最初に
UiPathにあるOCR - 中国語、日本語、韓国語という
アクティビティ(以下、CjkOCRと呼ぶ)で
エラーが出て使えなかったので
Googleが提供しているCloud Vision OCRを使用してRPAを作ってみた話。
参考にした記事は以下。
断念したが一応参考にしたUiPathのOCR関連の記事
他にも参考にした記事
ざっくり動作の流れ・設計
- 1.フォルダを選択
- 2.フォルダ内のPDFを1つずつ処理
- 2-1.画像へ変換
- 2-2.Cloud Vision OCRで画像からテキストを抽出
- 2-3.テキストから会社名、合計金額、請求書のNoを抽出
- 2-4. 2-3で抽出した情報をデータテーブルへ格納
- 3.出力先のExcelを選択し、データテーブルをシートへ書き込む
0.請求書の準備
実際の請求書とは勝手が違うかもしれないが、
RPAで使用する請求書は以下のサイトで作成。
RPAでは異なるフォーマットの請求書から
それぞれテキストを抽出できるよう作るため、
いくつか請求書を作成。
2.フォルダ内のPDFを1つずつ処理
以下のアクティビティを使用。
気づいたら便利そうなアクティビティがあったので
- 繰り返し(フォルダ内の各ファイル)
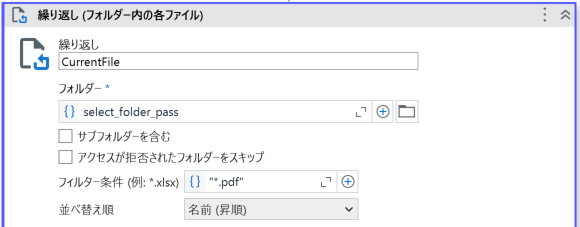
フォルダに格納されている請求書のみを
繰り返し処理したいので
フィルター条件は請求書の拡張子(.pdf)を設定する。
繰り返しの対象となる各ファイルはCurrentFileに格納されている。
2-1.画像へ変換
以下のアクティビティを使用。
- PDFページを画像としてエクスポート

繰り返しの対象となるファイルはCurrentFileに格納されているため、
ファイル名はCurrentFile.FullNameを入力する。
これでCurrentFileを画像としてエクスポートすることができる。
今回は変数image_file_passには
CurrentFile.FullName.Replace(".pdf", "_" + mk_datetime + ".png")
という値が入っている為、
PDFと同じフォルダにPNGで画像がエクスポートされる。
mk_datetimeも変数でDateTime.Now.ToString("yyyyMMddhhmm")
という値が入っていたりする、画像名が重複しないように。
2-2.Cloud Vision OCRで画像からテキストを抽出
以下のアクティビティを使用。
- 画像を読み込み
- Google Cloud Vision OCR

OCRで処理する画像はImage変数に格納されている必要があるため、
まずはimage_file_passの画像を読み込み、
Image型の変数(今回はinput_img)へ出力する。
次にGoogle Cloud Vision OCRのプロパティは以下内容で設定する。
| 項目 | 値 |
|---|---|
| リージョン | US(GoogleCloudRegion.US) |
| 検出モード | TextDetection |
| APIキー | Google Cloudで発行したAPIキー |
| 画像 | input_img |
| テキスト |
ocr_text_detection |
OCRで抽出したテキストは変数ocr_text_detectionへ格納するように設定している。
Google Cloud APIキー発行方法&Cloud Vision APIの有効化
とりあえず無料トライアルでGoogle Cloudの使用を開始する。
APIキーを発行するプロジェクトを選択する。
My First Projectというプロジェクトが初めから作成されているので
とりあえずこちらを選択する。
メニューを開いて、APIとサービス → 認証情報へ移動する。

上部の+認証情報を作成 → APIキーをクリック。

数秒待つと作成完了メッセージが表示されるので、コピーして閉じる。
キーの制限はよしなに。ちなみにアクセス元(IPやアプリの種類など)や、
キーで呼び出すAPIを制限できるらしい。

