この記事は?
この記事は、Distributed computing (Apache Hadoop, Spark, ...) Advent Calendar 2016の18日目の記事です。
この記事で書いている内容は?
Apache Flinkの分散スナップショットの方式についてです。
基となった情報はLightweight Asynchronous Snapshots for Distributed Dataflowsになります。
ただ、この論文の内容自体もある時点のスナップショットですので、
最新版ではこの事情が変わっていることも大いにあり得ますが、そこまでは確認できていませんのでご勘弁を。
読むのが面倒なのでまとめると?
-
入力に定期的にバリアマーカーを投入して、ストリームデータ処理をステージに区切るようにした。
-
各オペレータはバリアマーカーを受信したタイミングで該当入力チャネルからの受信をブロックし、全入力チャネルからバリアマーカーを受信したタイミングで状態を保存する。
-
上記の方式により、オペレータの状態のみの保存でストリームデータ処理のトポロジ全体のスナップショットを取得できる。
-
循環サイクルが存在する場合、循環でない全入力チャネルからバリアマーカーを受信したタイミングで循環サイクルの出力チャネルにバリアマーカーを送信し、循環サイクルの入力にバリアマーカーが入ってくるまでに受信したレコードもスナップショットに含めることで対応している。
Lightweight Asynchronous Snapshots for Distributed Dataflows
概要
分散ステートフルストリーム処理により、低レイテンシと高スループットの両方をターゲットとした大規模な連続計算を実行できます。
これを実現するための基本的な課題の1つは、潜在的な障害のもとで処理保証を提供することです。
既存のアプローチは、障害回復に使用できる定期的なグローバル状態スナップショットに依存しています。
これらのアプローチには2つの主な欠点があります。
- 全体の計算を停止させることが多い。
- 必要以上に大きなスナップショットが必要となる。
- 動作状態とともに、通信中のすべての状態を保持してしまう。
本論文ではこれらへの対処として、最新のデータフロー実行エンジンに適した軽量アルゴリズムである非同期バリアスナップショット(ABS)を提案します。
ABSは非循環グラフのデータフローではオペレータ状態のみを保持し、循環グラフのデータフローでは最小限の記録ログを維持します。
分散ステートフルストリーム処理をサポートする分散分析エンジンApache FlinkにABSを実装しました。
評価の結果、ABSは実行に大きな影響を与えず、リニアなスケーラビリティを維持し、頻繁なスナップショットでうまくいくことを示しています。
1. 導入
分散ステートフルストリーム処理は、コンピューティングの新たなパラダイムであり、低レイテンシと高スループットの両方をターゲットとした大規模な連続計算を実行できます。
このようなシステムでは、耐障害性は非常に重要です。
ステートフルな処理システム上で正確に一度のセマンティクスを保証する現在知られているアプローチは、実行状態の全体的で一貫したスナップショットに依存しています。
しかし、そのアプリケーションをリアルタイムストリーム処理で取得するあたっては主な欠点が2つある。
- 同期スナップショット技法は、全体的な状態の一貫したビューを得るために分散計算の全体的な実行を停止する。
- 分散スナップショットの既存のアルゴリズムはスナップショット状態の一部として、実行グラフ全体でチャネルまたは未処理メッセージで転送中のレコードを含む。
- ほとんどの場合、これには必要以上の状態が含まれる。
本論文の提案アルゴリズムでは、分散型のステートフルなデータフローシステムを対象とした軽量なスナップショットを提供することに重点を置き、パフォーマンスへの影響は既存方式と比べて軽微なものとなります。
提案アルゴリズムにおいては、非循環グラフのオペレータ状態のみを含む低コストの非同期状態スナップショットを提供します。
さらに、スナップショットの状態を最小限に保ちながら、トポロジの選択された部分にダウンストリームバックアップを適用することによって、循環グラフのケースをカバーします。
私たちの技術はストリーミング操作を停止させず、ランタイムオーバーヘッドがわずかにしか発生しません。
本論文の貢献は以下のように要約されます。
