はじめに
- 本記事は、UiPath Studio の基礎知識をお持ちで、これから Document Understanding を利用したい方向けの内容となっています。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 23.4 バージョンで構成しています。
UiPath Document Understanding で何ができるの?
Document Understanding(以降、DUと略す)は、ドキュメントから情報を抽出・解釈する機能群です。
DUの機能と Studio でのワークフロー実装によって、次の様な自動化を実現できます。
(左の例)請求書やInvoiceから請求依頼システムへの自動入力や仕訳IFの作成・連携等
(右の例)履歴書から人事システムへの自動入力
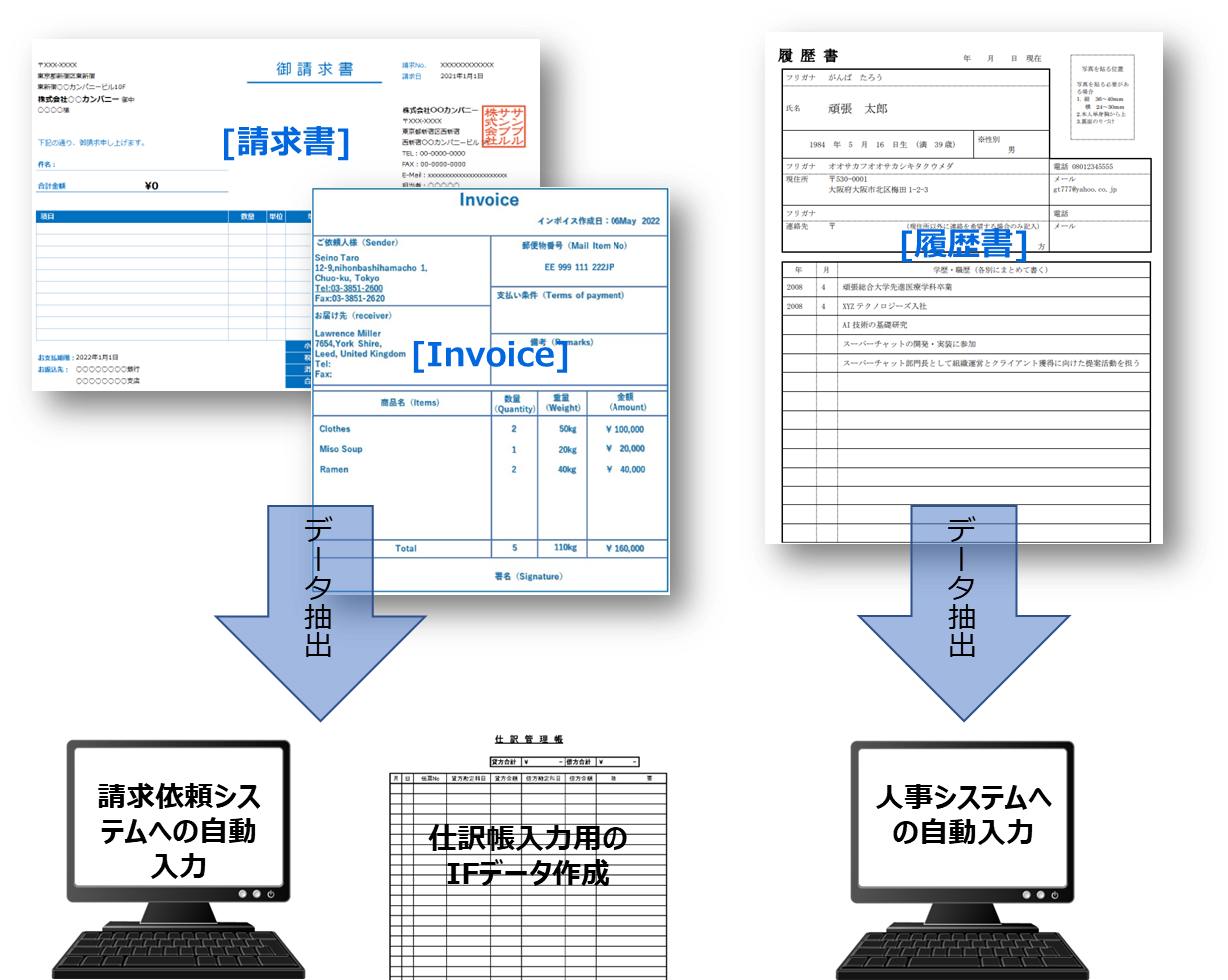
機能の全体像

