これは何
ドキュメント検索の一要素(弱学習機のひとつ)に、流行りのSentence BERT(SBERTと略します)を使うために勉強したことの個人的なまとめです。これが参考になる人がいる気がする(少なくても自分のチームのエンジニアの方々には)ため、Qiitaに残します。
想定読者
インフラよりの検索エンジニア。機械学習の実行環境の構築はわかるが、その上で何をどう動かしてるかについて、いまいちピンと来てない人向け
話すこと
以下、をざっくりと
- SBERT がなぜ検索エンジニアにとって重要そうか
- SBERT を使うためのツールやモデル学習の考え方
- 今回のコードの解説(改善の余地はたくさんありそうですが、とりあえず動きはしました)
話さないこと
ざっくりと、でないこと。詳細は下記参考資料などを参照してください。
Colab以外での実行環境の構築や、実際のサービスの検索エンジンにSBERTどう反映させるかも今回は触れません。
参考にした資料
以下の情報はもう古いです。2023年2月現在ならsentence-transformersでの実装が良いと思います
教科書。BERTの様々な使い方と各種ツールの使い方について一通り初学者でもわかるように書かれています。おすすめです
上記の教科書のコードです。特にChapter6のものが参考になりました
SBERTについての日本語の解説記事。サンプルデータもこちらのものを参照です。やってることはこちらの記事の方が上位互換なところがありますが、差分は(1)利用しているツール類が半分くらい違う(2)想定読者が違う、の2点です。
今回利用した機械学習フレームワークについての公式ドキュメント
pooling(MEAN)の実装の参考に
SBERTがなぜリアルタイム性が高いか(検索応用にはとても重要な点)についての解説が書かれている記事です。この記事自体の主題であるBEETの中間層に眠る情報(SBERTの発展形について)については、残念ながら本記事では全く使えていません。いつか挑戦します。
SBERT がなぜ検索エンジニアにとって重要そうか
SBERTとは、2つの文章が与えられたときに両者の関係性を学習するニューラルネットワークです。
「関係性」は(多分)何でもよく、その関係性をもつ文章の対と、もたない文章の対を大量に用意すれば、学習できるそうです。
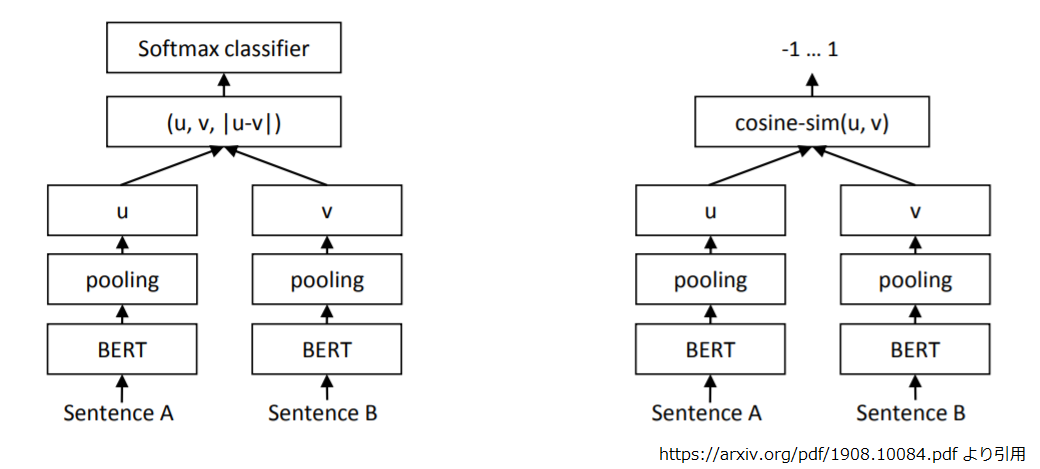
この図の左のネットワークで学習します。
このSentence BERTの大きな特徴のひとつは、この「関係性」が、数学でいう交換法則を満たさないものでも扱えることです。
つまり、関係性を $f$ とおき、文章の対を $x, y$ とおいたとき、 $f(x,y) \neq f(y,x)$ となる関係性でも良いというとです。
交換法則を満たさない文章同士の関係性の例だと、「質問と回答」「検索クエリと検索ドキュメント」といったものが挙げられます。この関係性を求めることは検索エンジニアが扱う主要な課題設定のひとつなので、このSBERTという方法論を検索エンジニアが勉強したほうが良いのでは?と考えています。
また、SBERTを検索に使うさいには、計算時間がかかるドキュメントのBERTによるベクトル表現部分を全部事前計算した上でindex化しておけば、クエリにだけBERT(メジャーワードはキャッシュで対応するなどBERTしないで済むように工夫も)をかけて、検索エンジン側で動的に計算するのはベクトル間のcos類似度だけで済みます。早いレスポンスが求められる「検索」にとって、計算の大半を事前計算に任せられるSBERTは非常に都合が良いです。
ちなみにBERTでは文章内の単語の順番を考慮しています。情報検索の古典的なベクトル空間モデルのように文中の単語だけを見ているわけではないです。
SBERT を使うためのツールやモデル学習の考え方
ツール類
今回、用いた主要なツール類です。
計算環境にGoogle Colaboratoryを使います。無料版だとちょっと学習に時間がかかるとGPUの利用制限に引っかかってしまう点に注意です。
コードはPython3系です。
ニューラルネットワークの構築に、transformersのBERTとpytorch Lightningを使いました。
これらを簡単に例えると、transformers はニューラルネットワークの構築済みデッキみたいなやつ(すぐ戦える)で、pytorch Lightningはニューラルネットワークのフレームワーク(できる限りコードを書かなくて済むようにかなりガチガチ)です。
学習過程の可視化には、TensorBoard を使いました。Jupyter notebookのマジックコマンドで呼び出せるのでかなり便利です。
モデル学習の考え方
大雑把にこんな手順です
- データ用意
- 文章のtokenize
- 学習済み(pretrained)モデルの準備
- 学習済みモデルを組み込んだニューラルネットワークでの fine tuning
- 学習できているか確認
- テストデータでの成績確認
