BQML で分類モデルを使用して訪問者の購入を予測するをやってみた(その1)の続き
Predict Visitor Purchases with a Classification Model in BQMLのIdentify an objectiveから
Identify an objective
目的を特定する
次に、BigQueryで機械学習モデルを作成して、新しいユーザーが将来購入する可能性があるかどうかを予測します。 これらの価値の高いユーザーを特定することで、マーケティングチームが特別なプロモーションや広告キャンペーンでターゲットにして、eコマースサイトへの訪問の間に買い物を比較しながらコンバージョンを確保することができます。
Select features and create your training dataset
機能を選択してトレーニングデータセットを作成する
Google Analyticsは、このeコマースWebサイトへのユーザーのアクセスに関するさまざまな側面と対策を把握しています。 ここで完全なフィールドのリストを閲覧してからデモデータセットをプレビューして、機械学習モデルがあなたのウェブサイトでの訪問者の初回についてのデータとそれらが戻ってきて購入するかどうかの関係を理解するのに役立ちます。
あなたのチームは、これら2つのフィールドがあなたの分類モデルにとって良い入力であるかどうかをテストすることにしました。
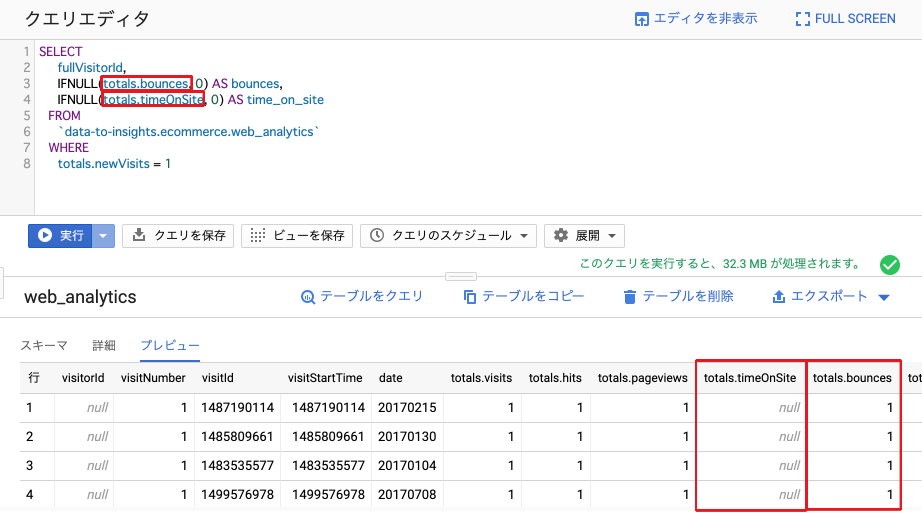
totals.bounces(訪問者がすぐにウェブサイトを離れたかどうか)
totals.timeOnSite(訪問者が当社のWebサイトにアクセスしていた期間)
Question: What are the risks of only using the above two fields?
質問:上記の2つのフィールドだけを使用した場合のリスクは何ですか?
答え:機械学習はそれに与えられるトレーニングデータと同じくらい良いだけです。 あなたの入力機能とあなたのラベルの間の関係(この場合、訪問者が将来購入したかどうか)を決定して学ぶのに十分な情報がモデルにないならば、あなたは正確なモデルを持っていないでしょう。 これら2つのフィールドだけでモデルをトレーニングすることは始まりですが、正確なモデルを作成するのに十分なものかどうかがわかります。
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1)
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
ORDER BY time_on_site DESC
LIMIT 10;
クエリ解読
分解して考える
前半
IFNULL(A,B)とはAがNULLでない場合はAを返し、NUllの場合はBを返すという意
(SELECT
fullVisitorId, #ユニーク訪問者ID
#totals.bounces(訪問者がすぐにウェブサイトを離れたかどうか)がnullでなければそのままいれる nullだったら0
IFNULL(totals.bounces, 0) AS bounces,
#otals.timeOnSite(訪問者が当社のWebサイトにアクセスしていた期間) がnullでなければそのままいれる nullだったら0
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
#totals.newVisitsが1であれば
totals.newVisits = 1)
| 行 | fullVisitorId | bounces | time_on_site |
|--:|--:|--:|--:|--:|
| 1 |8408031500083978531 |1 |0 |
| 2 |7061885047362906241 |1 |0 |
| 3 |9687855392373820534 |1 |0 |
| 4 |8503872733389952374 |1 |0 |
このクエリは新しい訪問者のfullVisitorIdとtotals.bounces(訪問者がすぐにウェブサイトを離れたかどうか)とotals.timeOnSite(訪問者が当社のWebサイトにアクセスしていた期間)のテーブルをつくっている
後半
これは前の項目で書いたSQLと同じで
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
前半のクエリではdata-to-insights.ecommerce.web_analyticsテーブルから、fullvisitorid:ユニーク訪問者のIDとtotals.transactions:取引回数が0より多いか,
totals.newVisits:訪問回数がNullか数を数え、それが0より多ければ1 0であれば 0のカラムをつくる.
