この記事はスタンバイ Advent Calendar 2021の6日目の記事です。
Introduction
最近、Apache Flinkを使用したストリーミングアプリケーションを開発する機会があったのと、前々から分散処理、ストリーミング処理に興味があったので、O'Reillyから出版されているApache Flinkの書籍で学習をおこないました。
一通り読んで基本的なところは理解できたので纏めつつ、業務でFlinkのどの機能を利用したのか、結果的にどういったFlinkアプリケーションになったのか、整理の意味も兼ねて書いていきます。
References
下記のサイトや書籍から説明、画像を引用しております。
[1] Stream Processing with Apache Flink
[2] Stream Processing Fundamentals
[3] ストリーム処理とは何か?+2016年の出来事
What is a streaming application?
Stream processing is an application design pattern for processing unbounded streams of events. [2]
つまり、「無限に発生し続けるイベントを処理するアプケーション」となります。
 ストリーミングアプリケーションの全体像 [3]
ストリーミングアプリケーションの全体像 [3]
例えばWebアプリケーションの場合、ユーザリクエストに応じて各種ビジネスロジックの実行、DB等への外部アクセスが発生し、最終的にユーザに結果を返します。
バッチアプリケーションの場合、普段は起動しておらず、定期的に一定量のデータを処理をする、といったモデルが一般的です。
つまり、システムのモデルとして絶え間なく処理をし続ける事が前提になっていない、と言えます。
それに対して、ストリーミングアプリケーションは絶え間なく発生し続けるイベントを処理する必要があるので、Webアプリケーションやバッチアプリケーションとは異なる機能要件が求められます。また、処理に失敗した場合もWebやバッチとは異なる対処が求められます。
Webアプリケーションのようにエラーハンドリングをしつつトランザクションをロールバックしてユーザにエラーを表示したり、バッチアプリケーションのように再実行するといった、単純な仕組みではリカバリが出来ない事が多いです。
上記で述べた事、そして下記で述べていく事は、ストリーミングアプリケーションにおいては一般的な内容なので、Apache Flinkにも当て嵌まります。
理解していく上で重要だと思う特徴をピックアップしつつ、業務で開発したFlinkアプリケーションがどのような形になっているのかを説明して、最後に纏める構成にしていきます。
Stateless or Stateful
- Stateless: Stateless operations do not maintain any internal state. Stateless operations are easy to parallelize, since events can be processed independently of each other and of their arriving order. Moreover, in the case of a failure, a stateless operator can be simply restarted and continue processing from where it left off.
- Stateful: In contrast, stateful operators may maintain information about the events they have received before. This state can be updated by incoming events and can be used in the processing logic of future events. Stateful stream processing applications are more challenging to parallelize and operate in a fault-tolerant manner because state needs to be efficiently partitioned and reliably recovered in the case of failures. [2]
Statelessは状態を持たない、つまりイベントを処理していく上で途中の計算結果などを保存する必要がなく、1つ1つのイベントを独立して処理をする事が出来るケースです。このケースで要件を満たせるなら、比較的単純なアプリケーションを構築するだけで済みます。
一方、Statefulの場合は状態を持つ必要があります。複数のイベントの集約や組み合わせをおこなう事が多く複雑になりがちで、計算の途中結果も保存しておく必要があります。
保存していない場合でも、最初から処理をやり直せば復元は一応できますが、例えば1時間掛けた上での処理結果を再実行によって復元するのは、システムの要件として一般的に許容出来ないと思います。
さて、業務で携わったアプリケーションについてですが、結論から言いますとStatelessとなります。
簡単にシステムの概略を述べると、下記のようになります。
App1 -> (events) -> AWS Kinesis -> (events) -> FlinkApp -> (events′) -> App2
App1が継続してイベントをAWS Kinesisに書き込み、Flinkアプリケーションが読み取って変換をおこない、App2に連携する構成となります。
1つ1つのイベントを変換して後続のアプリケーションに連携すれば良く、複数のイベントを組み合わせた処理や、イベントの処理順序を気にする必要はありません。そのため、Statelessで要件を満たせる、という事になります。
Latency and Throughput
ストリーミングアプリケーションは処理速度を求められる事が多いので、遅延の小ささ(Low Latancy)と単位時間当たりの処理量(Throughput)は重要になります。
一般的に、上記の2つの指標を改善するためには、非同期IOを上手く使う事、並列度を上げる事などが有効とされますが、ストリーミングアプリケーションにおいても同じ事が言えると思います。
開発したアプリケーションについては、前項でも述べたように単純なデータ変換であり、データ変換をおこなうための元ネタになる情報をRDBから取得する以外はオンメモリで処理が簡潔するため、非常に高い性能を出しやすいです。
厳密に言うと、イベント1件1件毎にRDBに接続しているわけではありません。イベントの特定のキーを基準に一定期間のイベントをグルーピングした上で、各グループ毎に1回RDBに接続する事で、IOを最小限に抑える工夫をしています。
変換データを後続のアプリケーションにHTTPリクエストで連携していますが、レスポンスを使って何らかの処理をする必要もなく、非同期で投げているだけなので、こちらの影響も無視できる程度です。
Operations
- Transformation: Transformation operations are single-pass operations that process each event independently. These operations consume one event after the other and apply some transformation to the event data, producing a new output stream.