それぞれ細かく見ていきます。
データ用意
ここと同じデータを使いました。学習データ作成のコードもそのまま使いました。
これで、アンカーテキスト(クエリのようなもの)と、ポジティブテキスト(アンカーテキストと関連するもの)と、ネガティブテキスト(アンカーテキストと関連しないもの)のセットが得られます。
データをtrain, validation, test の3つに分けている理由は後ほど本記事でも解説します。
文章のtokenize
BERTに入れる前に文章をtokenizeします。これにはBertJapaneseTokenizerと日本語の事前学習モデルを使いました。
transformersのBertJapaneseTokenizerというクラスのfrom_pretrainedという関数でファイル名を指定するだけで簡単に利用できます。
事前学習モデルは東北大の乾研究室が公開したものです(https://www.nlp.ecei.tohoku.ac.jp/news-release/3284/ )。とてもありがたいです。鈴木正敏さん(博士課程2年)に感謝です。
この中身はMeCab+IPA辞書による分かち書きのようです。このツールを使うと簡単に後続のBERTへの入力にふさわしいフォーマットでのデータが得られます。
学習済み(pretrained)モデルの準備
BERT部分も東北大の乾研究室で公開された事前学習済みモデルを使います。
こちらもtransformersのBertModelというクラスのfrom_pretrainedという関数でファイル名を指定するだけで簡単に利用できます。
学習済みモデルを組み込んだニューラルネットワークでの fine tuning
この辺から、少しは自分でコードを書く必要が出てきます。
fine tuningとは学習済みのモデルを、課題設定やデータに合わせた再学習することでチューニングすることです。BERTは複数の自然言語課題に対して、学習済みのモデルとして機能することで話題になりました。
コードの解説は後半で書くとして、ここで気をつけたことは
- pytorch Lightning にのっかることでコードを書く量を減らす
- 3種類の文章を読み込むための工夫
- Learning rate の探索
です。
pytorch Lightning にのっかることでコードを書く量を減らす
学習のループや、モデルの途中状態の評価やその保存など、「いつもあるやつ」を書かなくて済むように pytorch Lightningという便利なものがあります。
どう書くかは下記を参照してください。大雑把に書くと、LightningModuleというクラスを継承し、そのクラス内関数の必要な箇所だけを上書きする (training_step とか)と、そのクラス内関数のfitを使うだけで学習できるようになります。
これで「いつもあるやつ」を知らなくても、なんとなくニューラルネットワークが書けるようになります。ただ、エラーが出たときやらちょっと道から外れたことがしたくなったときに、「いつもあるやつ」が何なのかわからないとどうしようもなくなるので、このフレームワークを使う場合でも「いつもあるやつ」を知っておいたほうが良いです。本記事では割愛します。
3種類の文章を読み込むための工夫
主にここを参考にしてたのですが、この記事を書いてる途中でリンク切れになりました。
https://pytorch-lightning.readthedocs.io/en/stable/advanced/multiple_loaders.html
この処理でだいぶかっこ悪いことをしてしまっています。後半のコード解説でかきます。
Learning rate の探索
ハイパーパラメータのLearning rateの設定は重要です。これが大きすぎても小さすぎてもいい感じに学習できないです。
pytorch Lightning ではLearning rateを探索し提案してくれる機能があるので、それを使いました。実際のデータでちょっと学習して様子を見る手法のようです(https://arxiv.org/pdf/1506.01186.pdf)。
学習できているか確認
fine tuning実行中は、そもそもちゃんと学習できているのかが気になります。
そもそも学習がちゃんとできているか、の観点に以下の3つが重要です。
- trainに使ったデータでちゃんとlossが減っているか確認
- validation に使ったデータで過学習していないか確認
- 最終的にはtrainにもvalidationにも使っていないtestのデータでモデルの良し悪しを確認
validationはテストデータと違い、モデルの訓練に使うためのデータですが、trainと違いモデルのパラメータ更新(学習)には使わず、trainでの過学習を避けるために使われます。
これは教師付き学習の機械学習全般に使われるテクニックですが、特にニューラルネットワークでは
- モデルの表現力が高く過学習しやすい
- 逐次学習をどこかで止めないとかえって成績劣化するケースが多い
