概要
2024年4月に公開された論文で提唱されている機械学習モデルの話
LDTはLatent Diffusion Transformerの略であり、その名の通り拡散モデルとTransformerを用いた生成aiモデルのことである。主な生成対象は3DPointCloud。
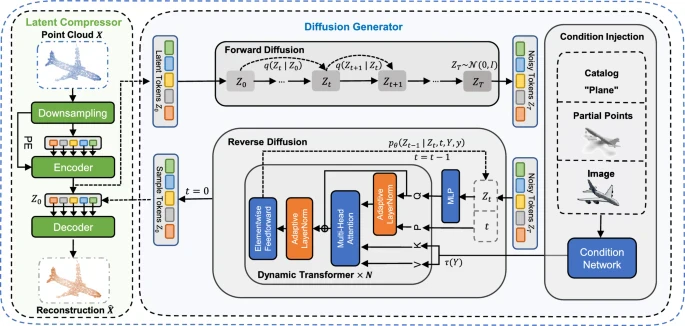
詳しくはLDT概要に記載。
動作環境
| Version | |
|---|---|
| Ubuntu | 20.04 |
| python | 3.10.12 |
| Graphics Board | NVIDIA GeForce RTX 4090 |
データセット
ShapeNetCore.v2.PC15k
インストール手順
- こちらからリポジトリをクローン
- 必要モジュールをインストール
pip install -r requirements.txt
- 必要ファイルをダウンロード
Drive内のexternをダウンロードし、LDT直下に配置 - セットアップ
cd evaluation/pytorch_structural_losses/
python setup.py install
cd extern/pointnet2_ops_lib
python setup.py install
cd extern/emd
python setup.py install
- データセットの用意
./dataset_download.sh
でダウンロード可能
LDT直下にdataディレクトリを生成し、ShapeNetCore.v2.PC15kを格納する
これで一通り準備は完了
実行
基本的に以下3ステップで学習完了となる
その後学習モデルを使って生成する
- Compressorの学習
- 学習モデルをセッティング
- Diffusion Generatorの学習
各学習機構のパラメータ数は以下の通り
Compressor:8100217
Diffusion Generator:457012344
1. Compressorの学習
3D点群データを拡散モデルで扱いやすい形式にするために情報を圧縮する装置
この段階では入力データを圧縮して展開するだけ
python3 train_Compressor.pyで学習できる。
しかしあるメソッドへ引き渡される変数が足りないなどコード上の問題が生じていたため、以下に自身が修正した内容を記載しておく
該当箇所はtrainer/Compressor_Trainer.py29~41行目
def update(self, data):
cates = data["cate_idx"].to("cuda")
data = data['tr_points'].to(self.device)
self.model.train()
self.warm_up(self.optimizer, self.itr)
loss, kl_loss, rec_loss = self.compute_loss(data, cates)
self.optimizer.zero_grad()
loss.backward()
if self.cfg.opt.grad_norm_clip_value is not None:
clip_grad_norm_(self.model.parameters(), self.cfg.opt.grad_norm_clip_value)
self.optimizer.step()
self.itr += 1
####################これを追加#####################
with torch.no_grad():
model_output = self.model(data)
max_feature = model_output['max'].max().item()
#################################################
return loss, kl_loss, rec_loss, max_feature # max_feature追加
問題なく動くと./experiments/Compressor_Trainer/airplane/に学習モデルのファイルが保存されているはず
2. 学習モデルをセッティング
1で出力した学習モデルのファイルパスをexperiments/Latent_Diffusion_Trainer/airplane/config.yamlの該当箇所に記載する
compressor:
pretrain_path:experiments/Compressor_Trainer/airplane/checkpt_5.pth #ここに追加
outsize: 2048
...
3. Diffusion Generatorの学習
圧縮されたデータを拡散、逆拡散し、その過程を学習することで完全なノイズから意味のあるデータを生成するためのモデルを学習する装置
圧縮機と同様python3 train_Latent_Diffusion.py.pyで学習可能
ここでも変数不足のエラーが生じたため、修正内容を記載する
該当箇所はexperiments/Latent_Diffusion_Trainer/airplane/config.yamlのscore部分
score:
num_steps: 1000
z_dim: 120
z_scale: 32
hidden_size: 1024
num_heads: 16
num_blocks: 24
num_categorys: 1
c_dim: 0.
t_dim: 1024
dropout: 0.