またこのカラムはwill_buy_on_return_visitという別名をつける
最後にGROUP BY fullvisitorid:ユニーク訪問者でまとめる
ここまでをテーブルにすると下記のようになる
| 行 | fullvisitorid | will_buy_on_return_visit |
|--:|--:|--:|--:|
| 1 |2998819887239951330 |0 |
| 2 |3890472663740298178 |0 |
| 3 |4618082091026474514 |0 |
JOIN関数
JOIN関数で
| 行 | fullVisitorId | bounces | time_on_site |
|--:|--:|--:|--:|--:|
| 1 |8408031500083978531 |1 |0 |
| 2 |7061885047362906241 |1 |0 |
| 3 |9687855392373820534 |1 |0 |
| 4 |8503872733389952374 |1 |0 |
と
| 行 | fullvisitorid | will_buy_on_return_visit |
|--:|--:|--:|--:|
| 1 |2998819887239951330 |0 |
| 2 |3890472663740298178 |0 |
| 3 |4618082091026474514 |0 |
結合し
USING (fullVisitorId)で2つの表の同じ名前の列のうち、USING句で指定した列(fullVisitorId)のみを等価結合の結合条件として使用している
クエリ全体
SELECT
# 差集合をつかう
* EXCEPT(fullVisitorId)
FROM
# 1つ目のテーブル
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1)
# JOINさせる
JOIN
# 2つ目のテーブル
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
#USING句で指定した列(fullVisitorId)のみを等価結合の結合条件として使用している
USING (fullVisitorId)
# time_on_site(訪問者が私達のウェブサイトにいた期間)で並び替え
ORDER BY time_on_site DESC
LIMIT 10;
出力結果
| 行 | bounces | time_on_site | will_buy_on_return_visit |
| 2 | 0 | 12136 | 0 |
| 3 | 0 | 11201 | 0 |
| 4 | 0 | 10046 | 0 |
| 5 | 0 | 9974 | 0 |
| 6 | 0 | 9564 | 0 |
| 7 | 0 | 9520 | 0 |
| 8 | 0 | 9275 | 1 |
| 9 | 0 | 9138 | 0 |
| 10 | 0 | 8872 | 0 |
入力はbounces(訪問者がすぐにウェブサイトを離れたかどうか)とtime_on_site(訪問者が私達のウェブサイトにいた期間)です。
ラベルはwill_buy_on_return_visitです。
Question: Which two fields are known after a visitor's first session?
質問:訪問者の最初のセッションの後に知られている2つの分野はどれですか?
回答:訪問者の最初のセッションの後、bounces(訪問者がすぐにウェブサイトを離れたかどうか)とtime_on_site(訪問者が私達のウェブサイトにいた期間)は判明しています。
Question: Which field isn't known until later in the future?
質問:どの分野が将来知られていますか?
回答:will_buy_on_return_visitは最初の訪問の後にはわからない。
繰り返しますが、あなたは自分のWebサイトに戻って購入したユーザーのサブセットを予測しています。あなたは予測時に未来を知らないので、新しい訪問者が戻ってきて購入するかどうかを確実に言うことはできません。 MLモデルを構築することの価値は、最初のセッションについて収集されたデータに基づいて将来の購入の可能性を得ることです。
Question: Looking at the initial data results, do you think time_on_site and bounces will be a good indicator of whether the user will return and purchase or not?
