この記事では、3つのGoogle Cloudプロジェクトを使います。
2つは監視可能なリソースを使用し、3つ目は中央の監視ワークスペースをホストするために使用します。
2つのリソースプロジェクトを監視ワークスペースにアタッチし、稼働時間チェック(Uptime check)を構築して、一元化されたダッシュボードを構築します。
#全体像
①ワーカープロジェクトを構成します。
②監視ワークスペースを作成し、2つのワーカープロジェクトをそれにリンクします。
③監視グループを作成および構成します。
④稼働時間チェック(Uptime check)を作成してテストします。
⑤カスタムダッシュボードを作成する
##①リソースプロジェクトを構成
ID1を監視ワークスペースのホストプロジェクト、
ID2およびID3は、監視対象/リソースプロジェクトとします。
ID2,ID3の各ワーカープロジェクトにNGINX Webサーバーを作成します。
####2つのリソースプロジェクトを構成する
監視するリソースを構築することから始めましょう。
ID 1 を Monitoring プロジェクト
ID 2 を Worker 1
ID 3 を Worker 2
とします。
Worker1に切り替えます。
赤枠を押下すると、プロジェクトの切り替え画面に遷移します。
コンソールの左上隅にあるナビゲーションメニューを使用してGoogle Cloudメニューを開き、Marketplaceへのリンクをクリックします。
検索ボックスに「NGINX Bitnami」と入力します。結果にポップアップ表示されるBitnamiによって認定されたNGINXオープンソースをクリックし、[起動]ボタンをクリックします。
デプロイメント名をworker-1-serverとしてデプロイします。
Deployment Managerインターフェイスが表示されたら、デプロイが完了するのを待たずに、次に進みます。
左上のナビゲーションメニューを使用して、プロジェクトのホームページに戻ります。
プロジェクトのドロップダウンを使用して、Worker 2のプロジェクトに切り替えます。