認証情報ページで作成されたAPIキーが一覧に表示されていれば発行は完了。

次にCloud Vision OCRを使用するため、Cloud Vision APIを有効化する。
APIとサービス → ライブラリへ移動する。
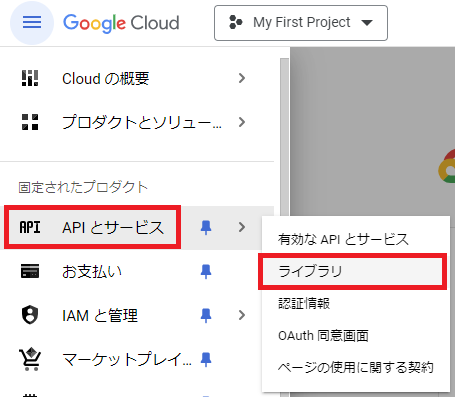
検索窓でCloud Vision APIと検索する。

検索できたら、有効にするを押下する。

数秒待って以下画面へ遷移していれば有効化は完了。

UiPathのCjkOCRでも一応作っていた話
Google Cloud Vision OCRアクティビティと同じ位置に
元々はCjkOCRアクティビティを入れていた。

その際の設定内容は以下の通り。
| 項目 | 値 |
|---|---|
| エンドポイント | "https://du-jp.uipath.com/cjk-ocr" |
| 画像 | input_img |
| テキスト | ocr_text_detection |
UiPathが提供しているOCRにはエンドポイントを設定する必要がある。
どのOCRにどのエンドポイントを設定する必要があるかは
以下の公式ページに記載されている。
作成途中までは問題なく動いていたもののCjkOCRを設定したUiPathのプロジェクトを複製、
複製したプロジェクトをデバッグしたところ、CjkOCRでエラーが発生。
エラー内容(抜粋)
OCR - 日本語、中国語、韓国語: Request CorrelationId: ほにゃらら
Request PredictionId:
Error performing OCR: Response indicates an error: Forbidden, Error: <!DOCTYPE html>
~省略~
<head>
<title>Attention Required! | Cloudflare</title>
~省略~
</head>
<body>
<div id="cf-wrapper">
<div class="cf-alert cf-alert-error cf-cookie-error" id="cookie-alert" data-translate="enable_cookies">Please enable cookies.</div>
<div id="cf-error-details" class="cf-error-details-wrapper">
<div class="cf-wrapper cf-header cf-error-overview">
<h1 data-translate="block_headline">Sorry, you have been blocked</h1>
<h2 class="cf-subheadline"><span data-translate="unable_to_access">You are unable to access</span> uipath.com</h2>
</div><!-- /.header -->
~省略~
UiPathのフォーラムを見たところ、
全く同じエラーについての質問は見当たらなかったものの
OCRでCloudflareのCookieのエラーが起きたというQ&Aはあった。
そのQ&AではUiPathの言語設定を英語に変更すると直ったような話だった。
今回は折角なら別のOCRを使おうという方向へ変更したので、
Q&Aと同じような方法で解消するか試せていないが、備忘録として記しておく。
2-3.テキストから会社名、合計金額、請求書のNoを抽出
ここからは、OCRで抽出したテキストを格納した
変数ocr_text_detectionから
必要な情報を取り出す為の処理をする。
まずは以下のアクティビティを使用。
- テキストを変更

この後に、必要な情報を取り出しやすいよう
半角スペースは念のため削除しておいたり、
合計金額の前後に記載されている¥や-が全角の場合は
半角へ置き換えるように変更させておく。
変更後のテキストは変数edit_ocr_text_detectionに格納する。
次にedit_ocr_text_detectionから必要な情報を取り出す処理を行う。
1つ目は請求書の番号(No.12345でいうところの12345の部分)を取り出す処理。
以下のアクティビティを使用。
- 一致するパターンを探す
- テキストを左右に分割

