 はじめに
はじめに
こんにちは。株式会社アベリオシステムズでエンジニアをやっている、なかざとです![]()
今回、DynamoDBについて学ぶ機会がありましたので、アウトプットしていきたいと思います。
 DynamoDBとは?
DynamoDBとは?
DynamoDB自体聞いたことがない方もいるかもしれないので、まずは公式説明から...
Amazon DynamoDB は、サーバーレスのフルマネージド分散 NoSQL データベースで、あらゆる規模で 1 桁ミリ秒のパフォーマンスを実現します。
DynamoDB を使用すると、リレーショナルデータベースのスケーリングと運用の複雑さの課題に対応できます。DynamoDB は、あらゆる規模で一貫したパフォーマンスを必要とするオペレーションワークロード向けに構築され、最適化されています。例えば、DynamoDB は、10 ユーザーの場合でも 1 億ユーザーの場合でも、ショッピングカートのユースケースで一貫した 1 桁ミリ秒のパフォーマンスを提供します。2012 年にリリースされた DynamoDB は、コストの削減と大規模運用におけるパフォーマンスの向上を実現しながら、リレーショナルデータベースからの移行を支援し続けています。
DynamoDB を使用して、すべての規模、業界、地域のお客様が、小規模から始めてグローバルにスケールできる最新のサーバーレスアプリケーションを構築しています。DynamoDB は、ほぼすべてのサイズのテーブルをサポートするようにスケールしながら、一貫した 1 桁ミリ秒のパフォーマンスと高可用性を提供します。
Amazon プライムデーなどのイベントの場合、DynamoDB は、Alexa、Amazon.com サイト、すべての Amazon フルフィルメントセンターなど、トラフィックの多い複数の Amazon の施設とシステムを強化します。このようなイベントでは、DynamoDB API は、Amazon の施設とシステムからの数兆にもおよぶ呼び出しを処理してきました。DynamoDB は、ピークトラフィックが 1 秒あたり 50 万件を超えるテーブルで、数百人ものお客様に継続的にサービスを提供しています。また、テーブルサイズが 200 TB を超える数百のお客様に対応し、1 時間あたり 10 億件を超えるリクエストを処理します。
結構長いですが、主に以下の特徴があると思って頂ければと思います。
- フルマネージド型のNoSQLデータベース
- サーバーレス
- スケーラブル
- 高い可用性
- 無制限のストレージ容量
まずはこれらについて、説明していきます![]()
フルマネージド型のNoSQLデータベース
DynamoDBはフルマネージド型のNoSQLデータベースです。
フルマネージドとは、サーバーのプロビジョニング、パッチ適用、クラスター管理などを利用者が行わずに済むサービスのことを指します。
面倒な部分を全てAWSに任せることにより、本来の設計/開発に集中することが出来ます。
次にNoSQLですが、Not Only SQLの略で、このSQLとはRDBを指します。
つまりNoSQLは、特定のデータベースの種類というよりも、RDB以外のデータベース全般を意味します。
DynamoDBだけのことを指すわけではありません...![]()
NoSQLの主な種類
NoSQLデータベースとしていくつか種類があるのですが、DynamoDBはキーバリュー型になります。
その名の通り、シンプルなキーとバリューの組み合わせでデータを管理します。
複雑なスキーマを持たないため、データを柔軟に格納できます。
また、データの読み込みや書き込み処理がシンプルなため、高速なパフォーマンスを実現できます。
その反面、SQLを使った高度な検索が行えないため、複雑で定形的な構造を持つデータの格納には向きません。
以下、NoSQLの種類と代表的なサービスになります。
| 種類 | 説明 | 代表的なサービス |
|---|---|---|
| キーバリュー型 | キーに対して値を格納するシンプルな構造 | DynamoDB, Redis, Memcached |
| ドキュメント型 | JSON/BSONなどの構造化ドキュメントを格納 | MongoDB |
| カラム指向型 | 列指向でデータを格納し、大規模分析に適する | Apache Cassandra |
| グラフ型 | ノードとエッジでデータ間の関係を表現 | Amazon Neptune |
サーバーレス
DynamoDBはサーバーレスサービスです。
サーバーレスとは、インフラストラクチャを意識せず利用できるサービスのことです。
たまに間違える方がいますが、正しくは
![]() サーバーがない
サーバーがない
![]() サーバーを意識する必要がない
サーバーを意識する必要がない
になります。
スケーラブル
DynamoDBは、1桁ミリ秒の一貫した低レイテンシーを実現します。
RDBだとデータ量が膨大になってくるとクエリ実行時間が長くなりがちですが、DynamoDBはデータ量が膨大になっても変わらず高い読み取り/書き込みパフォーマンスを発揮すること出来ます。
テーブルを複数のパーティションに水平スケールすることでパフォーマンスを維持します。
この高いスケーラビリティによって、DynamoDBは1日あたり10兆以上(ピーク時には、1秒あたり2,000 万以上)のリクエストを1桁ミリ秒という速度で処理します。
データを分散保存するために最低限必要なパーティションの個数は、テーブルのサイズとスループットで決まります。
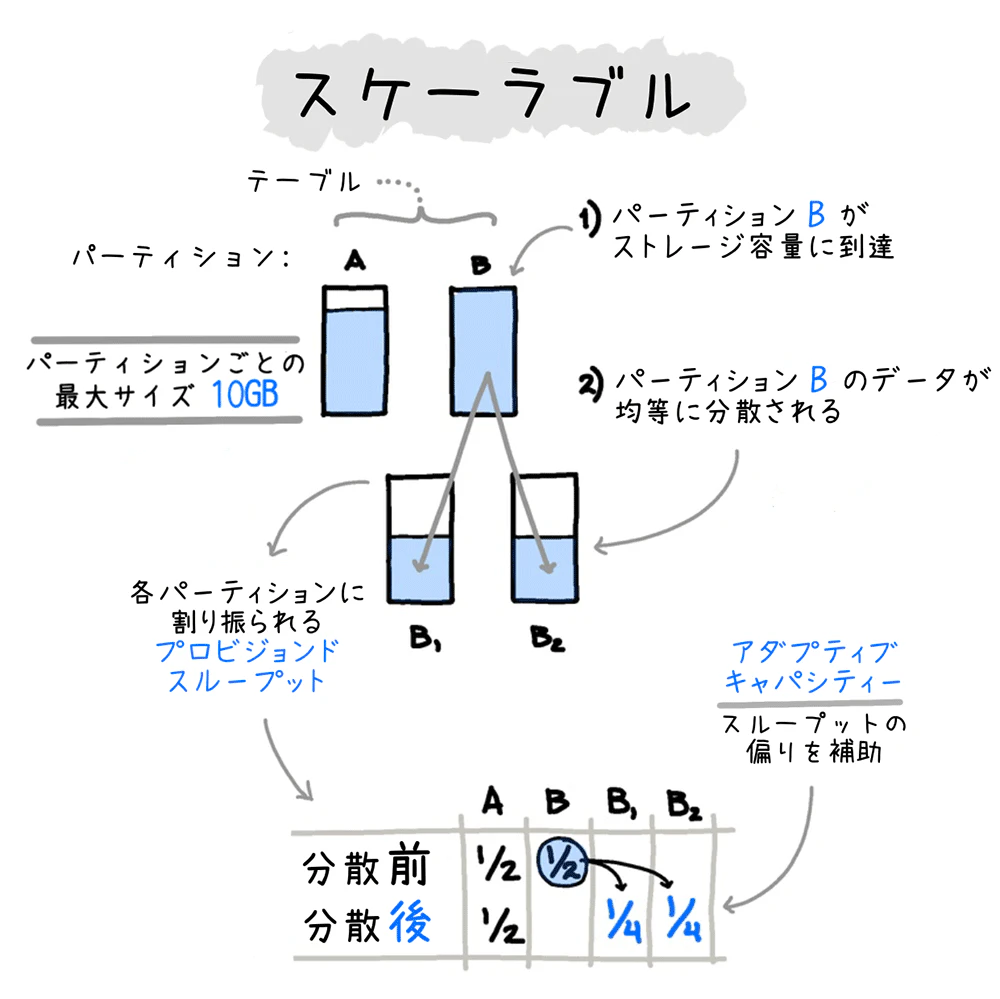
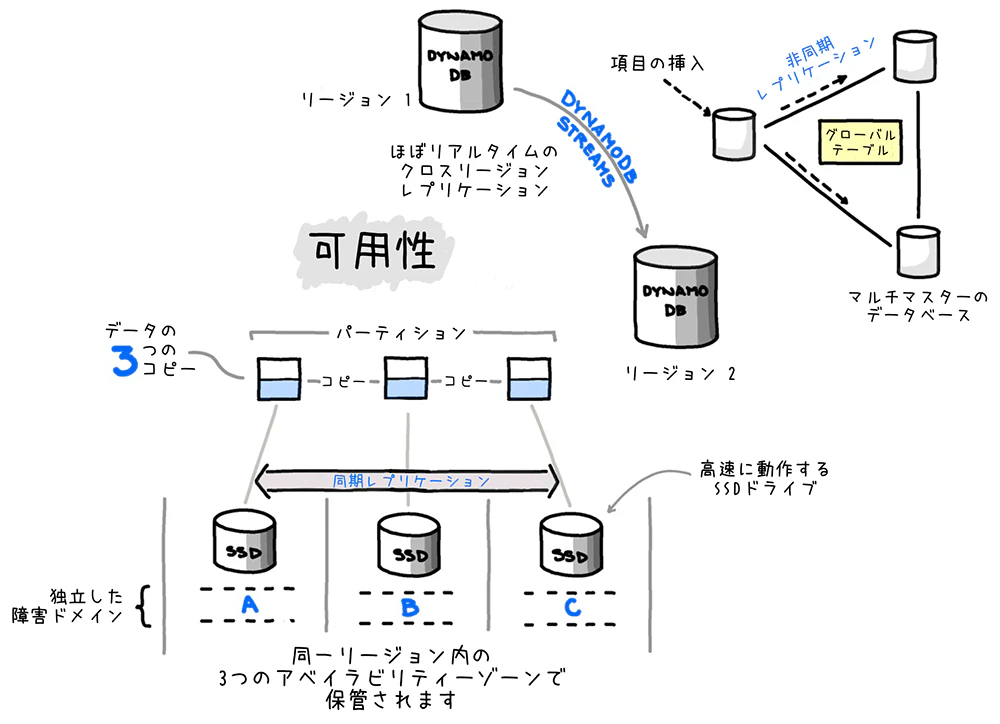
高い可用性
同一リージョン内の3つのAZにデータを自動レプリケーションすることで、最大99.999%の可用性を実現します。
無制限のストレージ容量
テーブルサイズとスループットに実質的な上限がないので、大容量データも保存できます。
※1アイテム毎のが制限あります
ユースケース
Dynamoの概要を説明してきましたが、実際DynamoDBはどんな場合に使われるのでしょう?