ワーカー2で同様の手順を実行します。
プロジェクトのドロップダウンを使用して、Worker 1プロジェクトに戻ります。
ナビゲーションメニューを使用して、コンピューティングエンジン-VMインスタンスへ遷移します。
External IPが表示されない場合は、少し待ってからページを更新してください。
External IPをコピーして、新しいブラウザタブに貼り付けます。Worker1Webサーバーが表示されることを確認してください。
プロジェクトのドロップダウンを使用して、Worker 2プロジェクトに切り替えます。
ワーカー2で同様の手順を実行します。
##②監視ワークスペースを作成し、2つのワーカープロジェクトをそのワークスペースにリンクします
####ワーカー1および2プロジェクトへの中央監視リンクを構成します。
Monitoring プロジェクトに切り替えます。
ナビゲーションメニューを使用して、Monitoring-Overviewに切り替えます。このプロジェクトでMonitoringにアクセスしたのはこれが初めてであるため、GoogleCloudは自動的にMonitoringWorkspaceを作成します。ワークスペースが作成されるまで待たなければならない場合があります。
モニタリングワークスペースが作成され、クラウドモニタリングの概要が表示されたら、左側のメニューで[Setting]をクリックします。
[ GCPプロジェクトの追加]を押します。
Worker 1およびWorker 2プロジェクトを選択します。
[スコーププロジェクトの選択]で[このプロジェクトをスコーププロジェクトとして使用する]を選択し、[プロジェクトの追加]を押します。
ダッシュボードページに切り替えます。何も表示されない場合は、ページを更新してください。1〜2分後に、他の2つのプロジェクトのディスク、ファイアウォール、インフラストラクチャの概要、およびVMインスタンスが表示されます。
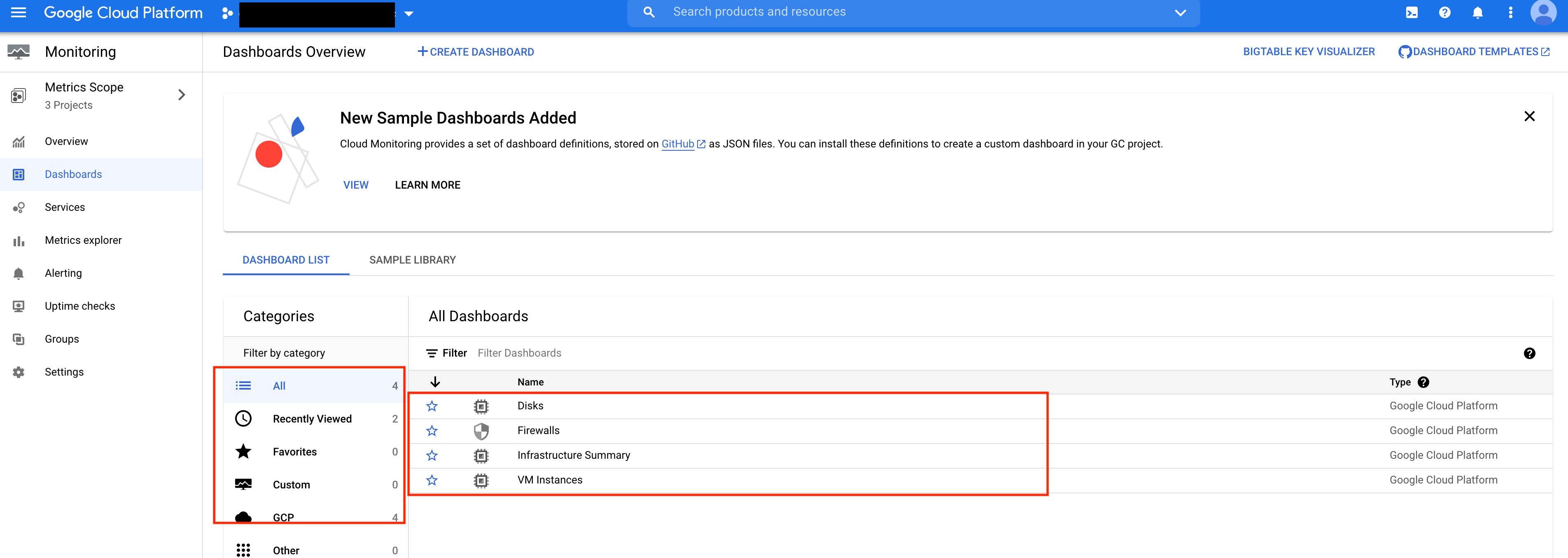
[ VMインスタンス]をクリックします。数分かかります。