一致するパターンを探すの正規表現は以下内容で設定。
一致した値は変数pic_file_numberへ格納するようにも設定しておく。
| 正規表現 | 値 | 量指定子 |
|---|---|---|
| カスタム | .*(No)(¥.|¥.).* | 指定回数 1 |
正規表現で取り出しただけだと、番号以外の文字列も含んでいる状態なので
pic_file_numberをNo.で区切った右側(12345の部分)のみ
pic_file_numberへ格納する。
これで番号の取り出しは完了。
2つ目は合計金額を取り出す処理を行う。
以下のアクティビティを使用。
- テキストを取得
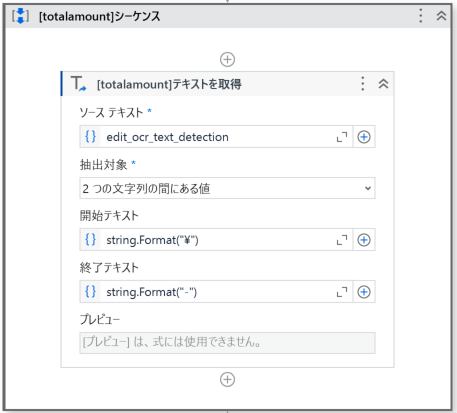
今回、請求書に記載されている合計金額はいずれも
¥と-の間にあるので、
その間にあるテキストを抽出するよう設定する。
抽出したテキストは変数pic_total_amountへ格納する。
これで合計金額の取り出しは完了。
3つ目は請求元の会社名を取り出す処理を行う。
ついでにデータテーブルへ会社名を格納する。
以下のアクティビティを使用。
- 一致するパターンを探す
- 繰り返し(コレクションの各要素)
- 型を変更
- 条件分岐(if)
- データ行を追加
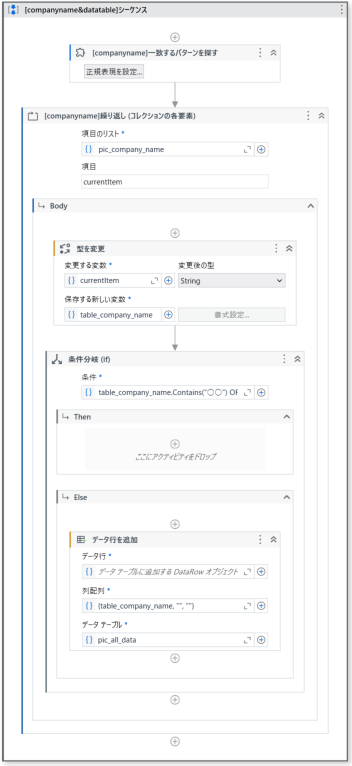
一致するパターンを探すの正規表現は以下内容で設定。
一致した値は変数pic_company_nameへ格納するようにも設定しておく。
| 正規表現 | 値 | 量指定子 |
|---|---|---|
| カスタム | .*(株式会社).* | 指定回数 1 |
請求書には請求元の会社名、記載されていれば自分の会社名があるため
pic_company_nameには1つ又は2つの会社名が格納されている状態となる。
請求元の会社名のみを抽出したい為、pic_company_nameから
自分の会社名ではない方の値(つまり請求元の会社名)であれば
データテーブルへ格納するように条件分岐(if)を設定した。
pic_company_nameはIEnumerable<Match>型で
String型ではないため、条件分岐(if)では
currentItem.Contains("自分の会社名")という条件は
設定できず、エラーが発生する。
そのため型を変更を行っているが、
currentItem.Value.Contains("自分の会社名")という条件の場合、
問題なく動くので型を変更は不要だと、
この記事を書いている最中に確認できてしまったのでこっそり記しておく。
何はともあれ、これで会社名の取り出しは完了。
2-4. 2-3で抽出した情報をデータテーブルへ格納
前述で請求元の会社名だけデータテーブルへの格納が済んでしまっているので
分けて章立てる必要ある?と思うでしょう。
アクティビティとしては分けている為、
このタイミングで請求書の番号、合計金額をデータテーブルへ格納する。
以下のアクティビティを使用。
- 複数代入
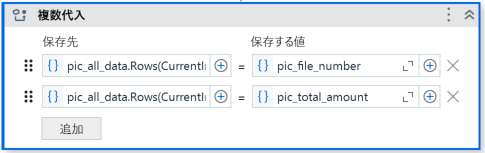
以下内容で設定。
| 保存先 | 保存する値 |
|---|---|
| pic_all_data.Rows(CurrentIndex - 1).Item("No") | pic_file_number |
| pic_all_data.Rows(CurrentIndex - 1).Item("金額") | pic_total_amount |
CurrentIndex - 1と設定している理由は
データテーブルの開始は0、CurrentIndexの開始は1となっている為。
.Rows(CurrentIndex)とした場合、
データテーブルの開始0行目ではなく、1行目を指定している事になり
0行目を飛ばしている為にエラーが発生する。
1行目に入れるとしても0行目は空欄?
0行目に何か値入れる?どうする?となると思う。
ちなみにCurrentIndexは2.フォルダ内のPDFを1つずつ処理で
出てきたCurrentFileのIndexを指している。
これでExcelへ書き込むデータテーブルの作成部分は完了。
3.出力先のExcelを選択し、データテーブルをシートへ書き込む
以下のアクティビティを使用。
- ファイルを参照
- Excelプロセススコープ
- Excelファイルを使用
- シートを挿入
- データテーブルをExcelに書き込み
- 最初/最後のデータ行を検索
- 範囲を自動調整
- Excelファイルを保存
- Excelファイルを使用
出力先のExcelはファイルを選択する形で、
選択されたExcelを使用して、書き込みを行う。
選択されたExcelはExcelファイルを使用の
参照名(今回はExport_Excel)で指定できる。
変数みたいなもの?今まではわざわざExcelのフルパスを
変数に入れて呼び出ししていたような気がするので
かゆい所に手が届く便利なアクティビティだと思ったり。
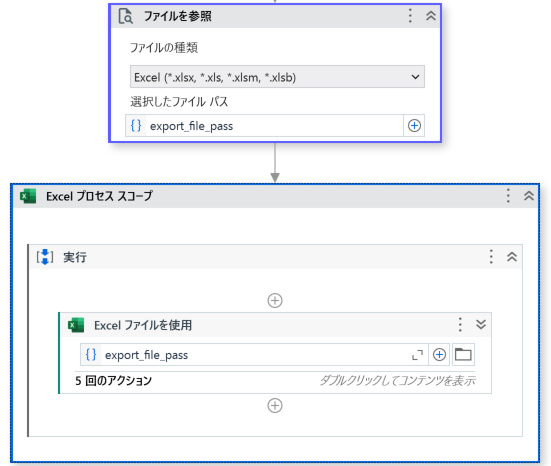
Excelファイルを使用配下の書き込み部分は以下。