- 非循環グラフ上で最小限のスナップショットを実現する非同期スナップショットアルゴリズムを提案して実装する。
- 我々は、循環グラフ上で動作するアルゴリズムの一般化を記述し実装する。
- Apache Flink Streamingを比較のベースシステムとして使用している最先端技術と比較して、我々のアプローチの利点を示す。
2. 関連研究
過去10年間、連続処理を行うシステムではいくつかの回復メカニズムが提案されています。
Discretized StreamsやCometなどのステートレス分散バッチ計算に継続的な処理をエミュレートするシステムは、状態の再計算に依存しています。
一方、Naiad、SDGs、Piccolo、SEEPなどのステートフルなデータフローシステムは、チェックポイントを使用して障害回復のためのグローバル実行の同期スナップショットを取得します。
Chandy and Lamportによって導入された、分散環境における一貫性のあるグローバルスナップショットの問題は、過去数十年にわたって広く研究されています。
グローバルスナップショットは、理論的には、実行の全体的な状態、またはその操作の特定のインスタンスでの可能な状態を反映します。
Naiadが採用しているシンプルでコストのかかる方法は、3つのステップで同期スナップショットを実行することです。
- 実行グラフの全体的な計算を停止
- スナップショットを実行
- 最後にグローバルスナップショットが完了したら各タスクに操作を続行するよう指示
このアプローチは、計算全体をブロックする必要があり、スループットとスペースの両方に大きな影響を与えます。
もともとChandyとLamportによって提案された、今日の多くのシステムに導入されているもう1つの一般的なアプローチは、上流のバックアップを熱心に実行しながらスナップショットを非同期に実行することです。
これは、オペレータおよびチャネル状態の持続性をトリガするマーカーを実行グラフ全体に分散することによって達成されます。
しかし、このアプローチでは、上流のバックアップが必要であり、結果としてバックアップ・レコードの再処理によって回復時間が長くなるため、スペースに対する課題が依然としてあります。
私たちのアプローチはChandyとLamportの元の非同期スナップショットの考え方を拡張していますが、非循環グラフのレコードのバックアップログも考慮しませんし、循環グラフであっても必要最低限のバックアップログしか取得しません。
3. 背景:Apahce Flink
私たちは現在、Apache Flink Stack(旧Stratosphere)の一部である分散ストリーム分析システムであるApache Flink Streamingの耐障害性確保のために本アルゴリズムを提案しています。
Apache Flinkは、ステートフルな相互接続されたタスクで構成されるバッチ・ジョブとストリーミング・ジョブの両方を一様に処理する汎用ランタイム・エンジンを中心に構成されています。
Flinkのアナリティクスジョブは、タスクの有向グラフにまとめられています。
データ要素は外部ソースから取得され、パイプライン方式でタスクグラフにルーティングされます。
タスクは、受信した入力に基づいて内部状態を継続的に操作し、新しい出力を生成しています。
3.1 ストリーミングプログラミングモデル
ストリーム処理用のApache Flink APIは、無限に分割されたデータストリーム(部分的に順序付けられた一連のレコード)を、データストリームと呼ばれるコアデータ抽象化として公開することにより、複雑なストリーミング分析ジョブの構成を可能にします。
DataStreamsは、外部ソース(例えば、メッセージキュー、ソケットストリーム、カスタムジェネレータ)から、または他のデータストリーム上でオペレーションを呼び出すことによって作成することができる。
DataStreamsは、レコードごとに増分適用され、新しいDataStreamを生成する上位関数の形式でmap、filter、およびreduceなどの複数の演算子をサポートします。
すべての演算子は、パラレル・インスタンスをそれぞれのストリームの異なるパーティションで実行することによって並列化することができ、ストリーム変換の分散実行を可能にします。
コード例を下記に示します。
val env : StreamExecutionEnvironment = ...