という2つの課題があり、特に2の課題から「学習途中」のモデルを最終的に選ぶことが多く、その選択基準にvalidationによる評価が用いられます。
trainのloss (学習に使う目的関数の値が多い)やvalidationのloss(学習に使う目的関数の値にして過学習具合を直接見たり、解釈しやすい値にして絶対的な性能をみたり)を、学習のループ(stepとよばれる)ごとに、ログにはき、それを確認すれば、学習途中でもちゃんと学習できてそうかを確認できます。
実行中にその結果を確認する方法のひとつに TensorBoard というものがあり、
%load_ext tensorboard
%tensorboard --logdir ./lightning_logs/
というマジックコマンドをうてば利用可能になります。2行目でログの場所を指定しています。いい感じのGUIでlossの変化の時系列などを見ることができます。
テストデータでの成績確認
先程の図です。この右のネットワークで評価します。
下記の手順です。
- アンカーテキストとペアのテキストをfine tuning したBERT(2種類あることに注意)+poolingで文章のembedding(ベクトルで表現されたもの)を得る
- 文章のembedding間でcos類似度を得る
- 今回、ひとつのアンカーテキストにふたつのテキスト(ポジティブとネガティブ)があるため、cos類似度が大きい方をpositiveとみなし、presicionを計算
今回、モデルの評価にpresicionを用いているのは、単に私が情報検索のランキングアルゴリズム課題をpair-wiseで評価することが良いと考えている+その応用を念頭に置いているから (https://qiita.com/naosugi1987/items/ba3bcd3e422ace8e477c )であって、この部分は応用を想定している先の課題設定によって柔軟に変更すべき箇所です。多分、介入の問題設定になるので、私の場合は因果ダイアグラム書いてみてどこの条件付き確率を最大化したいのかを見て、そこからテストデータの作り方や評価指標を考えます。
今回のコードの解説
改善の余地はたくさんありそうですが、とりあえず動きはしました
import pandas as pd
import random
import glob
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
from transformers import BertJapaneseTokenizer, BertModel
import pytorch_lightning as pl
from pytorch_lightning.trainer.supporters import CombinedLoader
import numpy as np
ライブラリを読み込みます。
# 日本語の事前学習モデル
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
tokenizerを読み込みます。from_pretrainedという関数が便利すぎてびっくりしました。
data_val = pd.read_csv('/content/triplet_dev.tsv', sep='\t', encoding='utf-8', names=['a','p','n'])
上で紹介したデータを静的ファイルに保存したものを読み込みます。Colaboratoryはセッションが切れるとディスクも消えるので、起動するたびにアップロードしていました。
PandasのDataframe型である必要はなかったのですが、コードの書きやすさを優先しました。
こんな感じのデータが入ってました。

a はアンカーテキストで、pはポジティブ(アンカーテキストと同じ画像を表している)、nはネガティブ(アンカーテキストとは違う画像を表している)となっています。
#validation
max_length = 16
data_transforms_val = []
texts_a = data_val['a'].values
texts_p = data_val['p'].values
texts_n = data_val['n'].values
dataset_for_loader=[]
for text_a, text_p, text_n in zip(texts_a, texts_p, texts_n):
encoding = {}
for text, f in zip([text_a, text_p, text_n], ['a', 'p', 'n']):
encoding_sub = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True
)
encodin_sub = { k+'_'+f: torch.tensor(v).cuda() for k, v in encoding_sub.items() }
