現象
運用中のRDSで、以下の減少が発生しました。
- 特定の重いクエリ(集計やソート)がタイムアウトで失敗する。
- 以前から実行時間が異常に長く、不安定だった。
原因調査:CloudWatchで確認
CloudWatchメトリクスを確認したところ、クエリ実行時間付近に以下の挙動が発生していました。
SwapUsageが高いFreeableMemoryが枯渇
メモリが足りず、低速な**スワップ領域(ディスク)**が使われていたため、処理がタイムアウトしていました。
解決策:work_mem の調整
メモリが足りないということでメモリを増やせば解決するのでは、と仮定づけて調査開始。
「work_mem を増やすと改善する」という情報を発見し、パラメーターグループを変更しました。
1 該当パラメータグループを選択し、編集を押下

2 work_mem部分を変更して反映させる
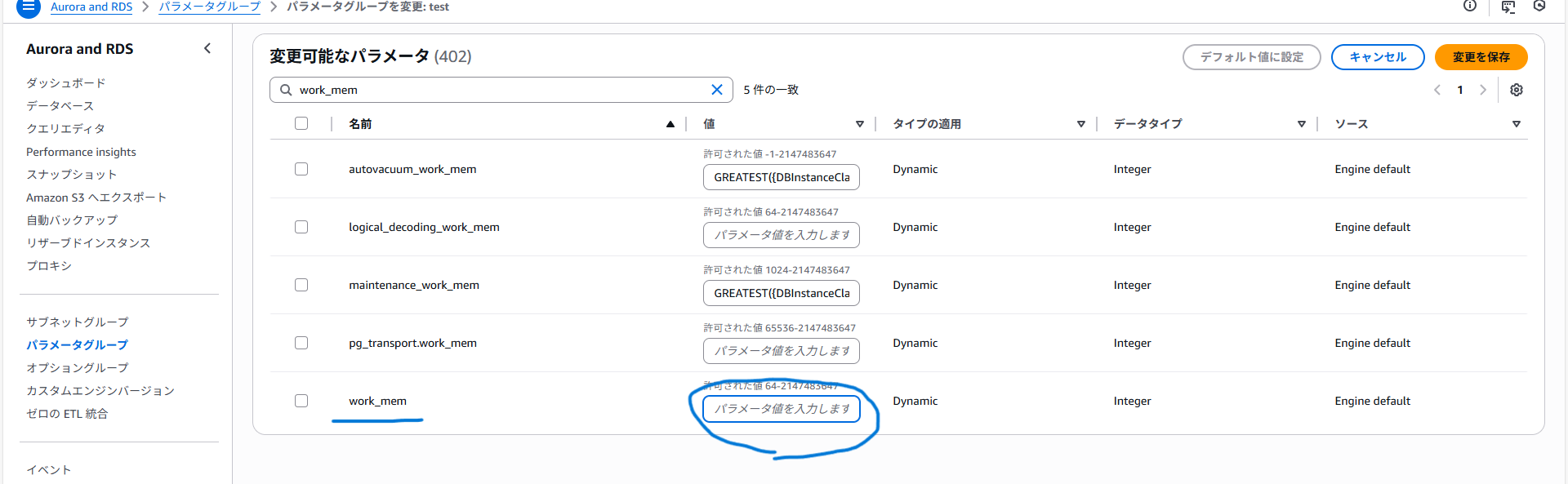
尚、デフォルトパラメータグループは変更できないためカスタムパラメータグループの必要があります。
-
変更内容:
work_memを 4MB(デフォルト)から 64MB に増量 -
理由:
work_memはソートやジョインに使う作業メモリ。これが足りないとディスク(一時ファイル)への書き出しが発生し、スワップを誘発するため。
イメージ図:work_memと処理の流れ
【改善前:work_memが少ない】
メモリに収まりきらないデータが溢れ、ディスクI/Oが発生。結果として激しく低速化し、タイムアウトへ。

【改善後:work_memを増やした】
すべての処理が高速なメモリ内で完結。

結果
- SwapUsage: 低い値で安定。
- 処理時間: タイムアウトしていたクエリが、詰まることなく正常に完了。
まとめ
RDSのタイムアウト調査では、CPU使用率だけでなく SwapUsage も確認する。
対策として、他のデータベースもcloudwatchで該当部分の監視をして、事前に把握しておく。