はじめに
この記事では,国土地理院が公開している セマンティック・セグメンテーション 用の 空中写真データセット を利用して,空中写真から道路領域を検出することに挑戦します.国土地理院の報告では,評価指標であるF値(Dice係数)が 0.8以上 となったそうです.このF値(Dice係数)と同等の精度を得ることを目標にPyTorchで実装して確認します.
地物抽出用の空中写真データセット
空中写真データセット(GSIデータセット)が国土地理院より公開されました. この空中写真(航空写真)は,平成30年度〜令和4年度にかけて実施された国土地理院の特別研究において作成された機械学習用のデータセットです.後述の セマンティック・セグメンテーションと呼ばれる手法の訓練データとして利用が可能であり,国土地理院技術資料として広く公開することになったそうです.現在は 道路 , 水部 , 防波堤 , 太陽光発電設備 , タンク , 透過水制 の6種類が公開されており,近日中に 普通建物 , 茶畑 の2種類が公開されると発表されています.
| 対象 | 着色 |
|---|---|
| 道路 | 道路を赤色に着色 #FF0000 |
| 水部 | 水部を青色に着色 #0000FF |
| 防波堤 | 防波堤を黄色に着色 #FFFF00 |
| 太陽光発電設備 | 太陽光発電設備を黄色に着色 #FFFF00 |
| タンク | タンクを赤色に着色 #FF0000 |
| 透過水制 | 透過水制を黄色に着色 #FFFF00 |
ここでは,道路の空中写真データセットに着目し,機械学習ライブラリのPyTorchを利用して,セマンティック・セグメンテーションを実装し,その精度を確認することを目的とします.道路のデータセットは, 286x286ピクセル と 572x572ピクセル の2種類の空中写真が提供されています.ここでは,前者の286x286ピクセルの空中写真を利用します.サンプル数は$N=10000$です.空中写真は地上画素寸法20cmで撮影されており,これは1ピクセルの長さが20センチメートルであることを意味しています.このため,画像の1辺の長さは57.2メートルです(次の式で算出).
$$
286(px) \times 20(cm)=5720(cm)=57.2(m)
$$
データセットに含まれる空中写真の例を示します(上から順に32.png,240.png,615.png).左がオリジナルの画像(空中写真),右が道路のマスク画像です.この色付け(ラベリング)は人手によって行われたそうです.マスク画像に含まれる道路領域が赤で着色されていることが確認できますが,田んぼの畦道や駐車場など,道路との境界が曖昧なケースもあるようです.



国土地理院のサイトには,このデータセットを利用することで,評価指標である F値(Dice係数) が0.8以上になったと記載されています.この値にどこまで近付けるか挑戦してみます!
セマンティック・セグメンテーション
セマンティック・セグメンテーション(Semantic Segmentation)は,画像の画素をラベリング(分類とも考えられる)する手法のことです.セマンティック・セグメンテーション用のデータセットとして COCO や CityScapes などが有名です. COCOは,人(person),バックパック(backpack),傘(umbrella)など80種類のオブジェクトを対象としたデータセットです.また,CityScapesは,道路(road),車(car),建物(building)など都市の風景を対象としたデータセットです.
COCOデータセットに含まれるサンプル画像を次に示します.最初の画像には,人物(person),犬(dog),自転車(bicycle)などのラベルが色付けされています.2番目の画像には,人物(person),鳥(bird),ハンドバッグ(handbag)などのラベルが色付けされています.本記事で取り上げる空中写真データセットも,これらと同種のデータセットとみなすことができます.


学習モデル
セマンティック・セグメンテーションには,畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)を拡張したSegNet,U-Netなどのモデルが用いられます.
