はじめに
GUI ベースで ETL 処理が行える Mapping Data Flow は Azure Data Factory だけでなく Azure Synapse Analytics で使うことができます。
Mapping Data Flow は元々 Parquet 形式をサポートしていましたが、最近 Delta 形式もサポート対象に加わりました。
また、Azure Synapse Analytics では SQL オンデマンド というサーバーレスなクエリ実行エンジンを利用できます。
本記事では、Azure Blob Storage に格納された CSV ファイルを Mapping Data Flow で Parquet 形式 & Delta 形式に変換して Azure Data Lake Storage Gen2 (ADLS) に格納し、SQL オンデマンドでクエリを実行するまでの一連の流れを簡単にまとめたいと思います。
目次
- Synapse Workspace 作成
- 入出力ファイル & フォルダ準備
- Linked services & Datasets 設定
- Data flows 作成
- Pipelines 作成 & 実行
- SQL オンデマンドでのクエリ実行
1. Synapse Workspace 作成
Azure ポータルで [synapse] と検索し [Azure Synapse Analytics (workspaces preview)] を選択します。

Workspace 作成画面です。20207/26 時点では東日本 & 西日本リージョンは選択できません。任意のリージョンを指定します。

SQL オンデマンドで ADLS のデータに対してクエリを実行する際に権限的に必要なためチェックしておきます。
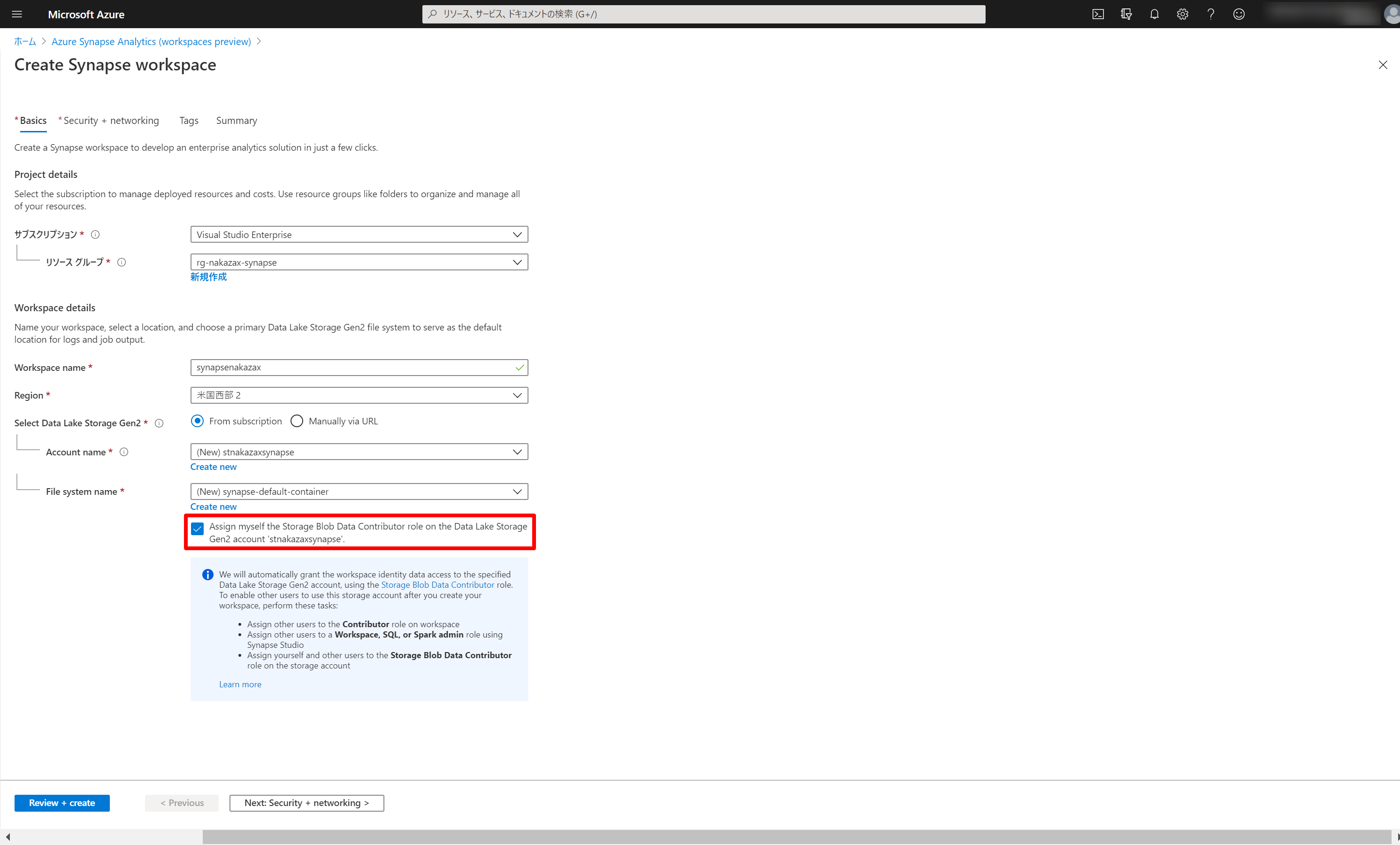
次画面では SQL 管理者のユーザー名とパスワードを入力します。他のチェックボックスについては必要に応じてオン/オフを切り替えましょう。
特定の IP アドレスからのアクセスのみを許可したい場合は、一番下の [Allow connection from all IP address] のチェックを外しておきます。Workspace 作成後に Firewall 画面から接続を許可する IP アドレスを編集します。
問題なければ作成します。数分後にリソース作成が完了します。