自動変換

文書データをOCRでデジタルデータに変換します。
読み取り可能なファイルの拡張子は 「.pdf」「.jpeg」「.png」「.tiff」 です。
読み取り対象文書に日本語が含まれる場合、2023年5月時点で最も精度が高い 「OCR - 日本語、中国語、韓国語」 をご利用ください。
自動変換では文書から抽出した テキストデータ と ドキュメント オブジェクトモデル(通称:DOM) を出力します。(DOMはオブジェクト型のデータであり、単純な文書のテキストデータだけではなく、文書のページ数やメタデータ、文字の位置情報、その他の情報を保持します。)
自動分類

自動分類では、 文書のテキストデータ と DOM と タクソノミー を引数に渡して文書の分類をおこないます。
ここで急に登場したタクソノミーですが、帳票定義の様なもの と覚えてください。
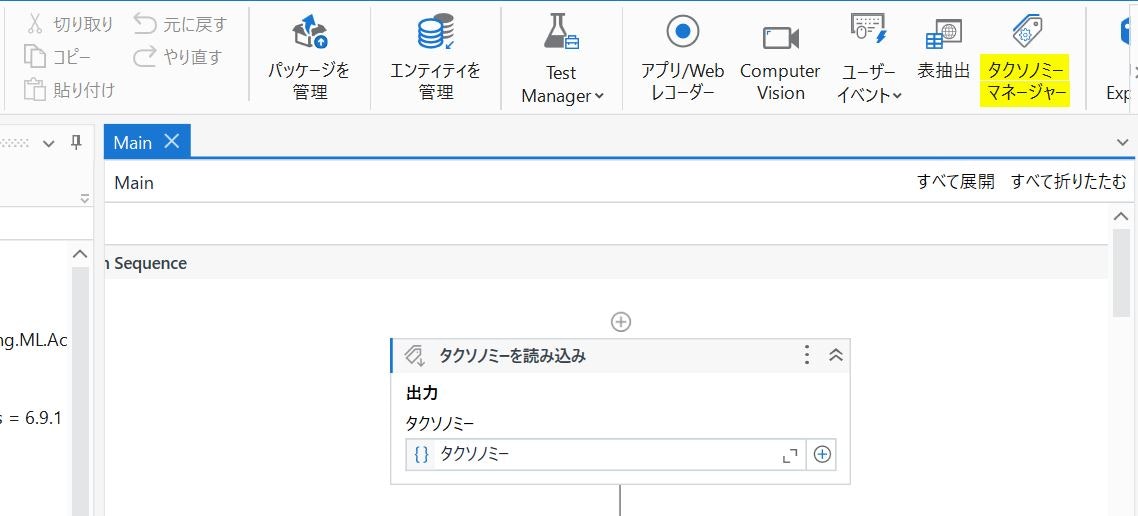
Studio のデザインリボンにある「タクソノミーマネージャー」ボタンを押下して表示される 専用画面で文書フォーマットの項目定義(※) をおこないます。
これは、DUのプロジェクトで一番最初にやることで、作成した定義は「タクソノミーを読み込み」アクティビティをワークフローの冒頭に配置し読み込みます。
※専用画面(タクソノミーマネージャー)