norm: layer_norm
learn_sigma: False
act: swish
unet: False
AdaLN: True
condition: False
graphconv: False #追記
これで実行が終わると./experiments/Latent_Diffusion_Trainer/airplane/に学習モデルが生成されているはずである。
また、その他にsmp_epXXX.npyというファイルがあり、これは訓練の段階で1つだけ生成された点群データである
結果
以下の組み合わせで学習させてみた
| category | Compressorの学習epoch | Diffusion Generatorの学習epoch |
|---|---|---|
| airplane | 5 | 6000 |
| airplane | 4000 | 6000 |
| chair | 4000 | 6000 |
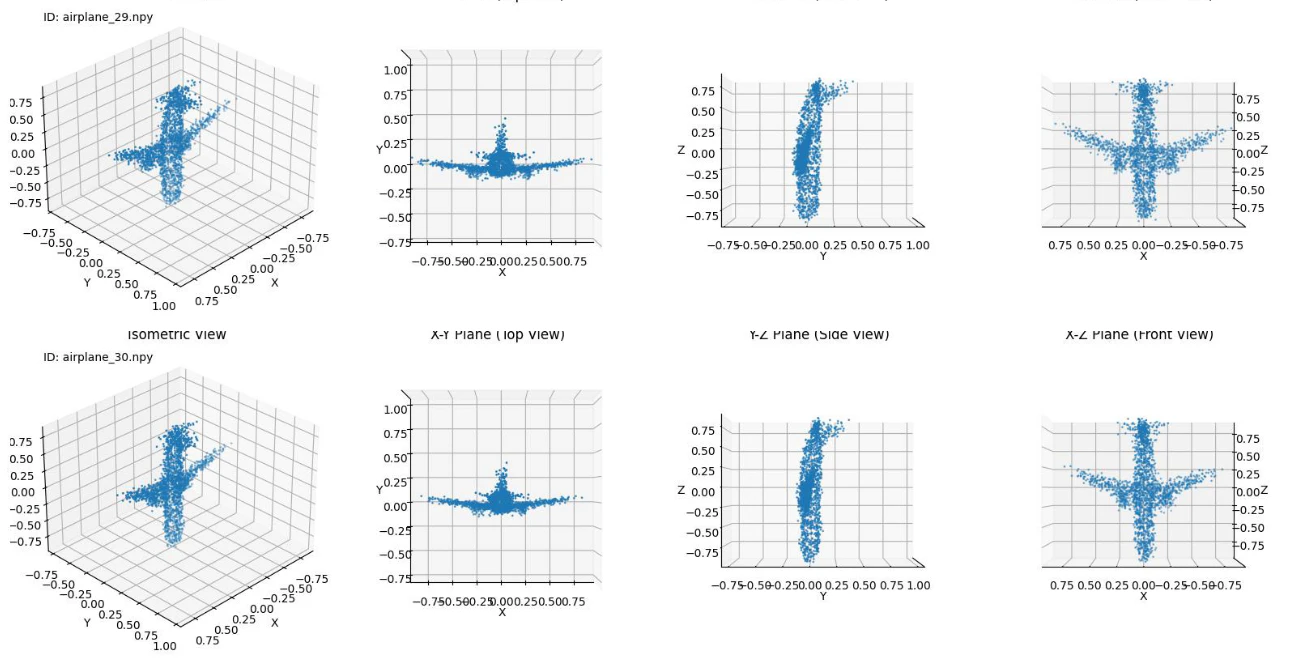
airplane
5-6000
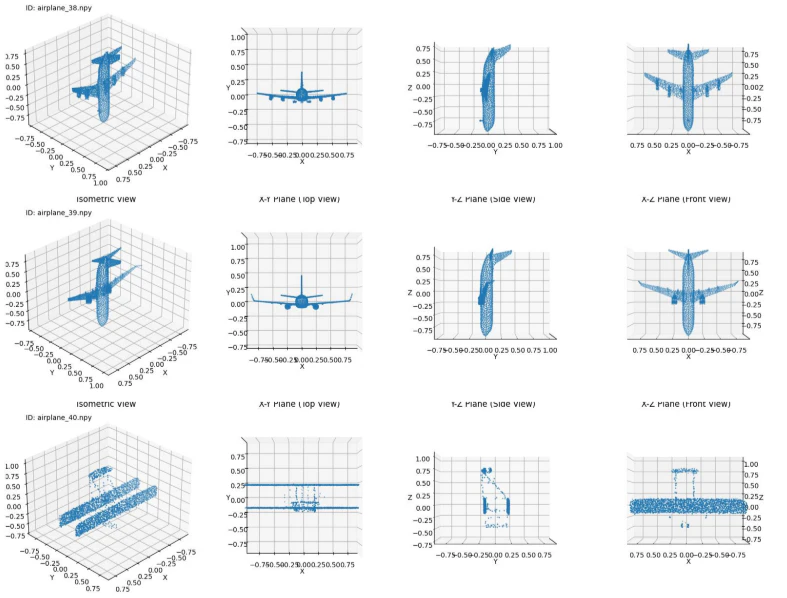
4000-6000

chair
4000-6000
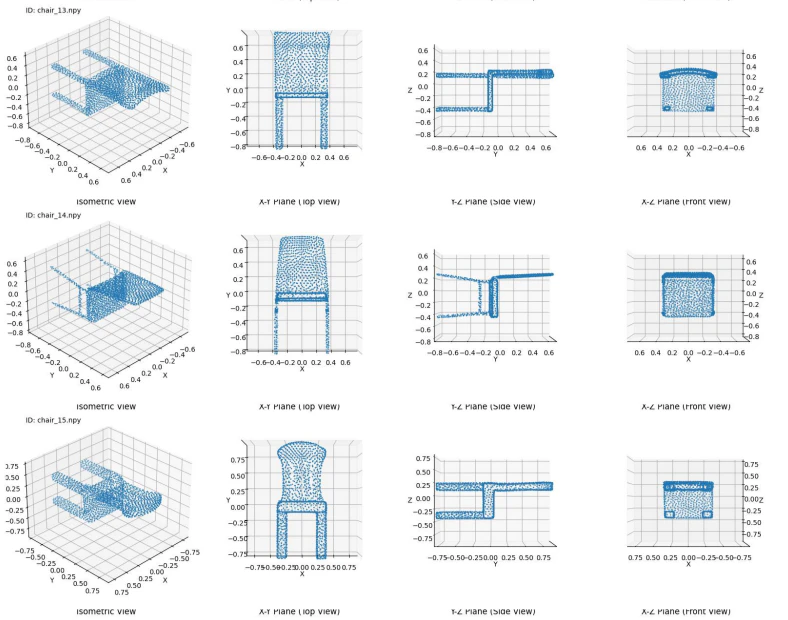
かなりの高精度で生成できていることが分かる。
たまに歪なデータ(上記ID:airplane_40)が生成されることもあるが、ShapeNetデータセットの中にもおおよそ飛行機と呼べないようなデータもいくつか存在していたため、学習自体は問題ないと考えられる
今後
各モデルのパラメータなどを変化させ、データ生成の傾向を調査する。
epoch数を増やし過学習の影響を見る
→そのためには数値として評価指標を立てるべきだが、そのあたりも調べていく
LDT概要
LDTはこちらの論文に詳しく書かれている。本記事の画像もこちらから引用している。
条件付き生成と無条件生成の2種類が用意されているが、今回は無条件生成の方で話を進めていく
LDTは大きく分けて以下の2つで構成されている
学習する際は上記2つをそれぞれ2回に分けて行う
Latent Compressor
目的
- 元の点群を、拡散モデルで扱いやすい潜在トークンへ変換する
- 複雑な点群形状 → 高表現力・柔軟なトークンへ圧縮
構成要素
1. Downsampling
- 点群を小さなクラスタに分割し、効率的に特徴を抽出
- 画像処理の「パッチ分割」に類似した手法を点群に適用
手順:
- FPS(Furthest Point Sampling):代表点(クラスタ中心)を抽出
- KNN:各代表点の近傍点をクラスタ化
- MLP + MaxPooling:クラスタごとの特徴を抽出
- 入力:点群の座標データ
X \in \mathbb{R}^{N \times3}
- 出力:クラスタ特徴ベクトル
X_0 \in \mathbb{R}^{M \times D}
C = \text{FPS}(X)\\
X_0 = \text{MaxPooling}(\text{MLP}(\text{KNN}(X, C)))
\begin{align}
X&:学習用入力データ\\