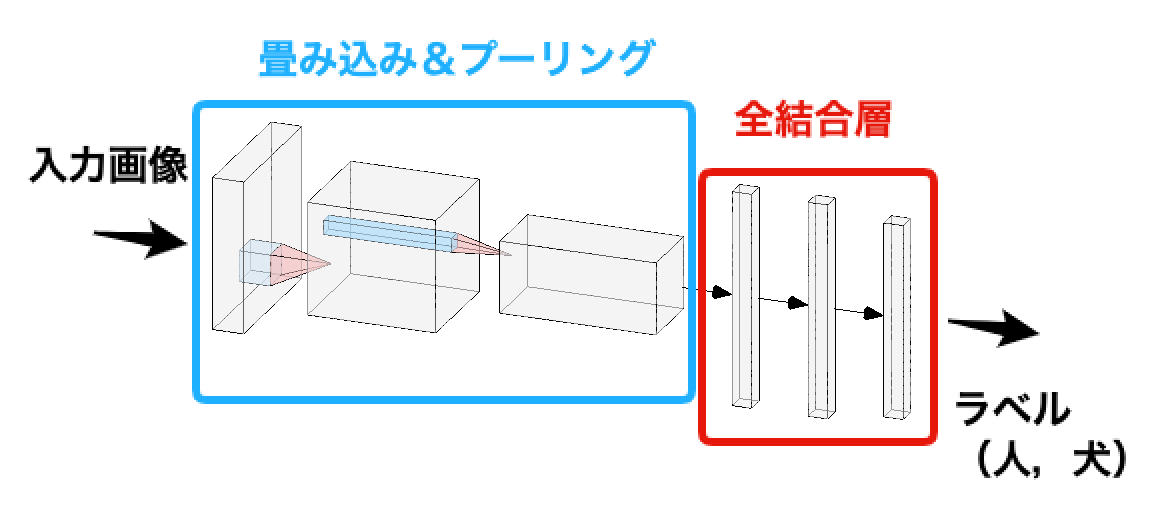
標準的なCNNは次の図で示すような構造となっています.入力画像は,畳み込み層&プーリング層でダウン・サンプリングされることで特徴抽出がなされ,最後は全結合層で分類結果を表す ラベル(人,犬など) が出力されます.
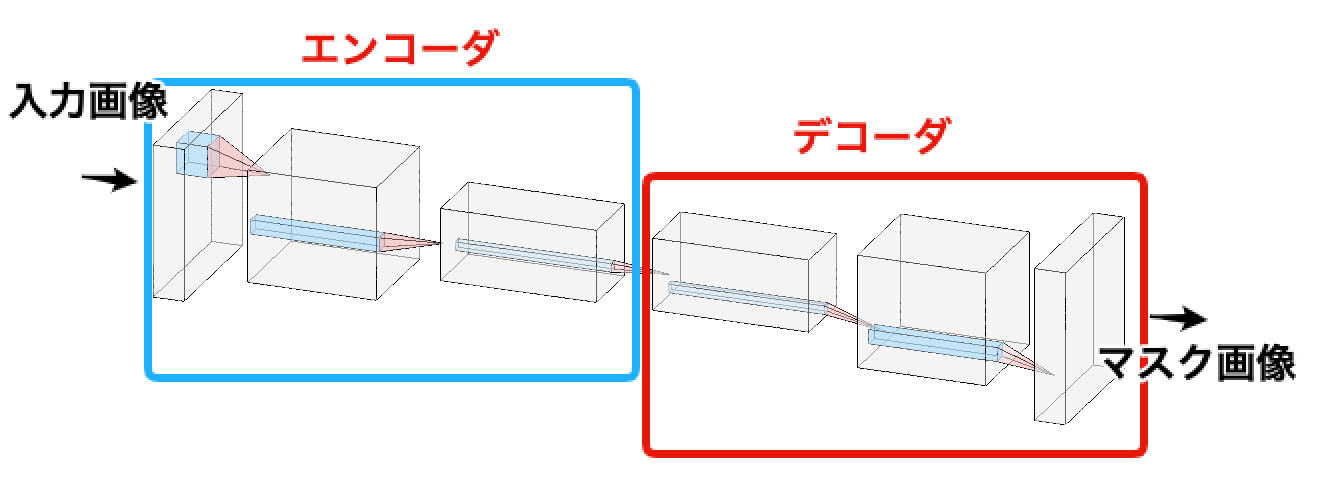
これに対し,SegNetは次の図で示すような構造となっています.Encoder-Decoder型と呼ばれる構造であり,入力画像はエンコーダでダウン・サンプリングされることで特徴抽出されます.その後,デコーダでダウン・サンプリングと同じだけのアップ・サンプリングされることで,入力画像に対応する マスク画像 を出力します.U-NetもEncoder-Decoder型のモデルであり,スキップ接続 と呼ばれる方法で,ダウン・サンプリングで消失される情報を保持する工夫が加えられています.後述のセマンティック・セグメンテーションの実装では,U-Netを採用します.
