この記事で書いている内容は?
ストリーム処理とはそもそも何かからはじまり、必要になる検討ポイントなどの情報を振り返り用にまとめたものです。
あとは、今年個人的にこの分野に影響が大きかったと思ったイベントをまとめています。
他の方へ説明する際のベースとするためにまとめているため、
既にこの分野を知っている方にとっては冗長な内容も多いかもしれませんが、
その場合は適宜読み飛ばしていただけると。
あと、私の他記事からも内容引っ張ってきているのでかぶりはあると思います。
特にGoogleが考えるストリームデータ処理とは?とは目的もかぶっているので相応に被りがあるかと・・・
出来るだけよく出てくる固有の言葉を最初から使用せずに書いているつもりですが、
何かわかりにくい場所あればコメントいただけるとありがたいです。
「ストリーム処理」とだけ書くと微妙にストリーミング配信等とも混同しやすいですが、
データのストリームを処理する技術群ということで、ここでは「ストリーム処理」と記述します。
参照資料
文章の途中で参照資料を適宜入れ込むと細切れになるため、文頭にまとめておきます。
GoogleCloudDataflow周りのは汎用的かというと微妙なのですが、
モデルを共通化して落とし込んでいるという意味ではそうなりますのでその分類としています。
Stream Processing汎用
- The world beyond batch: Streaming 101
- The world beyond batch: Streaming 102
- The Evolution of Massive-Scale Data Processing
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale
- The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
- Streaming Engines for Big Data
- Introduction to Streaming Analytics
- Stream Processing Myths Debunked:Six Common Streaming Misconceptions
- A Practical Guide to Selecting a Stream Processing Technology
Apache Beam
AWS
Confluent
DataTorrent
dataArtisans
ストリーム処理とは何か?
実際、どのようなものをさすのか?
ストリーム処理という言葉は様々な用途に使用されています。
そのため、用途や実際のシステムの概ねの共通点である、下記の性質を持つ処理として定義しています。
- 無限に発生し続けるデータを処理
- 常に増大し続け、本質的には無限に発生するデータを処理します。
- データ源自体もしばしば「ストリームデータ」と呼ばれます。
- システムのログ、センサーデータ、人間の行動ログ等多々存在します。
- また、ある巨大ファイルを延々読み込む場合も、読込み結果自体はストリームデータと言えます。
- 常に増大し続け、本質的には無限に発生するデータを処理します。
- 処理が永続的に継続
- 常に増大し続け、本質的には無限に発生するデータであるため、処理も永続的に実行されます。
- とはいえ、実際は上記のようなデータであっても一定の時間の区切りをすればバッチ処理でも処理は可能です。
- そのため、区別の意味でも永続的に継続するようなものをストリーム処理と呼びます。
- 常に実行し続けるという性質上、バッチ処理以上に性能の安定性や、スパイク時に死なないことが求められます。
- ここから、BackPressureという性質が生まれています。
- 常に増大し続け、本質的には無限に発生するデータであるため、処理も永続的に実行されます。
- 低遅延、近似値&不定期な結果出力
- ストリーム処理はバッチ処理に比べて遅延が小さくなります。
- ストリーム処理が生成する結果は以後に説明する性質の関係上、しばしば近似の値だったり、不定期な出力が行われます。
- バッチ処理の場合、基本は生成されるのは完全なデータで、出力されるのはバッチ処理が実行完了したタイミングと明確ですので、それとの対比になります。
まとめてみると長くなりましたが、「無限に発生し続けるデータを処理する際のモデル」と考えておけばいいと思います。
どういう用途に使用されているのか?
あくまで例示になりますが、下記のような用途で使用されているようです。
- 課金処理
- クラウド系サービスの利用料課金
- 携帯電話の通信料課金
- ライブ費用見積
- クラウド系サービスの利用状況からの課金見積り
- 携帯電話の通信量見積もり
- 不正・異常検出
- あるシステムに対する不正ログイン検知
- システムの異常検知
- 気象データの異常検知
- 株価の異常振れ幅検知
- ユーザの行動に対するレコメンド
- 不正・異常検知ではないですが、特徴的な行動に対する反応ということでここに挙げています。
- 不正検出結果復旧
- 不正ログイン検知の結果対応
- 不正を検知したタイミングで一度停止後、再開などの対応
- システムの異常復旧
- 気象警報後の経過通知
- 異常を検知した結果、即対応できるものをした後の事後対応
- 不正ログイン検知の結果対応
システムはどのような構造を取るのか?
ここで、一般にストリーム処理を行うシステムはどのようなシステム構成を取るかを示しておきます。
というのも、一度ここで示しておかないとその後がイメージできないと思われるためです。
ストリーム処理を行うシステムで良くある構成は下記のような構成になります。
各構成要素については、「実際のストリーム処理システムってどんなの?」で再度説明します。
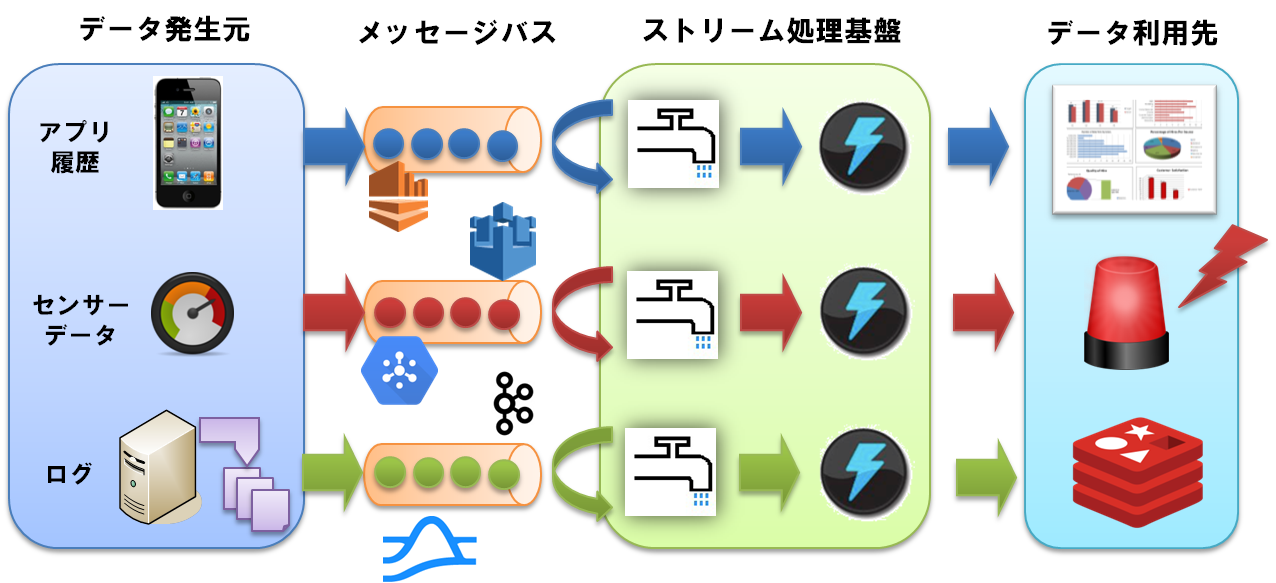
見てわかるように、一時的にメッセージバスの箇所にデータをバッファリングし、
バッファリングされたデータを取得してストリーム処理を行う構成となります。
バッチ処理とはどう違うのか?
