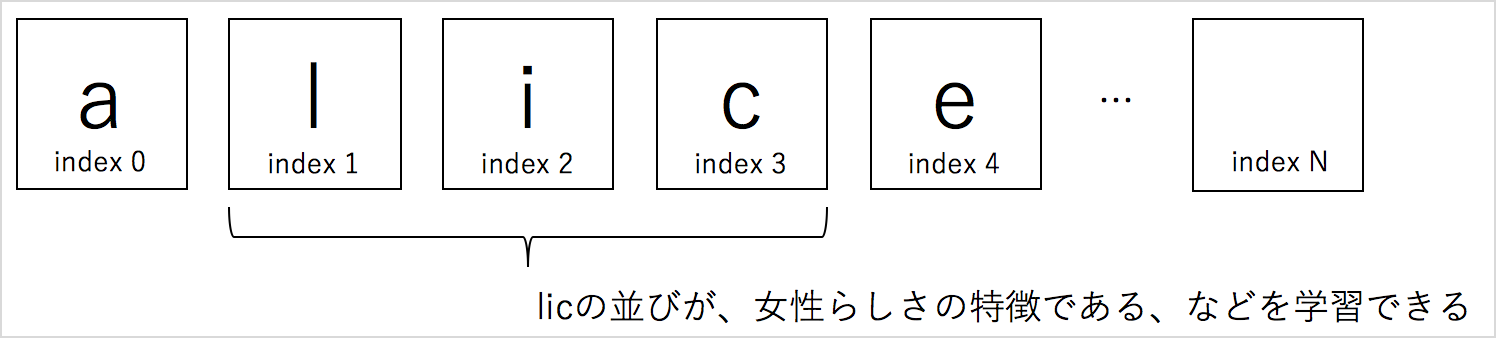
LightGBMはカテゴリ変数を効率的に扱うことができ、ある特定の文字の組み合わせが、性別を説明する特徴を持つとき、勾配ブーストはその組み合わせ表現を獲得することができます。
またCharactorLevel-CNNは位置がずれても組み合わせによる表現のパターンを獲得することができ、位置が変動するような。より長文では、CNNのほうがいいのですが、名前のようなものだと、勾配ブーストでも(それなりに)学習できます。
前処理
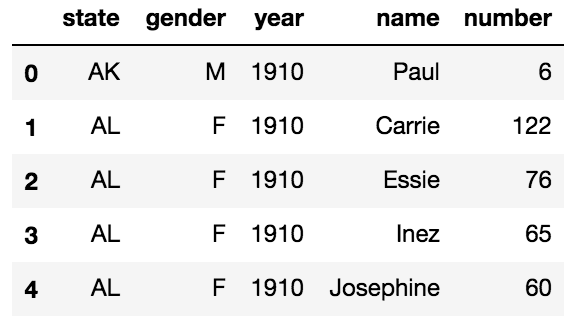
Pandasでデータを読み取り、名前を文字粒度で分解して、インデックスを振り、カテゴリ変数にするために前処理を行います
import pandas as pd
import numpy as np
df = pd.read_csv('name.csv.gz')
df.head()
# slicing name to map each index
char_index = {char:index+1 for index,char in enumerate('abcdefghijklmnopqrsutvwxyz')}
def slicer(i, name):
try:
char = name[i].lower()
return char_index[char]
except:
return 0
for i in range(20):
df[f'name_index_{i:04d}'] = df['name'].apply(lambda x:slicer(i, x)).astype(np.int16)
データセットをtrainとvalidationに分割してLightGBMのデータセットにします
state_index = { state:index for index, state in enumerate(set(df['state'].tolist())) }
df[f'state_index'] = df['state'].apply(lambda x:state_index[x]).astype(np.int16)
y = df[ 'gender' ].apply(lambda x: 1.0 if x == "F" else 0.0)
predictors = [f'name_index_{i:04d}' for i in range(20)] + ['year', 'number', 'state_index']