それぞれのアクティビティは以下内容で設定。
シートを挿入

| 項目 | 値 |
|---|---|
| シートを作成するブック | Export_Excel |
| シート名 | "【出力結果】請求書情報_" + mk_datetime
|
| 新しいシートの参照名 | Export_Sheet |
念のため挿入されるシート名が他のシート名と
重複しないようにDateTime.Now.ToString("yyyyMMddhhmm")
という値が入っている変数mk_datetimeを含めている。
挿入されるシートもExport_Sheetで指定できる。(便利)
データテーブルをExcelに書き込み

| 項目 | 値 |
|---|---|
| 書き込む内容 | pic_all_data |
| ターゲット |
Export_Excel.Sheet(Export_Sheet.Name).Range("B2") |
pic_all_dataは請求元の会社名、請求書の番号、合計金額が
格納されているデータテーブル。
このデータテーブルを、選択したExcelの
挿入したシート(B2セルを起点)へ書き込むように設定。
最初/最後のデータ行を検索

| 項目 | 値 |
|---|---|
| ソース |
Export_Excel.Sheet(Export_Sheet.Name) |
| 列名 | "B" |
| 最初の行の番号を保存 | first_row_num |
| 最後の行として設定 | 入力されている最後の行 |
| 最後の行の番号を保存 | last_row_num |
先ほど書き込んだシートのセルのサイズを
次のアクティビティで調整したいので範囲を確認したい。
そのため起点としたB2セルの列を基準に
値が入っている最初の行、最後の行を確認する。
行数はそれぞれ変数first_row_num、last_row_numへ格納するように設定。
ちなみに、シートにはデータテーブルのヘッダーも書き込んでいるので
オプションにある先頭行をヘッダーとするにはチェックを入れる。
範囲を自動調整