encoding.update(encodin_sub)
dataset_for_loader.append(encoding)
dataloader_val = DataLoader(
dataset_for_loader, batch_size=16, shuffle=False
)
各文章をトークナイズし、そのトークンをGPUにで動かせるようにし(cuda()のところ)、a,p,nの違いをキー名に追記しました。それを並列計算させるためのミニバッチにまとめるためにDataLoaderを使いました。この辺は、自分で触りながら各処理でどんな変換をし、どんなデータが入っているのかを確かめながら理解することをおすすめします。(おそらくここでテキストで丁寧に説明されても頭に入らない気がします)。
これをpytorch lightningのfit関数の引数に指定することでfine tuningができます。
上記と同じ処理をtrainと testのデータにも行います。
やはり、
a,p,nの違いをキー名に追記
はちょっとかっこ悪いので、他の方法も検討しました。
まず、trainのデータに限ってはDataLoaderの配列(a,p,nのそれが入ってる)を入力にすることもできました。しかし、その書き方だとpytorch lightningのfit関数ではvalidationでは違った解釈されるため、trainとvalidationのデータ生成コードに差分が出るため、避けました。
他にもmultiple_loadersというセクションで公式ドキュメントがいくつかの方法を解説していましたが、途中からリンク切れをおこしたこともあり、「きっとこの部分はまだ洗練されてないんだろうな」と考え、今回は一番愚直っぽい書き方を採用しました。
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
class SentenceBERT(pl.LightningModule):
def __init__(self, model_name, lr):
# model_name: Transformersのモデルの名前
# lr: 学習率
super().__init__()
# 例えば、self.hparams.lrでlrにアクセスできる。
# チェックポイント作成時にも自動で保存される。
self.save_hyperparameters()
# BERTのロード
self.bert_sc1 = BertModel.from_pretrained(
model_name
)
self.bert_sc1.cuda()
self.bert_sc2 = BertModel.from_pretrained(
model_name
)
self.bert_sc2.cuda()
self.triplet_loss = torch.nn.TripletMarginWithDistanceLoss(distance_function=torch.nn.PairwiseDistance(p=2), margin=1.0)
#self.triplet_loss = torch.nn.TripletMarginWithDistanceLoss(distance_function=torch.nn.CosineSimilarity(), margin=1.0)
self.cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
# 学習データのミニバッチ(`batch`)が与えられた時に損失を出力する関数を書く。
# batch_idxはミニバッチの番号であるが今回は使わない。
def training_step(self, batch, batch_idx):
output1 = mean_pooling(self.bert_sc1(attention_mask=batch['attention_mask_a'],
input_ids=batch['input_ids_a'],
token_type_ids=batch['token_type_ids_a']),
batch['attention_mask_a'])
output2 = mean_pooling(self.bert_sc2(attention_mask=batch['attention_mask_p'],
input_ids=batch['input_ids_p'],
token_type_ids=batch['token_type_ids_p']),
batch['attention_mask_p'])
output3 = mean_pooling(self.bert_sc2(attention_mask=batch['attention_mask_n'],
input_ids=batch['input_ids_n'],
token_type_ids=batch['token_type_ids_n']),
batch['attention_mask_n'])
