はじめに
AWSのs3バケットを静的ファイルの配信サーバにする他にバックアップ用途に使っている人も多くいると思います。
僕がやっている例を紹介します。
s3cmdをインストールと設定
- epelからインストール
入るバージョンを念のため見てみる
yum info –enablerepo=epel s3cmd
.
.
.
Name : s3cmd
Arch : x86_64
Version : 1.0.0
Release : 4.1
Size : 296 k
1.0.0が入るみたい。
最新ではないっぽいけど込み入った使い方はしないのでまぁ良いか
yum --enablerepo epel install s3cmd
一応色々見ながらyを押す
configを設定
s3cmd --configure
Access Key: xxx
Secret Key: xxx
[root@hostname]# s3cmd ls
2015-02-13 03:26 s3://xxxxxxxx
s3コマンドが使えたので正常にインストールされてることを確認
aws s3バケットの設定(非公開設定)
awsのコンソール>s3の管理画面>BK用のバケット>プロパティ>静的ウェブサイトホスティング
>有効にしない
確認
- 実際にBKファイルをs3の該当バケットにupload
- awsのコンソール画面から該当のファイルのプロパティを確認
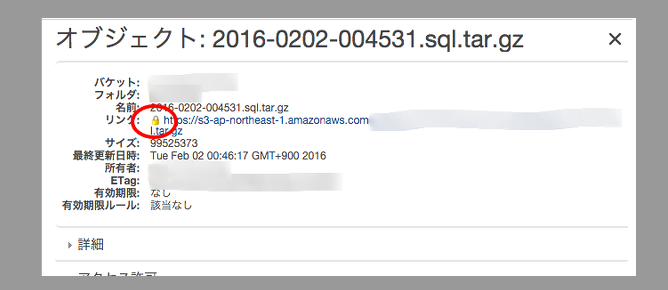
- 鍵マークがあり、実際にurlにアクセスしても
AccessDeniedと出る
バックアップ用のshellを作る
backup.sh
# !/bin/sh
# 終了ステータスが0以外の時は処理を中断してNGを出力する
# jenkinsのjobで実行予定で異常に気づけるように
set -e
trap 'echo NG' ERR
# n世代のバックアップを保存
MAX_SAVE_CNT=7
BACKUP_NAME=`date +"%Y-%m%d-%H%M%S".sql`
# BK用途のslaveサーバからmysqldumpでバックアップを取得
# サイズが大きくなればserviceをstopしてバイナリーバックアップに切り替える
ssh backup@<slave database hostname> /usr/local/mysql/bin/mysqldump -uroot <database name> > <bk dir>$BACKUP_NAME
tar cvzf $BACKUP_NAME.tar.gz $BACKUP_NAME
# s3へ格納
s3cmd put -r $BACKUP_NAME.tar.gz s3://<BUCKET_NAME>/<BUCKET_PATH>/
file_count=`ls -1 | grep sql.tar.gz | wc -l`
if [ $file_count -gt $MAX_SAVE_CNT ]
then
# s3にある7世代以降のバックアップを削除
s3cmd del -r s3://<BUCKET_NAME>/<BUCKET_PATH>/`ls -1 | grep sql.tar.gz | head -1`
# localのバックアップファイルも削除
rm -rf `ls -1 | grep sql.tar.gz | head -1 | xargs rm -rf`
fi
- 世代バックアップ管理をできるようにしている
- jenkinsで定期実行を想定。
- 何か例外的なことが発生したら処理を中断して
errorを出力するようにして、jenkins jobの実行失敗になるようにした。 - バックアップの実行時間はjenkinsのjobの実行時間をイコールで見るようにした
- 分散保存という意味でlocalにも世代バックアップを持っている
- リストアの確認は別途した