茶色を目指しているなかみんです。
AtCoderのABCD問題をまとめています。
ABC448(2026年3月7日実施)
A問題
- 入力例
5 10
6 4 7 1 3
- 回答例
N, X = map(int, input().split())
A = list(map(int, input().split()))
for a in A:
if a < X:
X = a
print(1)
else:
print(0)
B問題
- 入力例
7 5
4 4 8 3 7
1 2
2 3
5 2
4 10
2 3
5 4
2 3
- 回答例
N, M = map(int, input().split())
C = [0]+list(map(int, input().split()))
# print(C)
cnt = 0
for _ in range(N):
A, B = map(int, input().split())
if C[A] <= 0:
continue
else:
amt = C[A]-B
if amt >= 0:
cnt += B
C[A] -= B
# print(f"{A}, {B} -> {C} cnt+{B}")
else:
cnt += C[A]
# print(f"{A}, {B} -> {C} cnt+{C[A]}")
C[A] = 0
print(cnt)
ポイント
- if amt >= 0:(在庫が足りるか足りないか)で分けていますが、「コショウの在庫(C[A])」と「料理の上限(B)」のうち、小さい方の値を使えばよいとも言えます
# 実際に使える量は、在庫と上限の小さい方 use = min(C[A], B) cnt += use C[A] -= use
C問題
6 6
3 2 5 9 1 2
2
4 5
5
1 2 3 4 6
3
2 5 6
4
1 2 5 6
1
5
3
1 2 3
回答例
import sys
input = sys.stdin.readline
N, Q = map(int, input().split())
A = list(map(int, input().split()))
# (ボールの番号, 数値)
sorted_A = []
for i, a in enumerate(A, 1):
sorted_A.append((i, a))
print(sorted_A)
# 数値(x[1])でソート
sorted_A.sort(key=lambda x: x[1])
print(sorted_A)
for _ in range(Q):
K = int(input())
# 取り出したボールを set にする
removed_balls = set(map(int,input().split()))
# print("removed_balls: ", removed_balls)
# 小さい順に見ていき、取り出されていないものを見つけた瞬間に終了
for i in range(N):
if sorted_A[i][0] not in (removed_balls):
print(sorted_A[i][1])
break
ポイント
- 現在の袋に入っているボールに書かれた整数の最小値を見つけるという条件から、まずは整数を昇順にして並べておき、最初の要素を出力すればよいと考えます
D問題
- 入力例
5
1 3 2 1 2
1 2
1 3
3 4
3 5
- 回答例
import sys
sys.setrecursionlimit(10**7)
def main():
N = int(input())
A = list(map(int, input().split()))
graph = [ [] for _ in range(N) ]
for _ in range(N - 1):
u, v = map(int, input().split())
graph[u - 1].append(v - 1)
