【はじめに】
PandasはPythonで利用できる、データ解析のためのライブラリです。- データの読み込みや統計量の表示
- データのグラフ化
- データ分析
今回は、誰でもpandasを使いこなすための第一歩として基本的な使い方を紹介します。
※一部違うライブラリを使用する場面があります。
本記事の内容
- pandasをインポートする
- CSVファイルを読み込む
- データ型を確認する
- データフレームの情報を取得する
- 統計量を取得する
- グループごとに集計する
- データを並べ替える
- グラフ化する
【pandasをインポートする】
import pandas as pd
ポイント
as pdとして読み込むことでpandasを「pd」として使用することができます。
【CSVファイルを読み込む】
「1920年から2015年までの全国の人口推移のデータ」を使用します。
私のGitHubに「data.csv」としてアップロードしてあるので、下記コマンドでダウンロードすれば簡単に準備できます。
$ curl https://raw.githubusercontent.com/nakachan-ing/python-references/master/Pandas/data.csv -O
df = pd.read_csv('data.csv', encoding='shift-jis')
df
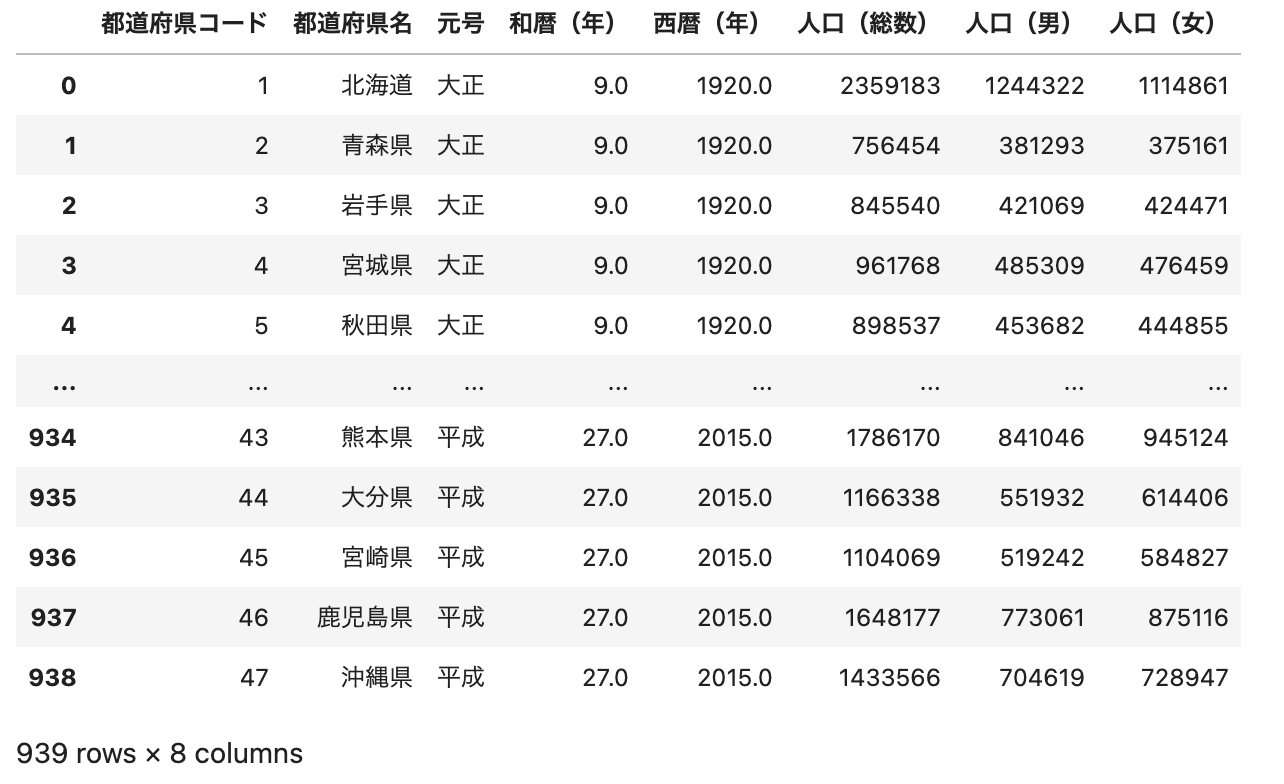
ポイント
pd.read_csv('csvファイル名', encoding='文字コード')-
encodingオプションを指定しないと次のようなエラーが発生することがあります。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 0: invalid start byte
【データ型を確認する】
type(df)
>>pandas.core.frame.DataFrame
ポイント
-
type()でデータ型を確認することができます。 - pandasのデータ型には、今回読み込んだようなデータフレーム(DataFrame)とシリーズ(Series)があります。
- データフレームは、Excel形式のように行(index)と列(column)で成り立っています。
- シリーズはデータフレームから一列だけ取り出したものです。
【データフレームの情報を取得する】
df.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 939 entries, 0 to 938
Data columns (total 8 columns):
Column Non-Null Count Dtype
0 都道府県コード 939 non-null int64
1 都道府県名 939 non-null object
2 元号 939 non-null object