評価指標
学習モデルの評価には Dice Score と IoU Scoreを採用することにします.また,学習の損失関数には,1からDice Scoreを引いた Dice Lossを用います.下図の例で考えてみましょう.左から「正解のマスク画像(訓練データ)」,「予測されたマスク画像」,「正しく予測されたピクセル(正解と予測が重なっているピクセル)」を表しています.画像は$5 \times 5 = 25$のピクセルで構成されています.
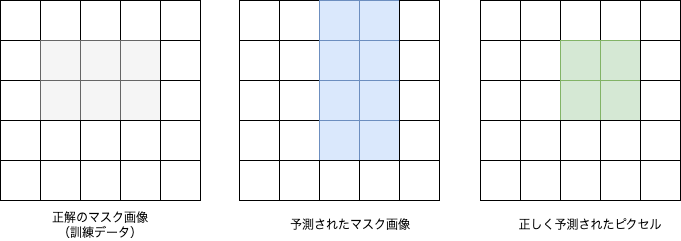
この画像の中で下記の条件を満たすピクセルを数えることで, TP(True Positive) ,TN(True Negative) ,FP(False Positive) ,FN(False Negative) を算出します.これらの値から後述の 適合率(Precision) と 再現率(Recall) が求められます.
- TP: マスクと予測し,実際にマスクだったピクセル数
- TN: 背景と予測し,実際に背景だったピクセル数
- FP: マスクと予測し,実際は背景だったピクセル数
- FN: 背景と予測し,実際はマスクだったピクセル数
| Positive | Negative | |
|---|---|---|
| True | TP=4 | TN=15 |
| Fase | FP=4 | FN=2 |
適合率(Precision)
適合率は,マスクと予測されたピクセル数($TP+FP$)に占める,実際にマスクだったピクセル数($TP$)の割合です.
$$
Precision = \frac{TP}{TP+FP}=\frac{4}{4+4} = 0.5
$$
再現率(Recall)
再現率は,実際のマスクのピクセル数($TP+FN$)に占める,マスクと予測されたピクセル数($TP$)の割合です.
$$
Recall = \frac{TP}{TP+FN}=\frac{4}{4+2} \simeq 0.67
$$
Dice Score(Dice係数)
F値とも呼ばれます.上記の適合率と再現率の調和平均です.適合率と再現率のバランスを考慮した評価指標です.予測されたマスクが正解のマスクと完全に一致したときに$Dice=1$になります.
$$
Dice = \frac{2}{\frac{1}{Precision} + \frac{1}{Recall}} = \frac{TP}{TP+\frac{FP+FN}{2}}= \frac{4}{4+\frac{4+2}{2}} \simeq 0.57
$$
また,損失関数として用いる Dice Loss は次の式で算出されます. Dice Lossの最小化は,Dice Scoreの最大化と同じ結果となります.
$$
DiceLoss = 1 - Dice \simeq 0.43
$$
IoU Score (Intersection over Union Score)
ジャッカード係数(Jaccard Score)とも呼ばれます.正解のマスクのピクセル集合を$A$,予測されたマスクのピクセル集合を$B$とします.このとき,和集合$A \cup B$に占める,共通集合$A \cap B$の割合です.Dice Scoreと同様に,予測されたマスクが正解のマスクと完全に一致したときに$IoU=1$になります.
$$
IoU = \frac{TP}{TP+FP+FN}=\frac{4}{4+4+2}=0.4
$$
実装
PyTorchを利用して,空中写真のデータセットを学習するためのU-Netを実装します.実装にはSegmentation Modelsというライブラリを利用します.