質問:初期データの結果を見ると、time_on_siteとbounceは、ユーザーが返品して購入するかどうかの良い指標になると思いますか?
回答:モデルのトレーニングや評価を行う前に言うのは時期尚早ですが、一見したところ、トップ10のtime_on_siteから1人の顧客しか購入しなかったため、あまり期待できません。モデルがどれだけうまくいくか見てみましょう。
Create a BigQuery dataset to store models
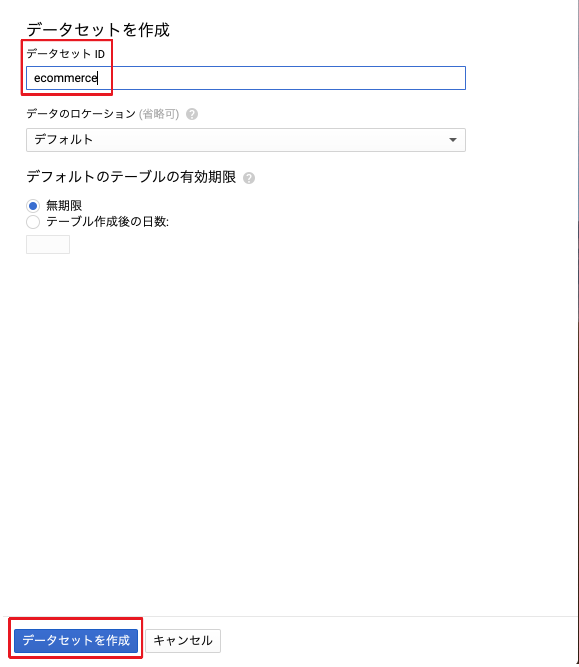
モデルを格納するためのBigQueryデータセットを作成する
次に、MLモデルも格納する新しいBigQueryデータセットを作成します。
-
左側のペインで、プロジェクト名をクリックしてから[データセットの作成]をクリックします。
-
[データセットの作成]ダイアログで、[データセットID]に「eコマース」と入力します。
-
他の値はデフォルトのままにしてください。
-
データセットの作成をクリックします。
目的を確認するには、[進捗状況を確認する]をクリックします。
Select a BQML model type and specify options
BQMLモデルタイプを選択してオプションを指定する
初期機能が選択されたので、BigQueryで最初のMLモデルを作成する準備が整いました。
選択可能な2つのモデルタイプがあります。
| モデル | モデルの種類 | ラベルデータタイプ | 例 |
|---|---|---|---|
| 予測 | linear_reg | 数値(通常は整数または浮動小数点) | 過去の売上データをもとに、来年の売上高を予測 |
| 分類 | logistic_reg | バイナリ分類の場合は0または1 | 状況に応じて、電子メールをスパムとして分類するか、スパムではないかに分類します。 |
注:機械学習で使用される多くの追加のモデルタイプ(ニューラルネットワークや決定木など)があり、TensorFlowなどのライブラリを使用して利用できます。 これを書いている時点で、BQMLは上記の2つをサポートしています。
どのモデルタイプを選ぶべきですか?