env.setParallelism(2)
val wordStream = env.readTextFile(path)
val countStream = wordStream.groupBy(_).count
countStream.print
上記コードはApache Flinkで簡単なインクリメンタル・ワード・カウントを実装する方法を示しています。
このプログラムでは、単語がテキストファイルから読み込まれ、各単語の現在のカウントが標準出力に出力されます。
これはステートフルなストリーミングプログラムであり、ソースは現在のファイルオフセットを認識する必要があり、カウンターは各単語の現在のカウントを内部状態として維持する必要があります。
3.2 分散データフロー実行
頂点$T$がタスクを表し、エッジ$E$がタスク間のデータチャネルを表すとします。
ユーザがアプリケーションを実行すると、すべてのオペレータが原則として有向グラフ$G=(T, E)$である実行グラフにコンパイルされます。
インクリメンタルワードカウントの例については、下記のような実行グラフとなります。
上記のように、オペレータのすべてのインスタンスは、それぞれのタスクにカプセル化されています。
タスクは、システム外部からデータを取得する場合、ソースとして分類できます。
さらに、Mは、並列実行中にタスクによって転送されたすべてのレコードのセットを示します。
各タスクt∈Tは、オペレータインスタンスの独立した実行をカプセル化し、以下のもので構成されます。
- 入力チャネルと出力チャネルのセット:$It、Ot⊆E$
- オペレータ状態:$st$
- ユーザー定義関数:$ft$
データの取り込みPull型です。
実行中、各タスクは入力レコードを消費し、オペレータ状態を更新し、そのユーザ定義関数に従って新しいレコードを生成する。
より具体的には、タスク$t∈T$によって受信された各レコード$r∈M$に対して、新しい状態$st'$と出力レコード集合$D⊆M$が下記のように生成されます。
ft:st、r |→ <st'、D>
4. 非同期バリアスナップショット
分散処理システムは、障害に対して復旧する機構が必要です。
この復旧機構を提供する方法は、実行グラフのスナップショットを定期的に取得し、後で障害から回復するために使用するという流れになります。
スナップショットは、実行グラフのグローバルな状態であり、その特定の実行状態から計算を再開するために必要なすべての情報を保存しています。
4.1 問題定義
実行グラフ$G=(T, E)$のグローバルスナップショット$G*=(T*, E*)$をすべてのタスク状態$T*$とエッジ状態$E*$との集合として定義します。
より詳細には、$T*$はすべてのオペレータの状態$st∈T : ∀t∈T$から構成されます。
同様に、$E*$はすべてのチャネル状態$e∈E$の集合となります。
ここで、$e$は$e$上の転送中のレコードから構成されます。
Telで説明されているように、終了性や実行可能性、および回復後に正しい結果を保証するために、スナップショット$G*$ごとに必要な情報が保持されている必要があります。
終了性は、すべてのプロセスが生存している場合、スナップショットアルゴリズムが開始後一定の時間内に最終的に終了することを保証します。
実現可能性は、スナップショットの有意性を表します。すなわち、スナップショット処理中に、計算に関して情報が失われていないことを示します。