# Segmentaion Modelsのインストール
!pip install -U segmentation-models-pytorch
空中写真のデータセットに含まれる画像のリストを次の形式のpandasのデータフレームdataset_dfで保持することにします.ここで, org はオリジナル画像のパス, val はマスク画像のパスです.データセットに含まれるサンプル数は$N=10000$ですが,ここでは簡単化のため,1.pngから1000.pngまでの$N=1000$のサンプルを対象とします.
| index | id | org | val |
|---|---|---|---|
| 0 | map-1 | ./dataset/gsi-1000/org286/1.png | ./dataset/gsi-1000/val286/1.png |
| 1 | map-2 | ./dataset/gsi-1000/org286/2.png | ./dataset/gsi-1000/val286/2.png |
| 2 | map-3 | ./dataset/gsi-1000/org286/3.png | ./dataset/gsi-1000/val286/3.png |
| 3 | map-4 | ./dataset/gsi-1000/org286/4.png | ./dataset/gsi-1000/val286/4.png |
| 4 | map-5 | ./dataset/gsi-1000/org286/5.png | ./dataset/gsi-1000/val286/5.png |
# データセットのデータフレーム
dataset_df = pd.read_csv(dataset_file)
データセットに含まれるマスク画像は,道路が赤(#ff0000)でマスクされています.このままでは,PyTorchのマスクとして利用することができません.そこで,次のgenerateMask関数を定義し,道路は1,その他は0のバイナリ画像(PillowのImageオブジェクト)に変換します.
# マスク画像の生成
def generateMask(image):
width, height = image.size
image_mask = Image.new("1", (width, height)) # "1"はバイナリ画像
for x in range(width):
for y in range(height):
r, g, b = image.getpixel((x, y))
# 赤のとき
if(r == 255 and g == 0 and b == 0):
image_mask.putpixel((x, y), (1)) # ピクセルの値を1に設定
else:
image_mask.putpixel((x, y), (0)) # ピクセルの値を0に設定
return image_mask
PyTorchでデータセットを読み込みためのクラスGSIDatasetを定義します.__getitem__関数は指定されたインデックスのサンプルを返します.サンプルはオリジナル画像image_orgとマスク画像image_maskのタプルで表されます.また,__len__関数はデータセットに含まれるサンプル数を返します.
# データを読み込むためのクラス
class GSIDataset(Dataset):
def __init__(self, dataset_df, transform):
self.dataset_df = dataset_df
self.transform = transform
self.id_list = dataset_df["id"].to_list()
self.org_list = dataset_df["org"].to_list()
self.var_list = dataset_df["val"].to_list()
# サンプルの取得(オリジナル画像とマスク画像)
def __getitem__(self, index):
with open(self.org_list[index], "rb") as f_org:
image_org = Image.open(f_org)
image_org = self.transform(image_org)
with open(self.var_list[index], "rb") as f_var:
image_var = Image.open(f_var)
image_mask = generateMask(image_var) # マスク画像をPyTorch用に変換
image_mask = self.transform(image_mask)
return (image_org, image_mask)
# サンプル数の取得
def __len__(self):
length = len(self.dataset_df)
return length
交差検証のためデータセットを訓練用と評価用で$9:1$に分割します.訓練用のサンプル数は900,評価用のサンプル数は100となります.train_transformとeval_transformは画像に対する前処理です.ここでは,画像サイズを$286 \times 286$から,$256 \times 256$に縮小します(32の倍数という制約があるため).加えて,画像をランダムに上下左右に反転することでデータ拡張(Data Augumentation)します.
# データセットを訓練用と評価用に分割(9:1)
train_df, eval_df = train_test_split(dataset_df, shuffle=True, test_size=0.1, random_state=random_state)
train_df = train_df.reset_index(drop=True) # 訓練用
eval_df = eval_df.reset_index(drop=True) # 評価用
train_dataset = GSIDataset(train_df, train_transform) # 訓練用
eval_dataset = GSIDataset(eval_df, eval_transform) # 評価用
ミニバッチ学習用のデータローダを作成します.バッチサイズは16とします.