- Rolling Aggregation: A rolling aggregation is an aggregation, such as sum, minimum, and maximum, that is continuously updated for each input event. Aggregation operations are stateful and combine the current state with the incoming event to produce an updated aggregate value.
- Window Operation: Window operations continuously create finite sets of events called buckets from an unbounded event stream and let us perform computations on these finite sets. Events are usually assigned to buckets based on data properties or based on time. [2]
Transformationは単純です。上記でも述べていますが、開発したアプリケーションはこのパターンです。受け取った1つ1つのイベントを後続のアプリケーションに適した形に変換します。
Aggregationは集約なので、イベントを受け取る毎に前回の処理結果に反映して、後続に連携する形となります。例えば数字を足し上げていくアプリケーションを考えてみます。下記の数列が右から左の順番で流れてくるとして
10, 9, 8, 7, 6, 5, 4, 3, 2, 1
ストリーミング処理の結果としては
55, 45, 36, 28, 21, 15, 10, 6, 3, 1
となります。Aggregationの場合、Statefulで構築する必要があります。Statelessで構築した場合、例えば、45まで処理した段階で再起動が掛かると途中経過が失われるため、55を算出するためには1から処理を再実行をする必要があります。ここで挙げた程度の処理では問題ではないですが、コストの高い処理を実行している場合、大きな問題となります。
次はWindow Operationについてです。複数のイベントを跨った計算をおこなう、という点ではAggregationと同じですが、違いとしては、複数のイベントを何らかの基準でグループに纏めて、そのグループのイベント群に対して1度処理をおこなう、という点です。
上記の数列の例で言えば、1から10の数字グループに対して、合計、平均、最小、最大の値を算出する、などがあります。
Windowの種類として主に下記の2つがあります。
-
Tumbling Window
-
イベント件数、または時間単位で固定長のグループ
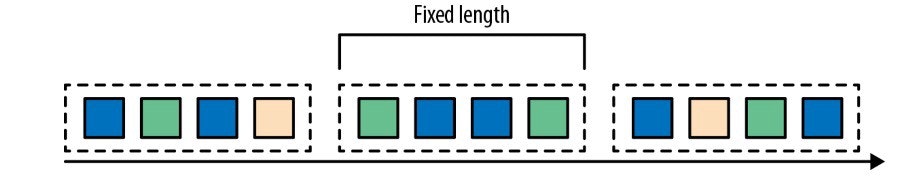
 Tumbling Windowの例 [1]
Tumbling Windowの例 [1] -
Sliding Window
-
固定長のWindow、スライド幅でグループを構成
-
1つのイベントが複数のグループに属する場合もある
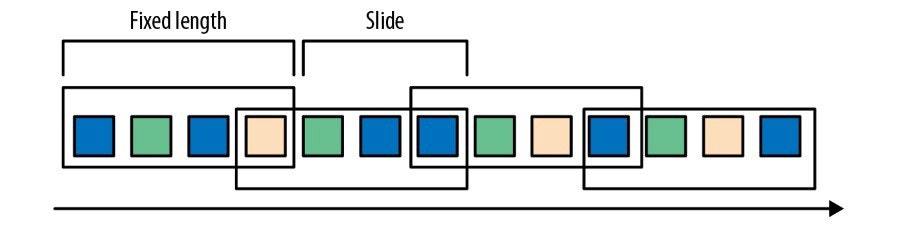 Sliding Windowの例 [1]
Sliding Windowの例 [1]
Time Semantics
- Processing time is the time of the local clock on the machine where the operator processing the stream is being executed. A processing-time window includes all events that happen to have arrived at the window operator within a time period, as measured by the wall clock of its machine.