よく使われるのは、金融、注文、ゲーム、ストリーミングなどリアルタイム性や高いスケーラビリティが求められるケースです。
私はやったことないですが、モンスターハンターライダーズにも使われているらしいです🎮
DynamoDBと以下のゲームの特徴がマッチしているため、オンラインゲームで使われることが多いです。
- Key Valueデータベース:データベースのキーはほとんどがプレイヤーID
- 高いスケーラビリティ:時間帯でプレイヤー数が大幅に変化する
- サーバレスによる低い管理負担:ゲームの面白さを作ることに集中できる
他にもDynamoDBが適しているケース、逆に適していないケースがあるので簡単に紹介します。
※説明でPKとSKとか出てきますが、いったん気にしないで読み進めてください![]()
DynamoDBが適しているケース
セッション管理
ログインユーザの認証情報管理をする際はDynamoDBやRedisが適しています。
認証処理は処理速度が求められるため、RDBではなくNoSQLを使って高速な読み書きをするケースが多いです。
PK: SessionId
属性: UserId, ExpirationTime (TTL), SessionData
IoTデータ
大量のIoTデバイスから、機器情報が高頻度で上がってくるケースではDynamoDBが適しています。
PK: DeviceId
SK: Timestamp
属性: Temperature, Humidity, Batteryなど
ゲームのリーダーボード
リアルタイムで順位やスコアが入れ替わるゲームのリーダーボードの更新/取得にはDynamoDBが適しています。
PK: GameId
SK: Score (数値)
GSI: PK=GameId, SK=Score(降順検索用)
ショッピングカート
オンラインショッピングでカートに出し入れしたりする際には、低レイテンシーが求められるのでDynamoDBが適しています。
PK: UserId
SK: ProductId
属性: Quantity, AddedAt
ユーザープロファイル
ユーザ情報に関してはRDBで管理することも多いですが、一般的なユーザ情報を管理し、ユーザIDでシンプルに取得する場合はDynamoDBで管理する方がパフォーマンス的に良さそうです。
PK: UserId
属性: Name, Email, Preferences (Map型)など
リアルタイムイベント処理
登録/更新/削除されたデータをリアルタイムに処理するようイベント駆動型アプリケーションを作る場合には、DynamoDBが適しています
後述するDynamoDB Streamsを合わせて利用します。
PK: EventType
SK: Timestamp
DynamoDBが適さないケース
| ケース | 理由 | 代替サービス |
|---|---|---|
| 複雑な結合クエリ | JOINがサポートされていない | RDS |
| OLAP分析(集計・レポート) | 集計操作が非効率 | Amazon Redshift, Athena |
| 全文検索 | テキスト検索機能がない | Amazon OpenSearch |
| 頻繁なスキーマ変更を伴うプロトタイプ | テーブル再設計のコストが高い | MongoDB (DocumentDB) |
| BLOBストレージ(大容量バイナリ) | アイテムサイズ上限400KB | Amazon S3 |
| 強い整合性が全操作に必要 | 結果整合性がデフォルト | RDS |
RDBとの比較
では、これから実際にテーブル設計をするにあたって、覚えておくべきポイントを紹介します!
まず、気になるのはRDBと何が違うんだ?っていうところですよね![]()
まず、よく使う用語の比較になります。
| RDB | DynamoDB |
|---|---|
| データベース | なし |
| テーブル | テーブル |
| 行 | アイテム |
| カラム | 属性 |
次に、主な機能的な違いになります。
| RDB | DynamoDB |
|---|---|
| 固定スキーマ | スキーマレス |
| 垂直スケール中心 | 水平スケール |
| データ量増加で性能劣化の可能性 | データ量に関わらず一桁msのレイテンシ |
| 柔軟なクエリ | PK/GSI/SLIベースのみの単純クエリ |
| joinサポートする | joinサポートしない |
| 強い整合性 | 結果整合性(デフォルト)、強い整合性 |
| DB制約で冪等性を担保しやすい | アプリケーション側で冪等性を考慮する必要がある |
