Kaggleのチュートリアルとして公開されているTitanic問題に対する素敵な解答を提出されている方がいたので、(データ分析と英語の)勉強を兼ねて翻訳してみます。
私はデータ分析も英語も特に出来るわけではないので、いろいろ誤りがあるかと思います。
もしお気づきの点があればお知らせくだされば幸いです。
なお、訳出は適宜抜粋しつつ行うものとします。全文訳ではないことをご承知おきください。
本記事は2記事目となります。1記事目をお読みでなければ先にそちらをご覧ください。
前回までのまとめ(翻訳者による)
| 特徴名 | 意味 | 種別 | 有用性及び考察 | 判明した事実 |
|---|---|---|---|---|
| PassengerID | 乗客ID | カテゴリ | 生存に貢献しないだろうから削除 | - |
| Survived | 生存 | 数値 | - | - |
| Pclass | 乗船クラス | カテゴリ(順序 | 生存との関連性あり | クラス1であれば生存率が高い |
| Name | 名前 | カテゴリ | 敬称を抜き出し新特徴に変換 | - |
| Sex | 性別 | カテゴリ | 生存との関連性あり | femaleであれば生存率が高い |
| Age | 年齢 | 数値 | 要補完。生存との関連性あり。またAgeBandsという新特徴にも変換 | 子供(年齢帯は不明)であれば生存率が高い |
| SibSip | 兄弟姉妹、配偶者 | 数値(不連続 | Familyという新特徴に変換 | - |
| Parch | 親、子供 | 数値(不連続 | Familyという新特徴に変換 | - |
| Ticket | チケット | 混合 | 重複が多すぎるので削除 | - |
| Fare | 料金 | 数値(連続 | 使えそうであればFareRangeという新特徴に変換 | - |
| Cabin | 客室 | 混合 | 欠損率が高すぎるので削除 | - |
| Embarked | 乗船地 | カテゴリ | 要補完。生存もしくはその他との関連性あり | - |
特徴を軸にした分析
ここまでに行った観察と仮定を確認するためにも、特徴を軸にしてお互いの特徴間における関連性を分析を速やかに行うべきである。この段階においては、空データを持たない特徴に対してのみアクションを起こすことがきる。また、それはカテゴリカルな特徴(Sex)、順序を示す変数(Pclass)、または非連続な変数(SibSp,Parch)に対して行うことにおいてのみ、意味を成す。
- Pclass //乗客クラス
私たちはPclassが1であるということと生存率の間にはっきりとした相関性があることを観察している。よって、この特徴を私たちのモデルに取り込むことを決定する。 - Sex //性別
私たちはSexがfemale(女性)であるものは高い確率で生存している(74%)ということを問題定義の説明文において確認している。 - SibSp and Parch //兄弟姉妹と配偶者、および親と子供
これらの特徴はそれぞれの値については相関性はゼロである。個々の特徴から、一つの特徴または一そろいの特徴を抽出するのが最もよいと思われる。
# Pclass
train_df[['Pclass', 'Survived'].groupby(['Pclass'],
as_index=False),
mean().sort_values(by='Survived', ascendinf=False)]
>>>
Pclass Survived
0 1 0.629630
1 2 0.472826
2 3 0.242363
# Sex
train_df[['Sex', 'Survived'].groupby(['Sex'],
as_index=False),
mean().sort_values(by='Survived', ascendinf=False)]
>>>
Sex Survived
0 female 0.742038
1 male 0.188908
# SibSp
train_df[['SibSp', 'Survived'].groupby(['SibSp'],
as_index=False),
mean().sort_values(by='Survived', ascendinf=False)]
>>>
SibSp Survived
1 1 0.535885
2 2 0.464286
0 0 0.345395
3 3 0.250000
4 4 0.166667
5 5 0.000000
6 8 0.000000
# Parch
train_df[['Parch', 'Survived'].groupby(['Parch'],
as_index=False),
mean().sort_values(by='Survived', ascendinf=False)]
>>>
Parch Survived
3 3 0.600000
1 1 0.550847
2 2 0.500000
0 0 0.343658
5 5 0.200000
4 4 0.000000
6 6 0.000000
可視化されたデータによる分析
さて、今から可視化されたデータ分析を使用して仮定の確認作業を再開しよう。
数的特徴の相関性
数的特徴と今回の目標(生存)との間にある相関性を理解することを始めよう。