[ダッシュボード]をクリックして、他の利用可能なダッシュボード、特にインフラストラクチャの概要を確認します。
##③監視グループを作成および構成する
Google Cloud Monitoringを使用すると、一連のリソースを1つのグループとしてまとめて監視できます。その後、グループをアラートポリシー、ダッシュボードなどにリンクできます。各ワークスペースは、最大500のグループと最大6層のサブグループをサポートできます。グループは、ラベル、地域、アプリケーションなど、さまざまな基準を使用して作成できます。
####Webサーバーにラベルを割り当てて、追跡しやすくします
ナビゲーションメニューを使用して、Google CloudConsoleのホームページに移動します。
プロジェクトのドロップダウンを使用して、Worker 1プロジェクトに切り替えます。
ナビゲーションメニューを使用して、コンピューティングエンジン-VMインスタンスに移動します。
リンクをクリックして、worker-1-server-vm設定に移動します。
押して[編集]ボタンをクリックします。
[ラベルの追加]ボタンを押して、キーcomponentと値-frontendと入力してラベルを作成します。
[ラベルの追加]ボタンを押して、キーstageと値-devと入力してラベルを作成します。
構成の変更を保存します。
プロジェクトのドロップダウンを使用して、Worker 2プロジェクトに切り替えます。
同様のタスクを実行します。
worker-2-server-vmの設定を編集します。
[ラベルの追加] component=frontend
[ラベルの追加] stage=test
変更を保存します。
####リソースグループを作成し、その中にサーバーを配置します
プロジェクトのドロップダウンを使用してMonitoring Projectに切り替えます。
Monitoring-Overviewに移動します。
左側のメニューで、[グループ]設定に移動します。
- CREATEGROUPリンクを使用して新しい監視グループを作成します。