graph[v - 1].append(u - 1)
print(graph)
answer = [False] * N # 頂点ごとの結果を保存
cnt = 0 # 重複の数
S = set() # 数字の種類を記録
def dfs(v, pv): # v: 現在の頂点 pv: 親の頂点
nonlocal cnt # 関数の外にあるcntを書き換えるため
cnt_del = 0 # 新しく重複が発生したかのフラグ
if A[v] in S: # 重複
cnt_del += 1
else:
S.add(A[v]) # 初めて見る数字
# 全体の重複数に加算
cnt += cnt_del
if cnt > 0:
answer[v] = True # 重複
for nv in graph[v]:
if nv == pv: # 今来た道には戻らないようにする
continue
dfs(nv, v) # 子頂点へ進む
# 戻る処理
cnt -= cnt_del
if cnt_del == 0:
S.remove(A[v])
dfs(0, -1)
for ans in answer:
if ans: print("Yes")
else: print("No")
if __name__ == "__main__":
main()
ポイント
- 頂点1から各頂点へのパスを一つずつ調べると何度も同じ道を通ることになってしまいます。入力例の場合、データは頂点 1 を根として、2 と 3 がぶら下がり、3 の先に 4 と 5 がある構造になっているので、DFS(深さ優先探索)で考えていきます。
- まずはどの頂点がつながっているかを表す隣接リストを作成します。入力例の場合、以下のようになります

- 隣接リスト graph:
- graph[0] = [1, 2]
- graph[1] = [0]
- graph[2] = [0, 3, 4]
- graph[3] = [2]
- graph[4] = [2]
- 隣接リスト graph:
-
頂点 0 (数字 1) dfs(0, -1)
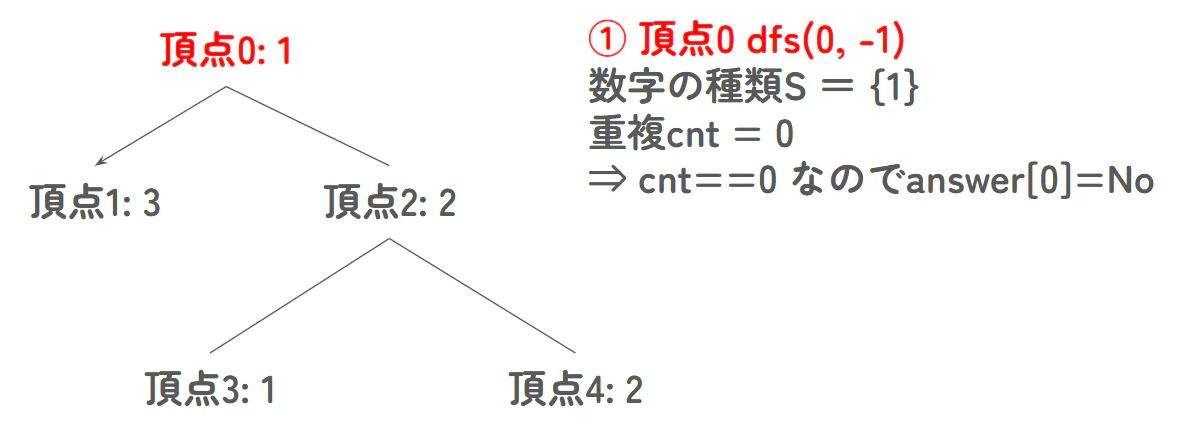
- 行く時: 袋 $S$ は空なので、1 を追加(S = {1})
- 重複: なし(cnt = 0)
- 判定: cnt == 0 なので、answer[0] = No
- 次へ: 隣の 1 へ進む
-
頂点 1 (数字 3) dfs(1, 0)

- 行く時: 袋 $S={1}$ に 3 はないので、追加(S = {1, 3})
- 重複: cnt = 0 のまま
- 判定: answer[1] = No
- 戻る時: 「自分(頂点1)が追加した 3」 を袋から捨てて、頂点 0 に戻る(S = {1})
-
頂点 2 (数字 2) dfs(2, 0)

- 行く時: 袋 $S={1}$ に 2 はないので追加(S = {1, 2})
- 重複: cnt = 0 のまま
- 判定: answer[2] = No
-
頂点 3 (数字 1) dfs(3, 2)

- 行く時: 袋 $S={1, 2}$ を見ると、すでに 1 が入っている
- 判定: 新しく袋には入れず、「ダブりが発生した目印」 として cnt_del = 1 を立て、全体の cnt を 1 に増やす(cnt = 1)
- 判定: cnt > 0 なので、answer[3] = Yes
- 戻る時: cnt を 1 減らして 0 に戻す。自分は袋に何も入れていないので、remove はしない
-
頂点 4 (数字 2) dfs(4, 2)

- 行く時: 袋 $S={1, 2}$ を見ると、すでに 2 が入っている
- 判定: cnt_del = 1 となり、全体の cnt は 1
- 判定: answer[4] = Yes
- 戻る時: cnt を 0 に戻して、頂点 2 に戻る
- DFSのテンプレ