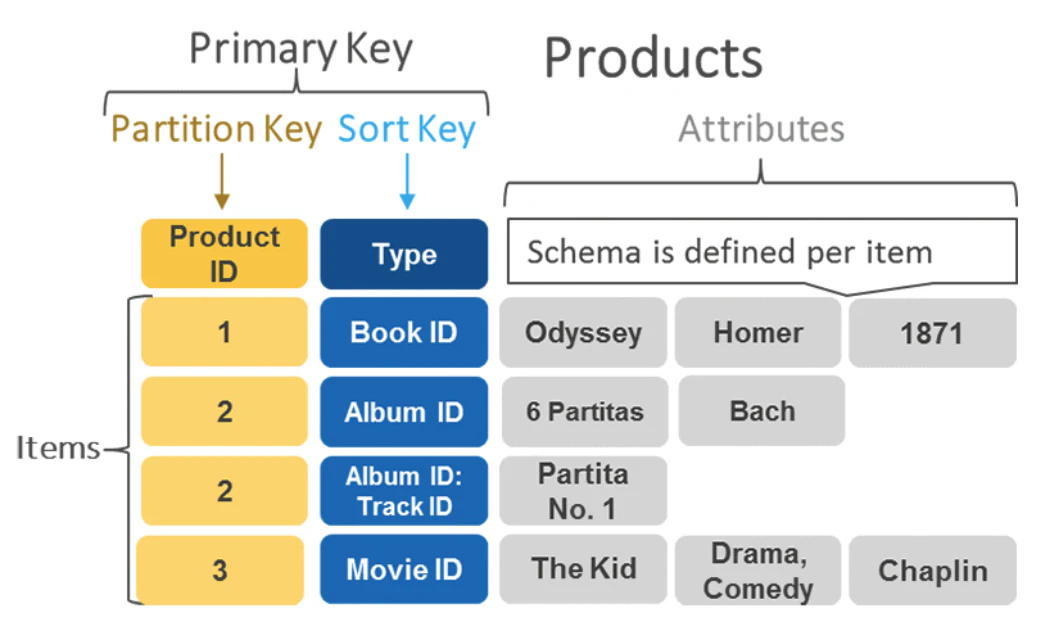
データベース
DynamoDBにはデータベースというものは存在しません!DynamoDBなのにDBがないのはちょっと違和感ありますね![]()
テーブル
データを格納するテーブルです。
RDBではデータベースを作ってその中にテーブルを作りますが、DynamoDBではテーブル毎に管理することになります。
テーブル作成時に定義が必要なのは プライマリキーのみです
アイテム
テーブル内の個々のレコードのことで、各アイテムはプライマリキーによって一意に識別されます。
アイテムの最大サイズは 400KBで、これ以上のレコードを登録することは出来ません。
スキーマレスなので、アイテムごとに異なる属性を持つことが可能です。
ここがRDBと大きく違うため混乱するポイント、かつ、DynamoDBの醍醐味と言えるでしょう ![]()
属性
アイテムの各値を登録するカラムのことです。
各アイテムでどんな属性を登録するかは自由に設定できます。
// アイテム1
{
"UserId": "U001",
"Name": "田中太郎",
"Email": "tanaka@example.com",
"Text": 30
}
// アイテム2(アイテム1とは異なる属性、異なる型を持っている)
{
"UserId": "U002",
"Name": "鈴木花子",
"Phone": "090-1234-5678",
"Text": "東京都渋谷区"
}
結果整合性/強い整合性
結果整合性とは、書き込み後、すべてのレプリカに反映されるまで少し時間がかかる。最終的には一致することを言います。
強い整合性とは、書き込み後、即座にすべての読み取りが最新データを返すことを言います。
DynamoDBでは、読み取り時にこれらを考慮する必要があります。
デフォルトでは結果整合性での読み取りになりますが、強い整合性で読み取ることが出来ます。
だったら、全部強い整合性で読み取ればいいじゃんって思うかもしれませんが、操作によっては結果整合性でしか読み取れなかったり、コストが倍かかったりします。
なので、基本的には結果整合で読み取りつつ、必要に応じて強い整合性にするのが良いと思います。
| 読み取り方式 | 整合性 | コスト | ユースケース |
|---|---|---|---|
| GetItem(デフォルト) | 結果整合性 | 0.5RCU / 4KB | 多少の遅延が許容できるデータ(一覧表示、キャッシュ等) |
| GetItem + ConsistentRead: true | 強い整合性 | 1RCU / 4KB | 書き込み直後に最新を読む必要があるデータ(在庫、残高等) |
| Query / Scan | どちらも可 | 1RCU / 4KB | |
| GSI | 結果整合性のみ | GSIでは強い整合性を選べない | |
| LSI | どちらも可 |
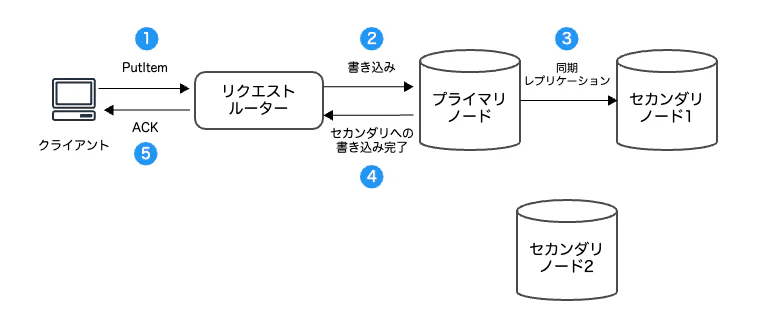
データは3AZに分散された各ノードへ反映されますが、実際には2AZに反映したらクライアント側には完了を返します。
非同期で3つ目のノードへも反映するのですが、結果整合性での読み取りだとまだ反映されていないノードからデータを取得しようとすることがあるため、最新状態ではない可能性があります。
強い整合性だと、必ずプライマリーノードからデータを取得するため必ず最新情報が取得することが出来ます。
冪等性
サーバーレスアプリケーションで考慮する必要があるのが、冪等性です。
冪等性とは、何回実行しても実行結果が同じ状態になることです。
サーバーレスアプリケーションでは、自動リトライを搭載したLambdaなどを利用するので、同じ処理が複数回実行する可能性があります。
なので、考慮できていないと同じデータが複数個登録されたり、複数回同じメールが送信されるなどが起きてしまいます。
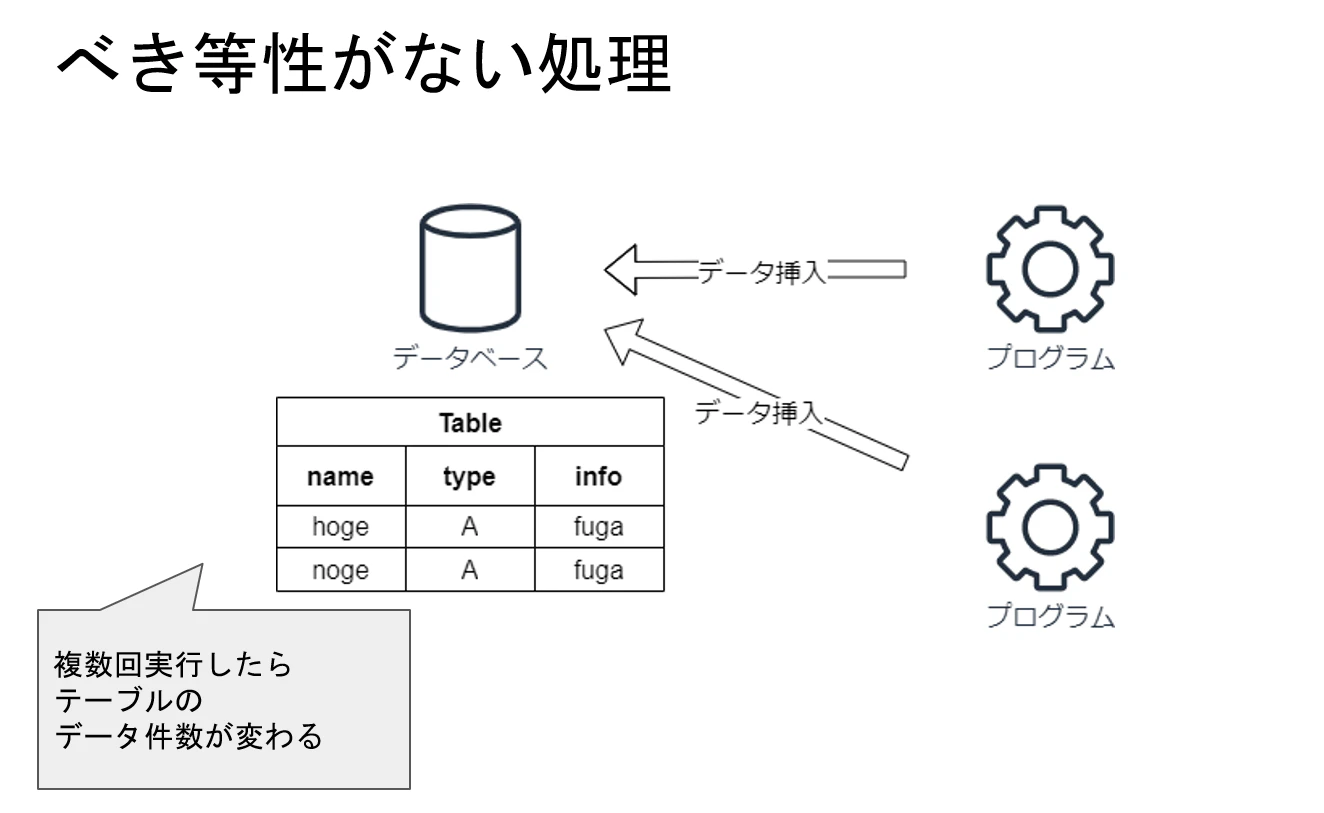
DynamoDBでは、
- 同じPKのデータが既に存在するなら書き込まないような条件(ConditionExpression attribute_not_exists(PK))を加える ※UUIDなどPKの値が実行毎に毎回変わる場合は難しい
- 毎回上書きする
などで、何回実行されても問題ないような作りにする必要があります。
プライマリーキーの設計
DynamoDBにはRDBと同様、プライマリーキーがあり、さらに設定の仕方として2種類あります。
他の属性は事前設定不要なので、プライマリーキーの貼り方がテーブル設計の全てと言っても過言ではありません!!!