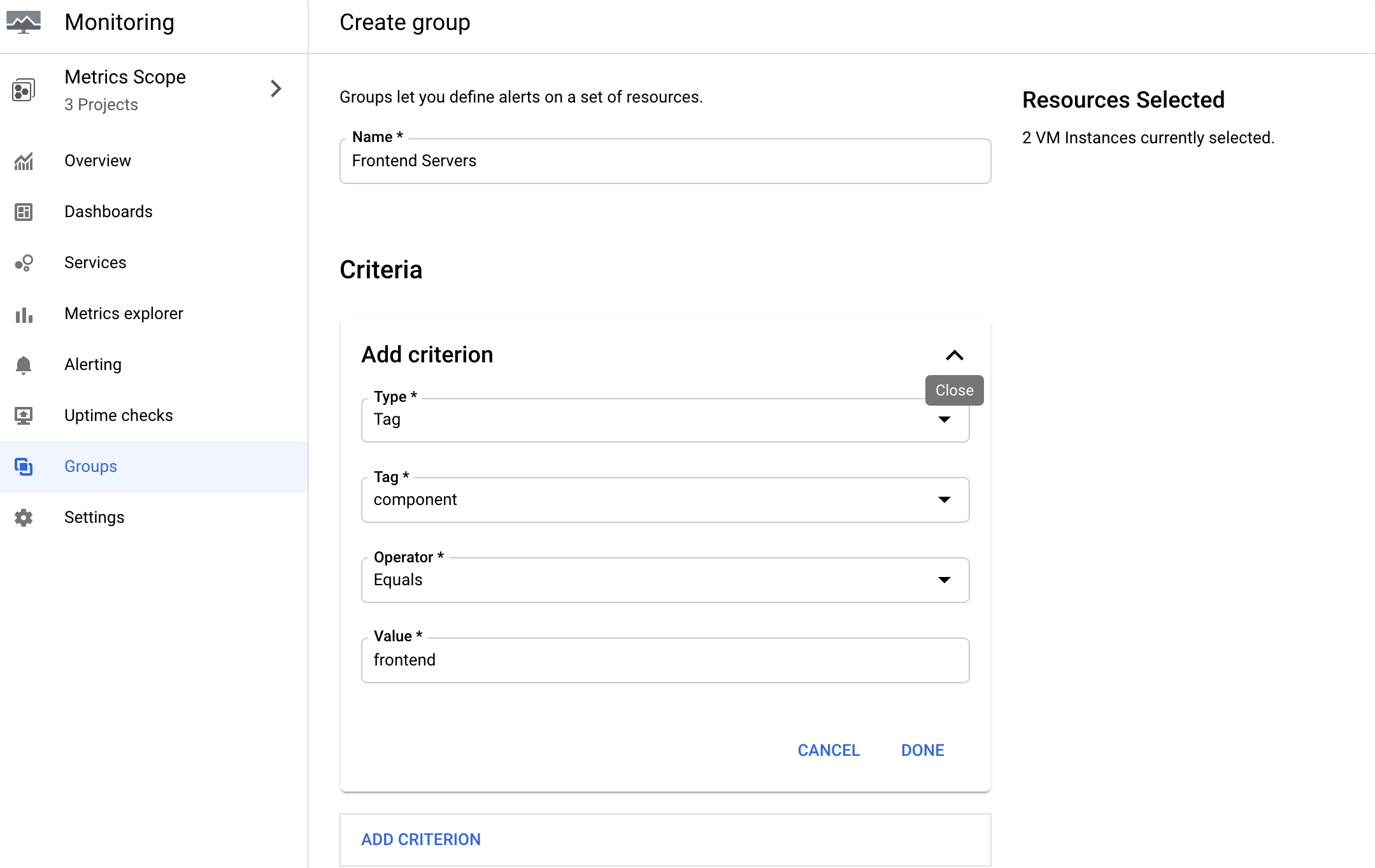
Frontend Serversと、グループに名前を付けます。
Criteriaには、以下を使用します。
Type=Tag
Tag=component
Operator=Equals
Value=frontend
Resources Selectedページの右側に 2 VM Instances currently selected.と表示されていることを確認してください。表示されていない場合は、条件を再確認してください。
####フロントエンド開発サーバー専用のサブグループを作成します
Frontend Serversグループで、Subgroupsセクションをクリックし、サブグループをCREATEします。
Name=Frontend Dev
Criteria 1
Type=Tag
Tag=component
Operator=Equals
Value=frontend
Criteria 2
Type=Tag
Tag=stage
Operator=Equals
value=dev
2番目の基準の[完了]をクリックし、And基準演算子を選択してそれらを結合します。
[作成]をクリックします。
Groupsホームページに戻ります。Frontend Serversグループを展開してサブグループを表示する方法に注目してください。UIには、グループに含まれるリソースの種類に関する情報を含むクリック可能なリンクも表示されます。
##④稼働時間チェック(uptime check)を作成してテストする
Google Cloudの稼働時間チェックでは、世界中の複数の場所からこれらのアプリケーションにアクセスすることで、外部に面しているHTTP、HTTPS、またはTCPアプリケーションの活性をテストします。後続のレポートには、稼働時間、遅延、およびステータスに関する情報が含まれます。稼働時間チェックは、アラートポリシーとダッシュボードでも使用できます。
####フロントエンドサーバーグループの稼働時間チェックを作成します