2. 入出力ファイル & フォルダ準備
入力用の準備として、ダミーデータを準備して Blob Storage にアップロードします。
出力用の準備として、ADLS にフォルダーを作成しておきます。
2-1. 入力用 - ダミーデータ作成
まずは Blob Storage に格納する CSV データを準備します。ここでは mockaroo というダミーデータ生成用の Web サイトでダミーデータを作成します。mockaroo では 1000 件 / 回のダミーデータを無料で作成できます。
https://www.mockaroo.com/
こんな感じでフィールド名と型とオプションを入れると良い感じのダミーデータが作成されます。

作成したデータは以下のような感じです。
order_number,created_at,customer_id,stock_name,quantity
1,2020-07-07T16:58:56Z,cb500cf5-4786-4bdc-b1a8-93652f31cfae,"American Eagle Outfitters, Inc.",82
2,2020-07-07T10:22:17Z,6c57e361-d511-4893-a2a1-af1579f3d15c,"Meridian Waste Solutions, Inc",24
...
999,2020-07-07T02:11:19Z,87f29c2d-30b0-4714-a2db-efe47e28831c,LKQ Corporation,45
1000,2020-07-05T04:34:07Z,58a4d463-9fc9-4f0c-9745-797e0427383f,Valvoline Inc.,29