単純キー
パーティションキーのみで構成します。
パーティションキーだけでアイテムを一意に識別できる場合は、こちらにします。
テーブル: Users
プライマリキー: UserId (パーティションキー)
| UserId (PK) | Name | Email |
|-------------|------------|----------------------|
| U001 | 田中太郎 | tanaka@example.com |
| U002 | 鈴木花子 | suzuki@example.com |
複合キー
パーティションキー + ソートキーで構成します。
パーティションキーとソートキーの組み合わせでアイテムを一意に識別する場合は、こちらにします。
同じパーティションキーのアイテムを複数格納でき、ソートキーで範囲検索が可能
テーブル: Orders
プライマリキー: UserId (PK) + OrderDate (SK)
| UserId (PK) | OrderDate (SK) | Amount | Status |
|-------------|--------------------|--------|----------|
| U001 | 2025-01-15T10:00Z | 3000 | shipped |
| U001 | 2025-02-20T14:30Z | 5500 | pending |
| U002 | 2025-01-10T09:00Z | 1200 | delivered|
パーティションキーとソートキーがいきなり出てきてよくわからない気もするので、もう少し説明していきます。
パーティションキー
- テーブルに必須のキー属性です
- DynamoDBは内部的にパーティションキーの値をハッシュ関数に通し、データの物理的な保存場所(パーティション)を決定します
- 単純キーのテーブルの場合は、パーティションキーの値は一意でなければなりません。
- 高いカーディナリティ(値の種類が多い)が望ましいです
ソートキー
- 任意で追加できるキー属性です
- 同じパーティションキーを持つアイテムの中で、ソートキーの値で順序付けされます
- ソートキーを設定することで、RDBで行うような範囲検索(begins_with, betweenなど)が可能になります
パーティションキーのみ:
PK = "UserId" → 各ユーザーを一意に識別
パーティションキー + ソートキー:
PK = "UserId", SK = "OrderDate" → 特定ユーザーの注文を日付順に取得
GSI/ LSI
RDBと違いDynamoDBでは、プライマリーキーに設定した属性での条件検索しか行うことが出来ません。
それ以外の条件で検索したい場合、Scanという非常にコスト/処理パフォーマンスが悪い呼び出しになってしまいます。
それだと色々困るなーって感じなんですが、GSI/LSIというインデックス機能で条件検索を行うことが可能になります。
GSI(Global Secondary Index)
- テーブルとは異なるパーティションキーとソートキーを定義できる
- 元のテーブルとは別のGSI用のテーブルが別途作られる
- テーブル作成後にも追加可能
- テーブルあたり最大20個作成可能
- 結果整合性の読み込みのみサポート
- 非同期で更新される(ので遅延あり)
- GSI毎にキャパシティを設定する
- 射影に設定した属性のみ取得できる
例:
元テーブルのキー: PK = UserId, SK = OrderDate
GSIのキー: PK = Status, SK = OrderDate
→ 注文ステータスでの検索が可能になる
LSI(Local Secondary Index)
- パーティションキーはテーブルと同じで、ソートキーのみ異なる
- 単一プライマリーキーのテーブルの場合は、LSIは作成できない
- GSIとは違いLSI用のテーブルは作られず、パーティションへのリンクが作られるイメージ
- テーブル作成時にのみ定義可能(後から追加不可)
- テーブルあたり最大5個作成可能
- 強い整合性の読み込みをサポート
- 同期的に更新される
- テーブルのキャパシティユニットを消費する
- 射影に設定した属性以外も取得できる(コストは高くなる)
例:
元テーブルのキー: PK = UserId, SK = OrderDate
LSIのキー: PK = UserId, SK = Amount
→ 同じユーザーの注文を金額順でソートして取得可能
射影
さらっと射影が説明で出てきましたが、もう少し詳しく説明します。
射影は、テーブルからGSI/LSIにコピーされる属性のセットです。
テーブルのパーティションキーとソートキーは常にインデックスに射影されます。
GSI/LSIにクエリを実行すると、その属性が自身のテーブル内にあるかのように、任意の属性にアクセスできます。
GSI/LSIを作成するときは、インデックスに射影される属性を指定する必要があり、3つのオプションがあります。
KEYS_ONLY:パーティションキーとソートキーの値、GSI/LSIの値のみで構成されます。
よって、セカンダリインデックスが最小になります。
INCLUDE:KEYS_ONLYの属性に加えて、その他の属性を含まれるように指定できます
ALL:全ての属性が含まれます。
全てのデータがインデックスに複製されるため、セカンダリインデックスが最大になります。
つまり、ALLでGSIを作成すると、作るたびにデータ量が倍になっていきます。
キャパシティユニット
DynamoDBでは書き込みと読み込みの性能をキャパシティユニットという単位で換算します。
キャパシティユニットには、以下の2つの種類があります。
- RCU(Read Capacity Unit):読み込みキャパシティユニット
- WCU(Write Capacity Unit):書き込みキャパシティユニット
また、DynamoDBには2つのキャパシティモードがあります。
RCU / WCU の計算
RCU(Read Capacity Unit)
| 読み取りタイプ | 1 RCU あたり |
|---|---|
| 強い整合性のある読み込み | 最大 4KB のアイテムを 1秒に1回 |
| 結果整合性のある読み込み | 最大 4KB のアイテムを 1秒に2回 |
| トランザクション読み込み | 最大 4KB のアイテムを 1秒に0.5回(2 RCU必要) |
計算例:
- アイテムサイズ: 6KB
- 強い整合性の読み込み: 毎秒100回
- 必要RCU = ceil(6 / 4) × 100 = 2 × 100 = 200 RCU
WCU(Write Capacity Unit)
| 書き込みタイプ | 1 WCU あたり |
|---|---|
| 標準書き込み | 最大 1KB のアイテムを 1秒に1回 |
| トランザクション書き込み | 最大 1KB のアイテムを 1秒に0.5回(2 WCU必要) |
計算例:
- アイテムサイズ: 3KB
- 毎秒50回の書き込み
- 必要WCU = ceil(3 / 1) × 50 = 3 × 50 = 150 WCU
オンデマンドモード
| 項目 | 内容 |
|---|---|
| 課金方式 | 実際に処理した読み書きリクエスト数に応じた従量課金 |
| キャパシティ管理 | 不要(自動スケーリング) |
| 適したケース | トラフィックが予測困難、スパイクがある、新規アプリケーション |
| コスト | リクエスト単価はプロビジョンドモードより高い |
オンデマンドは使った分だけ課金ですが、使えることを保証してくれるわけではないです![]()
なので、スロットルが起こる可能性があります
プロビジョンドモード
| 項目 | 内容 |
|---|---|
| 課金方式 | 事前に設定したキャパシティユニット数に応じた時間課金 |
| キャパシティ管理 | RCU/WCUを事前に設定(Auto Scaling併用可) |
| 適したケース | トラフィックが予測可能、安定したワークロード |
| コスト | オンデマンドよりリクエスト単価が安い |
Auto Scaling
プロビジョンドモードで利用可能なオートスケーリング機能です。
他のAWSサービスのオートスケーリングと同じようなイメージでOKです!
設定項目
- 最小キャパシティ: スケールダウンの下限
- 最大キャパシティ: スケールアップの上限
- ターゲット使用率: この使用率を維持するようにスケーリング(例: 70%)
設定例:
最小RCU: 5
最大RCU: 1000
ターゲット使用率: 70%
→ 使用率が70%を超えるとスケールアップ
→ 使用率が70%を下回るとスケールダウン
- スケールアップには数分かかる場合がある
- 急激なトラフィック増加には対応しきれない(が、バーストキャパシティ)で自動対応される
型
DynamoDBは以下の3カテゴリのデータ型をサポートしています。
パーティションキーとソートキーの属性に指定できるのは、スカラー型の文字列・数値・バイナリのみです
スカラー型
1つの値のみを表すデータ型です
※RDBの型と似ていると思います
| データ型 | 説明 | 例 |
|---|---|---|
| S(String) | 文字列 |
"Hello", "2025-01-01"
|
| N(Number) | 数値(整数・浮動小数点) |
42, 3.14, -100
|
| B(Binary) | バイナリ(Base64エンコード) | 画像データ、圧縮データ |
| BOOL(Boolean) | 真偽値 |
true, false
|
| NULL | 値が存在しないことを表す | null |
{
"Name": {"S": "田中太郎"},
"Age": {"N": "30"},
"IsActive": {"BOOL": true},
"ProfileImage": {"B": "dGhpcyBpcyBhIHRlc3Q="},
"DeletedAt": {"NULL": true}
}
ドキュメント型
ネストされた複雑な構造を表現できるデータ型です
Map(M)
- JSONオブジェクトに相当
- キーと値のペアのコレクション
- ネスト可能(最大32レベル)
{
"Address": {
"M": {
"Prefecture": {"S": "東京都"},
"City": {"S": "渋谷区"},
"ZipCode": {"S": "150-0001"}
}
}
}
List(L)
- JSON の配列に相当
- 順序付きのコレクション
- 異なるデータ型の要素を含められる
{
"Tags": {
"L": [
{"S": "technology"},
{"S": "aws"},
{"N": "2025"}
]
}
}
セット型
同じデータ型の値の集合を表すデータ型です。重複する値は許可されません
| データ型 | 説明 | 例 |
|---|---|---|
| SS(String Set) | 文字列のセット | ["red", "blue", "green"] |
| NS(Number Set) | 数値のセット | [1, 2, 3, 4, 5] |
| BS(Binary Set) | バイナリのセット | バイナリ値のセット |
{
"Hobbies": {
"SS": ["読書", "映画鑑賞", "プログラミング"]
},
"Scores": {
"NS": ["85", "90", "78"]
}
}
セット型の特徴
- 重複不可: 同じ値を複数含められない
- 空のセットは不可: 少なくとも1つの要素が必要
- 順序なし: 要素の順序は保証されない
- 同一型のみ: 1つのセットに異なるデータ型を混在できない
TTL(Time To Live)
TTLを使用すると、有効期限が切れたアイテムを自動的に削除できます。
テーブルのTTL属性を有効にし、任意の属性名を指定します。
各アイテムにUNIXエポック秒(秒単位のタイムスタンプ)を設定することで、その時間になったタイミングでアイテムが削除されます
アイテムが削除されたら、何か処理をしたいような場合は後述のDynamoDBStreamsと連携することで、可能になります。
有効期限が切れてから数日以内に行われる、と公式に記載がある通り、必ずしもTTLの時間に削除されるとは限らないようです。
なので、確実に指定した時間に削除したい場合は、自前で実装する必要があります![]()
APIの種類
Dynamoでデータを操作する際のAPIを紹介します!
