はじめに
Groongaは、トークナイザー、ノーマライザー、トークンフィルター、コマンド、関数をC言語かC++の共有ライブラリ形式のプラグインで拡張させることができます。
当方が自作したトークナイザーをいくつか紹介します。
TokenBigram
GroongaのデフォルトのTokenBigramトークナイザーでは、所定のユニットサイズで、1文字ずつずらしてトークナイズされます。
> tokenize TokenBigram "今日は雨だ" NormalizerAuto
[[0,1418629522.17365,0.00184750556945801],[{"value":"今日","position":0},{"value":"日は","position":1},{"value":"は雨","position":2},{"value":"雨だ","position":3},{"value":"だ","position":4}]]
これにより、漏れのない検索が可能となります。ただし、検索ノイズが含まれ得るという弱点があります(たとえば、東京都に京都でヒットする等)。要件にもよりますが、日本語の場合は、検索ノイズはさほど大きい問題ではないかもしれません。
トークナイズモード
Groongaでは、ドキュメントの更新時と検索時でトークナイズ方式を変更することができます。
デフォルトのTokenBigramでも実はドキュメントの更新時と検索時では少しだけトークナイズ方式が異なっています。
tokenizeコマンドでトークナイズモードを切り替える場合は、--modeオプションを使います。
> tokenize TokenBigram "今日は雨だ" NormalizerAuto --mode ADD
[[0,1418629767.53499,0.00154948234558105],[{"value":"今日","position":0},{"value":"日は","position":1},{"value":"は雨","position":2},{"value":"雨だ","position":3},{"value":"だ","position":4}]]
tokenize TokenBigram "今日は雨だ" NormalizerAuto --mode GET
[[0,1418629770.14026,0.00182175636291504],[{"value":"今日","position":0},{"value":"日は","position":1},{"value":"は雨","position":2},{"value":"雨だ","position":3}]]
--mode GETの場合は、{"value":"だ","position":4}がありませんね。
これは、末尾の1文字のものは、2文字以上で検索するときは不要だからです。
Groongaでは、だ1文字で検索したいときのために、ドキュメント更新時は、末尾の1文字もトークナイズされます。
この他、Groongaでは、アルファベット、記号、数字はグループしてトークナイズしたり、デフォルトでできるだけいい感じにトークナイズされるようになっています。
TokenYaBigram
上述のTokenBigramでは、--mode GETの場合に、だのみが省略されましたが、実はもっと省略することができます。
文字Ngramで1文字ごとずらしているのは、日本語は単語境界が判らないため、検索漏れがないように網羅的に全ての文字位置のトークンを作成する必要があるためです。
検索時は、検索対象の先頭が決まっているので、1文字ずつずらす必要はありません。すくなくともトークンの組み合わせによって、全ての文字がカバーしていれば、正しく検索にヒットさせることができます。
これを実現させたのが自作のTokenYaBigramです。
> register tokenizers/yangram
> tokenize TokenYaBigram "今日は雨だ" NormalizerAuto --mode GET
[[0,1418630457.32841,0.00173497200012207],[{"value":"今日","position":0},{"value":"は雨","position":2},{"value":"雨だ","position":3}]]
TokenBigramに比べ、{"value":"日は","position":1}が省略されています。これにより、1つのトークンのマッチング処理が不要となるため、検索速度の向上が見込めます。