import sys sys.setrecursionlimit(10**7) input = sys.stdin.readline def dfs(v, p): # --- [1] 行く処理 --- # 今の頂点 v に入った瞬間にやりたいこと # (例: スタンプを押す、答えを Yes にする、合計に足す) for nv in graph[v]: if nv == p: continue # 親への逆走防止 # --- [2] 子に進む前の準備 (必要の場合) --- dfs(nv, v) # 子頂点へジャンプ # --- [3] 子から戻ってきた直後の処理(必要の場合) --- # (例: 子の計算結果を自分に加算する) # --- [4] 帰る処理 --- # 親の元へ戻る直前にやりたいこと # (例: スタンプを消す、袋から出す、合計から引く)
ABC449(2026年3月14日実施)
A問題
- 入力例
2
- 回答例
import math
D = int(input())
print((D/2)**2*math.pi)
B問題
- 入力例
7 9 5
2 4
1 3
2 1
2 1
1 3
- 回答例
H, W, Q = map(int, input().split())
for _ in range(Q):
i, num = map(int, input().split())
if i==1:
print(num*W)
H -= num
else:
print(num*H)
W -= num
C問題
- 入力例
10 2 6
aabbccaabb
- 回答例
from collections import defaultdict
def main():
N, L, R = map(int, input().split())
S = input().strip()
# 文字ごとに出現位置(インデックス)を記録
pos = defaultdict(list)
for idx, char in enumerate(S):
pos[char].append(idx)
# print(pos)
cnt = 0
# 各文字(a, b, c...)について調べる
for char in pos:
indices = pos[char]
n_char = len(indices)
# print("char: ", char)
# indices[j] に対して、L <= indices[j] - indices[i] <= R を満たす i の個数を探す
left = 0
right = 0
for j in range(n_char):
# indices[i] が入るべき範囲の下限と上限
lower_bound = indices[j] - R
upper_bound = indices[j] - L
# lower_bound 以上となる最小の i (left) を探す
while left < j and indices[left] < lower_bound:
left += 1
# upper_bound 以下となる最大の i (right) を探す
while right < j and indices[right] <= upper_bound:
right += 1 # rightは条件を満たさなくなった最初の要素で止まる
# この j に対して条件を満たす i は [left, right) の範囲
if left < right:
cnt += (right - left)
print(cnt)
if __name__ == '__main__':
main()
ポイント
- 問題文をそのまま素直に実装すると、距離(idx)を固定して文字列を走査することを思いつきますが、その場合
O((R - L)*N)となりTLEになってしまいます - そのため、文字の種類ごとに位置を記録するという発想の転換を行います
- 最初に「同じ文字 $S_i = S_j$ である」という条件に注目し、アルファベット('a'〜'z')ごとに、その文字が何番目に出現したかのリストを作ります。