稼働時間チェックについて、リソースを含むグループをすでに作成している場合は、複数のサーバーに対して単一の稼働時間チェックを簡単に作成できます。
Monitoring Projectに切り替え、Monitoringで、[稼働時間チェック]をクリックします。
ページの上部にある+ CREATE UPTIMECHECKへのリンクをたどります。
次の設定で新しい稼働時間チェックを構成します(まだ[保存]を押さないでください)。
name=Frontend Servers Uptimeと入力し、[次へ]をクリックします。
ターゲットプロトコル=HTTP
リソースタイプ=Instance
適用=Group
グループ=Frontend Servers
Path=/
頻度を確認する=1 minute
[次へ]をクリックして、他のオプションをデフォルトのままにします。必要に応じて、[アラートと通知]セクションで、[通知チャネルの管理]を使用して、有効な通知オプションとして電子メールアドレスを追加します。アラートはデフォルトで有効になっていますが、実際には他の人に通知することはありません。
[テスト]をクリックして、200の応答を確認します。
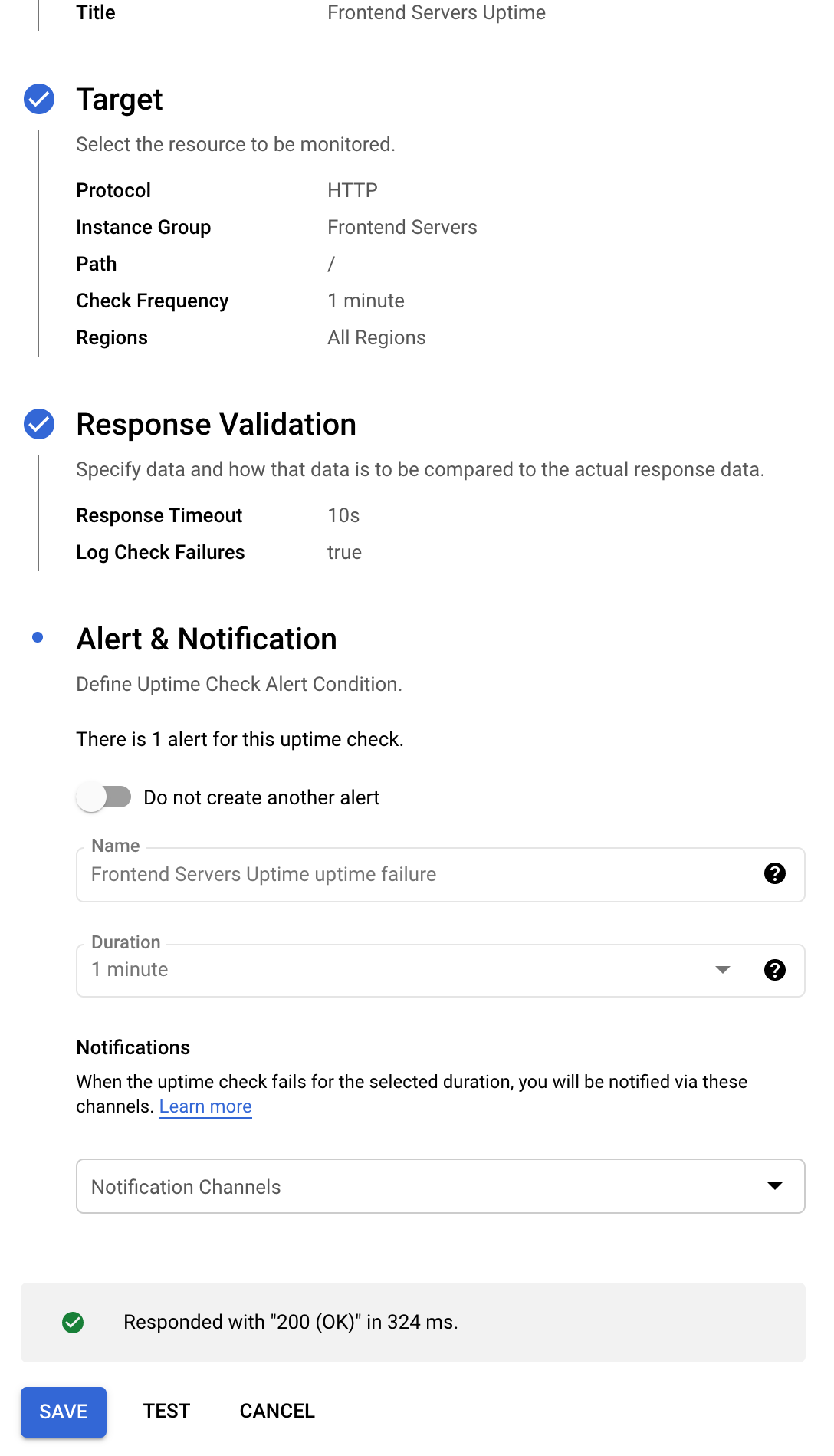
稼働時間チェックを作成します。
稼働時間チェックのリストで、新しいフロントエンドサーバーの稼働時間をクリックしてダッシュボードを表示します。
数分待ってから更新してください。ダッシュボードには、チェック結果に関する情報が表示されます。チャートとデータを調べてください。
Configurationボックス内のページの右側で、Check ID値をコピーして、メモのテキストファイルに貼り付けます。frontend-servers-uptimeを読み取る必要があります。
####稼働時間チェックが障害を処理する方法を確認
稼働時間チェックは機能していますが、失敗した場合はどうでしょうか。失敗をトリガーして、結果として生じる稼働時間のチェックとアラートの動作を調査してみましょう。