# 学習用データローダ
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
# 評価用データローダ
eval_dataloader = DataLoader(eval_dataset, batch_size=16, shuffle=False)
U-Netのモデルを定義します.エンコーダにはResNetを採用します.入力はRGB画像であるためin_channels=3,1クラスの分類("道路"と"その他")のためclasses=1,出力画像の各ピクセルは0から1の範囲で表すためactivation="sigmoid"を設定します.
# U-Net
network = smp.Unet(
encoder_name="resnet34",
encoder_weights="imagenet",
in_channels = 3,
classes = 1,
activation = "sigmoid",
)
損失関数に DiceLoss ,評価指標に IoU ,最適化手法にAdamを採用します.
# 損失関数(DiceLoss)
loss = DiceLoss()
# 評価指標(IoU)
metrics = [
IoU(threshold=0.5),
]
# 最適化手法(Adam)
optimizer = torch.optim.Adam([dict(params=network.parameters())])
モデルの学習における振る舞いを定義します.上記で定義した損失関数,評価指標,最適化手法を設定します.
# 学習用のエポック
train_epoch = TrainEpoch(
network,
loss = loss,
metrics = metrics,
optimizer = optimizer
)
# 評価用のエポック
eval_epoch = ValidEpoch(
network,
loss = loss,
metrics = metrics
)
100エポックでモデルを学習します.各エポックで, DiceLoss と IoUが算出され,これを後述で可視化します.
for i in range(100):
train_logs = train_epoch.run(train_dataloader) # 学習
print(train_logs)
eval_logs = eval_epoch.run(eval_dataloader) # 評価
print(eval_logs)
実験結果
DiceLoss と IoU の推移を次に示します.損失関数のDiceLossは,学習が進むと減少していくことが確認できます.また,評価指標のIoUは,学習が進むと増加していくことが確認できます.学習は順調に推移し,いずれも一定値に収束しており,過学習(オーバフィッティング)は確認できませんでした.
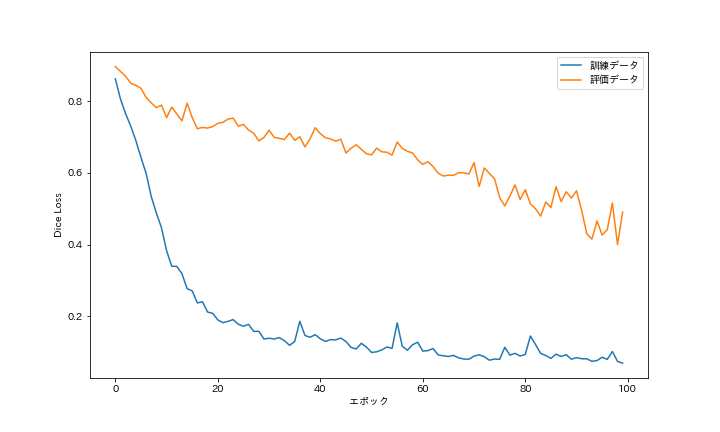
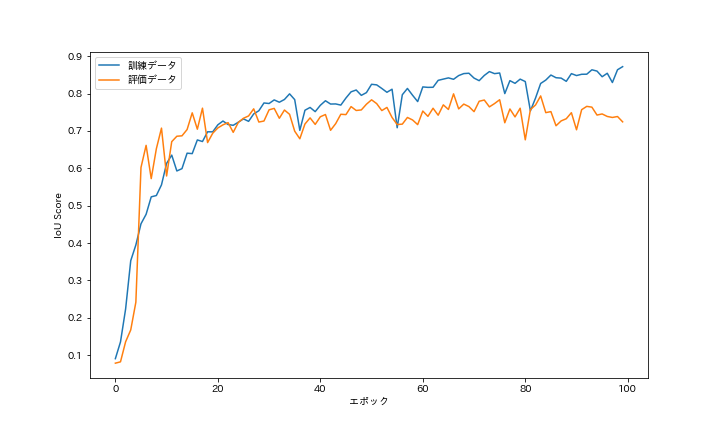
DiceとIoUの最大値を次の表にまとめます(Diceは1からDiceLossを引いた値).国土地理院のサイトには,Dice(F値)が 0.8 以上になったと記載されていました.今回の実験では,訓練データは 0.931 であり,0.8を超える結果となりました.一方,評価データは 0.600 であり,0.8には到達できませんでした.国土地理院の結果は,評価データに対するスコアだと思われ,大きな差があります.まだまだ工夫の余地がありそうです.