| 項目 | 値 |
|---|---|
| ソースを選択 |
Export_Excel.Sheet(Export_Sheet.Name).Range("B" + first_row_num.ToString +":E"+ last_row_num.ToString) |
値が入っているセルのサイズを調整したいので、自動調整の範囲を指定する。
先ほど確認した最初の行、最後の行が格納されている変数は
Int32型となっており、ソースを選択の欄に記入する際は
String型で指定する必要があるので、.ToStringを付けている。
また、オプションでは列、行それぞれ自動調整するかをチェックを入れて設定できる。
今回は列、行どちらもチェックを入れる。
最後にExcelを保存して終了。
完成
出来上がったExcelを見てみると、
以下のように表が出力されているシートを確認できる。
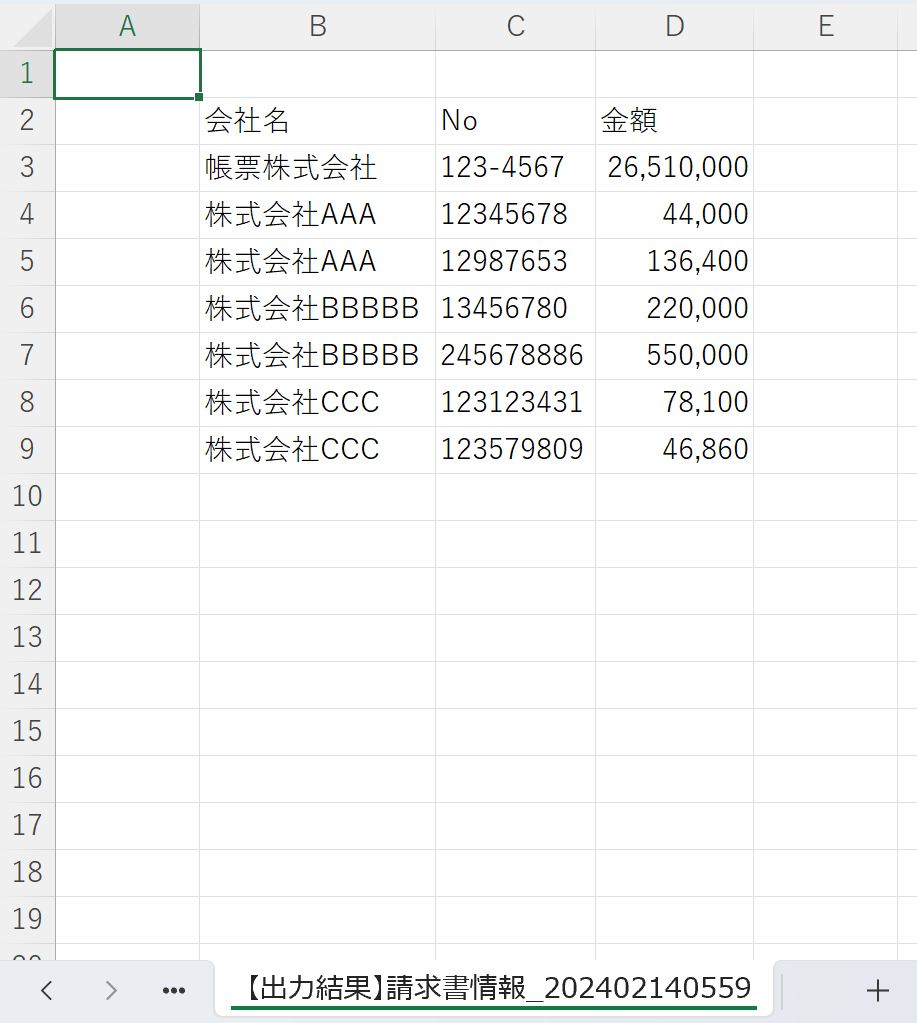
最後に
UiPathのアクティビティを見てみると他にもOCRアクティビティがある。
ただし、英文を読み込む前提らしく
(試しに使用してみたところ文字化けした日本語が抽出されたりされなかったり)
日本語を読み込む場合は日本語のデータを
UiPathの特定のファイルに入れておく必要があるものもあった。
また、AというパッケージのOCR、BというパッケージのOCRを
組み合わせようとインストールすると競合する為
組み合わせることが出来ないという事もあった。
なので今回少し触ってみて
今のところはUiPath以外のOCRを使用した方が困りごとは少なそうだと感じた。
今後UiPathのOCRがアップデートされたり、
より良いOCRの活用方法を思いついたらまた記事にしたい。