ストリーム処理はバッチ処理とは当然異なる事情が発生してきますが、
まずはじめにビッグデータの主な処理パターンについて挙げてみます。
ビッグデータの代表的な処理パターン
代表的な処理パターンとしては下記3つが存在します。
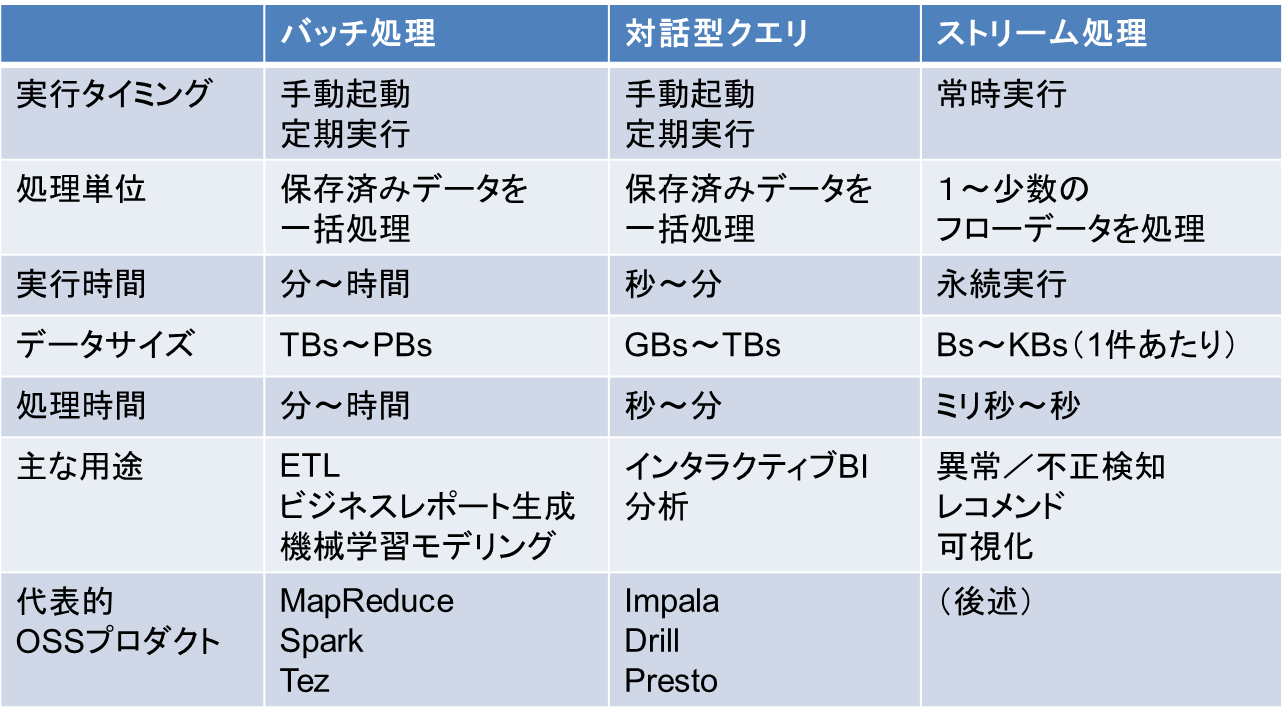
バッチ処理
データストアに蓄積したデータを一括変換し、結果出力を行う処理モデルです。
システム構成としては下記のような構成をとることが多いです。
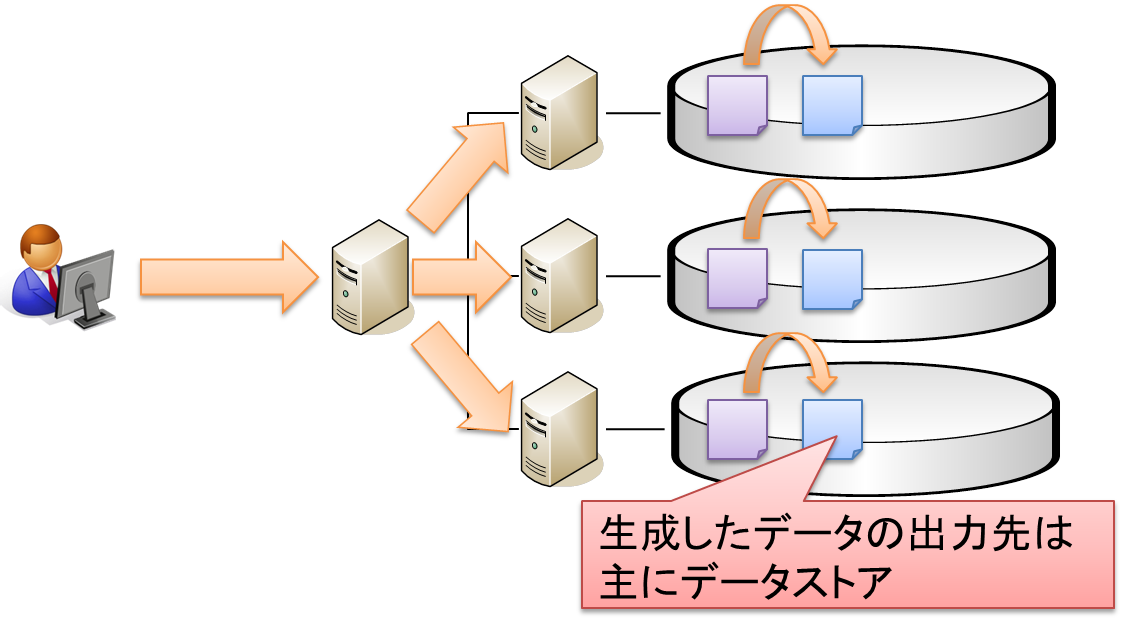
対話型クエリ
データストアに蓄積したデータに対してクエリを実行し、結果を取得するモデルです。
システム構成としては下記のような構成をとることが多いです。
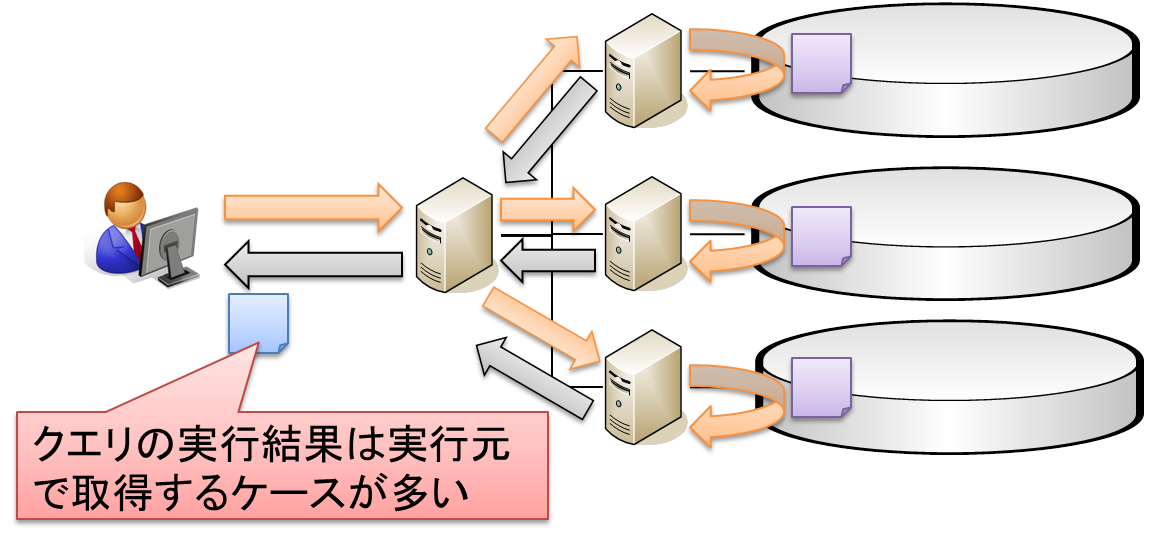
尚、上記の図だけ見るとバッチ処理の変形です。「出力先」が「実行元と同一」のパターンとなりますね。
実際のプロセスのモデルを見ると、バッチ処理&ストリーム処理は実行タイミングで
プロセスをデプロイするものの、対話型クエリの場合は常駐プロセス化していることが多い等、
違いはあるのですが、そのあたりは詳細に踏み込むので一端は省略します。
既に存在しているデータに対して分散処理をして、結果を出力(取得)という観点では
バッチ処理と変わらないのも事実ですし。
ですが、最近はクエリを設定しておき、クエリに合致したデータをリアルタイムで取得するという
「継続的クエリ」も広まっているため、バッチ処理/ストリーム処理両方のモデルに跨ったモデルとなるでしょう。
つまり、代表的な処理パターンの一項目ではありますが、
実態はバッチ処理/ストリーム処理のどちらかに含まれるということになります。
そのため、このモデルは以後の説明では省略します。
ストリーム処理
ここまで説明したとおりになります。
システム構成は「実際のストリーム処理システムってどんなの?」を参照してください。
バッチ処理とストリーム処理の違い
上記の上で、バッチ処理の持っている前提を抽出してみます。
バッチ処理は、下記の前提を置いて処理を構築しています。
- バッチ処理実行時に全てデータが揃っており、処理対象の範囲が明確でないといけない。
- バッチをまたいだ結果出力は基本的に対応しない。
1つ目の前提については、バッチ処理は下記のように元から完全にそろっているデータを整形するものだ、ということからわかると思います。
