はじめに
物体認識において、Deep Learningによる物体検出手法をまとめます。
OpenPoseの骨格検出を使って、野球の動作解析を進めてきました。
次は、バットやボールといった道具を自動的に検出(座標を取得)したいと考えています。
物体検出にはいろいろな方法があるようなので、まずはその整理を簡単にしてみます。
※.主に各手法の概要を整理したいと思います。具体的なアルゴリズムについては触れません。
物体認識とは
物体認識(object recognition)は、画像に写っているものが何であるかを言い当てる処理で、
特定物体認識と一般物体認識に分類されています。
特定物体認識は、ある特定の物体と同一の物体が画像中に存在するかを言い当てる(identification)処理で、一般物体認識は、椅子、自動車、虎など一般的な物体のカテゴリを言い当てる(classification)処理です。
物体検出とは
画像の中から定められた物体の位置とカテゴリー(クラス)を検出することを指します。
下図のように、画像の中からバウンディングボックスと呼ばれる矩形の位置とカテゴリを識別します。
「認識」と「検出」の違いについてはこちらでも分かりやすくまとめられていました。
自動運転にも応用される精緻な画像認識技術、「画像セグメンテーション」とは?事例を交えてわかりやすく解説
物体検出手法
HOG特徴量(*1)を使った物体検出もありますが、ここではDeepLearningを使った手法をまとめます。
物体検出では、アルゴリズムの違いによってR-CNN系、YOLO系、SSD系の大きく3つに分かれるようです。
主な特徴
| 手法 | モデル | 主な特徴 | 実装 |
|---|---|---|---|
| R-CNN系 | ・R-CNN (CVPR 2014) ・SPPnet(ECCV 2014) ・Fast R-CNN(ICCV 2015) ・Faster R-CNN(NIPS 2015) ・Mask R-CNN(arXiv2017) |
先駆け、遅い | PyTorch/Keras/TensorFlow/Caffe |
| YOLO系 | ・YOLO(CVPR 2016) ・YOLOv2(arXiv2016) ・YOLOv3 (arXiv2017) |
速い、多オブジェクトを検出できない | PyTorch/Keras/TensorFlow/Chainer |
| SSD系 | ・SSD(ECCV2016) ・DSSD(arXiv2017) ・ESSD ・RefineDet |
速い、多オブジェクトを検出可能 | PyTorch/Keras/TensorFlow/Chainer |
YOLOv3ではYOLOv2に比べて速度を犠牲にして、精度が向上しているようで、なおかつ多オブジェクトも検出可能になっているようです。
YOLOV3-kerasをリアルタイムで使用する
Masc R-CNNでは、ピクセル単位での認識(セグメンテーション)も可能になっており、下図のようにバウンディングボックスだけでなく、物体の境界も識別できています。

フレームワーク実装を試してみた
速いとは言え、SSDはGPU環境でならリアルタイム検出可能な模様(CUPでは無理っぽい)
SSDでは検出できなかった小さなオブジェクトも Mask R-CNNでは検出できていました
-
Mask R-CNN
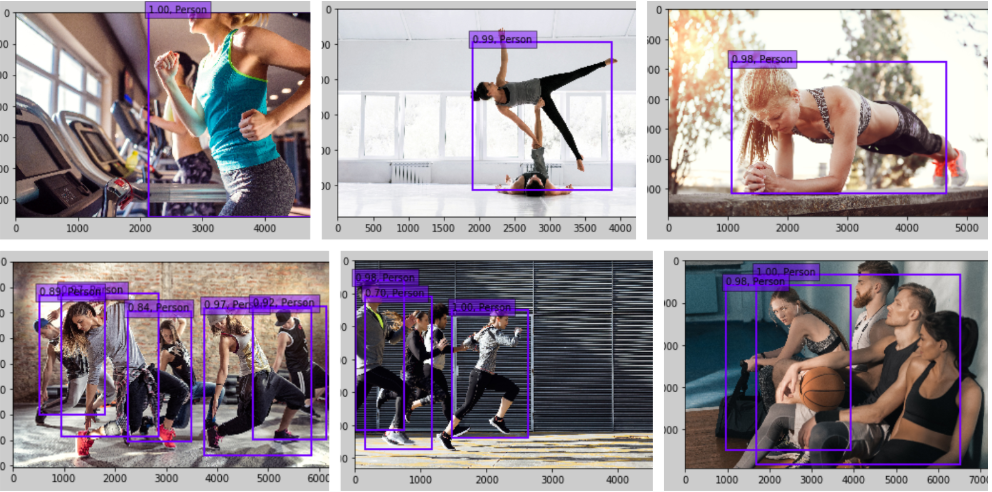
Mask R-CNN(keras)で人物検出 on Colaboratory
結局何を使えばいいか
まとめてみましたが、結局どの課題に対して、どの手法が適しているのかは分かりませんでした。。。
さらにそれぞれのモデルを実装したフレームワークにも違いがありそうで、課題に対して、何をどうやって判断・適用していけばいいのか、、、自分の理解不足・スキル不足も相まってもはや闇・・・
一般のプロジェクトではどうやって手法を取捨選択して行ってるのだろう・・・
参考
*1 :HOG特徴量
HOG(Histograms of Oriented Gradients)とは局所領域 (セル) の輝度の勾配方向をヒストグラム化したもの。
引用:画像からHOG特徴量の抽出
物体検出のアルゴリズム
歴史(欠点をいかにして克服してきたか)やアルゴリズムに関しては、以下のサイトが参考になりそう。
-
物体検出についての歴史まとめ
https://qiita.com/mshinoda88/items/9770ee671ea27f2c81a9 -
Slide Share
https://www.slideshare.net/ren4yu/single-shot