PutItem — アイテムの作成・置換
新しいアイテムをテーブルに追加します。
同じプライマリキーのアイテムが既に存在する場合は上書きされます。
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Users')
table.put_item(
Item={
'UserId': 'U001',
'Name': '田中太郎',
'Email': 'tanaka@example.com',
'Age': 30
}
)
GetItem — アイテムの取得
プライマリキーを指定して1つのアイテムを取得します。
response = table.get_item(
Key={
'UserId': 'U001'
}
)
item = response.get('Item')
print(item)
# {'UserId': 'U001', 'Name': '田中太郎', 'Email': 'tanaka@example.com', 'Age': 30}
UpdateItem — アイテムの更新
既存アイテムの特定の属性だけを更新します。
アイテムが存在しない場合は新規作成されます。
table.update_item(
Key={
'UserId': 'U001'
},
UpdateExpression='SET Age = :val, #n = :name',
ExpressionAttributeNames={
'#n': 'Name'
},
ExpressionAttributeValues={
':val': 31,
':name': '田中太郎(更新済)'
}
)
DeleteItem — アイテムの削除
プライマリキーを指定してアイテムを削除します。
table.delete_item(
Key={
'UserId': 'U001'
}
)
Query
- パーティションキーの一致条件を必須として検索する
- ソートキーに対して範囲条件(
=,<,>,between,begins_with)を指定可能 - 効率的:必要なパーティションのみを読み取る
from boto3.dynamodb.conditions import Key
response = table.query(
KeyConditionExpression=Key('UserId').eq('U001') & Key('OrderDate').begins_with('2025-01')
)
items = response['Items']
Scan
- テーブル全体を読み取る
- フィルタ条件を指定できるが、全アイテムを読んでからフィルタする
- 非効率:大量のRCUを消費する
from boto3.dynamodb.conditions import Attr
response = table.scan(
FilterExpression=Attr('Age').gt(25)
)
items = response['Items']
使い分けの指針
| 操作 | 使用場面 | コスト |
|---|---|---|
| Query | 特定のパーティション内のデータ取得 | 低い |
| Scan | テーブル全体のデータ取得(管理目的など) | 高い |
BatchWriteItem
- 最大25件のPutItem/DeleteItemを1回のAPIコールで実行
- 複数テーブルに対して同時に実行可能
- UpdateItem はサポートされていない
with table.batch_writer() as batch:
for i in range(100):
batch.put_item(
Item={
'UserId': f'U{i:04d}',
'Name': f'ユーザー{i}'
}
)
BatchGetItem
- 最大100件のアイテムを1回のAPIコールで取得
- 複数テーブルから同時に取得可能
- 合計サイズは 16MB まで
dynamodb = boto3.resource('dynamodb')
response = dynamodb.batch_get_item(
RequestItems={
'Users': {
'Keys': [
{'UserId': 'U001'},
{'UserId': 'U002'},
{'UserId': 'U003'}
]
}
}
)
条件付き書き込み(ConditionExpression)
条件付き書き込みにより、特定の条件が満たされた場合にのみ書き込み操作を実行できます。
ユースケース
- 楽観的ロック: バージョン番号をチェックして更新
- 重複防止: 同じプライマリキーが存在しない場合のみ挿入
- 条件付き更新: 在庫数が0以上の場合のみ減算
# アイテムが存在しない場合のみ挿入
table.put_item(
Item={
'UserId': 'U001',
'Name': '田中太郎'
},
ConditionExpression='attribute_not_exists(UserId)'
)
# 在庫が足りる場合のみ減算
table.update_item(
Key={'ProductId': 'P001'},
UpdateExpression='SET Stock = Stock - :dec',
ConditionExpression='Stock >= :dec',
ExpressionAttributeValues={
':dec': 1
}
)
条件が満たされない場合はConditionalCheckFailedExceptionの例外が発生します
TransactWriteItems
DynamoDBのトランザクションは、複数のアイテムに対する操作をアトミックに実行します。
- 最大 100件 の書き込み操作を1つのトランザクションで実行
- Put, Update, Delete, ConditionCheck の組み合わせが可能
- 全て成功するか、全て失敗するか(All or Nothing)
- 通常の操作の 2倍 のRCU/WCUを消費
- 読み取り: 4KBごとに2RCU、書き込み: 1KBごとに2WCU
client = boto3.client('dynamodb')
client.transact_write_items(
TransactItems=[
{
'Update': {
'TableName': 'Accounts',
'Key': {'AccountId': {'S': 'A001'}},
'UpdateExpression': 'SET Balance = Balance - :amount',
'ConditionExpression': 'Balance >= :amount',
'ExpressionAttributeValues': {':amount': {'N': '1000'}}
}
},
{
'Update': {
'TableName': 'Accounts',
'Key': {'AccountId': {'S': 'A002'}},
'UpdateExpression': 'SET Balance = Balance + :amount',
'ExpressionAttributeValues': {':amount': {'N': '1000'}}
}
}
]
)
TransactGetItems
- 最大 100件 の読み取り操作を1つのトランザクションで実行
- 取得した全アイテムが同じ時点のスナップショットであることを保証
response = client.transact_get_items(
TransactItems=[
{
'Get': {
'TableName': 'Accounts',
'Key': {'AccountId': {'S': 'A001'}}
}
},
{
'Get': {
'TableName': 'Accounts',
'Key': {'AccountId': {'S': 'A002'}}
}
}
]
)
テーブルの設計思想
では、テーブルの構成要素や実行できる操作がわかったところで、実際どのようにテーブル設計していくか説明していきます。
大事なのはアクセスパターンに基づいてデータモデルを設計するです![]()
RDBではデータの正規化を重視しますが、DynamoDBではどのようにデータにアクセスするかを最初に定義し、それに最適化したデータモデルを設計します。
シングルテーブルデザイン
DynamoDBでは、複数のエンティティ(ユーザー、注文、商品など)を 1つのテーブルに格納する設計パターンが推奨されています。
この時点でRDB経験者は???マークがいっぱいになりそうですね![]()
シングルテーブルデザインが推奨される理由としては以下になります。
- DynamoDBにはJOINがないため、複数テーブルへのクエリは複数回のAPI呼び出しが必要
- 1つのテーブルに関連データを格納することで、1回のクエリで関連データを取得できる
- パフォーマンスとコストの最適化が可能
以下のようなイメージですが、もちろんデメリットもあります。
ただ実際に運用されている現場でも、よほどの大規模ではない限りは、1テーブル(多くても1桁単位)で運用できるらしいです。
DynamoDBはテーブル単位での管理なので、テーブル数が少なければ少ないほど管理が楽になります
テーブル: AppData
PK | SK | Data
--------------|-------------------|------------------
USER#U001 | PROFILE | {Name: "田中", ...}
USER#U001 | ORDER#2025-01-15 | {Amount: 3000, ...}
USER#U001 | ORDER#2025-02-20 | {Amount: 5500, ...}
USER#U002 | PROFILE | {Name: "鈴木", ...}
PRODUCT#P001 | INFO | {Name: "商品A", ...}
| メリット | デメリット |
|---|---|
| 1回のクエリで関連データ取得が可能になる | 設計が複雑になる |
| API呼び出し回数が削減される | 可読性が低下する |
| コストが最適化される | チーム内での学習コストが高い |
アクセスパターンを軸にした設計手法
では実際に、どのようにテーブル設計するか流れを説明していきます。
ステップ1: アクセスパターンの洗い出し
まず、アプリケーションがどのようにデータにアクセスするかアクセスパターンを明確にします。
柔軟なクエリが実行できるRDBとはそもそも違いますよね![]()
例: ECサイトのアクセスパターン
1. ユーザーIDでユーザー情報を取得する
2. ユーザーIDで全注文を取得する
3. ユーザーIDと注文日で特定の注文を取得する
4. 商品IDで商品情報を取得する
5. カテゴリー別に商品を一覧する
6. 注文ステータスで注文を検索する
ステップ2: プライマリキーの設計
アクセスパターンに基づいて、パーティションキーとソートキーを決定します。
ステップ3: セカンダリインデックスの検討
プライマリキーだけでは対応できないアクセスパターンに対して、GSI/LSIを追加します。
ステップ4: 設計の検証
全アクセスパターンが効率的に実行できることを確認します。
RDBからの設計思考の切り替え
RDBに慣れた状態でDynamoDBを設計すると、致命的な問題を引き起こす可能性があります。
ECサイトを例とした6つのアクセスパターンについて、「RDB脳でやるとどう困るか」→「DynamoDBではどう設計すべきか」を説明していきます。
前提: RDB脳で作ってしまった3つのDynamoDBテーブル
RDBの正規化に慣れていると、エンティティごとにテーブルを分けて以下のように設計してしまいがちです。
Usersテーブル
テーブル名: Users(ユーザ)
パーティションキー: UserId
| UserId (PK) | Name | Email | Age |
|--------------|----------|----------------------|-----|
| U001 | 田中太郎 | tanaka@example.com | 30 |
| U002 | 鈴木花子 | suzuki@example.com | 25 |
Ordersテーブル
テーブル名: Orders(注文)
パーティションキー: OrderId
| OrderId (PK) | UserId | Amount | Status | OrderDate |
|---------------|--------|--------|-----------|---------------------|
| ORD001 | U001 | 3000 | shipped | 2025-01-15T10:00Z |
| ORD002 | U001 | 5500 | pending | 2025-02-20T14:30Z |
| ORD003 | U002 | 1200 | delivered | 2025-01-10T09:00Z |
Productsテーブル
テーブル名: Products(商品)
パーティションキー: ProductId
| ProductId (PK) | Name | Category | Price |
|-----------------|-------|-------------|-------|
| P001 | 商品A | electronics | 2000 |
| P002 | 商品B | books | 1500 |
| P003 | 商品C | electronics | 3000 |
この3テーブル構成で、以下の6つのアクセスパターンを実行しようとすると、どんな問題に直面するかを見ていきます![]()
例: ECサイトのアクセスパターン
1. ユーザーIDでユーザー情報を取得する
2. ユーザーIDで全注文を取得する
3. ユーザーIDと注文日で特定の注文を取得する
4. 商品IDで商品情報を取得する
5. カテゴリー別に商品を一覧する
6. 注文ステータスで注文を検索する
パターン1: ユーザーIDでユーザー情報を取得する
RDB脳での設計
Usersテーブルから UserId で取得する
response = users_table.get_item(Key={'UserId': 'U001'})
何が困るか
PKで取得できるため現状特に問題ありません。
※ただし、以降のパターンで問題が発生します
DynamoDBでの正しい設計
シングルテーブルにユーザー情報を格納する。
テーブル名: AppData
| PK (パーティションキー) | SK (ソートキー) | Name | Email | Age |
|--------------------------|-----------------|----------|----------------------|-----|
| USER#U001 | PROFILE | 田中太郎 | tanaka@example.com | 30 |
| USER#U002 | PROFILE | 鈴木花子 | suzuki@example.com | 25 |
response = table.get_item(Key={'PK': 'USER#U001', 'SK': 'PROFILE'})
同じテーブルに注文や商品も入れる準備ができていることが重要です。
パターン2: ユーザーIDで全注文を取得する
RDB脳での設計
Ordersテーブルから UserId = U001 の注文を全部取得する
response = orders_table.query(
KeyConditionExpression=Key('OrderId').eq(???) # ← UserIdで検索できない!