続行する前に、稼働時間チェックのダッシュボードに数分程度のデータがあることを確認してください。
ナビゲーションメニューを使用して、GoogleCloudホームページに移動します。
プロジェクトのドロップダウンを使用して、Worker 1プロジェクトに切り替えます。
ナビゲーションメニューを使用して、コンピューティングエンジン-VMインスタンスに移動します。
worker-1-server-vmの横にあるボックスを選択し、実行を停止します。
VM instancesページを更新し、サーバーの実行が停止したことを確認するまで待ちます。
プロジェクトのドロップダウンを使用してMonitoring Projectに切り替え、Monitoringへ移動します。その後、Uptime check-Frontend's serverへ移動します。
Current StatusとPassed Checksチャートを調べます。失敗が表示され始めるまでに1分かかる場合があります。
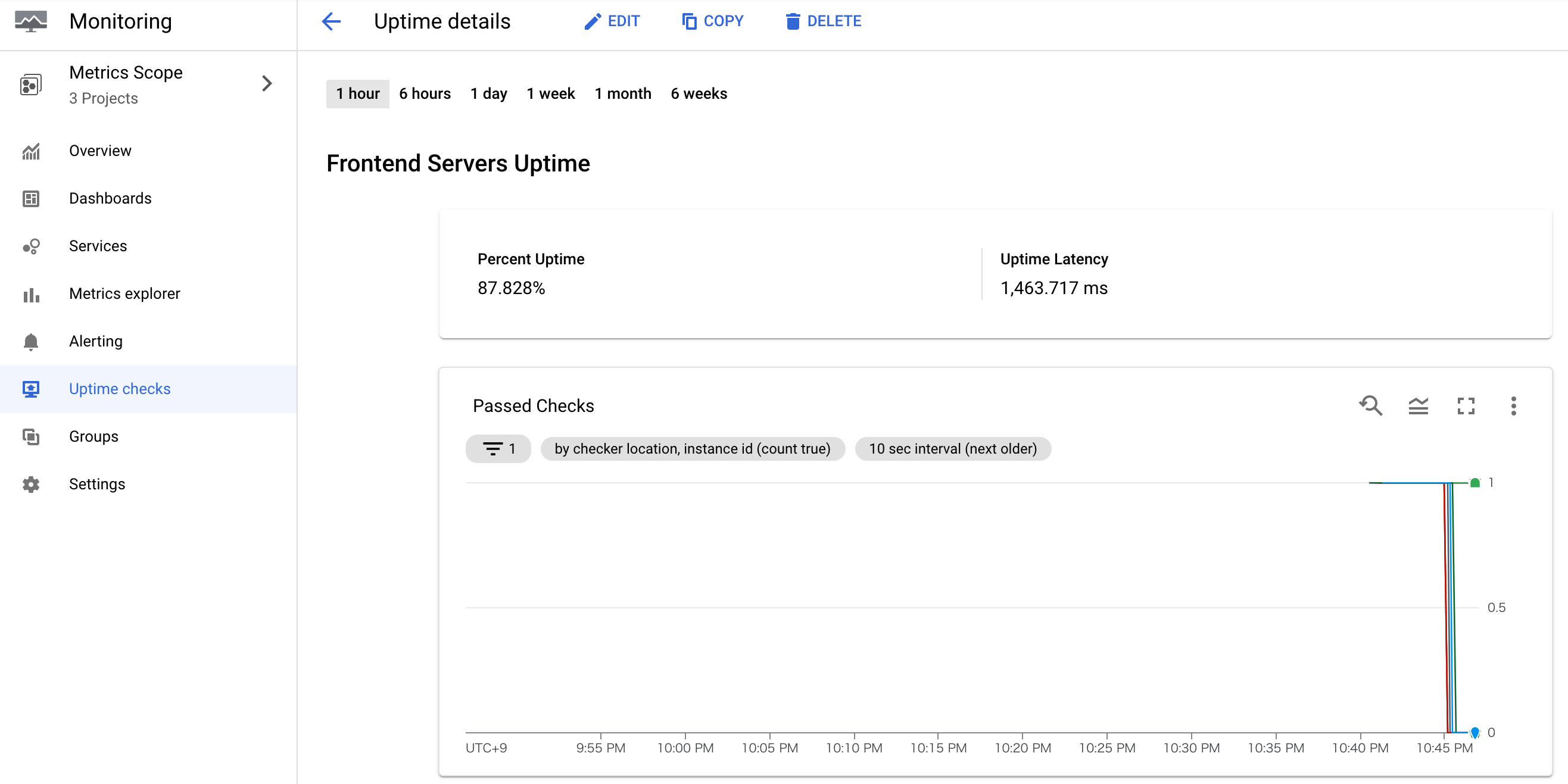
####Monitoring,Logging,Alertについて
Monitoring-Metric Explorerに移動します。
下の検索ボックスにFind resource type and metric、Passed_checkと入力/選択します。
ちなみに、Check passメトリックを調査した後、「uptime_check」を検索すると、調査したい他のメトリックがいくつか表示されます。
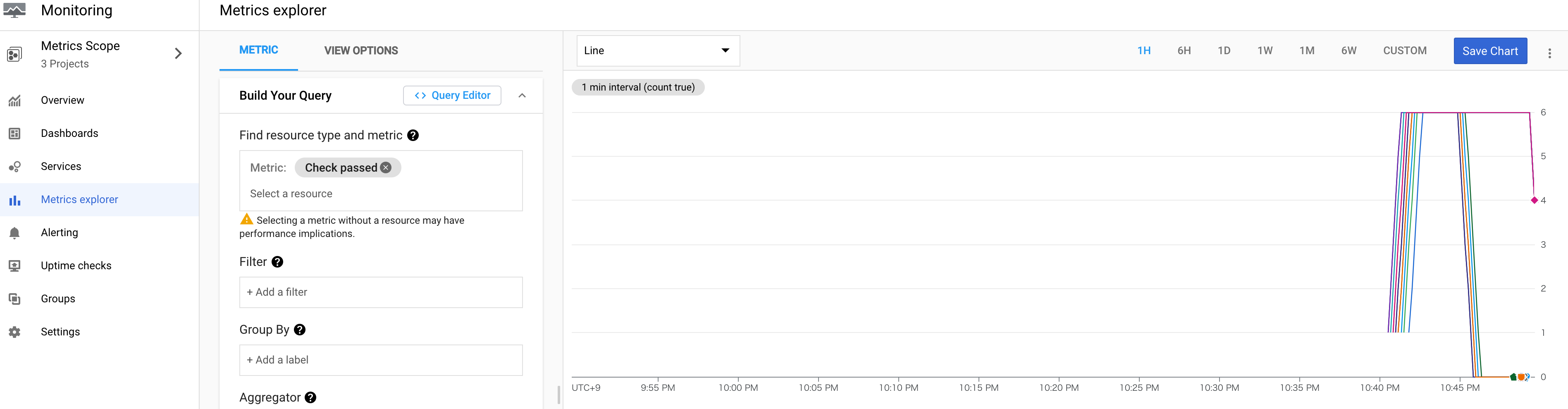
Group Byには、check_id(スクロールが必要な場合があります)を設定して、サーバーごとにチェック結果をグループ化します。
結果を確認してください。
ナビゲーションメニューを使用して、Logging-Log Explorerに移動します。
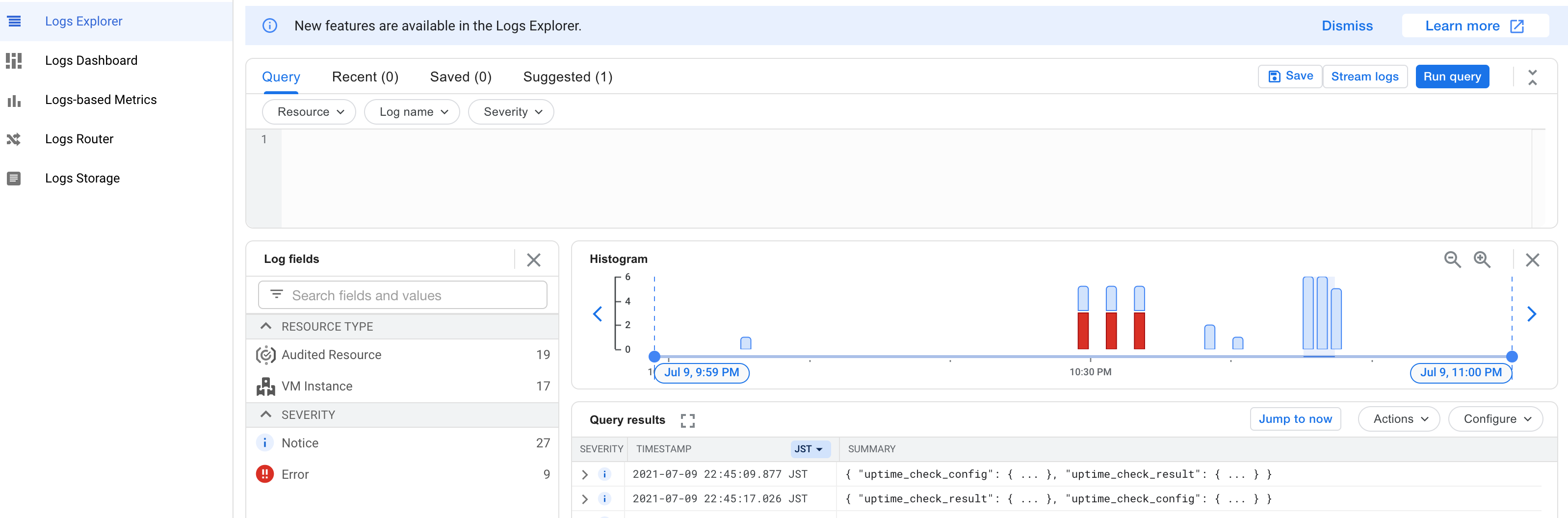