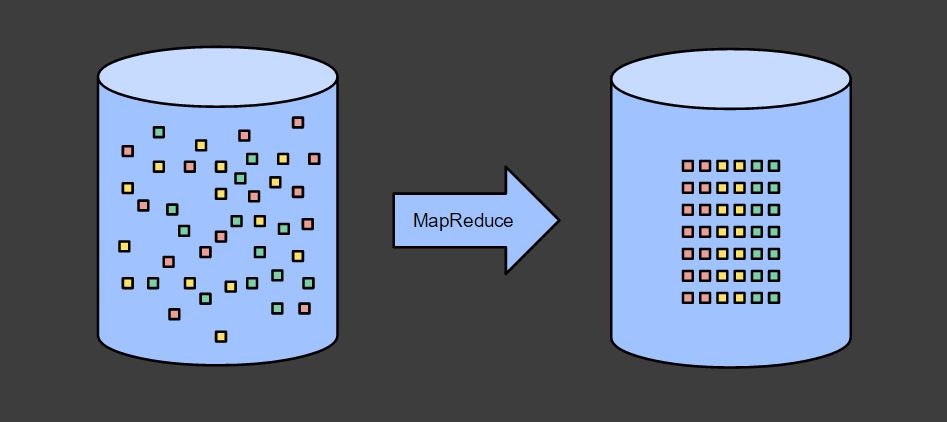
複数の結果を出力する場合には、下記のように複数回バッチ処理を実行します。
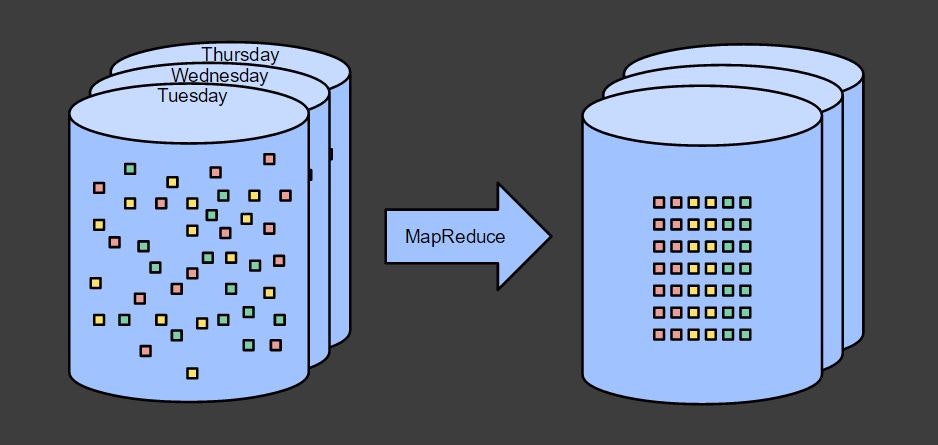
結果を時間ごとに区切る場合には、それを全て含むデータを基に、バッチ処理を実行します。
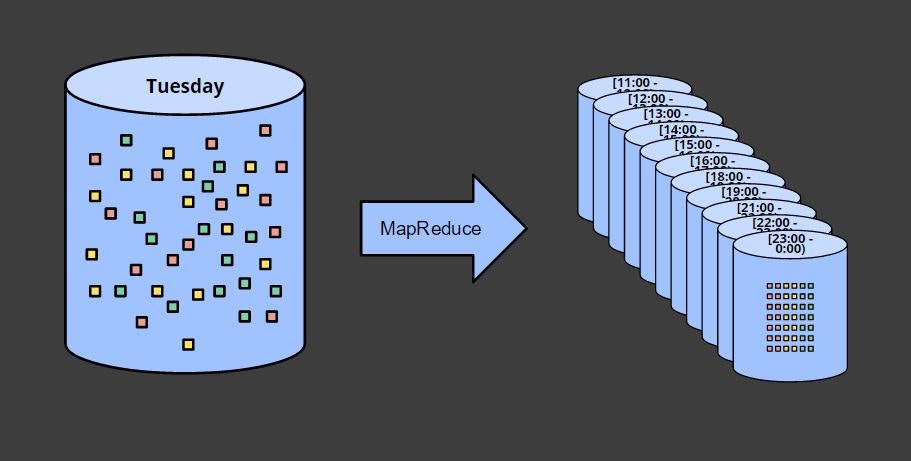
2つ目の前提については、下記のユーザのセッション(一定期間内に継続してアクセスがあった場合にさします)を出力する場合の図を見るとわかると思います。
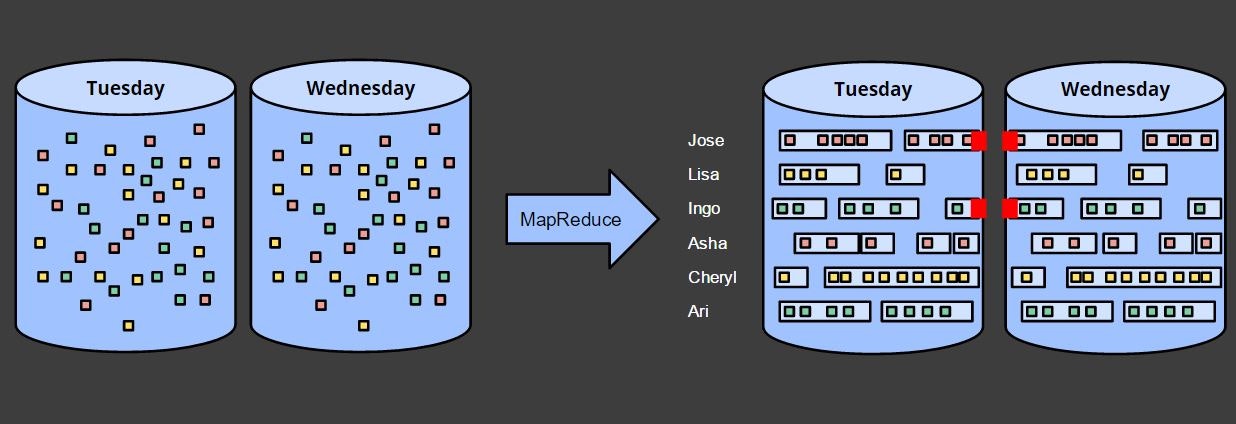
火曜日、水曜日の別々に出力すると、日を跨いだセッションが区切られます。
水曜日の結果を火曜日とつなげたければ、火曜日の結果を読み込んで新たに結果を出力しなおせばできますが、実際にやろうとすると過去の結果を全て読み込んでつなげる必要が出てくるあたり、現実的ではありません。
ここまで見ると気づくこととして、バッチ処理の2枚目の図は下記のように変形することが出来ます。
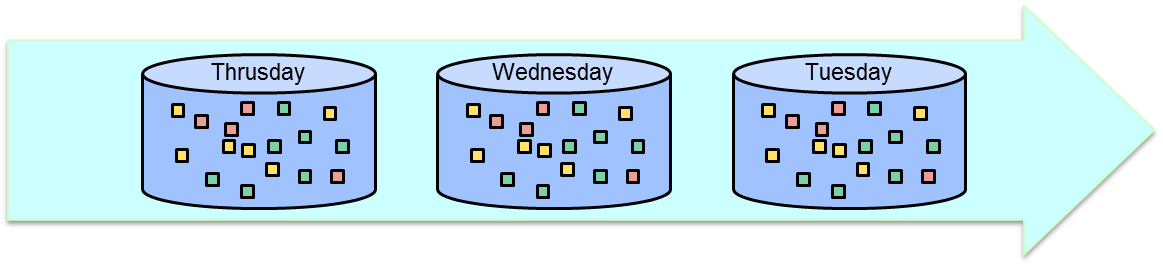
これは、すなわち無限のデータであるストリームデータを一定時間ごとに区切ったものに他なりません。
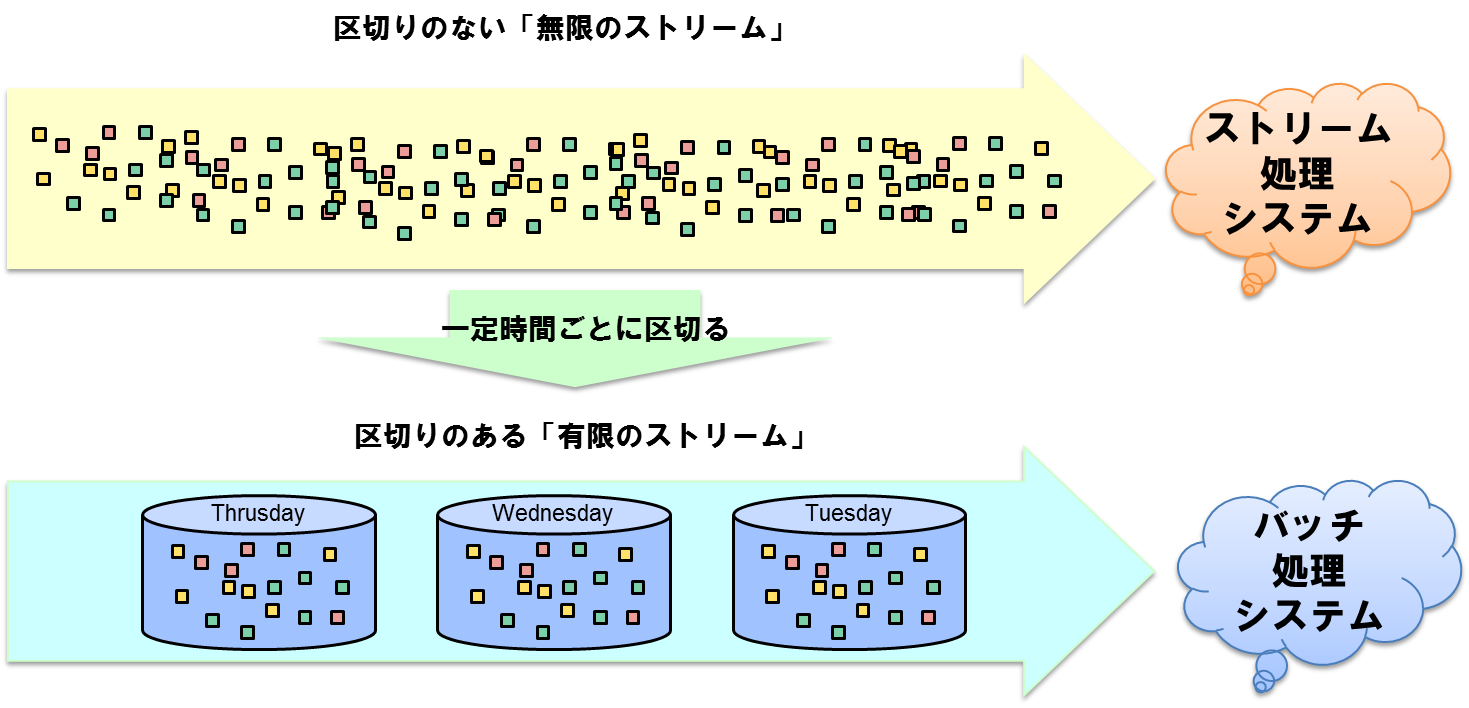
つまり、バッチ処理とは、ストリーム処理の中の限定的な処理のモデルであるということです。
ですが、ストリーム処理は下記の通り、バッチ処理にあった前提を適用することは出来ません。
- バッチ処理実行時に全てデータが揃っており、処理対象の範囲が明確でないといけない。
- > 無限のデータであり、常時データは到着し続けるためデータが揃うということはない。
- バッチをまたいだ結果出力は基本的に対応しない。
- > そもそも無限のデータを処理つづけるもののため、前提自体が違う。
ただ、バッチ処理と同じく実行時に全てデータが揃っていれば(時間ごとに区切られたデータが存在すれば)、
バッチ処理と同じことを実行することは可能です。
このあたりはバッチ処理とは、ストリーム処理の中の限定的な処理のモデルであるということが実感できるポイントになりますね。
(※ただし、これはあくまで機能的にはということで、人間の理解のしやすさや管理のしやすさ、性能的な効率とかは当然別途比較する必要があるとは思います。)
バッチ処理にはない、どういう新たな困った点があるのか?