)
何が困るか
パーティションキーが OrderId なので、UserIdでQueryが出来ません![]()
以下の方法で行うことも出来るがどちらも正しくありません。
方法A: Scan(テーブル全件走査)+ FilterExpression
response = orders_table.scan(
FilterExpression=Attr('UserId').eq('U001')
)
| 問題点 | 影響 |
|---|---|
| テーブルの全アイテムを読み取る | 注文が100万件あれば100万件を走査 |
| FilterExpression は読み取り後にフィルタ | RCU(読み取りコスト)は全件分消費される |
| データ量に比例してレイテンシーが増大 | ユーザー体験が著しく悪化 |
| 1回のScanで最大1MBまで | ページネーションが必要で実装が複雑化 |
方法B: GSIを後付けで追加
GSI: パーティションキー = UserId, ソートキー = OrderDate
これで取得できるようになるが、テーブル設計が分かれている問題は解決しません。
ユーザー情報と注文を一緒に取りたいとき、Usersテーブルと Ordersテーブルへの 2回のAPI呼び出しが必要になります
DynamoDBでの正しい設計
ユーザーと注文を同じテーブル・同じパーティションに入れる。
テーブル名: AppData
| PK | SK | Name | Email | Amount | Status | OrderDate |
|---------------|---------------------------|----------|----------------------|--------|-----------|---------------------|
| USER#U001 | PROFILE | 田中太郎 | tanaka@example.com | | | |
| USER#U001 | ORDER#2025-01-15#ORD001 | | | 3000 | shipped | 2025-01-15T10:00Z |
| USER#U001 | ORDER#2025-02-20#ORD002 | | | 5500 | pending | 2025-02-20T14:30Z |
| USER#U002 | PROFILE | 鈴木花子 | suzuki@example.com | | | |
| USER#U002 | ORDER#2025-01-10#ORD003 | | | 1200 | delivered | 2025-01-10T09:00Z |
from boto3.dynamodb.conditions import Key
response = table.query(
KeyConditionExpression=Key('PK').eq('USER#U001') & Key('SK').begins_with('ORDER#')
)
- Scanではなく Query → パーティション内のみ走査するので高速・低コスト
-
JOINなし → ユーザー情報も同じパーティションにあるため、
SK = PROFILEも含めれば1回のQueryで同時取得可能 - ソート済み → SKに日付を埋め込んでいるので、自動的に日付順で返る
パターン3: ユーザーIDと注文日で特定の注文を取得する
RDB脳での設計
前提のOrdersテーブル(PK = OrderId)で、ユーザーID + 注文日で検索する
# ユーザーID + 注文日で検索したい
response = orders_table.query(
KeyConditionExpression=Key('OrderId').eq(???) # ← OrderIdしか指定できない
)
何が困るか
OrderIdがパーティションキーなので、「ユーザーID + 注文日」という複合条件でのQueryが出来ない
# Scanで全件走査してからフィルタ…
response = orders_table.scan(
FilterExpression=Attr('UserId').eq('U001') & Attr('OrderDate').begins_with('2025-01-15')
)
| 問題点 | 説明 |
|---|---|
| Scan + FilterExpression | 全件走査。1件を取得するために100万件を読む可能性 |
| コスト増 | たった1件のために大量のRCUを消費 |
| 設計の限界 | GSIを追加しても、パターンごとにGSIが増え続ける ※GSIの上限20個 |
DynamoDBでの正しい設計
# ソートキーに日付が埋め込まれているので、begins_with で絞り込み
response = table.query(
KeyConditionExpression=Key('PK').eq('USER#U001') & Key('SK').begins_with('ORDER#2025-01-15')
)
取得結果(1件にピンポイント):
| PK | SK | Amount | Status | OrderDate |
|-------------|-------------------------|--------|---------|---------------------|
| USER#U001 | ORDER#2025-01-15#ORD001 | 3000 | shipped | 2025-01-15T10:00Z |
- PK = USER#U001でパーティションを特定 → Scan不要
- SK begins_with 'ORDER#2025-01-15' で日付絞り込み → 1件だけ読み取り
- 完全なSKが判明していればGetItemでさらに高速:
response = table.get_item(Key={'PK': 'USER#U001', 'SK': 'ORDER#2025-01-15#ORD001'})
パターン4: 商品IDで商品情報を取得する
RDB脳での設計
前提のProductsテーブルから ProductId で取得する
response = products_table.get_item(Key={'ProductId': 'P001'})
何が困るか
これだけなら問題ないが、ここまでで既に3テーブル(Users, Orders, Products)が存在している。
| 問題点 | 影響 |
|---|---|
| テーブルの増殖 | エンティティが増えるたびにテーブルが増える。管理コスト増大 |
| テーブル間の結合不可 | 「注文に含まれる商品情報も一緒に取得」ができない(JOINがない) |
| キャパシティ管理が3倍 | テーブルごとにRCU/WCUを個別に設定・監視する必要がある |
| トランザクションの制限 | 複数テーブルにまたがるトランザクションも可能だが、設計が複雑になる |
DynamoDBでの正しい設計
同じテーブルに商品も格納する。
テーブル名: AppData(ユーザー・注文・商品がすべて同居)
| PK | SK | Name | Category | Price |
|---------------|---------|-------|-------------|-------|
| PRODUCT#P001 | INFO | 商品A | electronics | 2000 |
| PRODUCT#P002 | INFO | 商品B | books | 1500 |
| PRODUCT#P003 | INFO | 商品C | electronics | 3000 |
response = table.get_item(Key={'PK': 'PRODUCT#P001', 'SK': 'INFO'})
- テーブルは1つ → キャパシティ管理、バックアップ、監視がすべて一元化
-
PKのプレフィックス(
USER#,PRODUCT#)でエンティティを論理的に分離 - テーブルが1つでも、アプリケーション側から見ればデータは明確に分かれている
パターン5: カテゴリー別に商品を一覧する
RDB脳での設計
前提のProductsテーブル(PK = ProductId)で、カテゴリーで検索する
# 「category = 'electronics' の商品を一覧したい」
response = products_table.query(
KeyConditionExpression=Key('ProductId').eq(???)
)
パーティションキーが ProductId なので、category での Query は不可能。
何が困るか
方法A: Scan + FilterExpression
response = products_table.scan(
FilterExpression=Attr('Category').eq('electronics')
)
| 問題点 | 影響 |
|---|---|
| 全商品を走査 | 商品10万件なら10万件全部読む |
| コスト | FilterExpressionは読み取り後にフィルタ。RCUは全件分 |
| レスポンス遅延 | データ量に比例して遅くなる |
| ソートできない | Scanは順序保証なし。アプリ側でソートが必要 |
方法B: GSIを追加
GSI: パーティションキー = Category, ソートキー = Price
| 追加の問題 | 影響 |
|---|---|
| テーブルごとにGSIを管理 | 3テーブル × 複数GSI = 管理が煩雑 |
| GSIにも独立したRCU/WCUが必要 | コストと管理がさらに増大 |
| GSI数の上限(20個/テーブル) | テーブルが小さい分、すぐに上限に達するリスク |
DynamoDBでの正しい設計
シングルテーブルにGSIを1つ追加する
テーブル: AppData にGSI1を追加
GSI1PK = Category
GSI1SK = Price
GSI1 のビュー:
| GSI1PK (Category) | GSI1SK (Price) | PK | Name |
|--------------------|----------------|---------------|-------|
| books | 1500 | PRODUCT#P002 | 商品B |
| electronics | 2000 | PRODUCT#P001 | 商品A |
| electronics | 3000 | PRODUCT#P003 | 商品C |
response = table.query(
IndexName='GSI1',
KeyConditionExpression=Key('GSI1PK').eq('electronics'),
ScanIndexForward=True # 価格の昇順
)
- Scanではなく Query → electronicsカテゴリーだけを効率的に取得
- 価格順にソート済み → GSIのソートキーにPriceを設定しているため
- テーブルは1つのまま → GSIも1つのテーブルに集約して管理
パターン6: 注文ステータスで注文を検索する
RDB脳での設計
前提のOrdersテーブル(PK = OrderId)で、ステータス検索する
# 「status = 'pending' の注文を日付順で取得したい」
response = orders_table.query(
KeyConditionExpression=Key('OrderId').eq(???) # ← statusで検索できない!