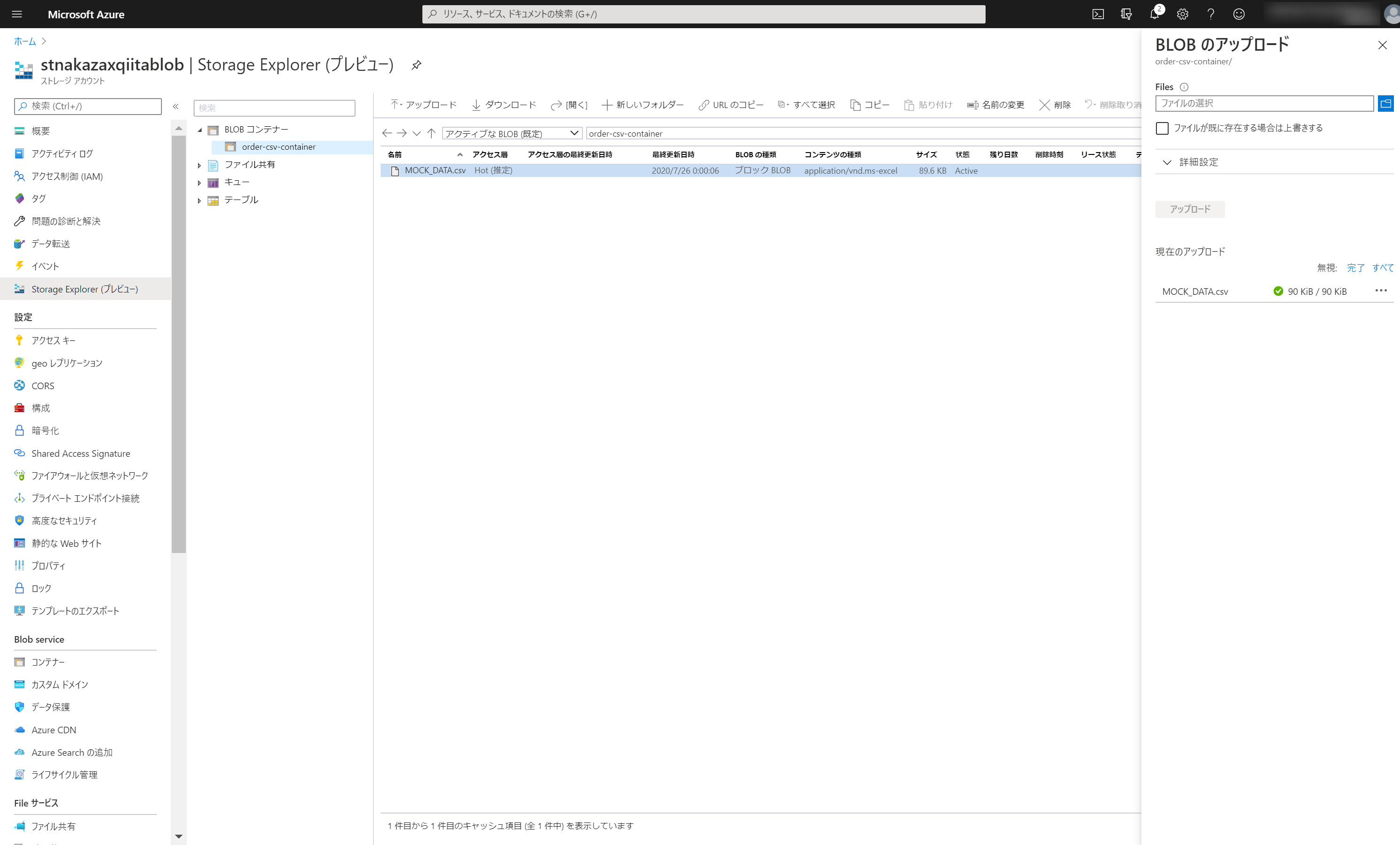
2-2. 入力用 - ダミーデータを Blob Storage にアップロード
あらかじめ 作っておいた Blob Storage に Storage Explorer でダミーデータをアップロードします。
2-3. 出力用 - フォルダ作成
この後 Datasets を設定する際に ADLS にフォルダが存在する必要があるため、ADLS の Storage Explorer でフォルダを作成しておきます。

3. Linked services & Datasets 設定
ここから先は Synapse Workspace で作業を行います。Synapse Workspace の Overview 画面の赤枠で囲んだリンクをクリックすると Workspace が別タブで起動します。

3-1. Linked services - Blob
(Name: BlobStorageNakazaxQiitaDf)
入力 Blob Storage 用の Linked service です。
[Manage] ハブ > [Linked services] で [New] をクリックして新規 Linked service を作成します。

3-2. Datasets - Blob
(Name: OrdersCsv)
入力データ用の Dataset です。[Data] ハブの [+] アイコンをクリックして [Datasets] をクリックします。[Azure Blob Storage] > [Delimited Text] を選んだ後、入力データが格納されているパスなどを指定して Dataset を作成します。作成後の状態がこちらです。