ー 例:S = "abaca" なら 'a': [1, 3, 5], 'b': [2], 'c': [4] - その後、各リストの中で、L <= j - i <= R を満たすペアを数えます。この「範囲内の個数」を数えるとき、尺取り法(または bisect などの二分探索)を使うと、2重ループを使わずに済みます。
- 今回行いたい尺取法は、「ある文字の位置リスト(indices)」 の中で、現在の位置 indices[j] に対して以下の範囲に収まる indices[i] がいくつあるかを探すことです。この条件は問題文の$L \le j - i \le R$ をiを中心に整理して、$j - R \le i \le j - L$とした結果です
- 下限:indices[j] - R $\le$ indices[i]
- 上限:indices[i] $\le$ indices[j] - L
- 例えば、$L=2, R=6$、そして今調べている $j$ の位置(値)が $6$ の場合を当てはめてみると以下のようになります
- 下限: $j - R = 6 - 6 = \mathbf{0}$
- 上限: $j - L = 6 - 2 = \mathbf{4}$
⇒ 「$i$ の値(位置)が $0$ 以上 $4$ 以下」
- 尺取り法の流れを示すと以下の図のとおりです

j が増える → 範囲が右にズレる → left と right も右に追いかけるようにしています。なお、while indices[right] <= upper_bound:としているので、条件を満たさなくなったところで止まるようになります
D問題
緑色レベルなので省略(^^;
ABC450(2026年3月21日)
A問題
- 入力例
9
- 回答例
N = int(input())
result = [str(i) for i in range(N, 0, -1)]
print(",".join(result))
B問題
- 入力例
3
45 450
45
- 回答例
N = int(input())
# dist[i][j] で i番目からj番目のコストが取れるようにする
dist = [[0] * (N + 1) for _ in range(N + 1)]
for i in range(1, N):
costs = list(map(int, input().split()))
print(costs)
for j, cost in enumerate(costs):
# i番目から (i+j+1)番目へのコスト
target = i + j + 1
dist[i][target] = cost
print(dist)
# i: 出発地点, j: 到着地点, k: 経由地点
for i in range(1, N + 1):
for j in range(i + 2, N + 1): # i+1は隣なので経由できない、i+2以降を調べる
for k in range(i + 1, j): # i と j の間にある地点 k
# 直行便より「i -> k -> j」の方が安いか
if dist[i][j] > dist[i][k] + dist[k][j]:
print("Yes")
exit()
print("No")
ポイント
-
dist[i][target]で絶対住所にアクセスしやすいように保存しておきます - 3重ループの役割
- 外側2つのループで「直行便($i$ から $j$)」を固定
- 一番内側のループで「寄り道($k$)」を1つずつ試す
C問題
- 入力例
5 15
##########..###
#...#######.###
####....###..##
######.########
########....###
- 回答例
import sys
input = sys.stdin.readline