)
何が困るか
方法A: Scan
response = orders_table.scan(
FilterExpression=Attr('Status').eq('pending')
)
ここまでのパターンで何度も出てきた同じ問題:
- 全注文を走査 → 遅い、高コスト
- ソートできない → アプリ側で日付ソートが必要
- 1回のScan上限の1MBによるページネーション → 実装が複雑
方法B: GSIを追加
GSI: パーティションキー = Status, ソートキー = OrderDate
ステータスでの検索自体はできるようになるが、「注文と一緒にユーザー名も表示したい」というよくある要件が来ると…
# ステップ1: GSIでステータス検索
orders = orders_table.query(IndexName='StatusIndex', ...)
# ステップ2: 各注文のUserIdでUsersテーブルから取得(N+1問題!)
for order in orders:
user = users_table.get_item(Key={'UserId': order['UserId']})
| 問題点 | 影響 |
|---|---|
| N+1問題 | 注文100件なら101回のAPI呼び出し(1回のQuery + 100回のGetItem) |
| レイテンシー爆発 | API呼び出しごとにネットワーク往復が発生 |
| コスト増大 | 呼び出し回数に比例してコスト増 |
| BatchGetItemでも限界 | 1回最大100件。1000件なら10回のBatchが必要 |
DynamoDBでの正しい設計
注文アイテムにユーザー名もあらかじめ格納しておく(非正規化)。
テーブル: AppData
| PK | SK | Amount | Status | OrderDate | UserName |
|-------------|---------------------------|--------|---------|---------------------|----------|
| USER#U001 | ORDER#2025-01-15#ORD001 | 3000 | shipped | 2025-01-15T10:00Z | 田中太郎 |
| USER#U001 | ORDER#2025-02-20#ORD002 | 5500 | pending | 2025-02-20T14:30Z | 田中太郎 |
| USER#U002 | ORDER#2025-01-10#ORD003 | 1200 | delivered| 2025-01-10T09:00Z | 鈴木花子 |
GSI2: PK = Status, SK = OrderDate
response = table.query(
IndexName='GSI2',
KeyConditionExpression=Key('Status').eq('pending'),
ScanIndexForward=False # 新しい順
)
取得結果:
| Status | OrderDate | PK | Amount | UserName |
|---------|---------------------|-------------|--------|----------|
| pending | 2025-02-20T14:30Z | USER#U001 | 5500 | 田中太郎 |
- 1回のQueryで完結 → N+1問題なし
- ユーザー名も取得済み → 別テーブルへのアクセス不要
- 「ユーザー名が変わったらどうする?」→ DynamoDB Streams で変更を検知し、関連アイテムを自動更新
RDB脳の落とし穴: RDBでは「データの重複 = 悪」だが、DynamoDBでは「データの重複 = JOINを不要にする設計テクニック」。非正規化はDynamoDBにおける正しい設計手法。
DynamoDBでの最終的なテーブル設計(GSI/LSI含む)
6つのパターンすべてに対応できる、DynamoDBのテーブル設計の全体像を記載
メインテーブル: AppData
テーブル名: AppData
パーティションキー (PK): String
ソートキー (SK): String
| PK | SK | Name | Email | Age | Amount | Status | OrderDate | UserName | Category | Price |
|---------------|---------------------------|----------|----------------------|-----|--------|-----------|---------------------|----------|-------------|-------|
| USER#U001 | PROFILE | 田中太郎 | tanaka@example.com | 30 | | | | | | |
| USER#U001 | ORDER#2025-01-15#ORD001 | | | | 3000 | shipped | 2025-01-15T10:00Z | 田中太郎 | | |
| USER#U001 | ORDER#2025-02-20#ORD002 | | | | 5500 | pending | 2025-02-20T14:30Z | 田中太郎 | | |
| USER#U002 | PROFILE | 鈴木花子 | suzuki@example.com | 25 | | | | | | |
| USER#U002 | ORDER#2025-01-10#ORD003 | | | | 1200 | delivered | 2025-01-10T09:00Z | 鈴木花子 | | |
| PRODUCT#P001 | INFO | 商品A | | | | | | | electronics | 2000 |
| PRODUCT#P002 | INFO | 商品B | | | | | | | books | 1500 |
| PRODUCT#P003 | INFO | 商品C | | | | | | | electronics | 3000 |
-
PKのプレフィックス(USER#,PRODUCT#)でエンティティの種類を識別 -
SKで同一パーティション内のアイテムを区別(PROFILE,ORDER#日付#ID,INFO) - 注文アイテムに
UserNameを非正規化して格納(パターン6のN+1問題を解決)
GSI1: カテゴリー別商品検索用(パターン5で使用)
GSI名: GSI1
パーティションキー (GSI1PK): Category
ソートキー (GSI1SK): Price
投影: ALL(全属性を射影)
GSI1のビュー(自動的にレプリケーションされる):
| GSI1PK (Category) | GSI1SK (Price) | PK | SK | Name |
|--------------------|----------------|---------------|------|-------|
| books | 1500 | PRODUCT#P002 | INFO | 商品B |
| electronics | 2000 | PRODUCT#P001 | INFO | 商品A |
| electronics | 3000 | PRODUCT#P003 | INFO | 商品C |
- Category が
GSI1PKに設定されたアイテム(PRODUCT系)のみがGSIに投影される - Price が
GSI1SKのため、同一カテゴリー内で価格順に自動ソート -
Query(GSI1PK='electronics')でカテゴリー検索が可能
GSI2: 注文ステータス検索用(パターン6で使用)
GSI名: GSI2
パーティションキー (GSI2PK): Status
ソートキー (GSI2SK): OrderDate
投影: ALL(全属性を射影)
GSI2 のビュー(自動的にレプリケーションされる):
| GSI2PK (Status) | GSI2SK (OrderDate) | PK | SK | Amount | UserName |
|------------------|---------------------|-------------|---------------------------|--------|----------|
| delivered | 2025-01-10T09:00Z | USER#U002 | ORDER#2025-01-10#ORD003 | 1200 | 鈴木花子 |
| pending | 2025-02-20T14:30Z | USER#U001 | ORDER#2025-02-20#ORD002 | 5500 | 田中太郎 |
| shipped | 2025-01-15T10:00Z | USER#U001 | ORDER#2025-01-15#ORD001 | 3000 | 田中太郎 |
- Status が
GSI2PKに設定されたアイテム(ORDER系)のみがGSIに投影される - OrderDate が
GSI2SKのため、同一ステータス内で日付順にソート -
Query(GSI2PK='pending', ScanIndexForward=False)で新しい順に取得
まとめ: RDB脳で設計するとこう困る
| # | やりたいこと | RDB脳での設計 | 何が起きるか | DynamoDBでの正解 |
|---|---|---|---|---|
| 1 | ユーザーIDでユーザー情報を取得する | Users専用テーブル | 単体は動くが、テーブル増殖の始まり | シングルテーブル PK=USER#id, SK=PROFILE
|
| 2 | ユーザーIDで全注文を取得する | 別テーブルOrders (PK=OrderId) | UserIdでQueryできない → Scan地獄 | 同一パーティション Query(PK=USER#id, SK begins_with ORDER#)
|
| 3 | ユーザーIDと注文日で特定の注文を取得する | 同上 | 複合条件でQueryできない → Scan地獄 | ソートキーに日付埋め込み SK begins_with ORDER#2025-01-15
|
| 4 | 商品IDで商品情報を取得する | Products専用テーブル | テーブル3つに増殖。管理コスト3倍 | 同一テーブル PK=PRODUCT#id, SK=INFO
|
| 5 | カテゴリー別に商品を一覧する | Products (PK=ProductId) | CategoryでQueryできない → Scan地獄 | GSIを追加 GSI(PK=Category, SK=Price)
|
| 6 | 注文ステータスで注文を検索する | Orders (PK=OrderId) + Users JOIN | JOINできない → N+1問題 | GSI + 非正規化で1回のQueryで完結 |
DynamoDB設計の鉄則
- まずアクセスパターンを洗い出す(「どんなクエリが必要か」を最初に決める)
- 1つのテーブルに複数エンティティをまとめる(シングルテーブルデザイン)
- PKとSKを最大限に活用する(プレフィックス、日付埋め込み)
- 足りない検索軸はGSIで補完する
- JOINの代わりに非正規化(データの重複格納)を恐れない
よくある設計ミスとその回避策
DynamoDBのよくある設計ミスについて紹介します!