フォーマットの各項目はテキストや数値、日付型、表データを抽出するためテーブル型(以下、例)などがあります。

タクソノミーマネジャーの詳細はこちらのガイドで確認できます。
本題の分類についてですが、次の3つのアクティビティが用意されています。
- 「キーワード分類器」
- 「インテリジェントキーワード分類器」
- 「マシンラーニング分類器」
「キーワード分類器」と「インテリジェントキーワード分類器」は学習した単語ベクトル(※) をもちいて分類をおこないます。
「マシンラーニング分類器」は単語ベクトルに加え、座標や画像なども考慮できます。
※:学習結果(主に「スコア」と「キーワード」が対になったデータ)はローカルファイルに記憶されます。
■対象ファイル:
{プロジェクトフォルダ}\DocumentProcessing\IntelligentKeywordClassifierLearningFile.json
自動分類で利用するAIは分類用のモデルです。後述の抽出用のモデルとは別物です。
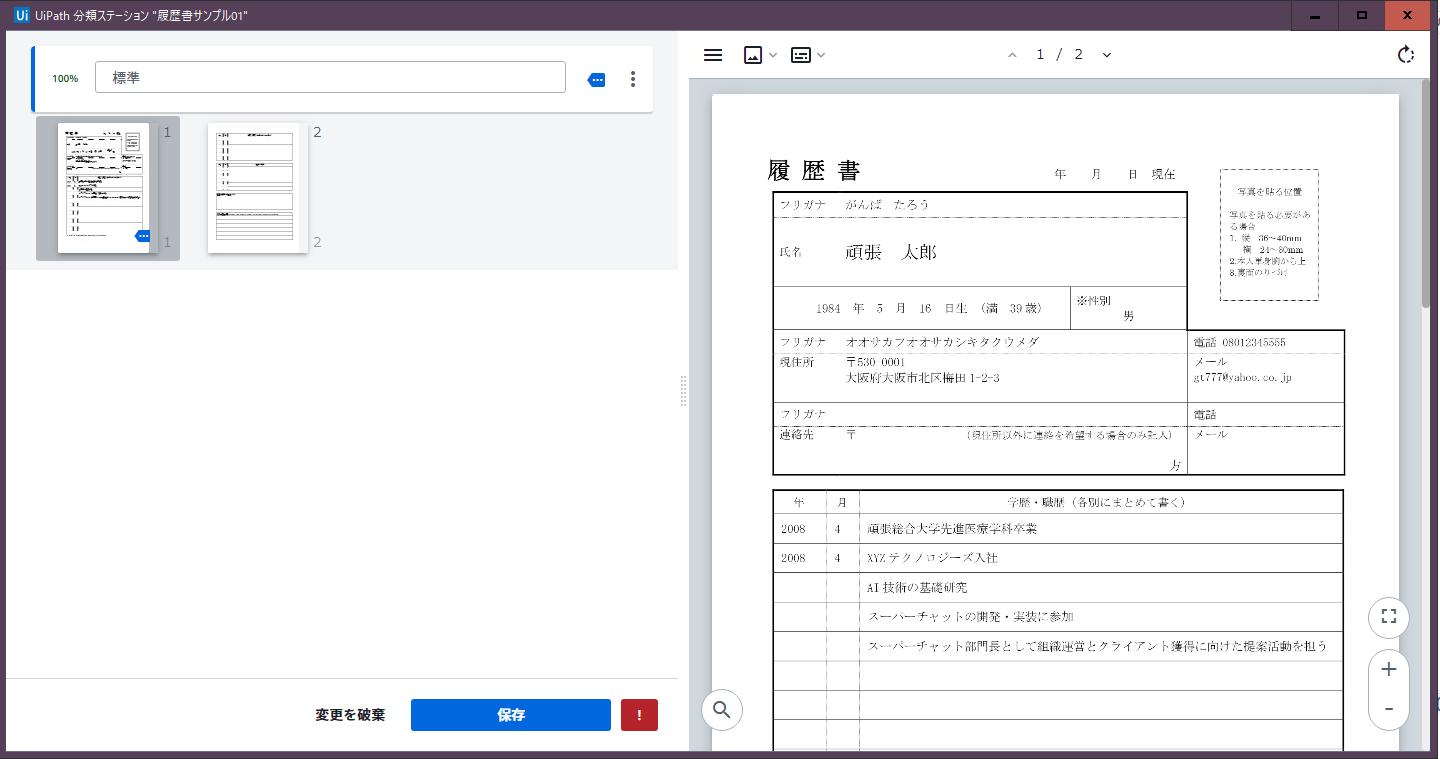
分類結果の表示

