概要
業務でファイルを直接やり取りするログ収集の仕組みを大幅に変更し、その際AWS Kinesis周辺サービスを利用しました。
構成を変更してから半年ほどたっていますが、構築時に調べた仕組みや運用してみてわかったことなどを記載します。
本構成で収集するログについて、内容は単純なjsonテキストで約2~3億行/日、データサイズはKinesisStreamsのGetRecords.Bytes計測で約500~600GB/日で運用しています。
構成
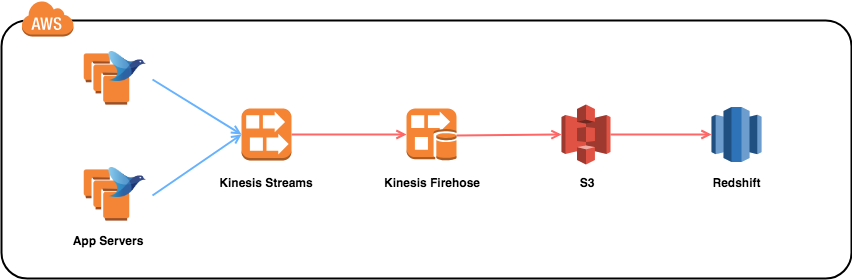
ログをfluentdが収集し、KinesisStreamsに連携します。
KinesisFirehoseはKinesisStreamsから取得したデータをS3を経由しRedshiftにCOPYします。
Redshiftにロードされたデータは、集計や分析などに利用します。
Fluentd
KineisStreamにログを送信する目的で利用しています。
主な利用プラグイン
fluent-plugin-kinesis
fluent-plugin-flowcounter
fluent-plugin-forest
fluent-logger
など
監視
td-agentログ監視(zabbix)
td-agentプロセス監視(monit)
td-agent重複デーモン対策(shell + monit)
flowcounterによる転送状態監視(flowcounter + shell + monit)
設計時によく見てたページ
fluentdでログが欠損する可能性を考える
http://blog.livedoor.jp/sonots/archives/44690980.html
fluentdを導入時にまず知っておいたほうがよさそうなこと(インストール、監視、HA構成、チューニングなど)
https://qiita.com/uzresk/items/3bfeeac82dfcb2a4300e
td-agentの監視・復旧の仕組みを整える
http://sgykfjsm.github.io/blog/2013/11/13/td-agent_with_monit/
Fluentd&Kinesis&Lambdaによる柔軟で高可用性なログ収集基盤の構築
https://qiita.com/KUMAN/items/38c09449b7d7a947aa6c
Amazon Kinesis
AWS Black Belt Online Seminar 2016 Amazon Kinesis
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-amazon-kinesis
KinesisStreams
大量データのリアルタイム処理に向いたストリームです。
プロジェクトではFluentdで集めたログの集約で利用しました。
FluentdでAggregatorを用意するよりも、制限はあるものの管理/冗長化が容易で、PUSH + PULL型の構成にできてよいです。
別途データ投入(PUSH)を行うプロデューサー / データ処理(PULL)を行うコンシューマーを用意する必要があります。
課金形式
シャード時間 (取得 1 MB/秒、送信 2 MB/秒) $0.0195
PUT ペイロードユニット、1,000,000 ユニットごと $0.0215
拡張データ保持期限 (最大 7 日間)、シャード時間ごと $0.0260
制限
書き込み 1シャードあたり 1MB or 1000PUT / sec
読み込み 1シャードあたり 2MB or 5PULL / sec
計測ログなど量が多いものは書き込み制限を少し気にする必要があります。(シャード増やせばいいのですが)
KPLを利用して1MB分まとめてPUTするとスループットをかなり稼げるのでプロデューサーは対応する / 対応しているライブラリを選んだ方が良いです。
また、アカウント毎にシャード数の上限が設定されていますがこちらは上限緩和申請を行えば拡張可能です。
スケーリング
スケーリングはシャード数の増減で対応します(リシャーディングという作業を行います)
仕組みが結構複雑なのですが、リシャーディングは大きな制約があるので注意が必要です。
(参考)
Amazon Kinesis StreamsのリシャーディングがAPI一発で行えるようになりました
https://dev.classmethod.jp/cloud/scale-your-amazon-kinesis-stream-capacity-with-updateshardcount/
1日2回のAPI 呼び出し制限
1/2倍, 2倍 を超えるスケールイン・アウトはできない
特に1日2回のAPI制限はきついので、スケーリングを行うときは1回目で余裕を持って増やす + 適切な値に調節する など実運用では注意すべき部分です。