ホットパーティション
カーディナリティが低い値をPKに設定しまい、ホットパーティション(特定のパーティションにリクエストが集中)してしまうミスです。
これにより、スロットリングエラーが発生します。
これに対応するためにDynamoDBには、バーストキャパシティとアダプティブキャパシティという機能がDynamoDBには備わっています。詳しく知りたい方は公式をご覧ください ![]()
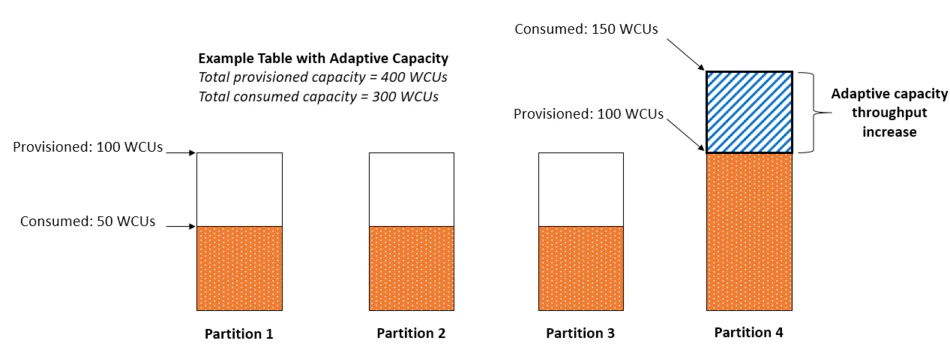
❌ 悪い例: PK = "Status" (値が "active" / "inactive" の2種類)
→ "active" パーティションにリクエストが集中
✅ 改善: PK = "UserId", GSI の PK = "Status"
→ メインテーブルはユーザーごとに分散、ステータス検索はGSIで対応
Scanの多用
前述したとおり、Scanは全データを走査するため、データ数が多くなれば多くなるほどコスト的にもパフォーマンス的にもよくありません。
❌ 悪い例: 条件検索のたびにテーブル全体をScan
→ RCU消費大、レイテンシー増大
✅ 改善: アクセスパターンに合わせたGSIを作成
→ Queryで効率的に検索
大きすぎるアイテム
DynamoDBはストレージ量の上限はありませんが、1アイテム400KBの上限があります。
400KBも行くことは基本ないと思いますが、頭の片隅に置いておきましょう。
❌ 悪い例: 1アイテムに大量のリストデータを格納
✅ 改善: 1対多の関係はソートキーで表現
PK = "USER#001", SK = "COMMENT#001"
PK = "USER#001", SK = "COMMENT#002"
GSIの過剰作成
検索を柔軟に行うためにはGSIの作成が不可欠です。
しかし、GSIには20個の上限があります。
条件が大量になる場合には、GSIオーバーローディングのテクニックを使いましょう
❌ 悪い例: あらゆるアクセスパターンに個別のGSIを作成
✅ 改善: オーバーローディング(汎用的なGSI設計)
GSI: PK = "GSI1PK", SK = "GSI1SK"
→ 異なるエンティティで同じGSIを共有
GSIオーバーローディング
GSIの多重定義と呼ばれるテクニックです。
スキーマレスの強みをフルに生かして、1つのGSIに複数のエンティティの属性を含めることで、1つのGSIで複数の条件検索が出来るようになります。
これにより、
- GSI作成上限の回避
- GSIを大量に作らないことによるコスト削減
が期待できます![]()
その分、データの持ち方としては複雑になるので事前設計が重要になります!
スパースインデックス
GSI/LSIには、インデックスのキーとして指定した属性(項目)を持っていないデータは、インデックスには反映されないという特徴があります。
これを利用したテクニックが、スパースインデックスです。
よくある取得として論理削除されたデータは除外したいという要件があると思います。
残念ながらbooleanはインデックスに利用できません。
そういった場合に、日付などの文字列や数字をインデックスのソートキーを指定し、アクティブなアイテムにはPendingDateを含めないようにして、以下のようにPKにORD001を指定してQueryします。
すると、PendingDate属性が存在する=削除されていないアイテムを取得することが出来ます![]()
テーブル: Orders
| OrderId(PK) | Status | PendingDate(LSI SK) |
|--------------|------------|--------------------|
| ORD001 | completed | (属性なし) |
| ORD001 | pending | 2025-01-15 |
| ORD003 | completed | (属性なし) |
| ORD004 | pending | 2025-02-01 |
その他機能
これまで紹介した以外のDynamoDBの機能をさらっと紹介します!
DynamoDB Streams
DynamoDB Streamsは、テーブル内のアイテムレベルの変更をキャプチャする機能です
変更キャプチャとしては、以下の4つがあります。
| ビュータイプ | 内容 |
|---|---|
| KEYS_ONLY | 変更されたアイテムのキー属性のみ |
| NEW_IMAGE | 変更後のアイテム全体 |
| OLD_IMAGE | 変更前のアイテム全体 |
| NEW_AND_OLD_IMAGES | 変更前後の両方のアイテム |
主なユースケース
主に以下のような場合に利用されます!
- Lambda関数のトリガー: アイテムの変更に応じてLambda関数を自動実行
- データレプリケーション: 他のテーブルやサービスへのデータ同期
- リアルタイム通知: データ変更時にユーザーへ通知
DynamoDB テーブル
│
▼
DynamoDB Streams
│
▼
AWS Lambda → SNS → メール通知
→ SQS → 非同期処理
→ 別のDynamoDBテーブルへレプリケーション
PITR
直近 35日間 の任意の時点にテーブルを復元することが出来る機能です。
有効化すると自動的に継続バックアップが取得されます。
DAX(DynamoDB Accelerator)
DAXは、DynamoDB用のフルマネージドインメモリキャッシュです。
- 読み取りレイテンシーをミリ秒 → マイクロ秒に短縮
- DynamoDBと API互換(コードの変更が最小限)
- 書き込みはDynamoDBへ直接、読み取りはDAX経由
アプリケーション → DAX → DynamoDB
↑
キャッシュヒット時は
DynamoDBにアクセスしない
DAXは以下のようなケースに適しています。
- 同じデータを何度も読み取るアプリケーション
- 読み取りが多いワークロード
- レイテンシーに敏感なアプリケーション
逆に以下のようなケースでは適していません。
- 書き込みが多いワークロード
- 強い整合性が必要なケース(DAXは結果整合性のみ)
- 読み取りパターンが予測不能なケース
グローバルテーブル
グローバルテーブルは、複数のAWSリージョンにテーブルを自動レプリケーションする機能です
- マルチリージョン、マルチアクティブ: どのリージョンからでも読み書き可能
- 自動レプリケーション: リージョン間のデータ同期は自動
- 低レイテンシー: ユーザーに最も近いリージョンからアクセス可能
- 災害対策(DR): リージョン障害時に他のリージョンで継続運用
- 書き込みの競合が発生した場合は「最後の書き込みが勝つ(Last Writer Wins)」
- レプリケーションのレイテンシーは通常 1秒未満
- グローバルテーブルに参加する全リージョンでDynamoDB Streamsが有効化される
 料金
料金
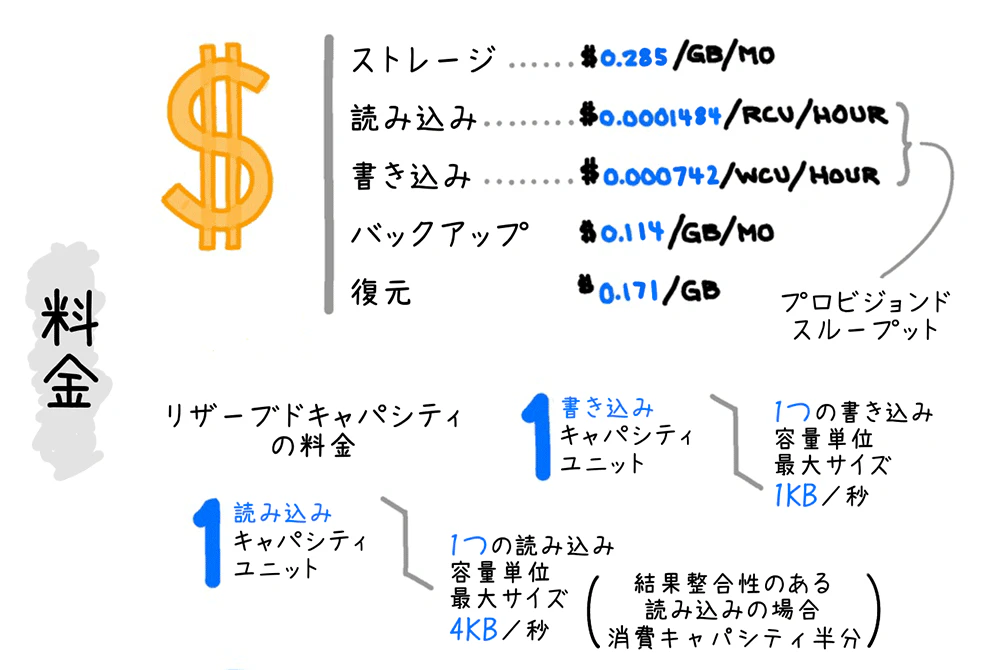
最後に料金です!
DynamoDBは以下に課金されるのですが、実際はキャパシティユニットをいかに下げるかが重要です。
キャパシティユニットを事前にしっかり予測できればいいのですが、実際はリリース前に計算するのは難しいことが多いです。
リリース後であれば、CloudWatchで使用量は確認可能なので、
- リリース直後はオンデマンドにし、トラフィック傾向がわかってきたらプロビジョンドモードに設定する
- プロビジョニングモードで過剰に設定しておいて、リリースしてトラフィック傾向がわかってきたら数を調整する
前述のとおり、キャパシティユニットはテーブル毎に設定する必要があります。
テーブルが増えれば増えるほど、予測する対象が増えるので、
テーブルの数を以下に減らすかが大事らしいです!
 おわりに
おわりに
今回はDynamoDBについてアウトプットしました!
色々覚えることが多いですが、RDB以外の選択肢を考える方の参考になれば幸いです![]()