この他、TokenYaBigramSplitSymbolAlphaやTokenYaTrigram等も用意しています。
以下のように、検索速度が向上できていることがわかります。
| TokenYaBigram | TokenBigram | |
|---|---|---|
| Hits | 112378 | 112378 |
| Searching time (Avg) | 0.0325 sec | 0.0508 sec |
| Offline Indexing time | 1224 sec | 1200 sec |
| Index size | 7.898GiB | 7.580GiB |
| TokenYaTrigram | TokenTrigram | |
|---|---|---|
| Hits | 112378 | 112378 |
| Searching time (Avg) | 0.0063 sec | 0.0146 sec |
| Offline Indexing time | 2293 sec | 2333 sec |
| Index size | 9.275GiB | 9.009GiB |
NgramのNのサイズが大きいほど省略できるトークンが増えるため、TokenYaTrigramは、より高速になります。
TokenYaVgram
上記の表のように、通常、TokenBigramよりもTokenTrigramの方が検索速度が速いです。
これは、トークンの文字数が増えることにより文字の組み合わせ数が増えて、トークンの種類が増え、トークンのポスティングリストが短くなり、ポスティングの比較回数が減るためです。
日本語は、アルファベットに比べて文字ごとの字種が多いため、それの3つの組み合わせとなるとかなりの組み合わせ数になります。
しかしながら、TokenTrigramにはデメリットもあります。組み合わせ数が増えるため、語彙表のキー数が爆発的に増えて、メモリ使用量が増えます。
以下のグラフに示すようにトークンの出現頻度は極端に偏ります。出現頻度が高くないものについては、比較回数も少なく、全文検索の速度は十分に高速です。
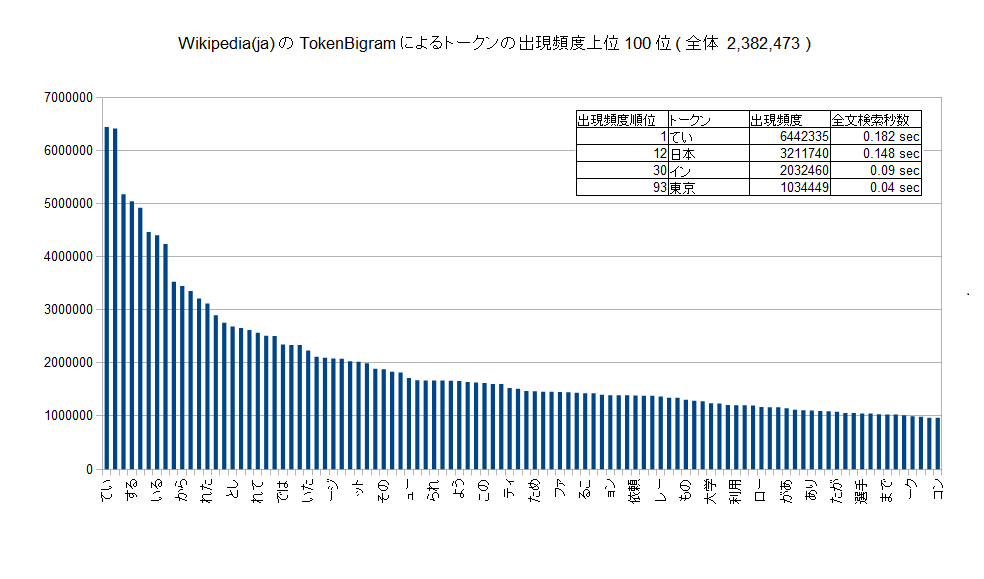
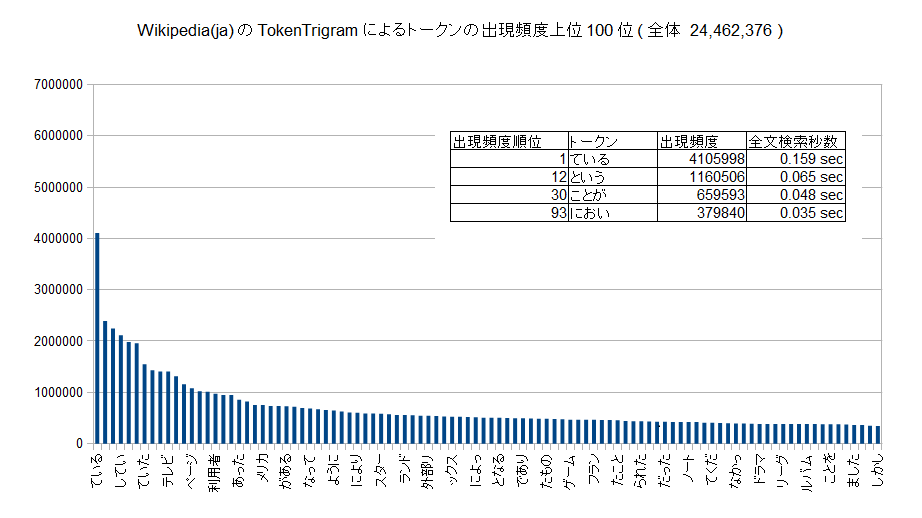
そこで、出現頻度が高いものを選択的にTrigramにするようにしたものがTokenYaVgramです。Trigramにする対象は事前にセットアップする必要があります。
> register tokenizers/yangram
[[0,1418631797.40811,0.000716209411621094],true]
> table_create vgram_words TABLE_HASH_KEY ShortText
[[0,1418631666.02319,0.0463216304779053],true]
> load --table vgram_words
> [
> {"_key": "今日"}
> ]
[[0,1418631682.25616,16.9251108169556],1]
> tokenize TokenYaVgram "今日は雨だ" NormalizerAuto
[[0,1418631727.00807,0.00183010101318359],[{"value":"今日は","position":0},{"value":"日は","position":1},{"value":"は雨","position":2},{"value":"雨だ","position":3},{"value":"だ","position":4}]]
vgram_wordsというテーブルに対象のトークンを登録がする必要があるため、少し面倒ですが、検索対象の分野がある程度が絞られれば、使い回せるんじゃないかなぁと思っています。
Bigramトークンの出現頻度のカウントは、TokenBigramでインデックスを作ってから以下のコマンドプラグインを使うと比較的簡単に計算することができます。
Rroongaを使ったスクリプトでも若干計算速度が落ちますが同様の計算を行うことができます。
TokenYaVgramBothは、1つ手前のトークンもTrigramにするようにしたものです。Trigramにしたい対象が検索クエリ末尾に来やすい場合は、こちらを使わないと効果があまりでないかもしれません。