H, W = map(int,input().split())
S = [input() for _ in range(H)]
# すでに調べたマスを忘れないようにする
checked = [[False]*W for _ in range(H)]
def bfs(si, sj):
out = False # 外につながっているかのフラグ
q = [(si, sj)] # 探索待ちリスト
checked[si][sj] = True # スタート地点をチェック済みにする
# 今いる場所 (i, j) が外周ならこの島は「外」に繋がっている->outをTrueに
for i, j in q:
if i == 0 or i == H-1 or j == 0 or j == W-1:
out = True
# 上下左右を確認
for di, dj in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
ii = i + di
jj = j + dj
if 0 <= ii < H and 0 <= jj < W and S[ii][jj] == '.' and not checked[ii][jj]:
q.append((ii, jj)) # あとからここも探索
checked[ii][jj] = True
print("白マスの島: ", q)
return out
# 全てのマスを見回る
ans = 0
for i in range(H):
for j in range(W):
# 白マスかつまだどの島の調べる対象にもなってなかったら
if S[i][j] == '.' and not checked[i][j]:
if not bfs(i, j):
ans += 1
print(ans)
ポイント
- 白マスの島の数を算出する問題です
- 白マスを見つけたら、そのマスをbfsの判定関数に入れて隣合う白マスがある場合、白マスリスト
qに追加していき、その島が外側に接しているかどうかを調べます- 「探索の起点」を探すループ (メインの for 文): まだ調べていない白マスを 1 つ見つける
- 「隣り合う白マスを広げる」リスト (
q): 見つけた白マスに隣合っている白マスをどんどん追加して、島全体を確定させる - 「性質」をチェックするフラグ (
out): 「探索の起点」を探すループ (メインの for 文)
- ここで確認していることは、①枠内にあること、②白マスであること、③まだチェックしていないこと、です。これを全て満たしているときに
qに追加して探索対象とします。# 上下左右を確認 for di, dj in [(0, 1), (0, -1), (1, 0), (-1, 0)]: ii = i + di jj = j + dj if 0 <= ii < H and 0 <= jj < W and S[ii][jj] == '.' and not checked[ii][jj]: q.append((ii, jj)) # あとからここも探索 checked[ii][jj] = True
D問題
- 入力例
3 10
3 21 9
- 回答例
import sys
input = sys.stdin.readline
N, K = map(int, input().split())
A_list = list(map(int, input().split()))
B = sorted([i%K for i in A_list])
extended_B = B + [x + K for x in B]
print(extended_B)
ans = float('inf')
for i in range(N):
# i番目から (i + N - 1)番目までの差
diff = extended_B[i + N - 1] - extended_B[i]
if diff < ans:
ans = diff