ストリーム処理で無限のデータを処理する場合、新たな困ったことが出てきます。
それは、「データが発生した順にシステムに到着するわけではないこと」(Out of order)です。
例えば、スマートフォンからデータを収集するようなストリームデータ処理を行う場合、電波が切れて、
その後しばらくしてから電波が復旧した場合、「電波が切れたタイミングのデータ」が後から到着することになります。
Out of orderの要素としては下記のようなものが考えられるでしょう。
- 大きなずれが発生する要素
- ネットワーク切断
- 上記のスマートフォンの事例もそうですね。
- ネットワーク遅延
- ネットワーク切断
- 小さなずれが発生する要素
- 分散システムであるがゆえに発生する遅延
- これは複数のマシンで構成される以上必ず発生する要素です。
- マシン間の時刻のずれ
- 分散システムであるがゆえに発生する遅延
上記のような事情があるため、ストリーム処理では下記のように複数の時刻の概念が存在します。
- イベント時刻(EventTime)
- 実際にデータを生成することとなったイベントが発生した時刻
- 到着時刻(IngestTime)
- システムにデータが到着した時刻
- 処理時刻(ProcessingTime)
- 実際にストリームデータを処理した時刻
ただ、本質的には「複数の時刻が存在する」「Out of orderである」が重要となります。
そのため、以降はイベント時刻(EventTime)と、処理時刻(ProcessingTime)のみを前提に考えます。
何故それで困るのか?
仮にデータの到着が遅れても、データ間に関わりが無ければ「結果が近似値である」ということはわかるものの、システムを構築する際に特に困ることはありません。
システムに到着し次第処理し続ければいいわけですので。
(※どのタイミングで全部到着したと判断すればいいのか、という問題は別個ありますが。)
ですが、先ほどバッチ処理の処理モデルの図に出てきたように、ストリーム処理では下記のようなウィンドウという概念が求められることがあります。
例えば不正検知であれば一件のアクセスだけで不正だと検知可能なケースは限られ、「短い時間内に大量のログイン失敗があった」というような前後のデータとの関連性で不正が検知されるのが主となるためです。
- 固定長ウィンドウ(Tubling Window)
- 1時間ごと、等の一定の時間ごとに区切った範囲のウィンドウ
- スライディングウィンドウ(Sliding Window)
- 毎分、過去5分間分の結果を集計して出力するといった範囲が移動するウィンドウ
- セッションウィンドウ(Session Window)
- 一定時間以内にアクセスが連続した場合にそのアクセスを紐づけるという長さが固定されないウィンドウ
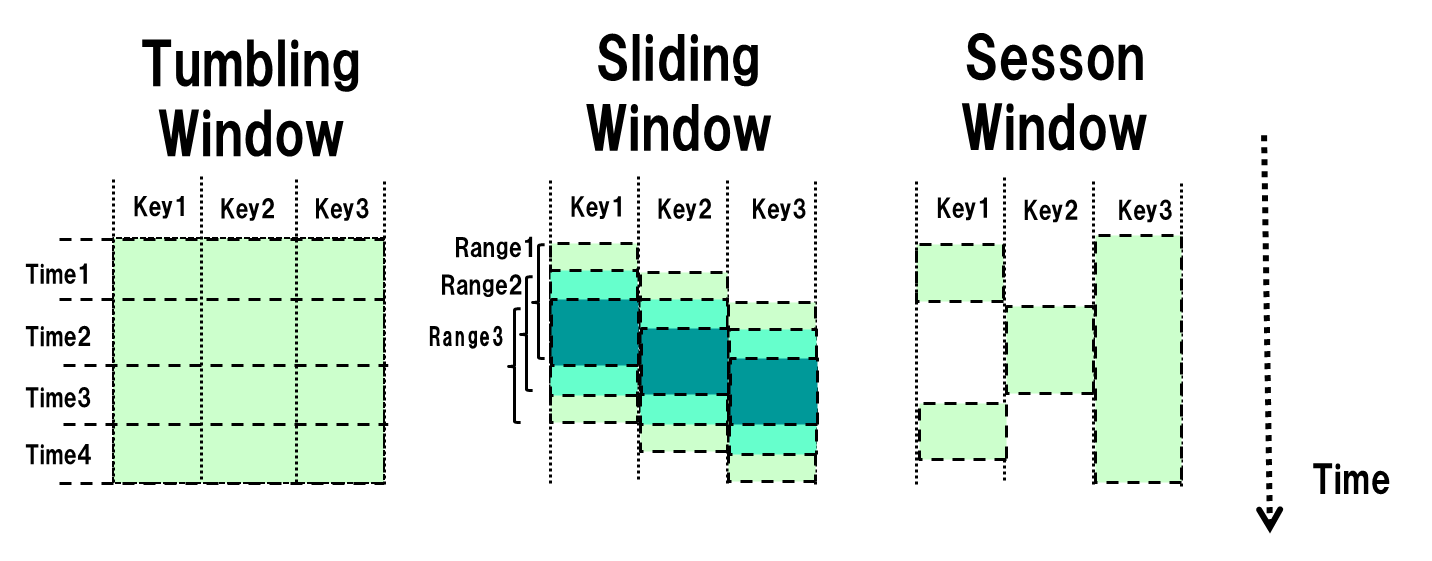
ここで「データが発生した順にシステムに到着するわけではないこと」が大きな問題になってきます。
何故なら、「17:00~17:59の間に発生したデータに対する固定長ウィンドウの集計結果」を出力した後に「17:10に発生したデータ」が遅れて到着したらどうするのか、という問題が発生するためです。
新たな困った点をどうやったら解消できるのか?