3-3. Datasets - ADLS
(Name: OrdersParquetByDate)
Parquet 出力データ用の Dataset です。[Data] ハブの [+] アイコンをクリックして [Datasets] をクリックします。[Azure Data Lake Storage Gen2] > [Parquet] を選んだ後、出力先のフォルダパスを指定して Dataset を作成します。


これで Datasets の設定は完了です。Delta 用の Dataset については後続の手順で設定していきます。
4. Data flows 作成
CSV > Parquet 変換用の Data flow と、CSV > Delta 変換用の Data flow を作成していきます。
4-1. CSV > Parquet 変換用 Data flow
(Name: DataflowOrdersCsvToParquet)
[Develop] ハブの [+] アイコンをクリックして [Data flow] をクリックします。Data flow ではそれぞれの箱を「変換」(transformation) と呼びます。以下、各変換のキャプチャを貼付します。
4-1-1. Source 変換
(Name: SourceOrdersCsv)
Dataset に OrdersCsv を指定します。

各カラムの型はデフォルトでは String で解釈されるため、order_number と quantity の Type を Integer に変更します。

4-1-2. Derived column 変換
(Name: AddDateColumns)
パーティションに利用する日時カラムを追加します。

4-1-3. Sink 変換
(Name: SinkOrdersParquetByDate)

ここでは出力先フォルダーを毎回の処理実行時にクリアするように設定しています。

pt_year/pt_month/pt_day というパーティションを指定します。

以下のカラムが出力ファイルに書き込まれます。

4-2. CSV > Delta 変換用 Data flow
(Name: DataflowOrdersCsvToDelta)
4-2-1. Source 変換
(Name: SourceOrdersCsv)
CSV > Parquet 変換用 Data flow と同じ内容のため割愛
4-2-2. Derived column 変換
(Name: AddDateColumns)
CSV > Parquet 変換用 Data flow と同じ内容のため割愛
4-2-3. Sink 変換
(Name: SinkOrdersDeltaByDate)
Delta を指定する場合、[Sink type] から [Delta] を指定します。