クエリウィンドウをクリックして、そこにあるものをすべて削除します。[ログ名]をクリックします。uptime_checksログを見つけて追加し、[クエリの実行]を選択します。
ナビゲーションメニューを使用して、Monitoring-Alertに移動します。
発砲アラートを調査します。通知チャネルとして自分を追加した場合は、電子メールを確認してください。
##⑤カスタムダッシュボードを作成する
開発者ダッシュボードを作成し、それに稼働時間チャートを追加します
開発者のWebサーバーで何が起こっているかに興味がある場合は、その単一のサーバー専用のグラフのダッシュボードがあると便利です。このセクションでは、稼働時間チェックの要約グラフを使用してダッシュボードを作成します。
ナビゲーションメニューを使用して、GoogleCloudホームページに移動します。
プロジェクトのドロップダウンを使用して、Worker 1プロジェクトに切り替えます。
ナビゲーションメニューを使用して、コンピューティングエンジン-VMインスタンスに移動します
worker-1-server-vmの横にあるボックスを選択し、実行を開始します。
プロジェクトのドロップダウンを使用してMonitoring Projectに切り替え、Monitoring-Dashboardに移動します。
ページの上部で、+ CREATEDASHBOARDを押します。
[新しいダッシュボード名]に、「Developer's Frontend」と入力します。
折れ線グラフをクリックします。
ADVANCEDをクリック。
チャートタイトル=Dev Server Uptime
リソースタイプ=VM Instance
メトリック=check_passed
ADD FILTERをクリック。
ラベル=instance_id
値=Select from dropdown
[完了]をクリックします。
Count trueにし、調整期間を5 minutesにします。
ダッシュボードにCPU使用率チャートを追加してテストします。