引数(文書のテキストデータ、DOM、タクソノミー、自動分類結果)を渡して実行することで、分類結果の画面(以下、例)を表示してくれます。

再学習(分類)
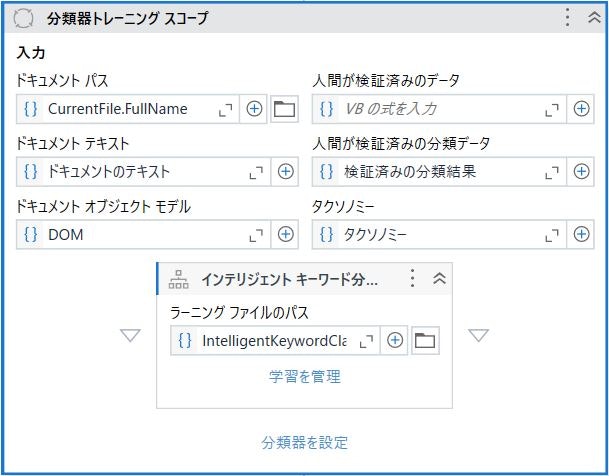
分類結果から手動で変更のあった項目のデータから再学習をおこないます。(上図は、ローカルの分類器のトレーニング用アクティビティ)
- 「キーワード分類器」と「インテリジェントキーワード分類器」 ➢ ローカルファイルのアップデート
- 「マシンラーニング分類器」 ➢ AIのモデルのアップデート
自動抽出
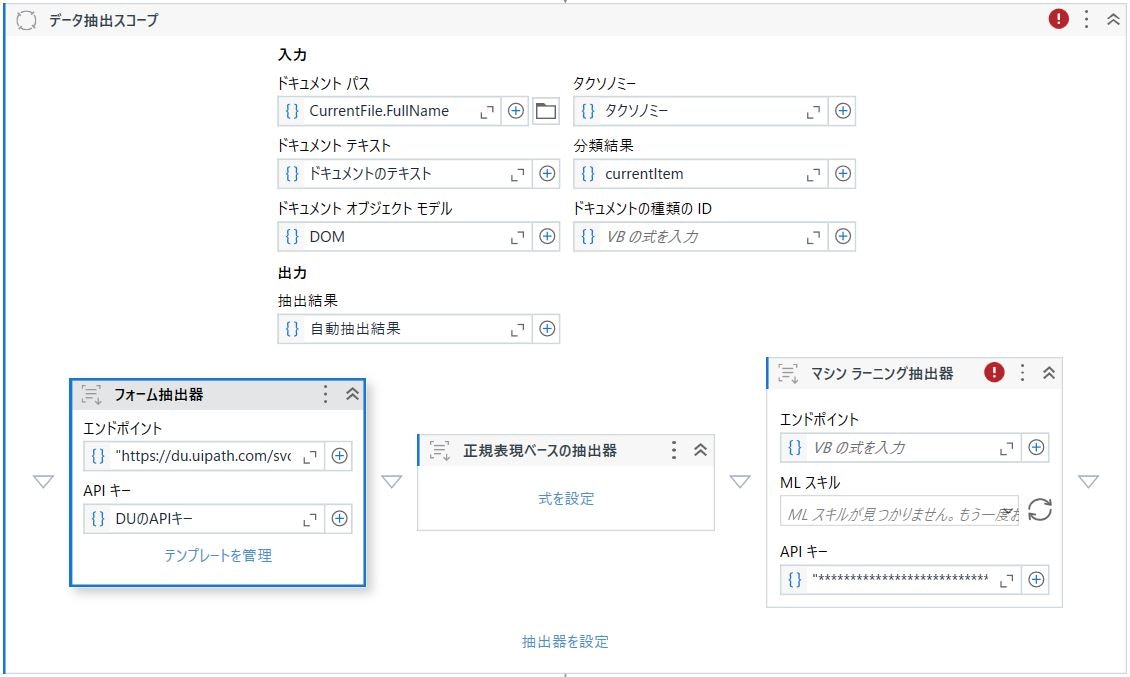
大別して3種類のデータ抽出方法があります。
-
ルールベース
- 「フォーム抽出器」と「正規表現ベースの抽出器」アクティビティ等をもちいて、文書上の固定領域内の値を抽出、または正規表現検索で一致する値を抽出します。
-
モデルベース
- 抽出用のAI(事前学習済みのモデル)に対して、トレーニングデータをもちいた追加学習をおこない、デプロイして利用可能となったエンドポイントを呼び出すかたちで値を抽出します。
-
ハイブリット
- ルールベースとモデルベース両方の抽出器をもちいて値を抽出します。
備考:
- 正規表現ベースの抽出では、該当データが複数在る場合、値は抽出されません。
- フォーム抽出器のテンプレート(読み取る領域の情報などを覚えさせたもの)は『分類』と紐づきます。複数のフォーマットのテンプレートを作成する場合、タクソノミーの登録段階で『分類』も分けておきましょう。
- AIのモデルの学習にもちいるデータセットの作成は DocumentManager(Automation Cloud のDUのサービスの一画面)等でおこなえます。
適用する抽出器は項目ベースで細かく指定することができます。