「データが発生した順にシステムに到着するわけではない」中で、
ウィンドウの結果をどう出力するかについて、3つの要素を組み合わせることで対応が行いやすくなります。
どのイベント時刻まで処理したかの区切り(Watermark)
Watermarkはイベント時刻ベースでどこまで処理が完了したかを示す概念になります。
イベント時刻と処理時刻が別に存在する場合、実際の処理時刻と、どこまでイベント時刻的に処理したかというのは下記の図のようにずれてきます。
そのため、Watermarkという概念が必要になります。
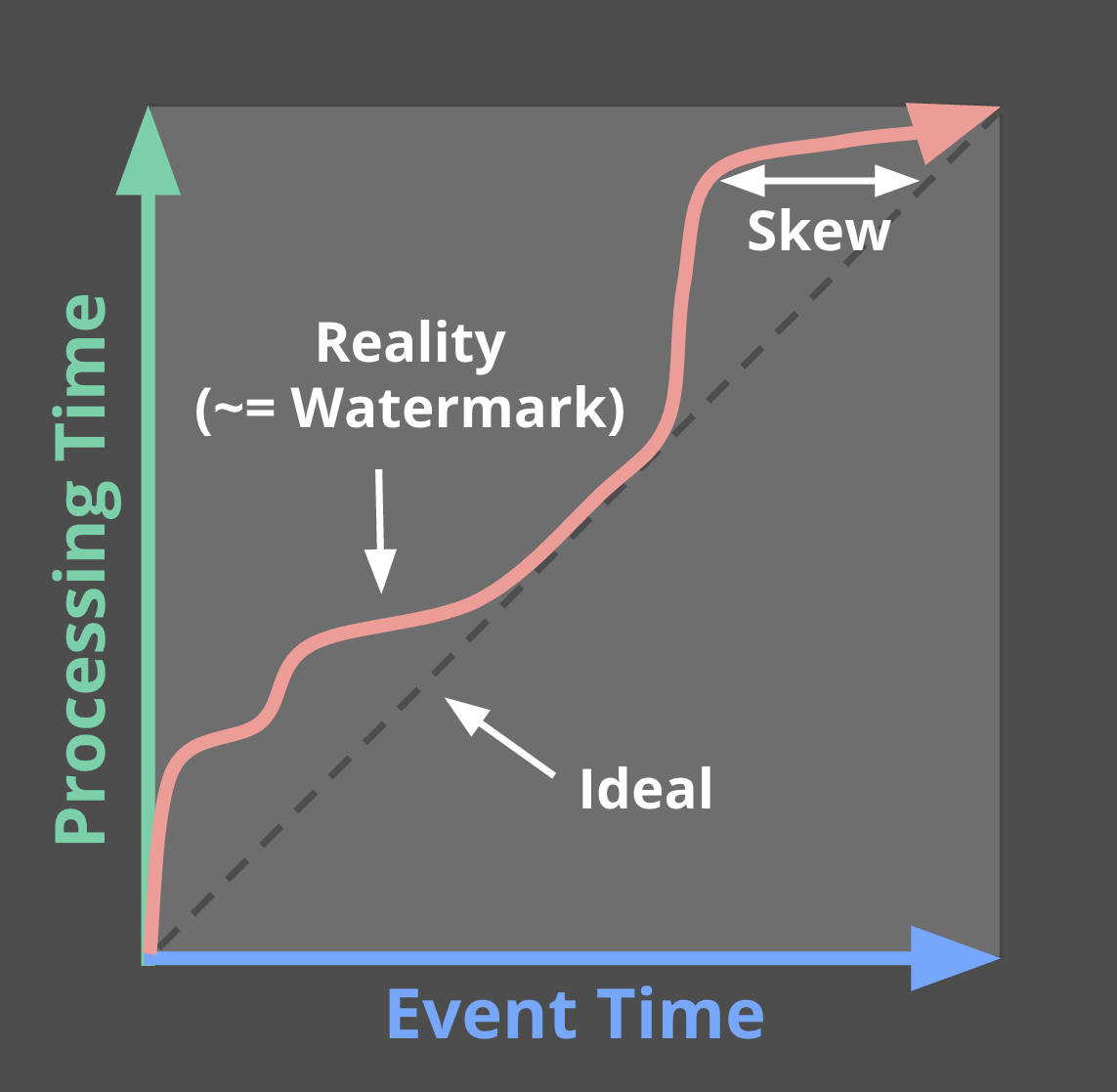
例として、WatermarkがXの値を取った場合、「イベント時刻がXより小さいデータは全て処理されている。」ことを示すわけですね。
つまりはWatermarkは無限のデータを処理している状態において、どこまで進んだかを示す"区切り"として動作します。
ただし、ここで注意しておくべきことは、Watermarkは決して完全なものにはなり得ないということです。
データが遅れて到着する以上、Watermarkは「多分このくらい遅れるだろう」という目算に過ぎないものとなってきます。
(※だったらそんなの必要ないだろという突込みがあるかもしれませんが、目算でもないと処理ができないという事情がありますので。)
集計結果をどのタイミングで出力するかを定義する機構(Trigger)
Triggerはウィンドウ集計結果をどのタイミングで出力するかを状況に応じて定義する機構になります。
Triggerを定義することによって、いつウィンドウ集計結果を出力するべきかについて実体化するべきかについて柔軟に定義が可能となります。
加えて、Trigger機構によってウィンドウ集計結果をデータが更新される毎に複数回出力するということも可能になってきます。
この機構によって、Watermarkが一定の場所に達したり、Watermarkより遅れたデータが到着した際に、その都度投機的な出力が行えるようになります。
例として、Watermarkが固定長ウィンドウの最後まで達した場合に集計結果を出力するという場合はClouddataflowでは下記のようなコードで記述が可能になっています。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) // 固定長ウィンドウを宣言
.triggering(AtWatermark())) // Watermarkが到着したタイミングで出力
.apply(Sum.integersPerKey());
上記に加えて、遅れたデータが到着した場合に結果を再出力するような場合は下記のように記述が可能です。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) // 固定長ウィンドウを宣言
.triggering(
AtWatermark()) // Watermarkが到着したタイミングで出力
.withLateFirings(AtCount(1)))) // 遅れデータが1件到着するごとに出力
.apply(Sum.integersPerKey());
更に、遅れたデータが到着した際にウィンドウを保持する期限を5分間の遅れまでと限定し、
それ以後に到着したデータを除去する場合は下記のように記述が可能です。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) // 固定長ウィンドウを宣言
.triggering(
AtWatermark()) // Watermarkが到着したタイミングで出力
.withLateFirings(AtCount(1))) // 遅れデータが1件到着するごとに出力
.withAllowedLateness(Duration.standardMinutes(5))) // 遅れの許容を5分間まで
.apply(Sum.integersPerKey());
つまり、Triggerの機構によって、下記が制御可能となることがわかります。
- 集計結果の出力タイミング
- Out of orderなデータへの対応
- 出力を行うタイミング
- EventTimeとProcessingTimeのずれの許容期間
集計結果出力時の累積計算方式(Accumulation)
Accumulationは同一ウィンドウ内で複数回集計結果が出力された場合の関係性や動作を定めるものです。
これは、集計結果の出力先システム、つまり、どう使用するかに依存してきます。
例えば出力先システムがそれまでの集計結果を足し合わせていくようなケースでは、1回ウィンドウで集計結果を出力したらその値は破棄し、次の出力は新たなデータの集計結果を出力すればOKです。
対して、出力先システムがユーザIDと時刻をキーにしたKey-Value Storeのようなデータ構造の場合は、1回ウィンドウで集計結果を出力した後もその値を保持しておき、次の出力は既存のデータと新たなデータをあわせた集計結果を出力する必要が出てきます。
上記のような集計結果出力時の値の取り扱い方についての方式を切り替える機構がAccumulationです。
Accumulationのモードとして主に下記の3つの方式が存在します。
- 破棄モード(Discarding)
- ウィンドウの集計結果を出力したタイミングで集計結果は破棄されるモード
- つまり、ウィンドウの集計結果を一度出力した場合、状態はクリアされ、次の集計出力においては、出力後に到着したデータのみの集計結果を出力する動作となります。
- このモードは下流のシステムが自前で何かしらの累積計算の機構を保持している場合に有用です。
- 例えば、集計値として前回との差分を送信し、外部システムはその値を合計して最終結果とするなど。
- 累算モード(Accumulating)
- ウィンドウの集計結果を保持し続け、前の値に対してその後の値を累算させて値を出力するモード
- このモードは新しい結果で古い結果を上書きすればいい場合に有用です。
- 例えば、BigTableのようなKVSに結果を出力するケースなど。
- 累算&後退モード(Accumulating & Retracting)
- 累算のモードに似いますが、新たな集計結果を出力する時には前回の値を基にした相殺するための差分値(後退値)を出力するモード
- 後退(前の値と今回の値を基にした結果)の方式で基本的な考え方として、「以前は結果をXとしたが、それは間違っていた。Xの代わりにYで更新するよ。」となります。
- このモードは下記のような場合に有用だと考えられます。
- Session Windowを使用する場合に新しい値は単に前の値を更新するだけでなく、前のWindowの値を統合するなど
- 下流のシステムが複数存在し、各々異なる方式で集計を行うなど
実際に複数のモードの動作を比較することで、各モードの違いを明確にします。
12:00から12:02までのデータを集計する場合において、下記のような順序でデータを受信したと仮定します。
| No | 処理時刻 | イベント発生時刻 | イベントの値 |
|---|---|---|---|
| 1 | 12:05 | 12:02 | 7 |
| 2 | 12:06 | 12:00 | 7 |
| 3 | 12:07 | 12:01 | 8 |
すると、モードごとの出力値は下記となります。
一見意義がわかりにくかった累算&後退モードですが、
こうしてみると、最終的な値を見ても、総計値を見ても、一定の値が保たれることがわかります。
| 破棄モード | 累算モード | 累算&後退モード | |
|---|---|---|---|
| Event1 | 7 | 7 | 7 |
| Event2 | 7 | 14 | 14,-7 |
| Event3 | 8 | 22 | 22,-14 |
| 最終値 | 8 | 22 | 22 |
| 総計値 | 22 | 43 | 22 |
その対処で全部に対応するのは無理なんじゃないの?