実際には、タスクで配信されるレコードもスナップショットの観点から取得されるように、因果関係がスナップショットに維持されることを意味します。
4.2 非循環グラフデータフローでの対応
非循環グラフデータフローにおいては、実行をステージごとに分割することで、チャネル状態を取得することなくスナップショットを取得することが可能です。
ステージは、注入されたデータストリームおよびすべての関連する計算を、すべての以前の入力および生成された出力が完全に処理された一連の可能な実行に分割します。
ステージの最後にあるオペレータ状態のセットは、実行履歴全体を反映しているため、スナップショットにのみ使用できます。
私たちのアルゴリズムの背後にあるコアアイデアは、連続したデータ取り込みを維持しながら、段階的なスナップショットを使用して同一のスナップショットを作成することです。
本論文のアルゴリズムでは、入力データストリームに周期的に注入される特別なバリアマーカーによって、連続的なデータフロー実行でステージ分割がエミュレートされ、実行グラフ全体を通してシンクまで送信されます。
スナップショットは、各タスクが実行ステージを示すバリアマーカーを受け取るたびに段階的に構築されます。
さらに、アルゴリズムについて以下の仮定を行います。
- ある特定のタスク間を接続するネットワークチャネルは信頼性が高く、FIFO配信順序を尊重し、ブロックおよびブロック解除することが可能。
- チャネルがブロックされると、すべてのメッセージはバッファされるが、ブロックが解除されるまで配信されない。
- タスクは、ブロック、ブロック解除、メッセージ送信などのチャネルの操作を実行可能。
- 下流全てに対してバリアマーカーを送信するようなブロードキャスト的な使用も可能。
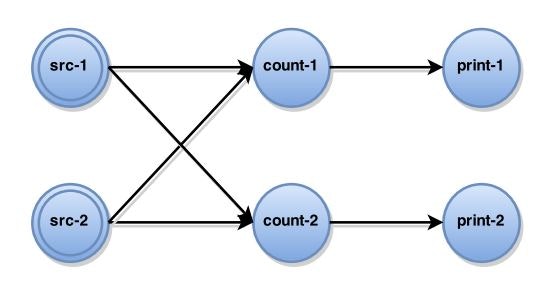
ABSアルゴリズムは、下記の図のように実行されます。
中央コーディネーターは、定期的にすべてのソースタスクにバリアマーカーを送信します。
ソースがバリアマーカーを受信すると、現在の状態のスナップショットを取得し、バリアマーカーをすべての出力にブロードキャストします。:$a)$
非ソースタスクがその入力の1つからバリアマーカーを受信すると、該当タスクはすべての入力からバリアマーカーを受信するまで該当の入力をブロックします。:$b)$
バリアマーカーをすべての入力から受信すると、タスクは現在の状態のスナップショットを取り、バリアマーカーをすべての出力にブロードキャストします。:$c)$
その後、タスクは入力のブロックを解除して計算を続行します。:$d)$
完全なグローバルスナップショット$G*=(T*, E*)$は、$E*=0$であるすべての演算子状態$T*$のみから構成されます。
証明:
前述のように、スナップショットアルゴリズムは終了性と実現可能性を保証する必要があります。
終了性は、チャネルおよび非循環グラフの性質によって保証されます。
チャネルの信頼性は、タスクが生存している限り、送信されるすべてのバリアマーカーが最終的に受信されることを保証します。
さらに、ソースからのパスが常に存在するため、非循環グラフ内のすべてのタスクは、最終的にすべての入力からバリアマーカーを受け取り、スナップショットを取得します。
実現可能性については、グローバルスナップショットのオペレータ状態が最後の段階まで処理されたレコードの履歴のみを反映することを示すことで十分である。