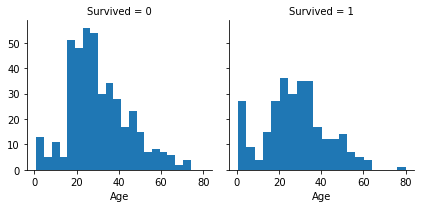
ヒストグラムやチャートは、今回のAge特徴のように帯を成しているものまたはある範囲を成しているような連続的な数的特徴を分析するのに役立ち、有用なパターンを特定してくれる。ヒストグラムは自動的に決定されたビンまたはバンドを使用して、サンプルの文保を表示することができる(幼児の生存率は高かったのだろうか)
ヒストグラムのX軸はサンプルまたは乗客の数を表していることに注目すること。
観察結果
- 幼児(4歳以下)は高い生存率であった
- 最も老いていた乗客(80歳)は生き残った
- 大きな割合を占めていた(15-25)歳の人々は生き残れなかった
- 最も乗客が多かった年齢帯は15-35歳であった
判定
この簡単な分析は連続的な処理ステージの決定としての仮定を確認する。
- Ageについての仮定を私たちのモデルに取り入れることを考えるべきだ。
- Age項目における空白を補完しなければいけない
- Ageは帯グラフ化すべきだろう
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
>>>
数的特徴と順序特徴における相関性
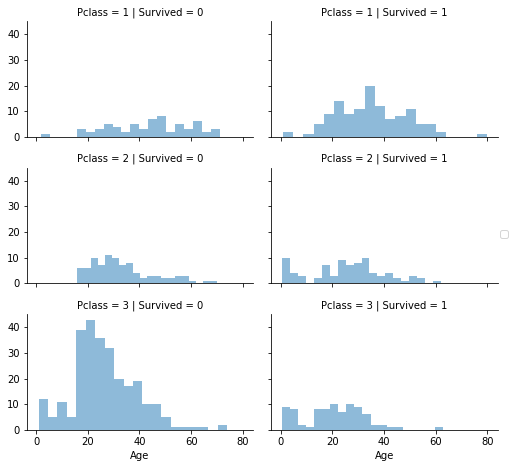
簡単なプロットを用いて、相関性を確認するためにいくつかの特徴を結合させることができる。これは数的な値を持つ特徴と数的な値を持つカテゴリ特徴を用いて行いうる。
観察結果
- Pclassが3である乗客が最も多い。しかしながら、最も生き残っていないのもこのクラスの乗客である。ここに我々の仮定の確かさが確認される。
- Pclassが2と3における子供は最も多く生き残っている。これは私たちの仮定をより強固なものにする。
- Pclassが1の乗客が最も多く生き残っている。ここに我々の分類についての仮定の確かさが確認される。
- Pclassは乗客の年齢分布によって変化する。
決定
- Pclassをモデルの訓練に取り入れることを考える。
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass'm size=2.2m aspect=1.6)
grid.map(plt.hist, 'Age', alpha=5, bins=20)
grid.add_legend()
カテゴリ特徴における相関性
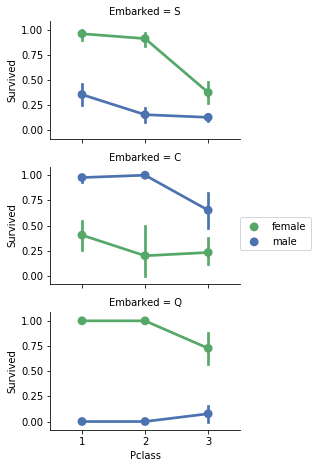
いま私たちは私たちの目標に対してカテゴリ特徴の関連づけることができる、
観察結果
- 女性の乗客は男性の乗客よりも多く生き残っている。ここに分類についての私たちの仮定の確かさを確認できる。
- EmbarkedがCである男性については、例外的に高い生存率が観察できる。これはPclassとEmbarkedの関係というよりはPclassとSurvivedの関係によるものであると思われるから、EmbarkedとSurvivedの間に直接の相関性があると考える必要はないだろう。
- 男性の乗客は、EmbarkedがCとQにおいて比較したとき、Pclassが2である人々よりも3である人々の方が優れた生存率を誇った。
- 乗船地という特徴は、Pclassが3である人々および男性乗客者に対して生存率を変化させる要因である。
決定
- Sex特徴をモデルの訓練に取り入れる。
- Embarkedの特徴は空白を補完したうえでモデルの訓練に取り入れる。
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
>>>
カテゴリ特徴と数的特徴間の相関性
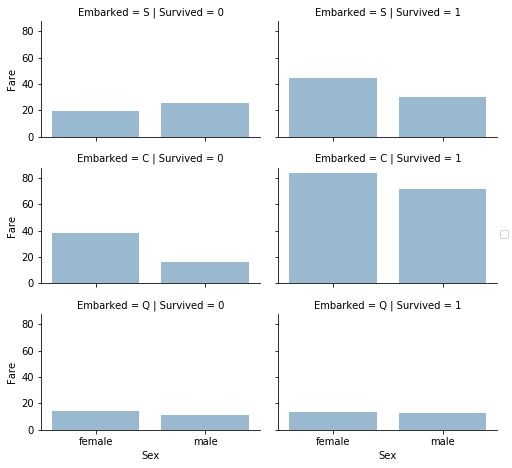
私たちはまた数字を含まないカテゴリ特徴と数的特徴についても関連付けることができる。乗船地、性別、料金と生存率の相関性について考える。
観察結果
- 高額な乗船料金を払った乗客はより優れた生存率を誇った。ここに、料金レンジについての新たな特徴を作るべきだという仮定の確かさを確認できる。
- 乗船地は生存率と相関性を持つ。
決定
- 料金特徴から、料金帯という特徴を作成する。
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspact=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=5, ci=None)
grid.add_legend()
---------------原文ここまで------------------
ここまでのまとめ(翻訳者による)
可視化したことで判明した事実群
|特徴名|意味|判明した主な事実|今後の方針|
|----|----|----|----|----|
|Pclass|乗船クラス|1の乗客は最も生存率が高かった。3の乗客は最も多いが、最も生存率が低かった
|Sex|性別|女性の生存率が高かった
|Age|年齢|4歳以下の幼児は生存率が高かった|年齢帯による区別を設ける|
|Fare|料金|高額な料金を払った乗客は生存率が高い|料金帯による区別を設ける|
|Embarked|乗船地|Pclassが3である人々および男性乗客者に対して生存率を変化させる要因である。
原文