Watermark、Trigger、Accumulationの機構が導入されればストリーム処理は全て対応可能かというと、
そんなことはありません。
何故なら、下記のような問題が発生してくるからです。
- Watermarkを実時刻からどれくらい遅らせて設定すればいいのか?
- 遅れを大きくすれば正確性は増しますが、遅延時間は大きくなります。
- Accumulationのためにウィンドウの集計結果をどれだけ保持すればいいのか?
- 保持する時間が長いほど、ストリーム処理を行うシステムのリソースが必要となります。
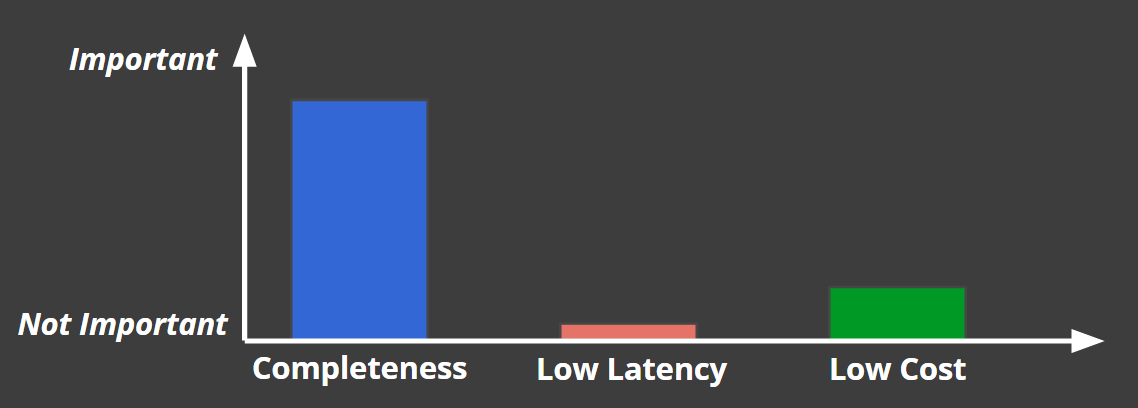
データ処理システム(バッチ、ストリーム含む)には下記の3要素のトレードオフがあるとされています。
- 完全性(Completeness)
- 低遅延(Low Latency)
- 低コスト(Low Cost)
この3要素を全てに満たすことは出来ず、全てのデータ処理システムはこの3要素のバランスで構成されるというものです。
ここでのコストとは、データ処理システムのリソースだけでなく、
データを収集する経路などに対するコストも含まれると考えていいと思います。
例えば、課金処理であれば、下記のように完全性重視で、遅延が多少発生したりコストがかかっても問題ないという判断になります。
対して、不正検知システムでは低遅延が最優先で、その他の要素の優先度は下がります。
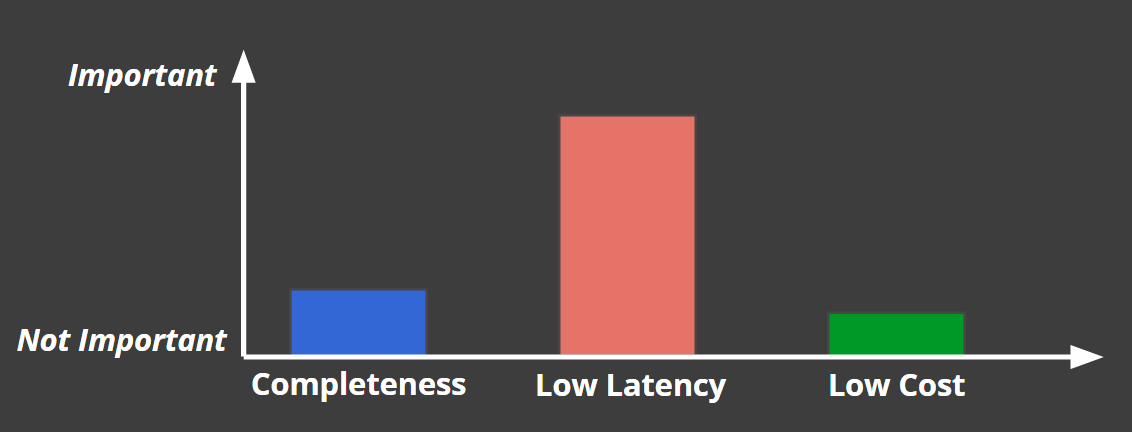
上記のような事情があるため、
実際に開発するシステムで何が求められるかを基に落としどころを見つける必要があるという形になってきます。
実際のストリーム処理システムってどんなの?
ここまでのストリーム処理とはどんなものか、を述べてきたため、
この後はストリーム処理を行うストリーム処理システムはどのようなものになるか、を説明します。
システム構成
システム構成は前にも出てきましたが、下記の図のような構成を取ることが多いです。
各構成要素の役割について説明します。
メッセージバス
ストリーム処理ステムは発生し続ける無限のデータの発生元の特性上、
いきなりデータ流量が増大するスパイクが発生することが多いです。
また、障害発生時にメッセージの処理保証を行うケースなど、
同一のメッセージを複数回取得することもあります。
そのため、一時的にメッセージバスにデータを蓄積するアプローチをとることが多いです。
- 使用される主要なプロダクト
- Apache Kafka
- (Distributed Log)
- (Pulsar)
- 使用される主要なマネージドサービス
- Amazon Kinesis Stream
- Google Cloud PubSub
- Azure Service Bus
ストリーム処理基盤
メッセージバスからデータを取得し、ストリーム処理を行う基盤部分です。
停止することがなく、ずっと動き続けるもののため、
バッチ処理と比べてプロセス自体の安定度が求められることが多いです。
使用されるプロダクトやサービスについては、数や考えることが多くなるため、
「ストリーム処理基盤にはどのようなものがあるのか?」を確認してください。
データ利用先
ストリーム処理基盤で処理したデータを出力し、実際に使用する機能です。
この箇所については完全にシステムに依存するため、一概にどうとは言えません。
尚、このデータ利用先が再度メッセージバスとなっており、
そこから多段でストリーム処理を行うというパターンも存在しています。
ストリーム処理基盤にはどのようなものがあるのか?