開発サーバー内で何が起こっているかについてのもう1つの重要な情報は、CPU負荷です。全体として、NGINXサーバー自体で何が起こっているのかを知ることは素晴らしいことですが、ロギングエージェントとモニタリングエージェントをインストールしないと、まだそれを行うことはできません。
ダッシュボードの一番上の右クリックから自動更新をオンにします。
ダッシュボードに別のグラフを追加します。折れ線グラフを押します。
ADVANCEDをクリック。
Resource typeでは、[ VMインスタンスの選択]を選択します。
Metricでは、[ CPU使用率の選択]を選択します。
ADD FILTERをクリック。
ラベル=instance_name
値=worker-1-server-vm
プロジェクトのドロップダウンを使用して、Worker 2プロジェクトに切り替えます。
worker-2-server-vmにSSHで接続します。
サーバーのパッケージデータベースを更新し、apache2-utilsをインストールします。Apache Benchは、HTTPロードを生成するために使用できるすばやく簡単なツールです。
$ sudo apt-get update
$ sudo apt-get install apache2-utils
ベンチを使用する前に、サーバーへのURLを設定してください。worker-1-server-vmノートファイルで外部IPを見つけ、それを使用して以下のURL環境変数を作成します。「http://」は省略しないでください。
$ URL=http://[worker-1-server-vmのip]
サーバーに負荷をかけます。次のコマンドは、一度に100リクエストを実行し、合計100,000リクエストまで実行し続けます。
$ ab -n 100000 -c 100 $URL/
Benchが実行を終了したら、1分ほど待ってから、以下を実行します。
$ ab -n 500000 -c 500 $URL/
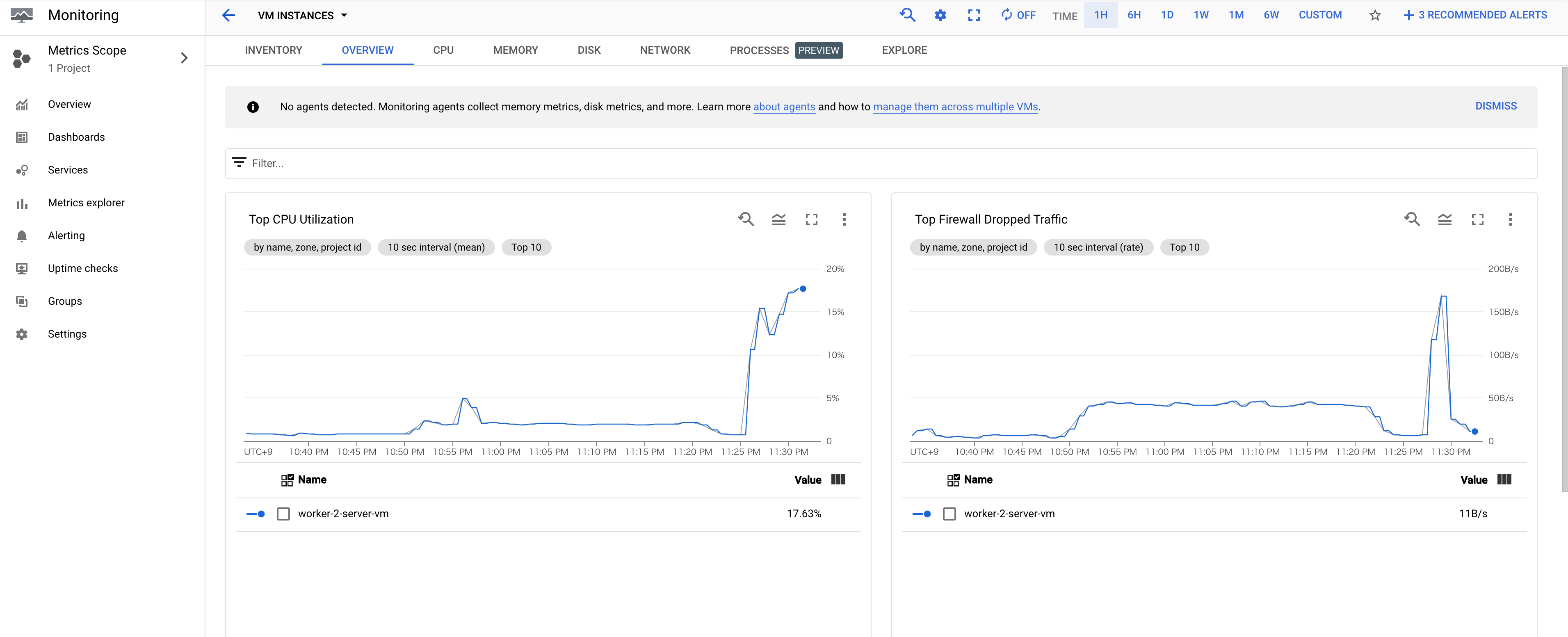
2番目の一連のトラフィックが生成されている間に、ダッシュボードに戻ります。
しばらくすると、CPU負荷に2つの明確なスパイクが見られます。