これは、チャネルのFIFO順序付けプロパティと、ステージの後のショットなしレコード(障壁に続くレコード)がスナップショットが取られる前に処理されることによって保証されます
4.3 循環グラフデータフローでの対応
実行グラフ中に循環サイクルが存在する場合、前節で提示されたABSアルゴリズムは、循環サイクル内のタスクがすべての入力からの障壁を受けるために無期限に待機するので、デッドロックに終わることはありません、
また、循環サイクル内で任意に転送中のレコードはスナップショットに含まれないため、実現可能性には影響しません。
したがって、スナップショットに1循環サイクル内に生成されたレコードを含めることで、実現可能性を確保し、回復時にこれらのレコードを循環サイクル中に転送中状態で復元する必要があります。
循環グラフを扱う場合、下記のアルゴリズムに見られるように、追加のブロッキングを引き起こさずに基本アルゴリズムを拡張します。
まず、実行グラフのループ上のバックエッジ$L$を静的解析で特定する。
制御フローグラフ理論から、有向グラフの後退エッジは、深さ優先探索の間に既に訪れたタスクに到着するエッジである。
実行グラフ$G(T, E / L)$は、循環グラフ内のすべてのタスクを含むDAGです。
このDAGの観点から、アルゴリズムは以前と同じように動作しますが、スナップショットの期間中に後退エッジから受信したレコードのダウンストリームバックアップも追加で取得します。
これは、ストリームの消費者である各タスク$t$で実行される。$Lt⊆It$となる。
各タスク、バリアマーカーを転送する瞬間から$Lt$から受け取ったすべてのレコードのバックアップ・ログを作成する。
バリアマーカーは、ループ内の転送中のすべてのレコードをダウンストリームログに取得するので、一貫性のあるスナップショットに一度だけ含まれます。
この循環サイクル対応版アルゴリズムをABSアルゴリズム2と呼びます。
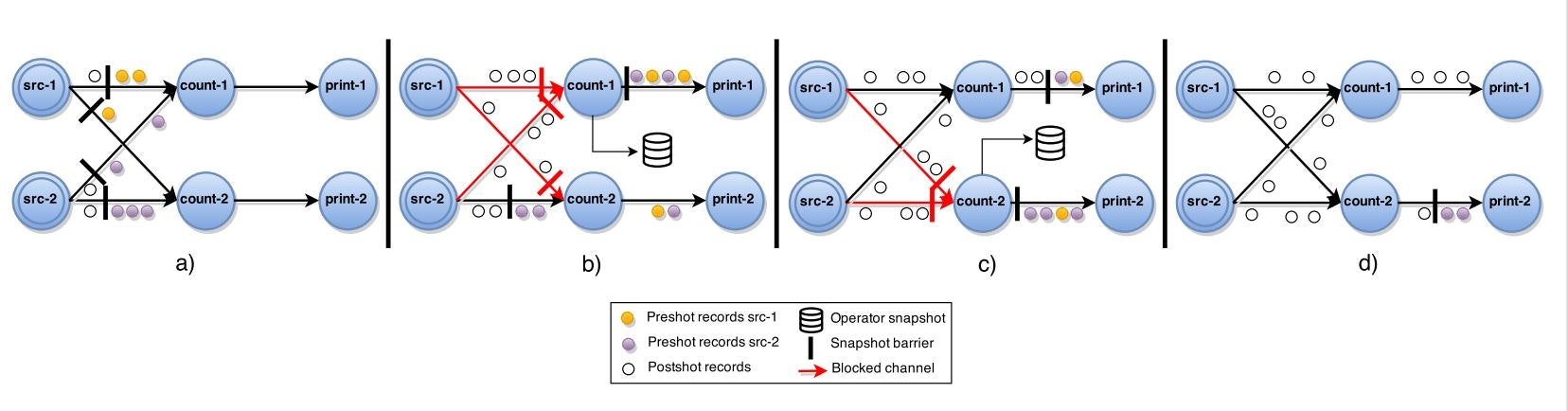
ABSアルゴリズム2は、下記の図のように実行されます。
後退エッジ入力を持つタスクは、自身の後退エッジでないチャネルからバリアマーカーを受信すると、状態のローカルコピーを作成します。:$b)$
さらに、この時点から、彼らは彼らの後退エッジから受信したすべてのレコードを記録します。
その後、後退エッジからバリアマーカーを受信した段階で、その時点までに受信したレコードをスナップショットとして取得します。:$c)$
最終的なグローバルスナップショット$G*=(T*, E / L*)$には、すべてのタスク状態$T*$と、後退エッジを転送中のレコード$L⊂E$のみが含まれることとなる。
証明:
このバージョンのアルゴリズムでも終了性と実現可能性が保証されていることを証明する。
すべてのタスクは、最終的にすべての入力(後退エッジチャネルを含む)からバリアマーカーを受け取り、スナップショットを完成させるため、終了性は4.2と同様に保証されます。
バリアマーカーをすべての通常の入力から受信した段階で、すぐにバリアマーカーをブロードキャストすることで、同様にデッドロック状態を回避します。
チャネルのFIFO性質は依然として後退エッジに対しても有効となり、以下の性質より、実現可能性が証明されます。
- スナップショットに含まれる各タスク状態は、通常の入力で受け取ったバリアマーカーからの事後イベントを処理する前に取られたそれぞれのタスクの状態コピーとなる。