- Event time is the time when an event in the stream actually happened. Event time is based on a timestamp that is attached to the events of the stream. It completely decouples the processing speed from the results. Operations based on event time are predictable and their results are deterministic. An event time window computation will yield the same result no matter how fast the stream is processed or when the events arrive at the operator. [2]
ストリーミングアプリケーションにおける「時間」の概念には2種類あります。
Processing timeの場合は実際に処理をおこなう時点でのマシンのシステム時間、Event timeの場合は実際にイベントが生成された時間となります。
Processing timeは単純なのですが、欠点があります。それは「システムで実際に処理される時間」なので、イベントが発生し、アプリケーションに届くまでに大きな遅延が発生した場合、実際にイベントが発生した時刻、遅延を考慮した処理をおこなう事が出来ません。
例えば、昼の12時に発生したイベントが、何らかの通信障害によって13時になってようやくアプリケーションに届いたとします。その結果、12時のちょっと前に発生したイベントとは異なるwindowで処理されてしまう、という事が起こり得ます。これは意図した挙動ではないでしょう。
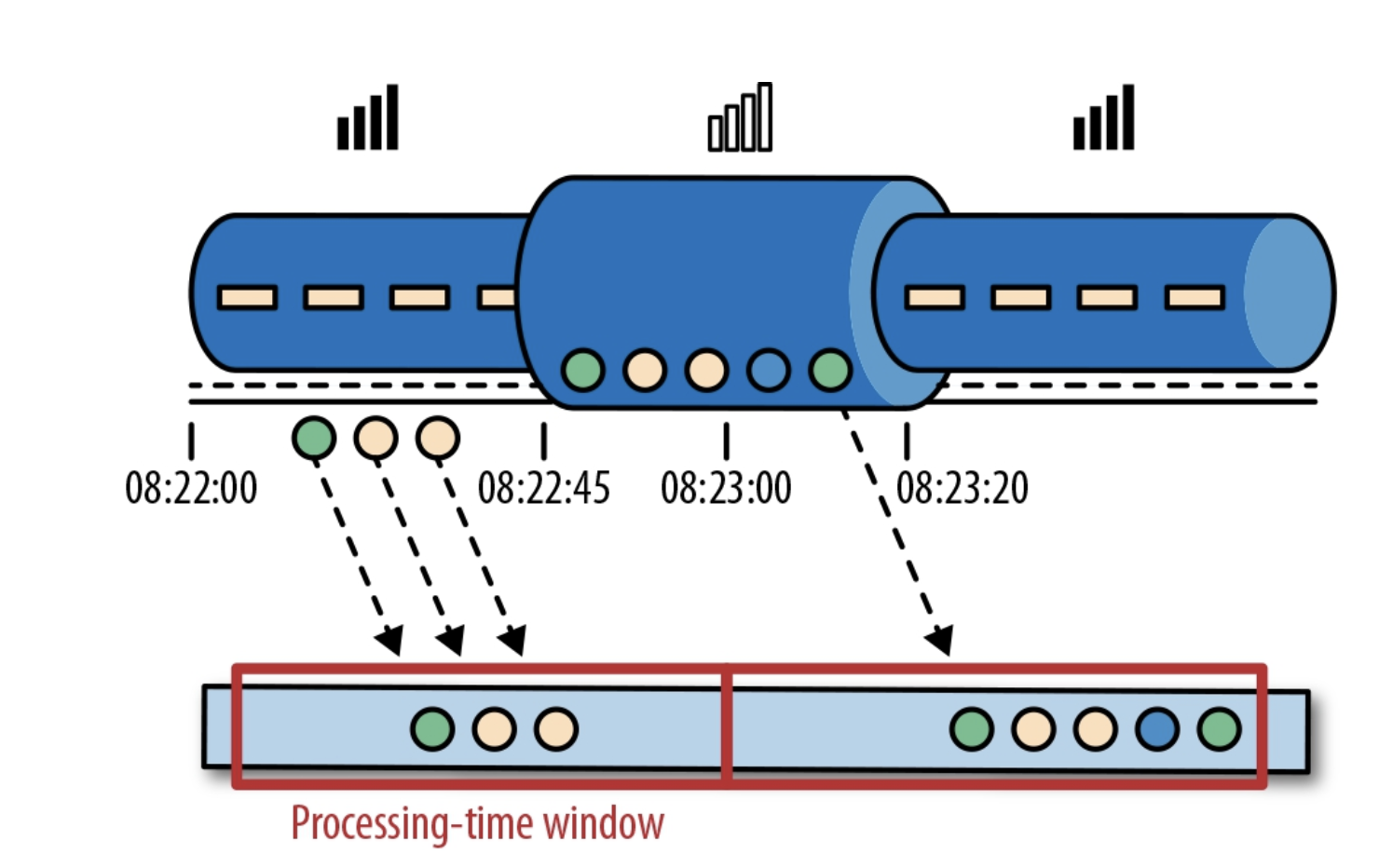 Processing-time Windowの例 [1]
Processing-time Windowの例 [1]
