こんにちは。「学びの探究者」です。普段はnoteで活動しています。
2025年のQiitaアドベントカレンダーでは、
「ノーコード/ローコードで、自分のコンテンツ基盤を自動化していく」
をテーマに、25日間の仕組みづくりを記録していきます。
ぜひ、応援してください。
昨日までで、
- Firecrawl でサイトをスクレイピングして
- LLM でメタ情報を「いい感じのJSON」に整形して
- Google スプレッドシートに保存する
というところまでの“部品”は揃いました。
Day5 では、いよいよ 実在のAIサービス2つを流して「比較できるデータ」にしてみる ところまでやってみます。
- 比較対象1:Dify(https://dify.ai/jp)
- 比較対象2:satto(https://satto.me/)
1. 今日のゴール
Day5 のゴールはシンプルです。
「AIサービス2つの LP をスクレイピング → LLM で構造化 → スプシに1行として保存」
というところまでをワークフローで自動化する
ここまでできてしまえば、
あとは URL を増やすだけで比較データベースが増えていく状態 になります。
2. ワークフロー全体像
今回のワークフローは、ざっくりこんな流れです。
- 開始ノード:手動で URL を入力
- Firecrawl ノード:指定URLをクロールして Markdown+メタ情報を取得
- LLM ノード:Markdown から meta / h1 / セクション情報などを抽出して JSON 生成
- Google Sheets ノード:JSON を1行としてスプレッドシートに追加
※2つのURL(Dify / satto)分、同じフローを2回流しています。
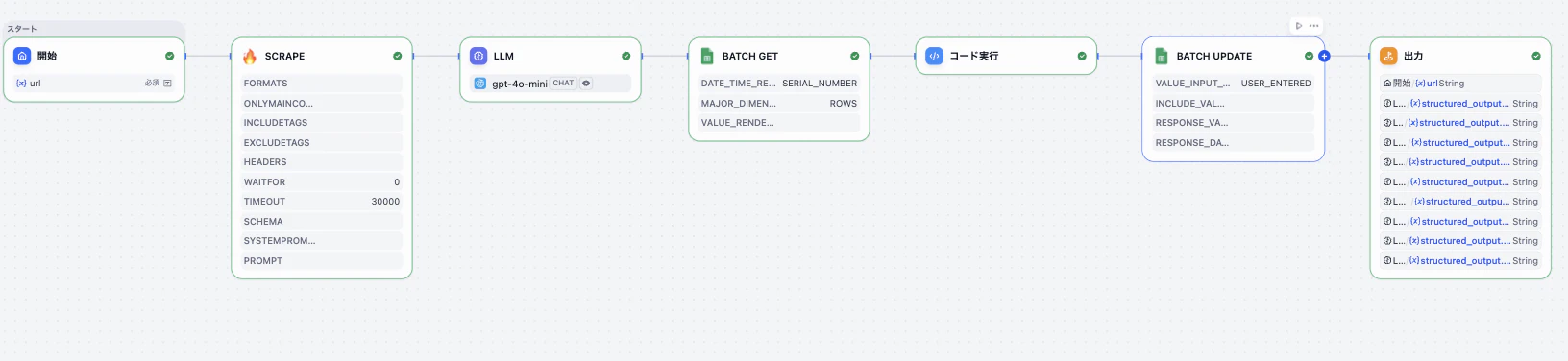
3. 開始ノード→Scrape(Firecrawl)ノードでページ内容を取得
まずは開始ノードで、URLを入力するように設定します。
次に、Scrape(Firecrawl)ノードで、対象サイトの情報を取ります。
-
入力フィールド:
-
url:ワークフローの入力(例:https://dify.ai/jp)
-
Firecrawl 側の設定はシンプルで、基本的には URLを渡すだけ です。
(オプションをいじりたくなりますが、Day5 時点ではデフォルトのままでOKにしました)

4. LLM ノードで整形する
次に、Scrape(Firecrawl)テキストを LLM に渡して、解析してもらいます。
LLMノードの作り方は、Day3を参考にしてみてください。
5. スプシの更新
スプシの更新は
1. Batch Get(スプシ全行を取得)
2. Code(次の空き行 or 更新行のインデックスを判定)
3. Batch Update(該当行にデータを書き込む)
となりますが、こちらの設定もDay2を参考にしてみてください。
シートの範囲が例えば、DayはA:Dですが、今回はA:JになっているところをJに変更するだけです。

これで完成です。
6. 次回(Day6)
Day6 では、ここを一歩進めて、
URL一覧をループで回して “大量に” データを貯めるワークフロー を作っていく予定です。