出力先 ADLS の Linked service を指定します。
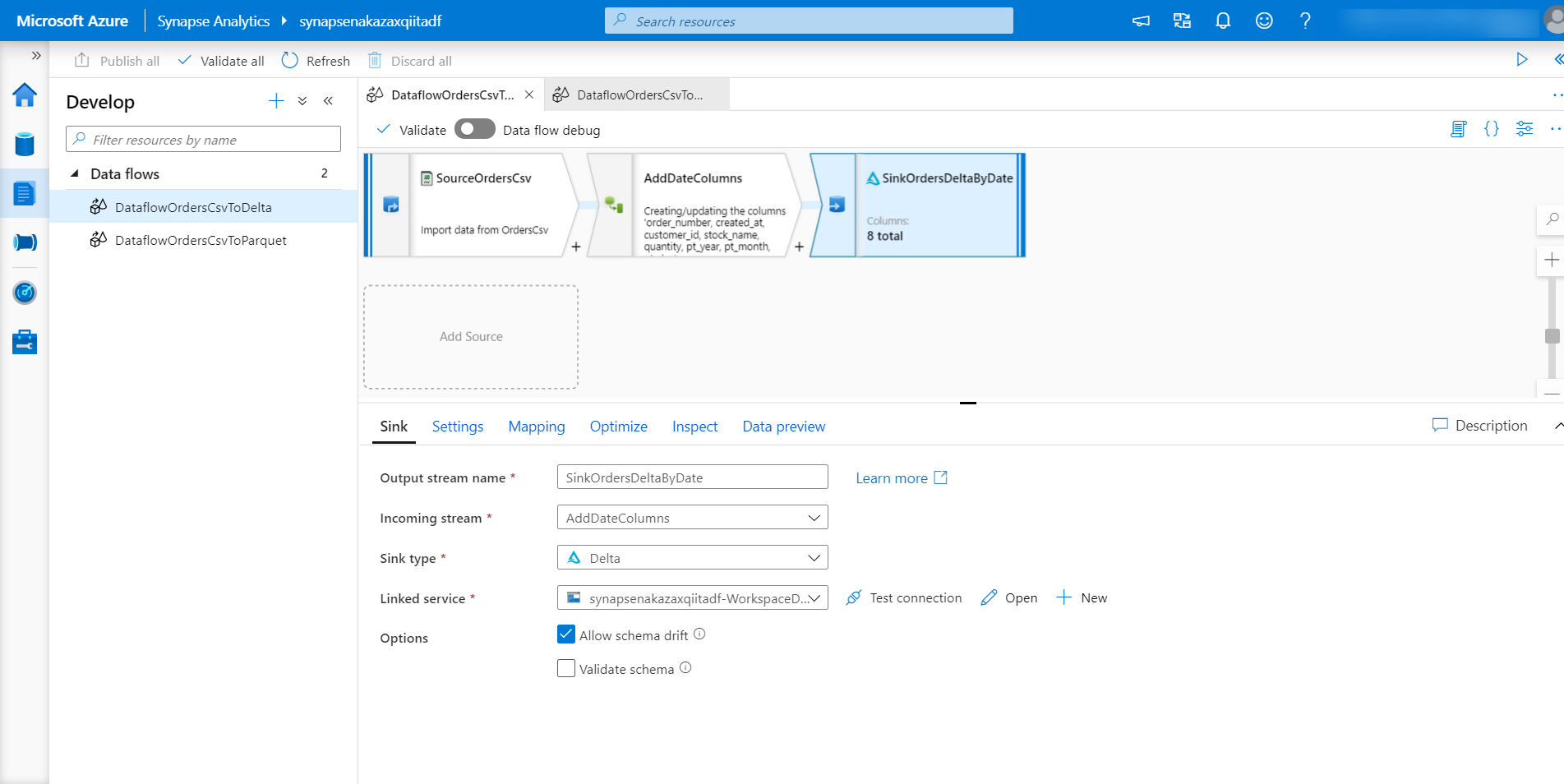
[Settings] タブでフォルダーパス以外にも諸々の設定ができますが、今回は特に変更せずにデフォルトのままにしておきます。

pt_year/pt_month/pt_day というパーティションを指定します。

5. Pipelines 作成 & 実行
先ほど作成した Data flow を呼び出す Pipeline を作成し、デバッグ実行して結果を出力します。
5-1. CSV > Parquet 変換用 Data flow 用 Pipeline
(Name: PipelineDataflowOrdersCsvToParquet)
[Orchestrate] ハブの [+] アイコンをクリックして [Pipeline] をクリックします。[Move & transform] > [Data flow] を右側の空白部分にドラッグ & ドロップして先ほど作成したCSV > Parquet 変換用 Data flow を指定します。[Publish all] をクリックします。