print(ans)
ポイント
-
すべての数 $A_i$ に対して「$K$ を何回でも足せる」ということは、各 $A_i$ を 「$K$ で割った余り」 で考えても同じということです
- 例:$A = [3, 21, 9], K=10$ の場合
- 最大値 21、最小値 3 → 21 - 3 = 18
- 余りをとる$A = [3, 1, 9]
- 最大値 9、最小値 1 → 9 - 1 = 8
- 元の数列の差も10で割れば余り8
- 例:$A = [3, 21, 9], K=10$ の場合
-
まず、各 $A_i$ を $K$ で割った余りに置き換えます。そうすると、「すべての $A_i$ を $0 \le A_i < K$ の範囲」に収まることになります
- 余りをとる [3, 1, 9]
- ソートする [1, 3, 9]
-
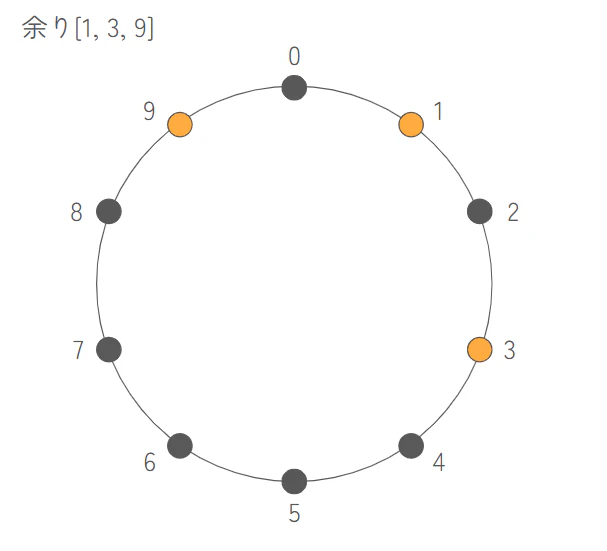
この数字を $K$ で割った余りにして、円の上に並べてみます。こうすることで、数字がバラバラに見えても、位置関係が分かります。これを3つの点を円に沿いながら線でつなぐとき、どの経路が一番短いかを考えます
-
$K$ で割った余りで考えたのでそれぞれの数字は $K$ を足すと「一周」して戻ってくるようになります。つまり、$K$ の倍数のズレを無視すれば、実質的な位置は 1時、3時、9時 の場所に固定されています
-
この図を見ると、1と3の間は『2』、3と9の間は『6』、9と1の間は『2』離れています。このどこか一つの間の距離を見ないようにして、3つの数字をつなぐ最短の道を探します
-
先ほどのソートした配列にそれぞれ $K$ を足したものを後ろにくっつけます
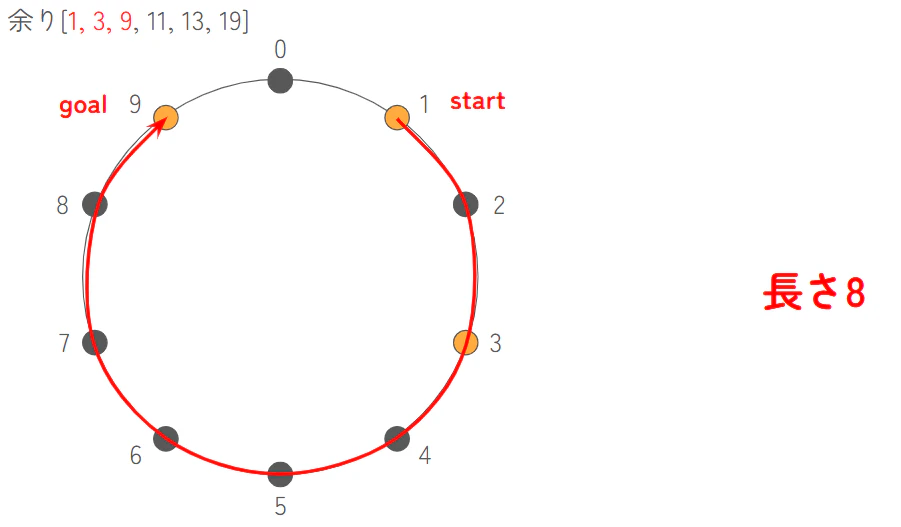
- 拡張した配列: [1, 3, 9, 11, 13, 19]
-
この拡張した配列の中で、「連続する $N$ 個」 を選んで最大値と最小値をチェックしていきます
- [1, 3, 9]: 最大値 9、最小値 1 → 9 - 1 = 8
- [3, 9, 11]: 最大値 11、最小値 3 → 11 - 3 = 8
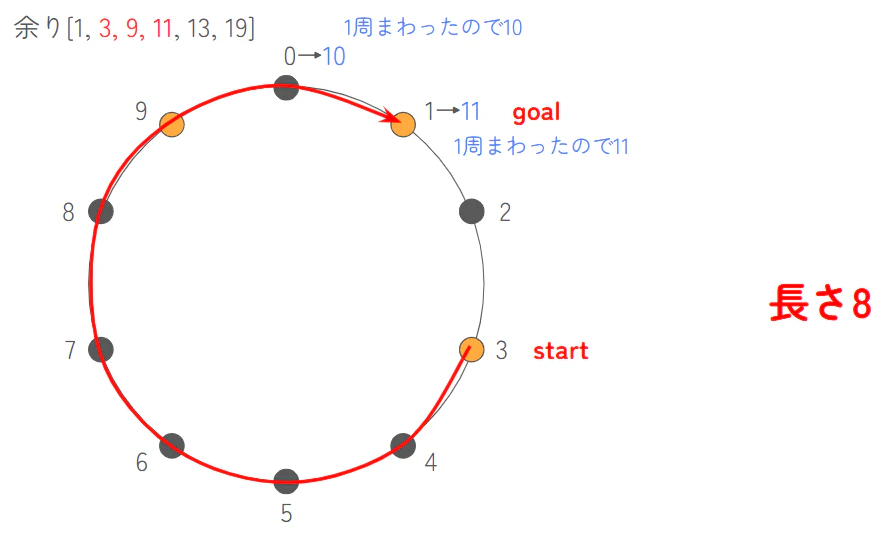
- [9, 11, 13]: 最大値 13、最小値 9 → 13 - 9 = 4
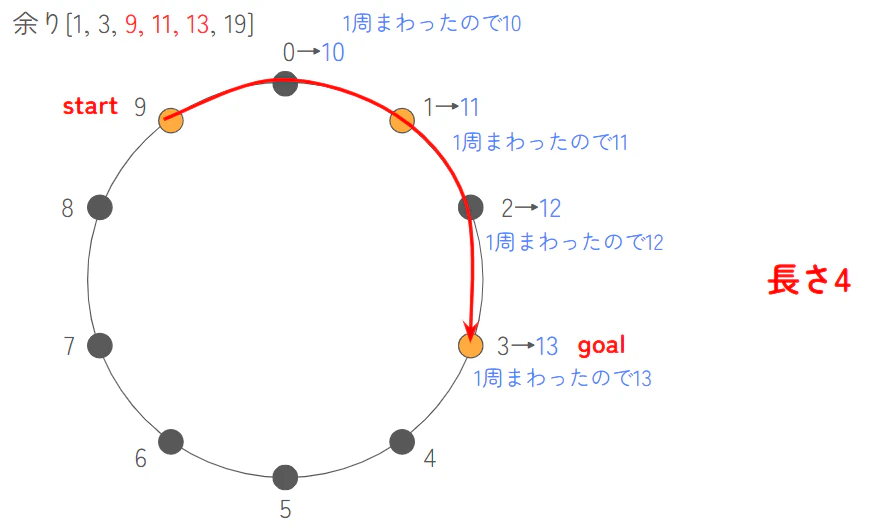
- [1, 3, 9]: 最大値 9、最小値 1 → 9 - 1 = 8
-
ここから最小の長さは4と分かります
ABC451(2026年3月28日)
A問題
- 入力例
legal
- 回答例
S = input()
if len(S) % 5 == 0:
print("Yes")
else: print("No")
B問題
- 入力例
5 4
1 2
2 1
3 1
2 2
2 4
- 回答例
N, M = map(int, input().split())
# 差分の管理
diff = [0] * (M + 1)
for i in range(N):
A, B = map(int, input().split())
# 今期所属する部門からは 1 減らす
diff[A] -= 1
# 来期所属する部門には 1 足す
diff[B] += 1
# 結果を出力
for m in range(1, M + 1):
print(diff[m])
C問題
- 入力例
5
1 5
1 7
1 8
2 7
1 3
- 回答例
import sys
input = sys.stdin.readline
import heapq
def main():
Q = int(input())
hq = [] # 木の高さを入れるヒープ(優先度付きキュー)
for _ in range(Q):
A, B = map(int, input().split())