ストリーム処理システムで実際にデータの処理を行う、
ストリーム処理基盤を実現するためのプロダクトやサービスについて説明します。
ストリーム処理基盤の系譜
まず、ストリーム処理基盤の系譜を見ると、下記のようになります。

ただ、一言でストリーム処理基盤といっても微妙に性質が変わってくるため、仮にいくつかのカテゴリ分けを行います。
きちんと中を見始めると厳密にこのカテゴリ分けはあてはまりませんが、
とりあえずわかりやすく切るために上記の図のように切っています。
カテゴリ毎の分類
各カテゴリは下記のような位置づけ/機能となります。
- ストリーム処理エンジン
- 特に他に特別な機能を持たないストリーム処理エンジン
- UIでDataflow定義
- UIでDataflowが定義可能になっており、その定義の通り動作する機能を保持
- DSL
- 同一の記述で複数のストリーム処理エンジン上でアプリケーションが実行可能
- マネージドサービス
- クラウド上で実行基盤が提供。アプリケーションをデプロイするとそれに従って動作する。
プロダクトの解説(一部)
上記の図にあるプロダクトやサービスの一部の概要を解説します。
基準は私自身がある程度以上知っているものになるため、偏りはありますが・・・
Storm
- 2011年にTwitterによって公開
- 実装言語:Clojure
- Clojureが読み書き出来ないと深い問題は追えない。
- 実質的にユーザに対して初のOSSストリーム処理エンジン
- メッセージの処理セマンティクスとして、At Least Onceが可能になったのが大きい。
- ただし、初期のプロダクトのため問題も多かった。
- 初期はメッセージ単位の処理であり、レイテンシは低いがスループットが小さい。
- データ取得側の性能が高いとあふれて死ぬ。
- デフォルトのスレッド配置が非効率。
- At Least OnceのAckの処理効率が非効率。
- 以後のストリーム処理プロダクトに大きく影響している。
Spark Streaming
- 2013年にamplabによって公開
- 実装言語:Scala
- バッチ処理フレームワークSpark上で小バッチを連続実行し、ストリーム処理を実現
- マイクロバッチと呼ばれる。
- 発表時点で、主にStormと比してスループットは大きいが、レスポンスは遅い。
- 現時点ではFlinkやApexが出てきており、それと比べると両方微妙な状況。
- 全体として、大規模クラスタを前提としているSparkのアーキテクチャに沿っているため効率も悪い。
- Sparkエコシステム上で実行可能なのが大きい。
- 機械学習ライブラリの利用
- SQLによるデータ操作
- 開発手法も同様のものが利用可能
NiFi
- 2014年にNSAによって公開
- 実装言語:Java
- 画面上でデータフローを定義し、複数サーバにデプロイして実行可能
- HTTPでデータ取得>変換>HDFSに投入 etc…
- コンポーネント間のキュー毎に優先度設定やQoS設定が定義可能
- 各データの発生元や処理履歴の確認機能があり、個別のデータ単位で実際にどう処理が行われたかを追える。
Flink
- 2014年に公開
- 実際は2011年からStratosphereとして公開されてはいた
- 実装言語:Scala
- バッチ処理とストリーム処理両方のAPIを提供するデータ処理エンジン
- 障害対応のための状態の自動保存として、効率のいい分散スナップショット方式を使用
- 自動的に各コンポーネントの状態を保存
- 詳細はApache Flinkの分散スナップショットの方式参照
- 高レベルAPIと低レベルAPIの両方を提供
- 簡易なものは簡単に組める。
Apex
- 2015年にDataTorrentによって公開
- 実装言語:Java
- 元々金融アプリケーション用プロダクトで可用性、耐障害性重視の設計
- 運用時の問題切り分けも容易な構成
- メッセージバッファリングで障害発生時の影響を低減
- 状態の保存、実行環境共にバランスよく高レベル
- HDFSをKVSのように使って耐障害性とレスポンスを両立
- YARN上でオーバーヘッドが少なく動作可能
- スケーラビリティにも優れた構成
- ストリーム処理中にAutoScalingが可能
Gearpump
- 2015年にIntelによって公開
- 実装言語:Scala
- Googleの「MillWheel」に影響を受けたプロダクト
- ストリーム処理モデルの論文
- Actorベースの「薄い」構成で拡張性が高い。
- その分、状態管理なども自前で準備する必要有
- 開発コストは高めだが、性能的にも優れる。
- Reactive Streamsに準拠しており、標準化されたBack Pressure機構を保持
- Akka Stream方式の記述により直観的にグラフを定義可能
Beam
- 2016年にGoogleによって公開
- 実装言語:Java
- バッチ処理/ストリーム処理を抽象化し、複数の実行エンジン上にデプロイ可能なDSL
- 下記のストリーム処理エンジンに対してデプロイ可能(端的に最近のJVM上ストリーム処理エンジンなら大体対応)
- ポータビリティは高いが、各エンジンの固有拡張機能、固有ライブラリは使用できない。
- 機械学習などの機能を使用する場合、別途TensorFlowなどにデータを渡して実行する必要がある。
Google Cloud Dataflow
- 2015年にGoogleによって公開
- Beam(公開当初はDataflow API)で記述した処理をマネージドサービス上で動作可能
- 他のマネージドサービス系プロダクトに比べて、可能な処理の幅が広い
- 「ストリーム処理アプリケーション」として記述可能であるため
- CPUの利用率を極力高めるように自動で調整されるため、リソースの遊びが発生しにくい。
Amazon Kinesis Analytics
- 2016年にAmazonによって公開
- SQLでストリーム上に流れているデータに対して継続的クエリを実行可能
- 出来る機能は絞られるが、非常にお手軽にストリーム処理を定義可能
- データを蓄積する前に分析・アクションを実行するというData in Motionの考え方のベース
- SQL方式ではあるものの、EventTimeとProcessingTimeの区別が可能など、機能はそこそこ広い。
- 内部で自動的にスケールするが、その分リソース使用量が事前に読みにくい。
どれを使えばいいの?
現時点で見ると、個人的にはオンプレ環境上で動作させるならFlinkとApexが性能・機能・開発効率のバランスがいいと考えています。
Gearpumpは説明にもありますが、カスタマイズ性が高く、性能も高めになるものの、
その分各要素をActorとして実装する必要があり、多くのアプリケーションを開発する上では開発効率的に微妙な印象です。
Spark Streamingは現時点でSpark上で動作させているバッチ処理を移行するコストが低いため、
現時点で既にSparkを使用しているなら適しています。
クラウド上で実行するなら、今使用しているクラウドサービスのものを使用するのが無難です。
ストリーム処理システムを構築する上で気を付けるべきことは?
ストリーム処理システムを構築する上での検討ポイントや開発時に仕込むべきポイント、
あとは落とし穴やよくある誤解などについてまとめます。
検討するべきポイント
ストリーム処理システムを構築するにあたり、検討しておくべきポイントは多いです。
その中でも代表的なものをまとめていきます。
- 状態管理方式
- 「状態」をローカルに管理するか?それともリモートのデータストアに管理するか?
- 耐障害性とパフォーマンスのトレードオフが発生
- 障害復旧時にどれくらいかかるか?
- その「状態」に対してアクセス可能な構成になっているか?
- 「状態」をローカルに管理するか?それともリモートのデータストアに管理するか?
- データの抽象定義
- データをどういう形式としてとらえて処理するか、という観点
- 大体のストリーム処理エンジンはデータストリームとしてデータを扱う
- Kafka Streams、Spark Streamingでは一定の間隔ごとの実行結果を「Table」として扱うことも可能
- 時刻モデル
- EventTimeを扱う必要があるか、それともProcessingTimeだけでいいのか?
- ProcessingTimeだけでいい場合、大幅に単純化するため、諸々コストが下がる。
- ただ、あとから切り替えるのは大変なので、あらかじめ決めておくこと。
- EventTimeを扱う必要があるか、それともProcessingTimeだけでいいのか?
- ウィンドウ処理
- 「何故それで困るのか?」で記述していますが、どの種別のウィンドウ処理が必要になるか?
- Out of orderなデータへの対応
- 「バッチ処理にはないどういう新たな困った点があるのか?」「新たな困った点をどうやったら解消できるのか?」参照
- どこまでを許容するか、どう扱うかを決める必要がある。
- 再処理が可能な構成にするか?
- A/Bテストを行ったり、機能の追加や不具合対応を行った際に再処理を可能にするか?
- 再処理を可能とする場合、既存のデータとの互換性維持やどうマージするかということが事前に検討が必要。
- 処理の拡張・縮小
- 実行中に処理規模の縮小・拡大を可能とするか?
- それともアプリケーションの再起動で問題ないのか?
- 最小実行単位はどの単位になるか?
- 基本、ストリーム処理システムは常時実行となるため、最小でもこれは常に必要と明確にすることが必要
- メッセージ処理セマンティクス
- メッセージの処理セマンティクスとして、どれを適用すればいいのか?
- At most once
- At least once
- Exactly once
-
全ケースをカバーするExactly onceは存在しないため、それを大前提に置く必要がある。
- ストリーム処理エンジンで保証可能なのは、「自身の内部状態がExactly onceで処理した状態になっていること」
- 外部へ出力を行う場合には活用する側でデータのキーで重複除去を行ったり、Accumulation方式による対処が必要
- メッセージの処理セマンティクスとして、どれを適用すればいいのか?
- 耐障害性
- 障害が発生した場合にどれくらい影響や遅延が出る構成になっているか?
- 障害発生時は自動で復旧するのか?それとも手動か?
- 障害復旧にかかる時間はどれくらいか?
- バックプレッシャー機能の有無
- 構成要素間でスループットの差分が発生した場合に、下流に合わせて流量を制御する機能
- この機能がない場合、事前にどれだけのスループットが出るかを見切っておく必要が出る。
- セキュリティ
- 保存するデータの暗号化が必要か?
- 必要な場合、どのタイミングで暗号化しておくか?
- アプリケーション毎にどのデータにアクセス可能かの制御をどう行うか?
- 保存するデータの暗号化が必要か?
- データの処理モデル
- レコード毎の処理か?(マイクロ)バッチモデルか?
- レコード毎処理するモデル
- 低レイテンシが特徴だが、スループットを出せるかは実行エンジンに依存。
- Out of orderなデータの取り扱いも行いやすい。
- (マイクロ)バッチモデル
- バッチ自体に起動終了・状態保存処理も伴うため、マイクロバッチは非常に中途半端な状態になりがち。
- レコード毎処理するモデル
- レコード毎の処理か?(マイクロ)バッチモデルか?
- 開発API
- どのような抽象度の開発が可能か?