あなたは訪問者を「将来購入する」または「将来購入しない」にまとめているので、分類モデルでlogistic_regを使用してください。
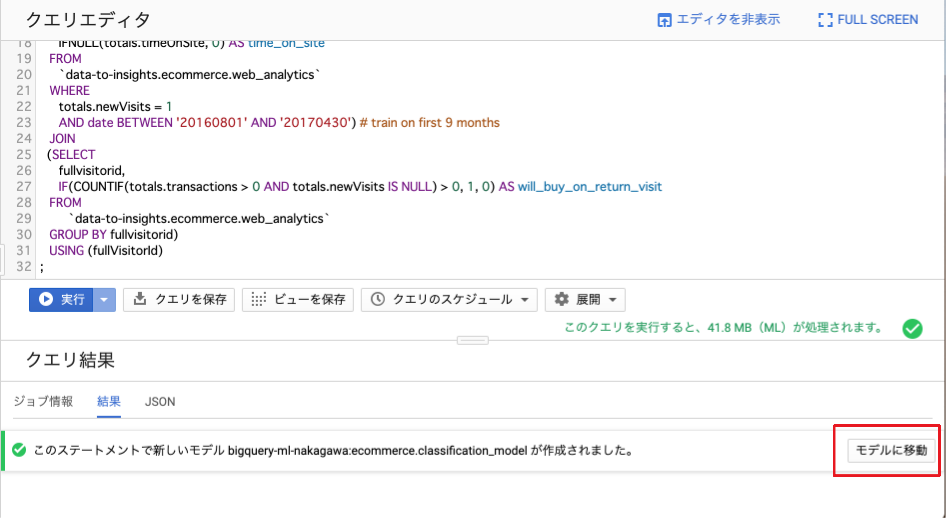
以下のクエリを入力してモデルを作成し、モデルオプションを指定します。
CREATE OR REPLACE MODEL `ecommerce.classification_model`
OPTIONS
(
model_type='logistic_reg',
labels = ['will_buy_on_return_visit']
)
AS
# standardSQL
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430') # train on first 9 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
;
クエリ解読
クエリ前半
モデルを作るとき、新しく作ったecommerceのグループの中にclassification_modelという名前のモデルが作成される
オプションで分類モデルでlogistic_regを指定している
ラベルの名前は'will_buy_on_return_visit'
CREATE OR REPLACE MODEL `ecommerce.classification_model`
OPTIONS
(
model_type='logistic_reg',
labels = ['will_buy_on_return_visit']
)
AS
クエリ後半
# standardSQL
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430') # train on first 9 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
;
AND date BETWEEN '20160801' AND '20170430')の条件が追加されている
これははじめの9ヶ月のみを対象としている。それ以外は前回と同様のクエリである
学習させる
次に、[実行]をクリックしてモデルを学習させます。
モデルが訓練するのを待ちます(5 - 10分)。
注:モデルの評価とテストのために目に見えないデータポイントをいくつか保存する必要があるため、トレーニング中に利用可能なデータすべてをモデルに入力することはできません。 これを実現するには、12ヶ月データセットのセッションデータの最初の9ヶ月のみをフィルタリングして学習するためにWHERE句条件を使用します。
目的を確認するには、[進捗状況を確認する]をクリックします。
モデルのトレーニングが終わると、「このステートメントにより、qwiklabs-gcp-xxxxxxxxx:ecommerce.classification_modelという名前の新しいモデルが作成されました」というメッセージが表示されます。
[モデルに移動]をクリックします。
eコマースデータセットを調べて、classification_modelが表示されていることを確認します。
次に、目に見えない新しい評価データに対してモデルのパフォーマンスを評価します。
新しいモデルができたことを確認した
Evaluate classification model performance
分類モデルのパフォーマンスを評価する
Select your performance criteria
業績基準を選択してください
MLの分類問題では、False Positive Rateを最小化し(ユーザーが返品して購入すると予測し、そうしないと予測する)、True Positive Rateを最大化します(ユーザーが返品と購入すると予測します)。
この関係は、下の図のようなROC(Receiver Operating Characteristic)曲線で視覚化されます。ここでは、曲線の下の領域またはAUCを最大化しようとします。
BQMLでは、訓練されたMLモデルを評価するとき、roc_aucは単なる照会可能フィールドです。
ここの言っていることがいまいちよくわからなかった
参考文献を見る限り、それが本当に良いモデルができたかどうかがわからないので、このモデル自体を評価しようという話だと解釈した。
どうやらroc_aucというのが大事な値らしい
AUCが1に近いほど=ROCで囲われている面積の大きいほうがモデル性能が高い
とのことなのでとにかく1にどれくらい近づいているのかということを検証しているのだと思う。
参考文献
[【ROC曲線とAUC】機械学習の評価指標についての基礎講座]](http://www.randpy.tokyo/entry/roc_auc)
トレーニングが完了したので、ML.EVALUATEを使用して、このクエリでモデルがどの程度うまく機能するかを評価できます。
ML.EVALUATE 関数とはモデルの指標を評価するものらしい
実行するクエリ
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'decent'
WHEN roc_auc > .6 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model, (
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630') # eval on 2 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
));
クエリ解読
前半
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'decent'
WHEN roc_auc > .6 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model, (
roc_aucの値によって、良い、普通、悪いなどの評価をあたえることができそう