[Add trigger] > [Trigger now] をクリックし、Pipeline を実行します。
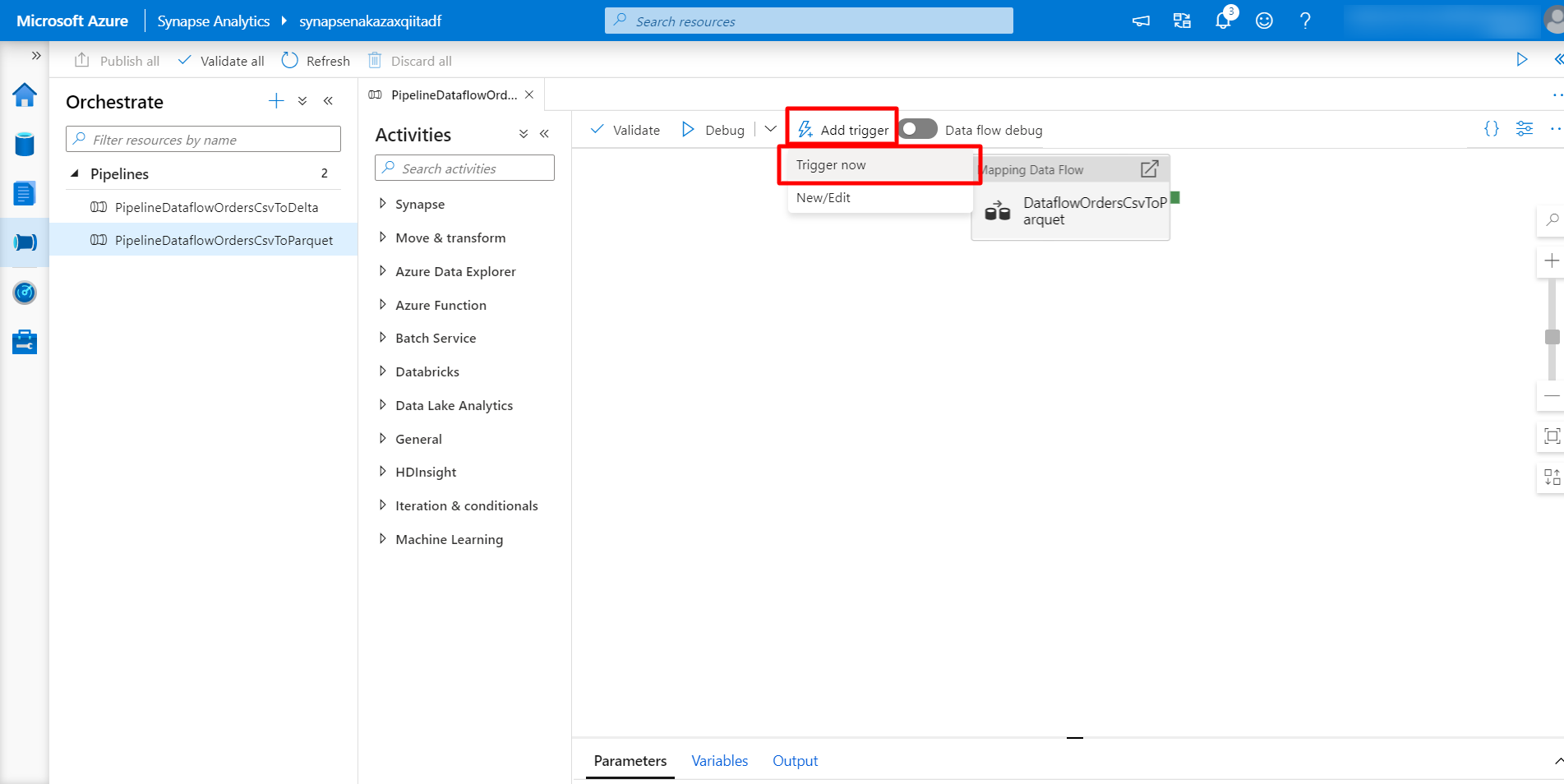
5-2. CSV > Delta 変換用 Data flow 用 Pipeline
(Name: PipelineDataflowOrdersCsvToDelta)
上記と同様の手順のため割愛します。
5-3. Pipeline 実行結果確認
[Monitor] ハブ > [Pipeline runs] から Pipeline の実行結果が確認できます。[STATUS] が [Succeeded] になっていれば OK です。

Parquet 出力結果
実際にどのようなデータが出力されたかを見てみましょう。
[Data] ハブ > [Linked] の Storage accounts に ADLS のコンテナー一覧が表示されているはずなので、その中で出力先として利用しているコンテナーを指定します。
Parquet の方はこのような出力になるはずです。

pt_year=2020 フォルダー (年のパーティション) と _SUCCESS ファイル (処理成功を表す) がある

pt_month=07 フォルダー (月のパーティション) がある

pt_day=01 ~ pt_day=07 フォルダー (日のパーティション) がある

各フォルダーの配下に part-00000-${GUID}.c0000.snappy.parquet といったネーミングのファイルがある (これがデータの実体)