運用が始まってからは一度、高負荷時のスケーリングでこの制限に引っかかってしまいストリームを作り直すことになりました。
KinesisFirehose
この構成ではKinesisStreamsのコンシューマーの役割をしています。
KinesisStreamへ投入されたログを60秒ごとに取り込み、S3を経由してRedshiftへロードします。
ちょうど検討を行なっていた頃に東京リージョンにきたので導入しました。
従来はKCLは自前で用意する必要がありましたが、Firehoseを利用するとほぼ管理不要で S3 / Redshift / Elasticsearch等へ自動データロードが可能です。
課金形式
取り込みデータ(GB)あたり
最初の 500TB/月 $0.036
次の 1.5PB/月 $0.031
次の 3PB/月 $0.025
取り込み間隔
1~128MB/60~900secの範囲でバッファサイズ, バッファ間隔を設定可能です。
サイズor間隔が先に最大値に到達したタイミングで連携が実行されます。
デフォルトは5MB/60sec (Daisyでは128MB / 60sec)
制限事項
各デリバリーストリームでは、
トランザクション : 2,000件/sec
レコード : 5000件/sec and 5MB/sec
の制限があります。
この制限は、サービス上限緩和申請をすれば引き上げが可能です。
ログデータの変換
KinesisStreamからデータを取得し、Firehoseにデータをロードする前にlambda関数を実行することができます。
FirehoseによるRedshift連携
Redshiftにデータを連携する場合は、KinesisStreamから取得したデータをS3に保存したのち、
COPYコマンドでRedshiftにデータをロードします。
COPYコマンドのオプションはfirehoseコンソール画面から設定可能です。
リトライ
S3へのデータ連携が失敗した場合、最大24時間5秒毎にリトライを実行します。
※24時間を過ぎた場合はデータは破棄されるので、KinesisStreamから再取得を行うか、ログの再投入が必要です。
Redshiftへのデータロードが失敗した場合、最大60分間5分ごとにデータの配信が再試行されます。
60分経過してもリトライが完了しない場合、S3にエラーファイルを作成します。
このエラーファイルはマニフェストファイルになっているので、このファイルを元にCOPYの再実行が可能です。
また、自動リトライ期間の設定も可能です。
データの一意性
ごくまれにタイムアウトなどでデータが重複する場合があるため考慮が必要です。
この場合は、ログ発行時に一意な値を付与 -> 取得時に重複除去 で対応するのが楽です。
参考
Amazon Kinesis Firehose 開発者ガイド
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/what-is-this-service.html
Amazon Kinesis Data Firehose についてのよくある質問
https://aws.amazon.com/jp/kinesis/data-firehose/faqs/
Amazon Redshift
KinesisFirehoseのデータ投入先に指定しています。
特にRedshiftのサービス内容については触れませんが、今回のようにログを投入し続ける構成の場合はデータ容量が日々増加するためそれに対応できる仕組みが必要です。
簡単ですがプロジェクトで実施した仕組みを記載します。
パーティショニング
Redshiftにはパーティショニング機能がないため、時系列テーブルを作成し擬似的にパーティションを行います。
利用者側では、各時系列テーブルをユニオンしたビューを参照します。
※参考 : 時系列テーブルを使用する
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/vacuum-time-series-tables.html
日時処理
日時で動作するバッチを別途作成し下記の処理を行なっています。
- 新規時系列テーブルの作成
- 時系列ビューテーブルの定義更新
- 不要時系列テーブルのドロップ
- Firehoseの連携先テーブルの更新
Firehoseは連携先テーブルを1つしか持てないため、時系列テーブルの運用を行う場合はこちらから切り替えてあげる必要があります。
切り替え中のデータロードについてですが、こちらは設定変更処理中は旧テーブルへロードし続ける → 処理完了後新規テーブルへデータが流れるといった挙動になります。
切り替え前後のテーブルを時系列ビューに含めておくことで、利用者は切り替えを考慮しないで良い仕組みになっています。
おわりに
現在の構成に変更してから約半年運用をしていますが、以前と比べると大きな障害なく快適に運用できるようになりました。
他にも思いついたら追記していきます。