- スナップショットに含まれるダウンストリームログは完全であり、FIFO保証のために後退エッジで受信されたバリアマーカー受信前に受信した、すべての転送中のポストショットレコードを含む。
5. 障害復旧
障害回復の動作について、説明します。
整合性のあるスナップショットでには、動作するいくつかの障害回復方式があります。
最も単純な形式では、実行グラフ全体を最後のグローバルスナップショットから次のように再開することができます。
すべてのタスクtに対して下記を行う。
- スナップショットstの関連する状態を読込み、それを初期状態として設定
- 後退エッジ用バックアップアップログを読込み、すべてのレコードを処理
- 入力チャネルからのレコード取り込みを開始
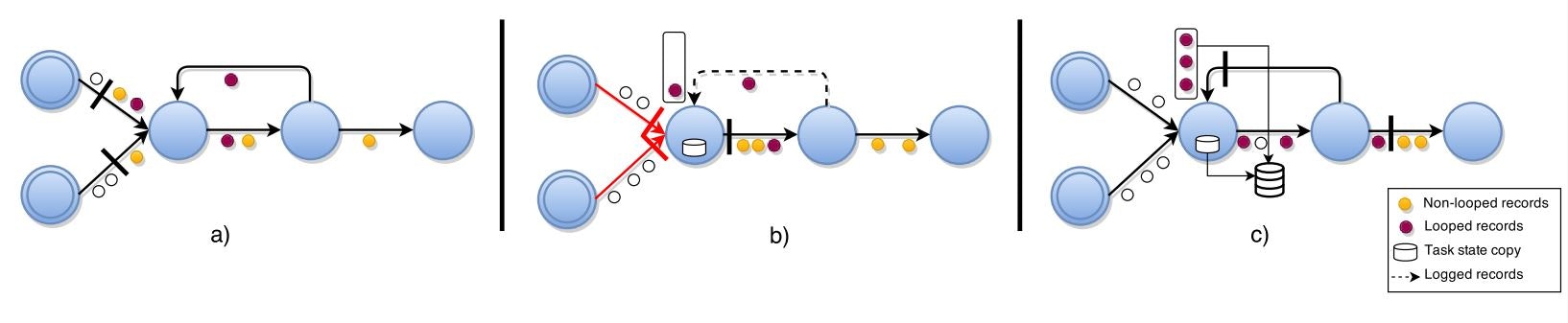
上流のタスク依存性(出力チャネルを失敗したタスクに保持するタスク)とそれぞれの上流のタスクをソースまで再スケジューリングすることで、TimeStreamと同様にグラフの一部の回復も可能です。
回復計画の例を下図に示します。
Exactly onceのメッセージ処理セマンティクスを提供するためには、再計算を避けるために、すべての下流タスクで重複レコードを無視する必要があります。
これを達成するために、我々はSDGsに類似した方式に従い、ソースからの特定シーケンス番号を持つレコードをマークすることができます。
したがって、各下流のタスクは、シーケンス番号が既に処理したものより少ないレコードを破棄できます。
6. 実装
我々は、ストリーミング実行時にExactly onceの処理セマンティクスを提供するために、Apache FlinkへのABSアルゴリズムの実装を行いました。
現在の実装では、ブロックされたチャネルはすべての受信レコードをメモリに保存するのではなく、ディスクに保存してスケーラビリティを向上させています。
この手法は堅牢性を保証しますが、ABSアルゴリズムの実行時の影響を増加させます。
オペレータの状態をデータと区別するために、オペレータの状態を更新および取得するためのメソッドを含む明示的なOperatorStateインターフェイスを導入しました。
加えて、オフセットベースのソースや集計用に、Apache Flinkでサポートされているステートオペレータ用のOperatorState実装を提供しました。
スナップショットコーディネータは、ジョブマネージャのアクタープロセスとして実装され、単一のジョブの実行グラフのグローバルな状態を維持します。
コーディネーターは、実行グラフのすべてのソースにバリアマーカーを定期的に投入します。
再起動時や再構成時、最後にスナップショットされた状態は、分散メモリ内永続ストレージからオペレータに復元されます。
7. 評価
評価の目的は、ABSとNaiadで採用されているグローバルに同期化されたスナップショットアルゴリズムのランタイムオーバーヘッドを比較し、さらに多数のノードに対するアルゴリズムのスケーラビリティを評価することです。
7.1 評価環境
評価に使用される実行トポロジは、下図の通りとなります。
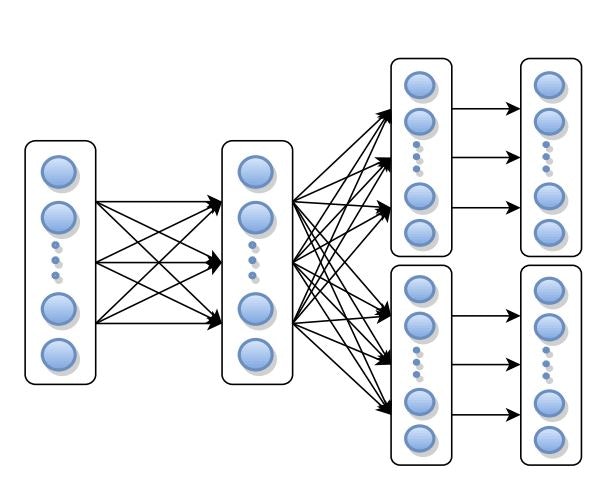
クラスタノードの数に等しい並列性を持つ6つの異なるオペレータで構成されています。
つまり、$6 * クラスタノード数 = Task数$となります。
この実行には、3つのフルネットワークシャッフルが含まれており、ABSでのチャネルブロックの影響を確認します。