ML.EVALUATE関数の中に、評価をしたいモデル(ecommerce.classification_model)を入れている
後半
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630') # eval on 2 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
));
後半は前回とほぼ変わらない
期限がdate BETWEEN '20170501' AND '20170630')が変更されている
クエリの結果
| ||
|:--|:--|:--|
| 行 | roc_auc | model_quality | |
| 1 | 0.724574 | decent |
モデルを評価すると、roc_aucが0.72になります。これは、そのモデルの予測力が良好ではないが優れていることを示しています。 目標は、曲線の下の面積をできるだけ1.0に近づけることであるため、改善の余地があります。
このモデルだとまだまだ1に近づけられる余地があるから他の値でもためしてみようということなのだろう
Improve model performance with Feature Engineering
Feature Engineeringを使用してモデルのパフォーマンスを向上させる
前に示唆したように、モデルが訪問者の最初のセッションと次回の訪問時に購入する可能性との関係をよりよく理解するのに役立つ可能性があるデータセットには、さらに多くの機能があります。
いくつかの新機能を追加して、種別_モデル_2という2番目の機械学習モデルを作成します。
・最初の訪問時に訪問者がチェックアウトプロセスにどれだけの距離をおいた
・訪問者がどこから来たか(トラフィックソース:オーガニック検索、参照サイトなど)
・デバイスカテゴリ(モバイル、タブレット、デスクトップ)
・地理情報(国)
以下のクエリを実行して、この2番目のモデルを作成します。
クエリ
CREATE OR REPLACE MODEL `ecommerce.classification_model_2`
OPTIONS
(model_type='logistic_reg', labels = ['will_buy_on_return_visit']) AS
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430' # train 9 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
);
クエリ解読
(前半)
# ecommerce.classification_model_2という新しいモデルをつくる
CREATE OR REPLACE MODEL `ecommerce.classification_model_2`
# オプションはlogistic_regを設定 ラベルはwill_buy_on_return_visitを設定
OPTIONS
(model_type='logistic_reg', labels = ['will_buy_on_return_visit']) AS
# all_visitor_statsという仮テーブルをつくる(前回と同じようなテーブルができる)
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
all_visitor_statsはこういう結果がかえってくる
| 行 | total_visitors | will_buy_on_return_visit |
| 1 | 729848 | 0 |
| 2 | 11873 | 1 |
(後半)
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# ラベル
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# サイトでのふるまい
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# どこからきたのか
trafficSource.source,
trafficSource.medium,
channelGrouping,
# モバイルかデスクトップか
device.deviceCategory,
# 国別情報
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# 新規訪問のみを対象
AND totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430' # 9ヶ月
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
後半で作られるテーブルの内容はこのような感じになる
| 行 | unique_session_id | will_buy_on_return_visit | latest_ecommerce_progress | bounces | time_on_site | pageviews | source | medium | channelGrouping | deviceCategory | country | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 74143611894107420091481927107 | 0 | 3 | 0 | 532 | 32 | dfa | cpm | Display | desktop | United States | |
| 2 | 17884635900290040041470125424 | 0 | 0 | 1 | 0 | 1 | dfa | cpm | Display | desktop | Canada | |
| 3 | 92206037068936851811473183867 | 0 | 0 | 0 | 11 | 3 | dfa | cpm | Display | desktop United States | ||