08:22:00 ~ 08:22:45で発生したイベントは遅延が無いので同じwindow内で処理されますが、08:22:45 ~ 08:23:20で発生したイベントはアプリケーションへの到達が遅延しているため、別のwindowで処理されています。イベント発生の時間的には近いので、本来の意図としては、同じwindowで処理したいのですが・・・。
Processing timeにおいては、処理される時点のマシンの時間を利用するため、windowの幅を超えてしまい、別windowで処理されるためです。
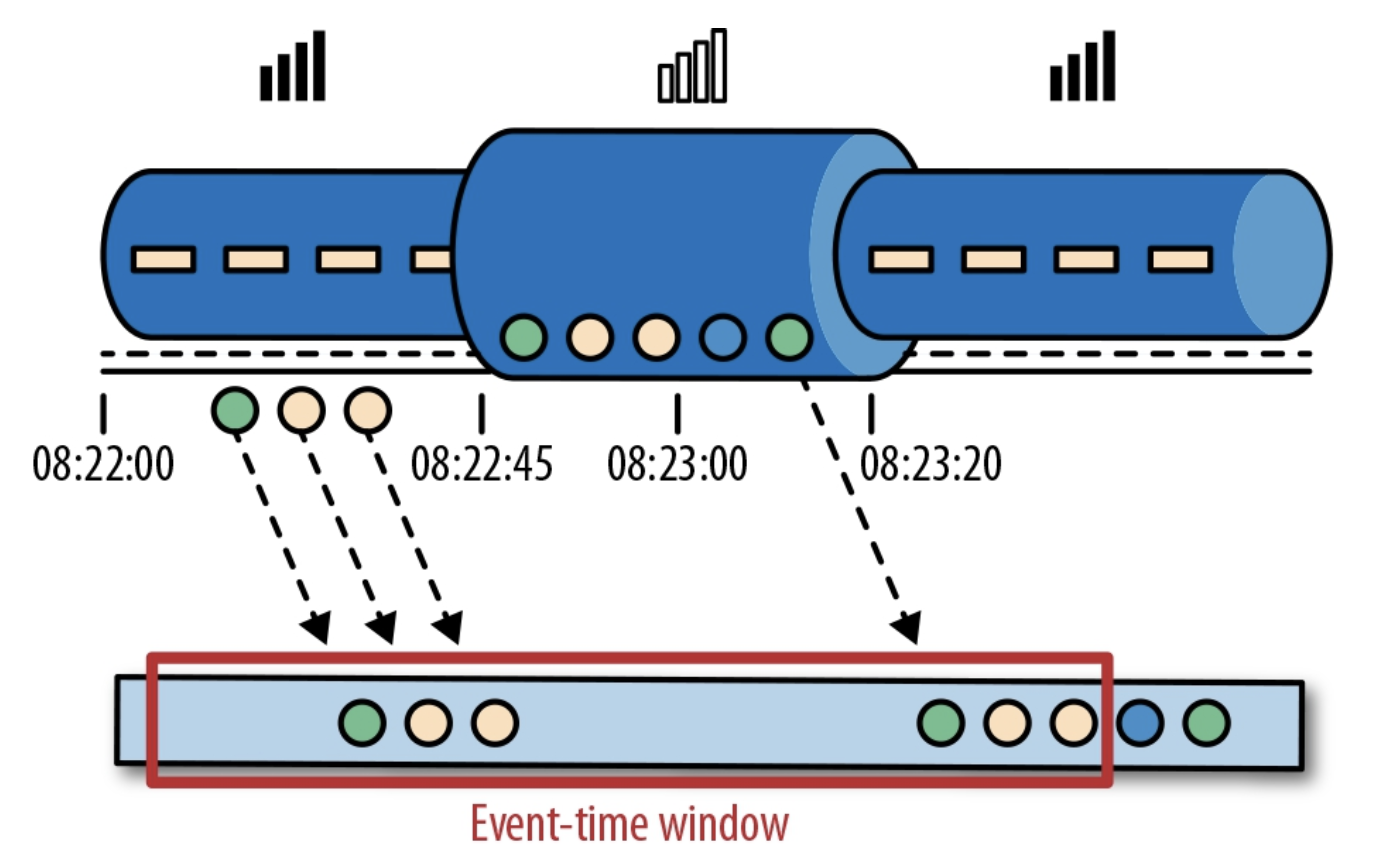 Event-time Windowの例 [1]
Event-time Windowの例 [1]
一方、上記の図は同じ状況でのEvent time windowの例です。
08:22:45 ~ 08:23:20で発生したイベントがアプリケーションに遅れて到達している、という点ではProcessing timeの場合と同じですが、「実際にイベントが発生した時刻」を利用するため、たとえ遅延しても同じwindowで処理される事になります。
「では、いつまで遅延するイベントを待つ必要があるのか?」という疑問が浮かびます。そのために「Watermark」という概念が存在するのですが、今回の記事では割愛します。参考文献のサイトや書籍に詳しい解説がありますので、ご興味のある方は是非参照してみて下さい。
Processing timeモード、Event timeモードのどちらかで動作させるか、ソースコード上で指定できます。
上述したように、Processing timeモードの場合、Window Operationの際に利用する時間は処理時点のマシンのシステム時刻を使うため、Flinkがよろしくやってくれます。
Event timeモードの場合、受信したイベントが持つフィールドの中で、「どのフィールドの値をEvent timeとして利用するか?」を指定する事になります。そのためのAPIをFlinkが提供してくれているので、そちらを使用する事になります。
ちなみに、実装上は必ずしもイベントのフィールドを使う必要はなく、ScalaやJavaの時刻APIによって出した時間を使う事も出来ます。ただ、「Event time」ですから、実際のイベントの発生時刻を使うのが適切です。
さて、開発したアプリケーションについてですが、上述の通り、1つ1つの独立したイベントを変換するTransformation Operationのため、イベントの発生時刻を考慮する必要は特にありません。そのため、Processing time or Event timeの明示的な指定はせず、デフォルト設定(Event time)にしています。
Task Failure and Result Guarantees
- AT-MOST-ONCE: The simplest thing to do when a task fails is to do nothing to recover lost state and replay lost events. This type of guarantee is also known as “no guarantee” since even a system that drops every event can provide this guarantee.
- AT-LEAST-ONCE: In most real-world applications, the expectation is that events should not get lost. This type of guarantee is called at-least-once, and it means that all events will be processed, and there is a chance that some of them are processed more than once. In order to ensure at-least-once result correctness, you need to have a way to replay events — either from the source or from some buffer. Persistent event logs write all events to durable storage, so that they can be replayed if a task fails.