自動抽出で利用するAIは抽出用のモデルです。先述の分類用のモデルとは別物です。
抽出結果の表示

引数(文書のテキストデータ、DOM、タクソノミー、自動抽出結果)を渡して実行することで、抽出結果の画面(以下、例)を表示してくれます。

再学習(抽出)

抽出結果から手動で変更のあった項目のデータから再学習をおこないます。(上図は、抽出のAIモデルのトレーニング用アクティビティ)
2023年5月時点で、トレーニング機能が備わっているのは「マシンラーニング抽出器」のみです。
「フォーム抽出器」と「正規表現ベースの抽出器」はルールベースのため再学習はありません。
データ操作・出力

「抽出結果をエクスポート」アクティビティを使うことでデータセット型(※)の情報を出力できます。
※:複数のデータテーブルを保持できます。データテーブルを単一の「テーブル」とした場合、データセットは「データベース」のイメージです。
(出力サンプル)

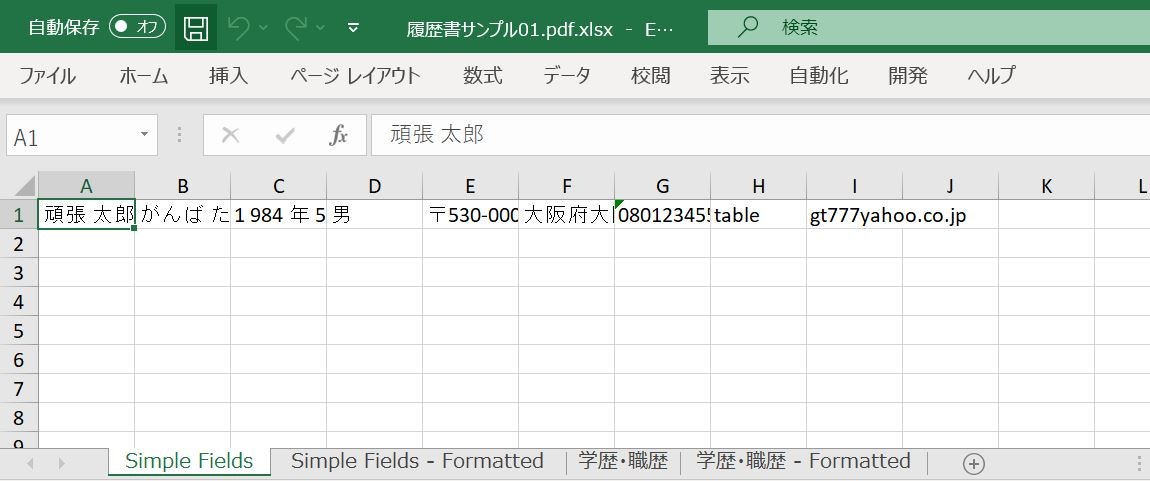

抽出したデータはワークフローの中で容易に整形することができます。
例えば、読み取った電話番号をハイフンなしに加工したい場合、

「代入」アクティビティを配置し、
{左辺の整形済みテキスト} = System.Text.RegularExpressions.Regex.Replace(電話番号, "[^0-9]", "")
と書くだけでできますし、住所を市区町村で分割してあげたければ
こちらの記事の様にChatGptと連携して処理することで実現できます。
最後に
いかがでしたでしょうか?
Document Understanding は登場人物が多い機能のため、UiPath の製品の中でも理解するのが難しい部類です。
この記事を読んで少しでもDUの理解が深まった、また関心が強まったという方は
是非以下の記事等もご覧になっていただけますと幸いです。
最後までお読みいただきありがとうございます(・ω・)ノ