Delta 出力結果

pt_year=2020 フォルダー以下の構造は Parquet と同じですが一点だけ違いとして _delta_log フォルダーがある

_delta_log フォルダーには以下のような JSON ファイルがある

JSON の中には以下のようなメタデータが格納されている。
{"commitInfo":{"timestamp":1595757668111,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[\"pt_year\",\"pt_month\",\"pt_day\"]"},"isBlindAppend":true,"operationMetrics":{"numFiles":"7","numOutputBytes":"84256","numOutputRows":"1000"}}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"04e98468-c8ca-41e7-a01f-f589ab5f533b","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"order_number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"created_at\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"customer_id\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"stock_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"quantity\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"pt_year\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"pt_month\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"pt_day\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":["pt_year","pt_month","pt_day"],"configuration":{},"createdTime":1595757649086}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=01/part-00000-4dfe08ac-252a-4cee-a797-e7bdd4b48fa5.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"01"},"size":14098,"modificationTime":1595757657000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=02/part-00000-e12e27d8-e651-4bd2-8e45-6dddac0665ac.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"02"},"size":12294,"modificationTime":1595757658000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=03/part-00000-bb8e1936-e220-4200-a241-57d1663b00e4.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"03"},"size":11243,"modificationTime":1595757660000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=04/part-00000-5968555c-de58-4c29-b1b0-d433870d7976.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"04"},"size":11288,"modificationTime":1595757661000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=05/part-00000-b19c8e6b-1853-46c6-9d34-5b8b70f50d8f.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"05"},"size":11764,"modificationTime":1595757662000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=06/part-00000-725b1fcd-5c6c-49bf-a194-56710d5766fc.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"06"},"size":11898,"modificationTime":1595757664000,"dataChange":true}}
{"add":{"path":"pt_year=2020/pt_month=07/pt_day=07/part-00000-27b18250-ae7e-42de-8f76-37c69fac7d07.c000.snappy.parquet","partitionValues":{"pt_year":"2020","pt_month":"07","pt_day":"07"},"size":11671,"modificationTime":1595757665000,"dataChange":true}}
6. SQL オンデマンドでのクエリ実行
以下、Delta 形式のデータに対するクエリの例をいくつか記載します。Parquet 形式についても同様のクエリでアクセスできます。他のパターンについては以下ドキュメントを参考頂くのが良いと思います。
単一ファイル指定 & TOP 100
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://stnakazaxqiitadf.dfs.core.windows.net/orders-container/orders_delta_by_date/pt_year=2020/pt_month=07/pt_day=01/part-00000-4dfe08ac-252a-4cee-a797-e7bdd4b48fa5.c000.snappy.parquet',
FORMAT='PARQUET'
) AS [r];

単一ファイル指定 & COUNT
SELECT
COUNT(*)
FROM
OPENROWSET(
BULK 'https://stnakazaxqiitadf.dfs.core.windows.net/orders-container/orders_delta_by_date/pt_year=2020/pt_month=07/pt_day=01/part-00000-4dfe08ac-252a-4cee-a797-e7bdd4b48fa5.c000.snappy.parquet',
FORMAT='PARQUET'
) AS [r];

全ファイル指定 & COUNT
SELECT
COUNT(*)
FROM
OPENROWSET(
BULK 'https://stnakazaxqiitadf.dfs.core.windows.net/orders-container/orders_delta_by_date/pt_year=*/pt_month=*/pt_day=*/*.parquet',
FORMAT='PARQUET'
) AS [r];

WHERE 句で絞り込んだ日付別の件数
SELECT
SUBSTRING(r.created_at, 0, 11) AS created_at_date,
COUNT(*) AS count
FROM
OPENROWSET(
BULK 'https://stnakazaxqiitadf.dfs.core.windows.net/orders-container/orders_delta_by_date/pt_year=2020/pt_month=07/pt_day=*/*.parquet',
FORMAT='PARQUET'
) AS [r]
WHERE r.filepath(1) >= '01' AND r.filepath(1) <= '04'
GROUP BY SUBSTRING(r.created_at, 0, 11)
ORDER BY created_at_date ASC;

以上です。