if A == 1:
heapq.heappush(hq, B) # 木を追加
else:
# 「一番低い木」が B以下である限り抜いていく
while hq and hq[0] <= B:
heapq.heappop(hq) # 削除
# 残った数を出力
print(len(hq))
if __name__ == "__main__":
main()
ポイント
- 問題文から「木の追加」と「高さB未満の木の取り出し」が何度もあると分かります。都度ソートして最小値を取り出すとTLEになってしまうので、
heapqを使って最小値を常に先頭に置きます。 -
heapqの使い方import heapq hq = [] # 要素を追加する(heappush) heapq.heappush(hq, 10) heapq.heappush(hq, 5) heapq.heappush(hq, 15) # この時点で、hq[0] は必ず最小値の「5」になる print(hq[0]) # 5 # 最小値を取り出す(heappop) min_val = heapq.heappop(hq) print(min_val) # 5 # 5が消えたので、次に小さい「10」が自動的に先頭(hq[0])に来る print(hq[0]) # 10
D問題
- 入力例
10
- 回答例
import heapq
def solve():
N = int(input())
# 2の冪パーツ(単体で「良い整数」になるもの)
powers_of_2 = []
p = 1
while p <= 10**9:
powers_of_2.append(p)
p *= 2
# print("powers_of_2: ", powers_of_2)
# 最初はパーツ単体をすべて入れる
heapq.heapify(powers_of_2)
seen = set(powers_of_2)
# パーツを文字列として持っておく(結合用)
parts_str = [str(p) for p in powers_of_2]
# print("parts_str: ", parts_str)
count = 0
# 候補となる数字がまだヒープの中にある限り、小さい順に取り出し続る
while powers_of_2:
curr = heapq.heappop(powers_of_2)
# print("curr: ", curr)
count += 1
# N番目を取り出したらそれが答え
if count == N:
print(curr)
return
# 今の数字の後ろにパーツをくっつけて新しい「良い整数」を作る
curr_str = str(curr)
for p_str in parts_str:
next_str = curr_str + p_str
# 10^9を超えないかチェック(長さで概算して速める)
if len(next_str) > 10:
continue
next_val = int(next_str)
if next_val <= 10**9 and next_val not in seen:
seen.add(next_val)
heapq.heappush(powers_of_2, next_val)
solve()
ポイント
- すべての良い整数を一度に作ろうとせず、小さいものから順々に作っていくようにします
- 「良い整数」は、1, 2, 4, 8, 16... という特定のピースだけを使って作れる数字です。普通にピースを組み合わせていくと、桁数が増えたり数字が変わったりして、生成される順番はバラバラになります。そこで
heapqを使って、新しく作った数字をとりあえず全部 heapqに追加します。heappop を使えば、この中で 「今一番小さい数字」 が自動的に選ばれます。これを $N$ 回繰り返せば、確実に $N$ 番目に小さい数字にたどり着いてくれます
以上です。読んでいただきありがとうございました。