C&:クラスタ中心の座標データ\\
M&:クラスタ数\\
D&:1つのクラスタに含まれる点群の数
\end{align}
2. Tokenization Auto-Encoder
エンコーダー
- Transformer ベースの構造
- クラスタ中心を位置エンコーディングとして使用
- 自己注意(Self-Attention)により、局所的・大域的な依存関係を学習
- 点群の幾何情報をエンコーディングに含めることで、各トークンが異なる領域の特徴を効果的に表現
- 入力:クラスタ特徴ベクトル
X_0 \in \mathbb{R}^{M \times D}
- 出力:潜在トークン
Z \in \mathbb{R}^{M \times D} \
デコーダー
- Cross-Attention を備えた Transformer
- シードベクトル $h \in \mathbb{R}^{N \times D}$をクエリとして使用
- クロスアテンションにより、トークン $Z$ の情報をシードに統合
- 最終的に MLP を通じて点群を再構成
再構成の特徴
- シードからサンプルサイズ(クエリの数)を変えることで、様々な解像度の点群を再構成可能
- 潜在空間で明示的に幾何構造を保存しなくても、各トークンが局所領域を表すことで、ローカル情報を効果的に学習できる
損失関数
潜在トークン $Z$ を通じて点群 $X$ を再構成するための損失関数
L(\xi, \psi) = \mathbb{E}_{q_\xi(Z|X)}[-\log p_\psi(X|Z)] - \lambda_{\text{KL}} \cdot D_{\text{KL}}(q_\xi(Z|X) \parallel p(Z))
- $\xi$:エンコーダのパラメータ
- $\psi$:デコーダのパラメータ
- $q_\xi(Z|X)$:エンコーダによる潜在トークンの分布
- $p_\psi(X|Z)$:デコーダによる再構成点群の分布
- $p(Z)$:標準正規分布
- $\lambda_{\text{KL}}$:KLダイバージェンス項の重み
- 再構成誤差には Chamfer Distance (CD) や Earth Mover's Distance (EMD) を使用
Diffusion Generator
目的
- Latent Compressorで変換された潜在トークンを用いて生成のための学習を行う
- ノイズから潜在トークンを生成できるようにする
構成要素
1 Forward Diffusion(順拡散)
- 順拡散は マルコフ連鎖として設計されており、元の潜在トークン $Z_0$ に 段階的にノイズを加えるプロセスであり、ノイズ予測ネットワーク $\epsilon_\theta(Z_t, t)$ の学習に利用される
- 各ステップでは、以下のようにガウスノイズを加えていく
Z_t = \sqrt{\alpha_t} Z_0 + \sqrt{1 - \alpha_t} \varepsilon_t, \quad \varepsilon_t \sim \mathcal{N}(0, I)
2 Reverse Diffusion(逆拡散)
- 逆拡散は、拡散生成における 生成プロセスそのもの