- EXACTLY-ONCE: Exactly-once is the strictest guarantee and hard to achieve. Exactly-once means that not only will there be no event loss, but also updates on the internal state will be applied exactly once for each event. Providing exactly-once guarantees requires at-least-once guarantees, and thus a data replay mechanism is again necessary. Additionally, the stream processor needs to ensure internal state consistency. That is, after recovery, it should know whether an event update has already been reflected on the state or not. [2]
ストリーミングアプリケーションにおいて非常に重要な考慮事項として、処理の失敗等の理由でアプリケーションの再起動が掛かった時の結果整合性が挙げられます。
再起動後に、本来は処理すべきだったイベントをスキップしてしまうと期待通りの結果を出力する事が出来ません。
ストリーミングアプリケーションには、結果整合性をどのレベルで担保するのかを指す指標として、上記の3つが定義されています。
AT-MOST-ONCEは「最大でも1回」と言う意味です。
これはイベントを最大で1回処理すれば良い、という事で、言い換えると0回でも良い、つまり、失敗したイベントを再実行しなくても良い、という意味になります。これは事実上、障害時の保証が何も無い事になるので、多くの場合、実運用では許容できないかと思います。
AT-LEAST-ONCEは「最低でも1回」という意味です。
イベントの取りこぼしが無い事が保証された状態を指します。数列の足し上げ処理の例で言うと、5まで処理した段階で再起動が掛かった時に、7から再開されて6がスキップされるような事は無い状態です。
定義上、6以前から再開されれば、つまり未処理のイベントがスキップさえされなければOKです。
ただし、アプリケーションの状態は復元しなくてもAT-LEAST-ONCEの定義は満たすので、必ずしも正しく処理を再開できるとは限りません。
数列の足し上げで言うと、1から5までの加算の結果を復元せずに、6から処理を再開しても正しい結果は得られません。
1つ1つのイベントを独立して処理すれば良いアプリケーションであれば、AT-LEAST-ONCEで正しく処理を再開できます。
EXACTLY-ONCEは「正確に1回」という意味です。AT-LEAST-ONCE + 状態を正しく復元、という事なので、あたかも再起動が無かったかのように振る舞う事が保証された状態です。数列の足し上げで言うと、1から5までの加算の結果を復元した上で、6から処理を再開します。これなら、正しい結果が得られます。
「正確に1回」という言葉が直感的に分かりにくいかもしれませんが、同じイベントを複数回処理しても、EXACTLY-ONCEになり得ます。EXACTLY-ONCEにおいては、どこかの時点の状態に復元され、処理イベントもその状態の時点から再開されます。
仮に同じイベントを複数回処理してしまったとしても、そのイベントを処理する前の状態に正確に戻る事が出来れば、アプリケーションから見ると「1回だけ処理を実行」と事実上、同じとなります。
5まで処理した時に再起動が掛かり、再起動後に、4まで処理をした状態に復元、そして5から処理・・・。
この場合、再起動前後で5を2回処理していますが、「4まで処理をした状態」に戻っているので、5をもう一度処理しても問題はありません。
さて、開発したアプリケーションについてですが・・・。
- 互いに独立したイベントを1つずつ変換するだけのStatelessなストリーミングアプリケーション
- データソースがAWS Kinesisで、数日間レコードを保存しており、保存さえされていれば好きな時刻からレコードを読み直す事が可能
- 再起動時に15分前からKinesisレコードを読み直すように設定している(同じレコードが複数回処理される)
これらの事から、定義上、「AT-LEAST-ONCE」でアプリケーションを設計している事になります。ただし、状態を持たないので、事実上「EXACTLY-ONCE」を満たした状態となっています。
ちなみにですが、後続のアプリケーションは送信されたイベントをRDBに保存し、かつ冪等性を担保するように作成しているので、同じレコードを複数回処理して後続アプリケーションに連携しても問題はありません。
正確に言うと、保存テーブルの更新日時カラムが複数回更新されるので、厳密に冪等性が成り立つわけではありませんが、運用上全く問題は無いので、「実質的に」冪等性は担保されています。
Summarize
ストリーミングアプリケーションの重要(だと思う)点を解説しつつ、業務で開発したストリーミングアプリケーションはどういう特性を持っているのか、という形でお話をしました。
大まかな特徴は下記です。
- AWS Kinesisをデータソースとする
- 互いに独立したイベントを1つずつ変換するだけなのでStatelessでOK
- 後続アプリケーションは連携されたイベントをRDBに冪等性を担保しつつ保存するので、同じイベントを複数回処理してもOK
- AT-LEAST-ONCEを満たせばEXACTLY-ONCEも満たされる
ストリーミングに限った話ではないのですが、状態を持つとロジックや障害からの回復、結果整合性の担保が難しくなります。その意味ではStatelessな変換処理をおこなうだけで機能要件を満たす事が出来るので、結果的にFlinkアプリケーションにしては単純な形に収まっているのかな、という所感です。
勿論、複雑であれば良い、という事は無いですし、複数のアプリケーションを連携する中で単純でも機能要件を満たせているのですから、全体の責務の分離が適切に出来ている証拠だと思っています。
一方で、Flinkの機能を存分に使っているとは言えないので、too muchな選択だったかな、という気もしています。フレームワークを選定した当時としては、正しいと判断していたのですが。
この記事では解説しきれなかった様々な機能がApache Flinkには存在します。それらを正しく組み合わせればもっと色々と便利な事が出来そうですね。