| TokenYaVgramBoth | TokenYaVgram | TokenTrigram | TokenBigram | |
|---|---|---|---|---|
| Hits | 112378 | 112378 | 112378 | 112378 |
| Searching time (Avg) | 0.0065 sec | 0.0166 sec | 0.0126 sec | 0.0444 sec |
| Offline Indexing time | 1818 sec | 1592 sec | 2150 sec | 1449 sec |
| Index size | 8.566GiB | 8.474GiB | 9.009GiB | 7.580GiB |
| Key sum | 8560779 | 7425198 | 28691883 | 5767474 |
| Key size | 200.047MiB | 172.047MiB | 684.047MiB | 136.047MiB |
上記のようにキーサイズの増大を抑えつつ、検索速度が向上できています。
フレーズ抽出
TokenYaBigram、TokenYaVgram等には、フレーズ抽出の機能もあります。これを使えば、既知のフレーズは、Ngramではなくひとまとまりでトークナイズされます。見出しタグや検索ノイズ低減、特定フレーズの高速化に利用することができます。
> table_create known_phrases TABLE_PAT_KEY ShortText --normalizer NormalizerAuto
[[0,1418635066.4222,0.0266995429992676],true]
> load --table known_phrases
> [
> {"_key": "今日は雨"}
> ]
[[0,1418635082.8542,22.6170270442963],1]
> tokenize TokenYaBigram "今日は雨だ" NormalizerAuto
[[0,1418635118.32713,0.00166845321655273],[{"value":"今日は雨","position":0},{"value":"だ","position":1}]]
TokenYaDelimit*
TokenDelimitでは空白区切りでトークナイズされますが、その他にセミコロン;やコロン:などの区切り文字でトークナイズするものを作りました。
私は英語のタグとかで使っています。
> register tokenizers/yadelimit
> tokenize TokenYaDelimitSemicolon "a;b"
[[0,1418631559.25254,0.00179910659790039],[{"value":"a","position":0},{"value":"b","position":1}]]
TokenTinySegmenter
TinySegmenterを使ったトークナイザーです。
機械学習のみを使って分かち書きをするため、辞書が不要でコンパクトなのが特徴です。
が、まあ、全文検索する時点でそこまでサイズにシビアになる環境はあまりなさそうで使いどころは少なそうです。
> register tokenizers/tinysegmenter
[[0,1418632047.50614,0.01009202003479],true]
> tokenize TokenTinySegmenter "今日は雨だ"
[[0,1418632062.93017,0.00131678581237793],[{"value":"今日","position":0},{"value":"は","position":1},{"value":"雨","position":2},{"value":"だ","position":3}]]
その他
この他、MeCabトークナイザーをいじって、未知語とか品詞情報を使って何かしようと思ったのですが、現状放置しています。
また、Luceneのトークナイザーでは正規表現パターンに一致するものだけ抽出みたいなのもあった気がしますが、欲しければそういったものも作れると思います(速さはしりませんが)。
以下にGroongaサンプルトークナイザーのカスタマイズの記事があります。
興味がある方は、参考に自作してみるといかがでしょうか。
参考資料
以下に全文検索エンジンGroongaを囲む夕べ5で当方が発表したスライドがあります(誤字が結構ありますが)。