loss = self.triplet_loss(output1,output2,output3)
self.log('train_loss', loss) # 損失を'train_loss'の名前でログをとる。
return loss
# 検証データのミニバッチが与えられた時に、
# 検証データを評価する指標を計算する関数を書く。
def validation_step(self, batch, batch_idx):
output1 = mean_pooling(self.bert_sc1(attention_mask=batch['attention_mask_a'],
input_ids=batch['input_ids_a'],
token_type_ids=batch['token_type_ids_a']),
batch['attention_mask_a'])
output2 = mean_pooling(self.bert_sc2(attention_mask=batch['attention_mask_p'],
input_ids=batch['input_ids_p'],
token_type_ids=batch['token_type_ids_p']),
batch['attention_mask_p'])
output3 = mean_pooling(self.bert_sc2(attention_mask=batch['attention_mask_n'],
input_ids=batch['input_ids_n'],
token_type_ids=batch['token_type_ids_n']),
batch['attention_mask_n'])
val_loss = self.triplet_loss(output1,output2,output3)
self.log('val_loss', val_loss) # 損失を'val_loss'の名前でログをとる。
# 学習に用いるオプティマイザを返す関数を書く。
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.lr)
モデル部分です。 アンカーテキスト用のBERTと、ポジティブ/ネガティブ用のBERTの2種類あることが一番の特徴です。後々の使い回しの良さを考えて、テストの部分は pytorch lightningによせなかったため、今回test_stepを書かなかったです。
そもそものここの書き方は下記をご参照ください。
# 学習時にモデルの重みを保存する条件を指定
checkpoint = pl.callbacks.ModelCheckpoint(
monitor='val_loss',
mode='min',
save_top_k=1,
save_weights_only=True,
dirpath='./model/',
)
# 学習の方法を指定
trainer = pl.Trainer(
gpus=1,
max_epochs=3,
auto_lr_find=True,
callbacks = [checkpoint]
)
checkpointに、学習したモデルを学習の途中でも保存するための設定を書いてます。ここでdirpathをGoogle Driveにマウントした場所にしておけば途中でColabのセッションが打ち切られても、学習の一切が無になる事態は避けられます。val_lossをみて一番マシなやつを保存するようにしています。
trainerに学習の方法を指定しています。max_epochsは学習回数に大きく影響し、本当はもっと大きな値を設定したかったのですが、無料のColabを使っているため途中でGPUが使えなくなることが頻発し、これ以上大きな設定での学習を終わらせることができませんでした。
model = SentenceBERT(model_name=MODEL_NAME, lr=1e-5)
pretrainされたBERTでモデルを作ります。tokenizerと同じモデル名を指定しています。
lr_finder = trainer.tuner.lr_find(model, dataloader_train, dataloader_val)
model.hparams.lr = lr_finder.suggestion()
learning_rateは、データからいい感じの値をもとめてモデルにセットしています。これをやらずに適当な値を設定していたときはほとんど学習が収束せず、つらい思いをしました。
%load_ext tensorboard
%tensorboard --logdir ./lightning_logs/
tensorbordを立ち上げます。この時点では学習が始まっていないので何のログもなく、グラフが表示されません。学習開始してから左上のリロードボタンをおすとグラフが表示されます。自分はtrain_lossと validation_lossを見るのに使っていました。
こんな感じのグラフが出ます。