| 4 | 86364417586190885091484751347 | 0 | 0 | 1 | 0 | 1 | dfa | cpm | Display | desktop | United States |
注:この新しいモデルを使用しても、最初の9か月分のデータについてはまだトレーニング中です。
新しいトレーニングデータや異なるトレーニングデータではなく、
優れたモデル出力が優れた入力機能に起因すると確信できるように、同じトレーニングデータセットを持つことが重要です。
トレーニングデータセットクエリに追加された重要な新機能は、各訪問者がセッションで到達した最大のチェックアウトの進行状況です。
これはhits.eCommerceAction.フィールドに記録されています。
フィールド定義でそのフィールドを検索すると、6 = Completed Purchaseのフィールドマッピングが表示されます。
余談ですが、Web分析データセットにはARRAYSのような入れ子になった繰り返しフィールドがあり、
データセット内で別々の行に分割する必要があります。 これはUNNEST()関数を使用することによって達成されます。これは上記の照会で見ることができます。
新しいモデルがトレーニングを終了するのを待ちます(5〜10分)。
この新しいモデルを評価して、より優れた予測力があるかどうかを確認します。
表でいうとlatest_ecommerce_progressが各訪問者がセッションで到達した最大のチェックアウトの数らしい
# standardSQL
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'decent'
WHEN roc_auc > .6 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model_2, (
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630' # eval 2 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
));
実行すると下記のテーブルが作成される
| 行 | roc_auc | model_quality |
| 1 | 0.910393 | good |
この新しいモデルでは、roc_aucが0.91となり、最初のモデルよりもはるかに優れています。
訓練されたモデルが完成したので、次に予測を行います。
Predict which new visitors will come back and purchase
どの新規訪問者が戻ってきて購入するかを予測する
次に、どの新しい訪問者が戻ってきて購入するかを予測するためのクエリを作成します。
以下の予測クエリでは、Google商品ストアを初めて訪れた人が後の訪問で購入する可能性を予測するために、改良された分類モデルを使用しています。
SELECT
*
FROM
ml.PREDICT(MODEL `ecommerce.classification_model_2`,
(
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
SELECT
CONCAT(fullvisitorid, '-',CAST(visitId AS STRING)) AS unique_session_id,
# ラベル
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# サイトに対する振る舞い
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# どこから訪問してきたのか 流入元
trafficSource.source,
trafficSource.medium,
channelGrouping,
# モバイルかデスクトップか
device.deviceCategory,
# くに情報
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE
# 新規訪問のみを予測する
totals.newVisits = 1
AND date BETWEEN '20170701' AND '20170801' # test 1 month
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
)
ORDER BY
predicted_will_buy_on_return_visit DESC;
予測は、データセットの最後の1ヶ月(12ヶ月のうち)に行われます。
これで、モデルは2017年7月のeコマースセッションに関する予測を出力します。 新しく追加された3つのフィールドを見ることができます。
predict_will_buy_on_return_visit:訪問者が後で買うとモデルが考えているかどうか(1 =はい)
predict_will_buy_on_return_visit_probs.label:yes / noのバイナリ分類器
predict_will_buy_on_return_visit.prob:モデルの予測に対する信頼度(1 = 100%)
ORDER BY predicted_will_buy_on_return_visit DESC;をつけるだけ・・・・?
作られたテーブルは下記のような感じになる
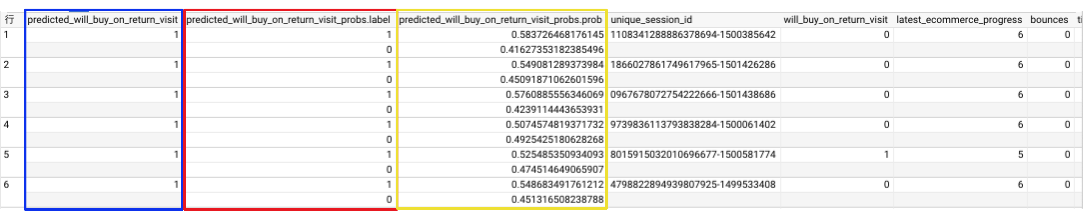
Results
結果
初めての訪問者の上位6%(予測確率の降順でソートされています)のうち、6%以上が後の訪問で購入します。
これらのユーザーは、後の訪問で購入するすべての初めての訪問者のほぼ50%を占めます。
全体的に見て、初めての訪問者のわずか0.7%が後の訪問で購入をします。
初回の上位6%をターゲットにすると、マーケティングのROIは9倍になります。