categorical = [f'name_index_{i:04d}' for i in range(20)] + ['state_index']
from sklearn.model_selection import train_test_split
xtr, xva, ytr, yva = train_test_split(df.drop(['state', 'gender', 'name'], axis=1), y, test_size=0.10, random_state=23)
import lightgbm as lgb
lgtrain = lgb.Dataset(xtr, ytr.values,
feature_name=predictors,
categorical_feature = categorical)
lgvalid = lgb.Dataset(xva, yva.values,
feature_name=predictors,
categorical_feature = categorical)
学習
lgbm_params = {
'task' : 'train',
'boosting_type' : 'gbdt',
'objective' : 'binary',
'metric' : 'auc',
'max_depth' : 15,
'num_leaves' : 33,
'feature_fraction': 0.7,
'bagging_fraction': 0.8,
'learning_rate' : 0.9,
'verbose' : 0
}
lgb_clf = lgb.train(
lgbm_params ,
lgtrain ,
num_boost_round=16000 ,
valid_sets = [lgtrain, lgvalid],
valid_names = ['train','valid'] ,
early_stopping_rounds=200 ,
verbose_eval=200
)
lgb_clf.save_model('model')
予想とAUCの計算
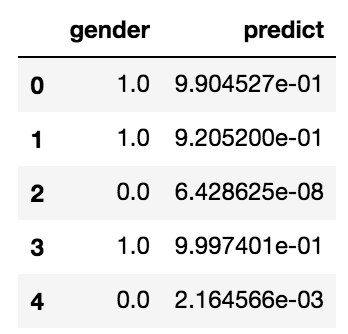
validationを予想して、正解とのペアが記されたcsvを出力します
lgb_clf = lgb.Booster(model_file='model')
ypr = lgb_clf.predict(xva)