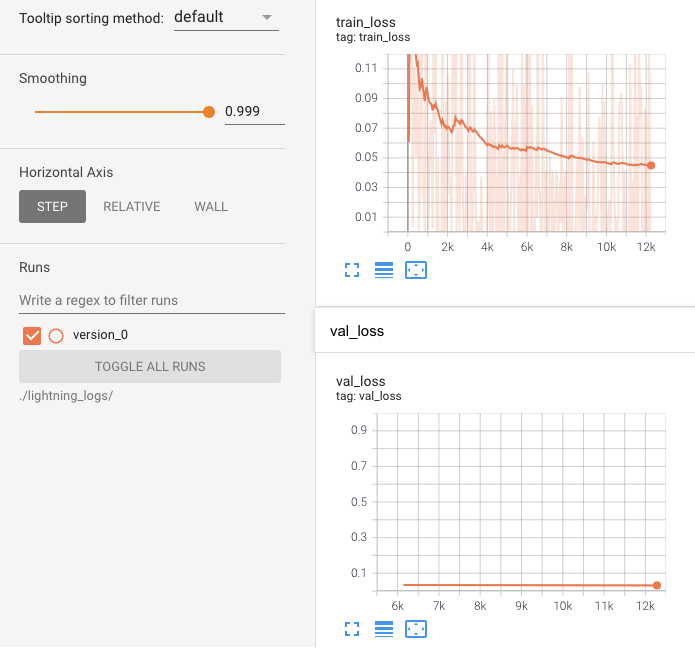
今回のepoch3回が終わった時点のグラフです。明らかにまだまだ学習できそうです。
smoothingを大きな値にして。lossが減る方向にあるかを確認していました。たぶん、いろんな観点があってそのためにいろんな機能が用意されている用ですが、私がまだ使いこなせていないです。
losses = []
sim_diffs = []
prc = []
for batch in dataloader_test:
output1 = mean_pooling(model.bert_sc1(attention_mask=batch['attention_mask_a'],
input_ids=batch['input_ids_a'],
token_type_ids=batch['token_type_ids_a']),
batch['attention_mask_a'])
output2 = mean_pooling(model.bert_sc2(attention_mask=batch['attention_mask_p'],
input_ids=batch['input_ids_p'],
token_type_ids=batch['token_type_ids_p']),
batch['attention_mask_p'])
output3 = mean_pooling(model.bert_sc2(attention_mask=batch['attention_mask_n'],
input_ids=batch['input_ids_n'],
token_type_ids=batch['token_type_ids_n']),
batch['attention_mask_n'])
loss = model.triplet_loss(output1,output2,output3)
losses.extend([float(loss.cpu())])
cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
sim_diff = cos(output1, output2)-cos(output1, output3)
sim_diffs.extend(np.array(sim_diff.cpu()))
prc.extend([float(torch.sum(cos(output1, output2)>cos(output1, output3)).cpu())])
print("loss:{0}".format(np.array(losses).mean()))
print("cos_diff:{0}".format(np.array(sim_diffs).mean()))
print("presicion:{0}".format(np.array(prc).sum()/len(data_test)))
学習前にテストデータを食わせた場合での性能を確認しました。ここではloss、アンカーテキストとポジティブテキストのcos類似度とアンカーテキストとネガティブテキストのcos類似度の差分(大きいほど嬉しい)、presicionを確認しました。その結果
loss:0.2745676236227155
cos_diff:0.06301850080490112
presicion:0.9066113010910275
という結果が返ってきました。fine tuningなしでもpresicionは高く出ますが、cos類似度の差分の平均はさほど大きくなかったです。
trainer.fit(model, dataloader_train, dataloader_val)
これでモデル学習が始まります。今回はepoch1回が 23分くらいだったので終わるまで1時間ちょっとかかりました。学習中は基本的にやれることはないのですが、tensorboardを眺めながら明らかに学習できてないといった状態になっていないか(なっていたら緊急停止)を監視はしていました(たまに)。
モデル学習の結果(前述の通り明らかに学習足りてないのですが)、テストデータでの性能は下記になりました。
loss:0.032800842474292345
cos_diff:0.31318098306655884
presicion:0.9869728057319654
ちゃんとlossも減り、cos類似度の間隔も広くなり、presicionも明らかに向上しました。すごい
まとめ
ざっくりSBERTの魅力と、とりあえずfine tuningして見る系のコピペで動くコードの共有でした。コードの分量自体は最終的にはだいぶ少なくなってますが、ここに至るまでそこそこ試行錯誤があり(主にmultiple datasetの扱い方について)、(少なくても勉強前の自分には)とりあえず動くコードがあると理解が捗ると思っています。
もう少し色々と試して本記事を追記していきたいのですが、この状態でも役に立つ方がいる気がするので、いったん公開します!