- 順拡散でノイズが加えられたデータ $Z_T$ を 段階的にノイズ除去して $Z_0$ を復元する
p_\theta(Z_0 | Z_T) = p(Z_T) \prod_{t=1}^{T} p_\theta(Z_{t-1}|Z_t)
p_\theta(Z_{t-1}|Z_t) = \mathcal{N}\left(Z_{t-1}; \mu_\theta(Z_t, t), \sigma_t^2 I\right)
- このとき、平均 $\mu_\theta$ はノイズ予測ネットワークを用いて計算される
- 学習済みのノイズ予測ネットワーク $\epsilon_\theta$ を用いて、正規分布から徐々に潜在トークンを生成できる
3 Dynamic Transformer(動的トランスフォーマー)
- 拡散プロセスで用いる ノイズ除去ネットワークの中核
- Transformer をベースとし、長距離依存性のモデル化が可能
- さらに、時間ステップごとに変化するノイズ量に対応するために Dynamic Positional Encoding(動的位置エンコーディング) を導入
- 時刻 $t$ に基づく位置エンコーディング $P$ を MLP によって処理し、各層ごとの平均・分散を動的に調整
Z^{(l+1)}_t = \text{AdaLN}\left(\text{MLP}\left(\text{softmax}\left(\frac{Q^{(l)}_t {K^{(l)}_t}^\top}{\sqrt{D^{(l)}}}\right)V^{(l)}_t\right), P_t\right)
- 条件付き生成(Conditional Generation)の場合は、外部条件 $Y$(例:画像や不完全な点群)から得た特徴 $\tau(Y)$ をキーやバリューに使用
K_t = \tau(Y)W_K, \quad V_t = \tau(Y)W_V
損失関数
ノイズ付き潜在状態からのノイズ予測を通じて、点群を生成できるように訓練
L(\theta, \xi, \psi) = \mathbb{E}_{q_\xi(Z|X)}[-\log p_\psi(X|Z)] + \mathbb{E}_{q_\xi(Z|X)}[\log q_\xi(Z|X)] + \mathbb{E}_{q(Z_t|Z)}\left[w_t \cdot \left\| \varepsilon - \varepsilon_\theta(Z_t, t) \right\|^2\right]
- $\theta$:拡散生成器(denoising network)のパラメータ
- $\varepsilon_\theta(Z_t, t)$:ネットワークによるノイズ予測
- $\varepsilon$:実際のノイズ
- $w_t$:時間ステップごとの重み
データの流れ
以下の表にまとめる
| フェーズ | 動作 | 学習しているか? |
|---|---|---|
| エンコーダー | 点群を潜在表現に圧縮 | している |
| 順拡散 | ノイズを加える | していない |
| 逆拡散 | ノイズ除去してデータを推定 | している |
| デコーダー | 潜在表現から点群を復元 | している |