- 開発メンバのスキルや優先すべきもの(カスタマイズ性?開発スピード?)等によって検討が必要
- 開発時のAPIは主に下記の3つ。
- 宣言型定義(開発スピード〇、カスタマイズ性〇)
- map()、filter()などのデータストリームに対する処理を宣言
- 命令型定義(開発スピード△、カスタマイズ性◎)
- process(event)という形で各イベントレベルで処理を実装
- Streaming SQL(開発スピード◎、カスタマイズ性△)
- データストリームに対して適用するクエリ(STREAM SELECT FROM WHERE....)
- 宣言型定義(開発スピード〇、カスタマイズ性〇)
- ストリーム処理とバッチ処理を同一のAPIで開発可能なのか?
- どのような抽象度の開発が可能か?
- どのような拡張ライブラリが必要か?
- 機械学習
- グラフ処理
- 外部コンポーネントとの接続
- UIの充実性
- 大抵ストリーム処理エンジンにはUIも組み込まれている
- UIからどのような情報が見れるか?
- UIからどのようなオペレーションが可能か?
- 実行グラフが表示されるのも有用
- Shuffleの回数などがわかれば、非効率な処理を行っているかについても解析しやすい。
- 大抵ストリーム処理エンジンにはUIも組み込まれている
- 開発サイクルとオペレーション
- アプリケーションという形でローカルで実行できるか?それともクラスタ上でないと実行できないか?
- ローカルで実行できる場合、テストコード>クラスタ環境の差分を埋めることが出来る。
- 事前に何かしらのインストールが必要なのか?それともリソースマネージャ上にデプロイすればいいのか?
- ログやエラーの集約が可能なのか?
- 分散処理で個々のサーバからログを取得して確認するのは無謀。
- ストリーム処理エンジンの機能か、または独自でログやエラーを一か所で見れるようにしておく必要がある。
- アプリケーション更新時に再起動していいのか?それともNo downtimeでローリングアップデートが必要なのか?
- 既に使用している開発ツールとどれだけ親和性があるか?
- いざという時に解析が可能なよう、開発チームが理解できる言語で開発されているか?
- アプリケーションという形でローカルで実行できるか?それともクラスタ上でないと実行できないか?
実際にシステムを組んでみるとどんな場所がボトルネックになるの?
実際にストリーム処理システムを組んでみると、様々なボトルネックが発生します。
その中から代表的なものを。
- ファイルアクセス
- 初期の理解が浅い時期に主によくはまる。
- データを処理するたびにファイルアクセスが発生するような機能の場合、そこがボトルネックになる。
- キャッシュを活用するなどして同期的なファイルアクセスを発生しないようにする必要がある。
- 不要なプロセス間の通信
- バッチ処理でも同様だが、Shuffleを実行した時のプロセス間の通信負荷はストリーム処理でも大きい。
- 事前にプロセス内で集約しておくなども行い、プロセス間の通信頻度と量を抑えること。
- メッセージバスの処理性能が追い付かなくなる
- KafkaであればStormやSpark Streamingの時代はメッセージバス側がボトルネックになることは少なかった。
- FlinkやApexの世代になってくるとKafkaの性能を振り切ることも多くなってきている。
- メッセージバス側のクラスタサイズ調整やレプリケーション設定を見直す。
- GC
- JVM上で動作するストリーム処理エンジンが多いため、どうしてもぶつかる問題。
- まずはJVMのチューニングを行う。
- それでもどうしようもない場合
- アプリケーションでのオブジェクトの生成数を極力抑える。
- オブジェクトに個々のフィールドではなくバイト配列でまとめて持たせる。
- JVM上で動作するストリーム処理エンジンが多いため、どうしてもぶつかる問題。
ストリーム処理に対する誤解
ストリーム処理に対するよくある誤解について解説しておきます。
- ストリーム処理では近似値しか出せず、バッチとの組み合わせが必須である。
- 初期のStormでは実際そうで、Lambda Architectureという形で対処がとられていました。
- 今ではWatermark、Triggerなどを使ってそれも制御可能です。
- レイテンシとスループットはどちらかを選ぶ必要がある。
- それも、初期のStorm VS Spark Streamingの比較から来ている話です。
- 実際プログラム上ではその2軸のトレードオフはありません。
- ただし、今は新たなトレードオフがあるため、「その対処で全部に対応するのは無理なんじゃないの?」を参照
- マイクロバッチ方式の方がスループットが高い。
- レコード毎処理であってもデータはバッファリングされているため、実際にはそうではないようです。
- マイクロバッチ方式はバッチとして区切ることによる管理コストが発生するため、今となっては利点が薄いと言われています。
- Exactly onceは不可能
- 実際に全ケースへの対応は不可能ですが、下記の2ケースを分けて考える必要があります。
- 「正確に1回実行されたという状態」をストリーム処理エンジン側に維持することは可能です。
- 「正確に1回外部に通知」は他のデータストアなどとの重複除去機構をかませる必要があります。
- 実際に全ケースへの対応は不可能ですが、下記の2ケースを分けて考える必要があります。
- ストリーム処理はリアルタイム系の処理にしか適用できない
- 「バッチ処理とストリーム処理の違い」にあるとおり、ストリーム処理はバッチ処理の機能的な上位互換になります。
- そのため、効率は別途確認が必要ですが、リアルタイム系の処理ではなくても適用可能。
- ストリーム処理は難しい
- 無限のデータソースがあり、データが頻繁に変わるならモデルで対応するよりむしろ対応しやすいです。
- 初期のストリーム処理は命令型定義のみで開発コストが高かったですが、最近は宣言型定義やSQLによる定義も可能になっているため、ハードルは下がっているかと。
2016年にストリーム処理で何があったのか?
この章では2016年でストリーム処理に何があったかについてまとめます。
つまりは「2016年の出来事」になりますね。
(※個人的に印象が強かったものになります。)
Apache Beamの登場
これが個人的には一番大きかったです。
ストリーム処理はバッチ処理の機能的上位互換であるという説明をした上で、
ストリーム処理・バッチ処理をDSL的に定義して複数の環境上で共通的に実行可能なプロダクトを出してくるあたり、
流れが綺麗でシビれました。
加えて、DSL的に定義と言っても普通にJavaやScalaで開発可能なもののため、
IDEもそのまま使用できるのもポイントが高いです。
Amazon Kinesis Analyticsの公開
昨年から予告はされていましたが、Kinesisのデータを
マネージドサービス上でSQLで処理するというAmazon Kinesis Analyticsの公開で、
それまでAWS Lambdaや、自前で処理していたものをマネージドサービス上で動作できるようになりました。
もちろん、対応可能な範囲には限りがありますが、お手軽にできるというのは非常に大きいですね。
来年どうなると思ってる?
※この章については完全に私の妄想ですので、決して真に受けないようお願いします。
あと、既にやるよ、とアナウンスされている内容も混ざっているのでそれもそれで。
今年のApache Beamの登場によって、一つ大きなピースが埋まったと感じています。
そのため、構成としては大きな変化はなく、ある意味確実な進化が来年は続きそうではあります。
確実な進化としては、開発をより容易にするという方向性と、ハードの進化への追従という方向性が
出てくるのではないかと勝手に想像しています。
開発をより容易にするというのは、APIの充実と、UI型プロダクトの拡大があります。
ストリーム処理エンジンは命令型定義>宣言型定義>SQL定義という形で開発が容易になっていきますが、
それをフルセットで揃えているエンジンは限られます。
そのため、複数のエンジンがそのAPIを充実させてくるのではないかと踏んでいます。
UI型プロダクトの拡大については、NiFiやSpring Cloud Dataflowでは現状UIから定義した状態を
保存は可能ですが、UIから定義するということはつまりはコードで管理できないため、使い込むと問題になります。
そのため、とっつきやすく、かつ使い込んでもメンテがしやすい構成になってくるのではないかと。
ハードの進化への追従というのは、ManyCore、大容量メモリへのハードへの追従ですが、
実際の所はその上で動かした場合にストリーム処理としてどういう課題が出てくるかの洗い出しなのかもしれません。
バッチ処理だとBoosting Spark Performance on Many-Core Machinesみたいに新ハード上での課題が出てきました。
ストリーム処理で同レベルの問題があるかどうかはまだわかりませんが、
実際どうなのかについてもストリーム処理エンジン側の情報を追っているとあまり出てきません。
私が単に無知なだけな可能性も大きいですが。
論文を探してみても、そのものずばりなのは見つからず。
MES 2016の論文には近そうだな、というのはあるものの、まだ読めていない状況ですね。
ともあれ、こんな感じです。
まとめ
長文にお付き合いいただきありがとうございます。
ストリーム処理とは何かについてをまずは説明しました。
その上で、実際のシステムを構築する上での課題や検討ポイントについてまとめて、
あとは個人的な2016年の出来事と来年どうなるかについて書きました。
一気に書いているものなので誤りやわかりにくい点などあるかとは思いますが、
あればコメント等に書いていただければ幸いです。