ソースは、合計10億レコードを生成し、ソースインスタンス間で均一に分散されます。
トポロジ内のオペレータの状態は、キーごとの集約とソースオフセットでした。
評価は最大40のm3.mediumのインスタンスを使用してAmazon EC2クラスタ上で実行されました。
さまざまなスナップショット方式、つまりABSおよび同期スナップショットの実行中の評価ジョブのランタイムオーバーヘッドをさまざまなスナップショット間隔で測定しました。
我々は、比較のために、Apache Flinkの上でNaiadで使用されている同期スナップショット作成アルゴリズムを実装しました。
この実験は、10ノードクラスタを使用して実行されました。
アルゴリズムのスケーラビリティを評価するために、一定量の入力レコード(10億)を処理しながら、トポロジの並列性を5ノードから40ノードまで変化させました。
7.2 評価結果
下図では、2つのアルゴリズムのベースライン(耐障害性なし)に対する実行時の影響を示しています。
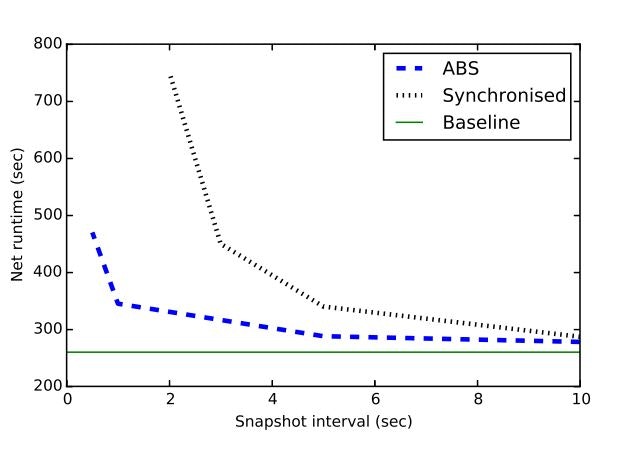
同期スナップショットの大きなパフォーマンスへの影響は、スナップショット間隔が小さい場合に特に顕著になります。
これは、グローバルスナップショットを取得するために、システムがデータを処理しない時間が多く発生するためです。
ABSは、全体的な実行をブロックすることなく、安定したスループットを維持しながら継続的に実行されるので、ランタイムに与える影響は小さいものとなります。
より大きいスナップショット間隔の場合、同期アルゴリズムの影響はあまり重要ではありません。
ただし、バースト発生時は同期スナップショット方式を用いた場合、侵入検知パイプラインのように、レイテンシが重要な多くのアプリケーションのリアルタイム保証という観点から、SLAに違反することがよくあります。
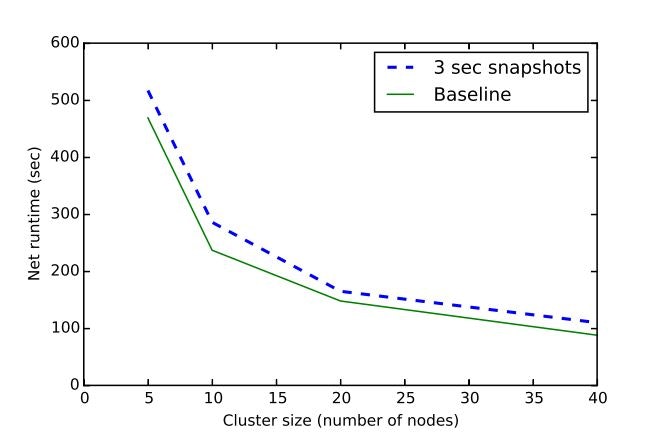
下図では、ABSを実行しているトポロジのスケーラビリティとベースラインに対する3秒のスナップショット間隔(耐障害性なし)を比較しています。
ベースラインとなるジョブとABSの両方が線形スケーラビリティを達成していることは明らかです。
8. 今後の展望
今後の研究では、スナップショットの状態と動作状態を切り離すことにより、ABSの影響をさらに低減する可能性を検討する予定です。
これにより、タスクはスナップショットを維持しながらレコードを連続的に処理できるので、純粋に非同期の状態管理が可能になります。
このような方式では、プレショットとポストショットのレコードをそれぞれの状態と同期させる必要があります。これらのレコードは、レコードが属するスナップショットに応じてレコードにマーキングすることで解決できます。
この手法は、アルゴリズムの計算、空間、およびネットワークのI/O要件を増加させるため、現在のABS実装とその性能を比較する予定です。
最後に、Exactly onceのセマンティクスを維持しながら、タスクごとの粒度で操作することで再構成の必要性を最小限に抑えるさまざまな回復手法を調査する予定です。
まとめ
以上のように読んでみました。
アルゴリズム自体はシンプルな構造になっているため、読みやすい内容ではありました。
こういう方式での状態保持についてはFlinkだけでなく、他のストリームデータ処理基盤でも似たものが見られるため、参考になりそうです。