ypr = pd.DataFrame(ypr)
ypr.columns = ['predict']
yva = pd.DataFrame(yva).reset_index()
yva = yva.drop(['index', 'level_0'], axis=1)
ys = pd.concat([yva, ypr], axis=1)
ys.to_csv('ys.csv', index=None)
ys.head()
validationでROC曲線を描く
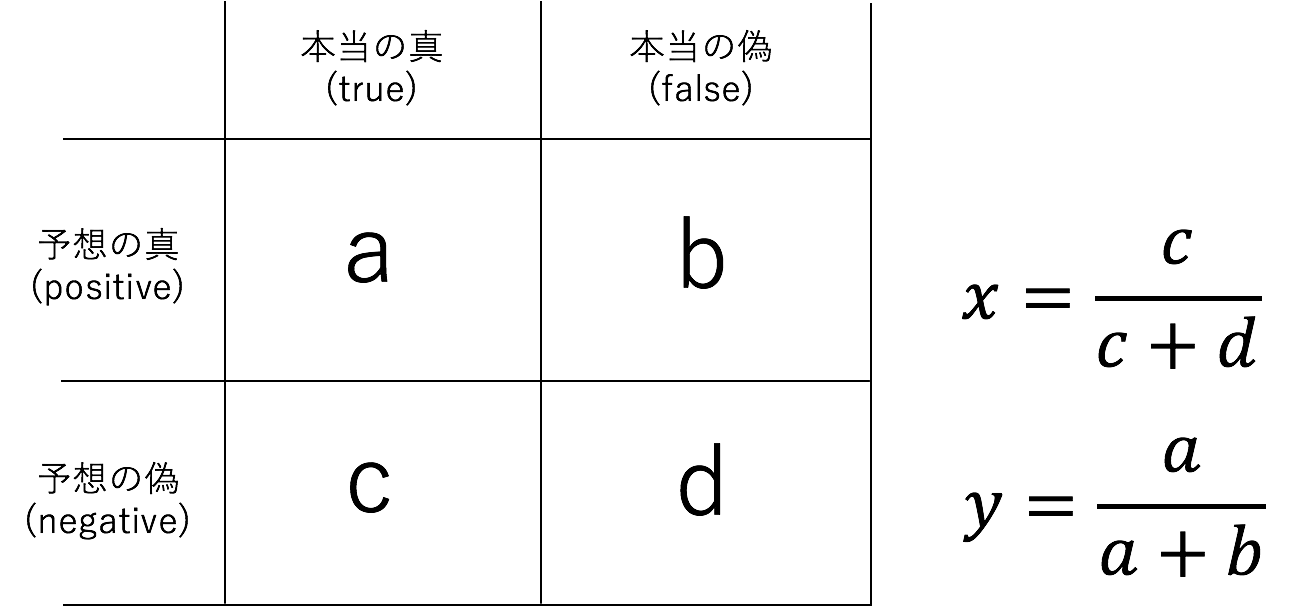
2値分類では、真偽と判断されるしきい値を変化させながら、以下の表を、しきい値分、作成します
import pandas as pd
df = pd.read_csv('ys.csv')
for th in [ 0, 0.0001, 0.01, 0.1, 0.5, 0.8, 1]:
tp, tn, fp, fn = 0, 0, 0, 0
for o in df.to_dict('record'):
#print(th, o)
real = o['gender']
pred = 1 if o['predict'] >= th else 0
if real == 0 and pred == 1:
fp += 1
if real == 1 and pred == 0:
fn += 1
if real == 1 and pred == 1:
tp += 1
if real == 0 and pred == 0:
tn += 1
print('ratio_tp', tp/(tp+tn), 'ratio_fp', fp/(fp+ft))
これを実行するとこのような結果を得られます。
$ python3 auc_calc.py
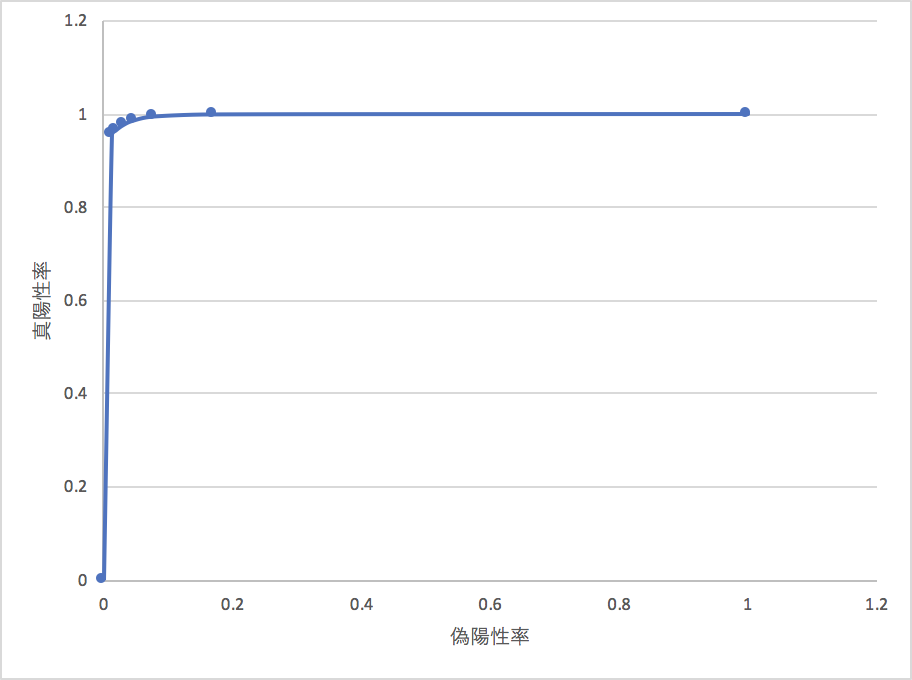
AUCの数値的な値自体は、2値分類においては、判別しきい値を変動させプロットさせるのですが、実際にはScikit-Learn等のソフトウェアで行うと、手っ取り早いです。
しきい値を連続的に変化させながら、判別の性能を見ると、しきい値が下がると右に全体のサンプル数が寄っていくことが確認できるかと思います。
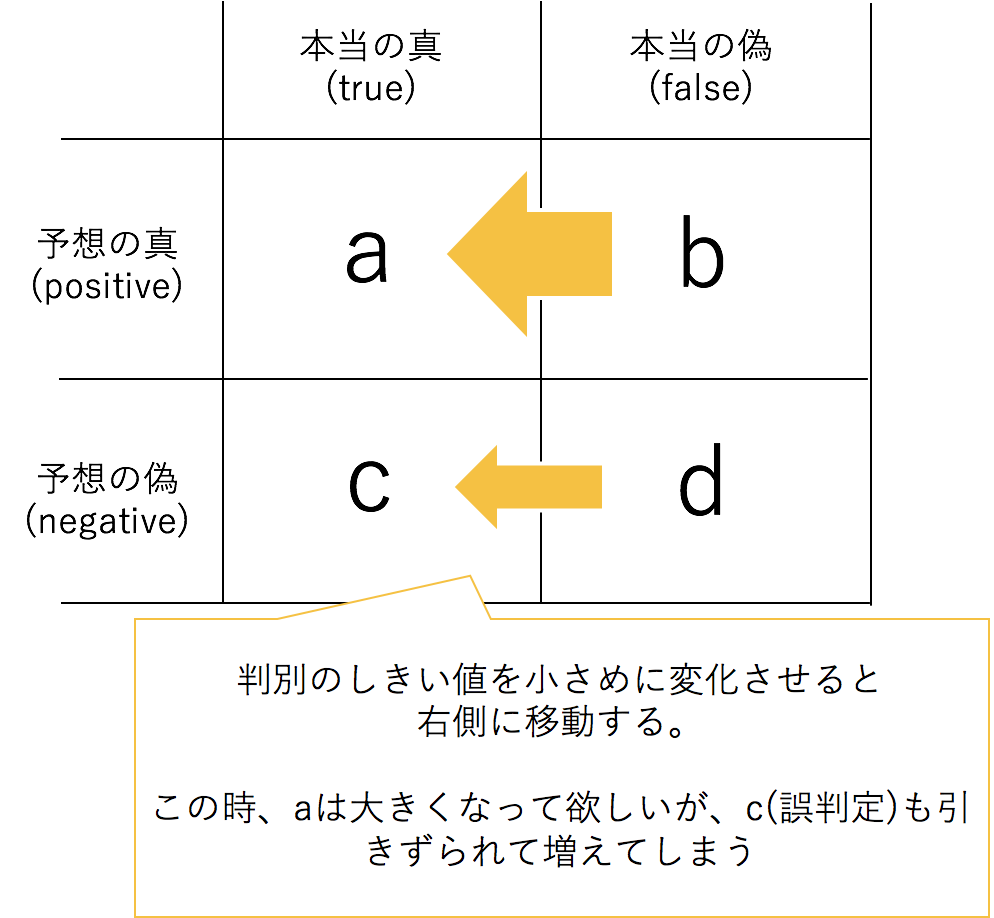
理想的な状態

Appendix
今回、利用したデータは、Kaggleから、この学習と評価に用いたJupyter Notebookはこちらから参照する事ができます。