| Dice Score | IoU Score | |
|---|---|---|
| 訓練データ | 0.931 | 0.872 |
| 評価データ | 0.600 | 0.799 |
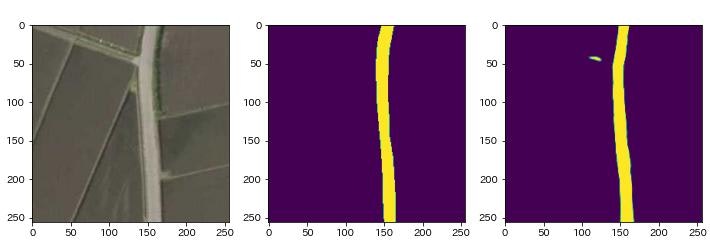
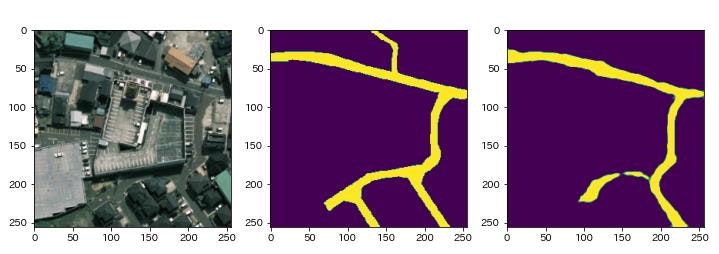
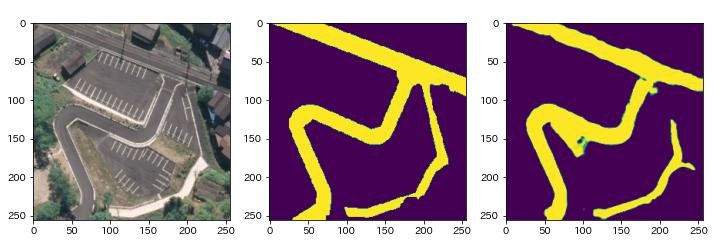
次に学習したモデルを利用してマスク画像(道路位置の予測)を生成します(上から順に32.png,240.png,615.png).左はオリジナル画像,中央は正解のマスク画像,右は予測したマスク画像です.いずれも道路のおおまかな形状や配置を予測できています.しかし,道路の接続が切断されてしまうなど,不完全な箇所も多く存在します.正確な情報を必要としない地物調査などの用途には,適用可能な精度と言えそうです.
まとめ
本記事では,国土地理院が公開した空中写真データセットを利用して,空中写真から道路を抽出するセマンティック・セグメンテーションを実装してみました.国土地理院のサイトに記載されている「Dice(F値)が0.8以上」には到達できませんでしたが,道路のおおまかな形状と配置の認識が可能であることを示すことができました.今後は,U-Netとは異なるモデル(U-Net++など)の適用を検討するとともに,セマンティック・セグメンテーションを活用した交通事故分析などの応用に取り組みたいと思っています.
出典
- 国土地理院(2022):CNNによる道路抽出のための教師画像データ,国土地理院技術資料 H1-No.17.
- "Microsoft COCO: Common Objects in Context", Lin, Tsung-Yi et. al., arXiv, 2014
- "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation", Badrinarayanan, Vijay et. al., arXiv, 2015
- "U-Net: Convolutional Networks for Biomedical Image Segmentation", Ronneberger, Olaf et. al., arXiv, 2015
- "Deep Residual Learning for Image Recognition", He, Kaiming et. al, arXiv, 2015
- "Adam: A Method for Stochastic Optimization", Kingma, Diederik P et. al., arXiv, 2014
- "UNet++: A Nested U-Net Architecture for Medical Image Segmentation", Zhou, Zongwei et. al., arXiv, 2018