3 和暦(年) 939 non-null float64
4 西暦(年) 939 non-null float64
5 人口(総数) 939 non-null int64
6 人口(男) 939 non-null int64
7 人口(女) 939 non-null int64
dtypes: float64(2), int64(4), object(2)
memory usage: 58.8+ KB
ポイント
info()でデータフレームの情報を取得することができます。
【統計量を取得する】
df.describe()

ポイント
describe()で統計量を取得することができます。
- count:数量
- mean:平均
- std:標準偏差
- min:最小値
- 25%:1/4分位数
- 50%:中央値(median)
- 75%:3/4分位数
- max:最大値
df.describe().round(0)
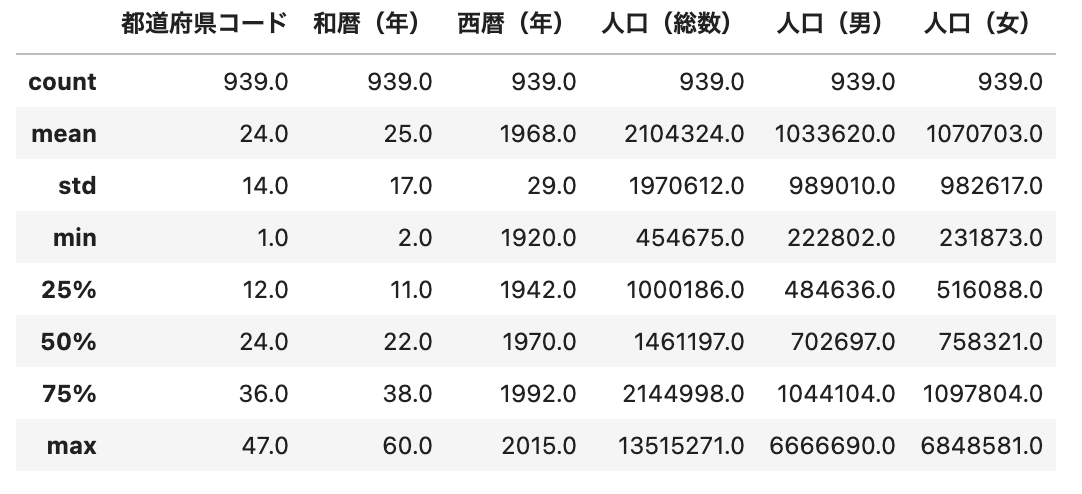
round()を使用することで、桁数を指定して数値の切り捨て/切り上げをすることができます。
【グループごとに集計する】
# データフレームの先頭5行を表示
df.head()
df_mean = df.groupby(by='都道府県名').mean()[['人口(総数)', '人口(男)', '人口(女)']].round(0)
df_mean.head(10)

ポイント
-
groupby(by='グループ分けしたいcolumn')でグループ分けすることができます。 -
mean()の後に[平均を算出したい対象]を指定することができます。 - 複数の対象を指定する場合は
[ [リスト型] ]にします。
【データを並べ替える】
df_mean.sort_values(by='人口(総数)', ascending=False).head(10)
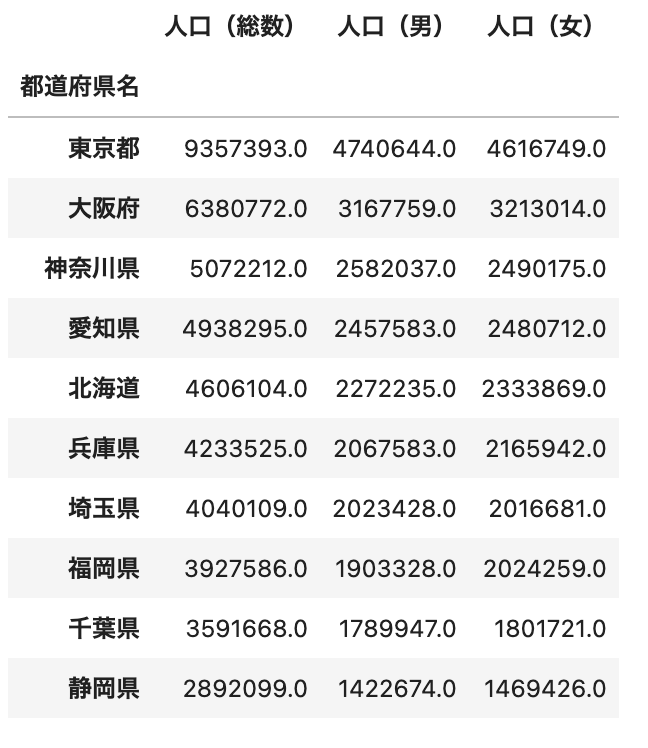
ポイント
-
sort_values(by='並び替えたいcolumn', ascending=True or False)でデータを並べ替えることができます。 -
ascendingオプションにTrueを指定すると「昇順」、Falseを指定すると「降順」に並び替えます。
【グラフ化する】
可視化のための「matplotlib」と日本語を表示させるための「japanize_matplotlib」をインポートします。import matplotlib.pyplot as plt
%matplotlib inline
import japanize_matplotlib
「japanize_matplotlib」のインポートでエラーが発生した場合、PCにライブラリのインストール自体がまだできていない可能性があります。
!pip install japanize-matplotlibでインストール後に再度インポートをします。
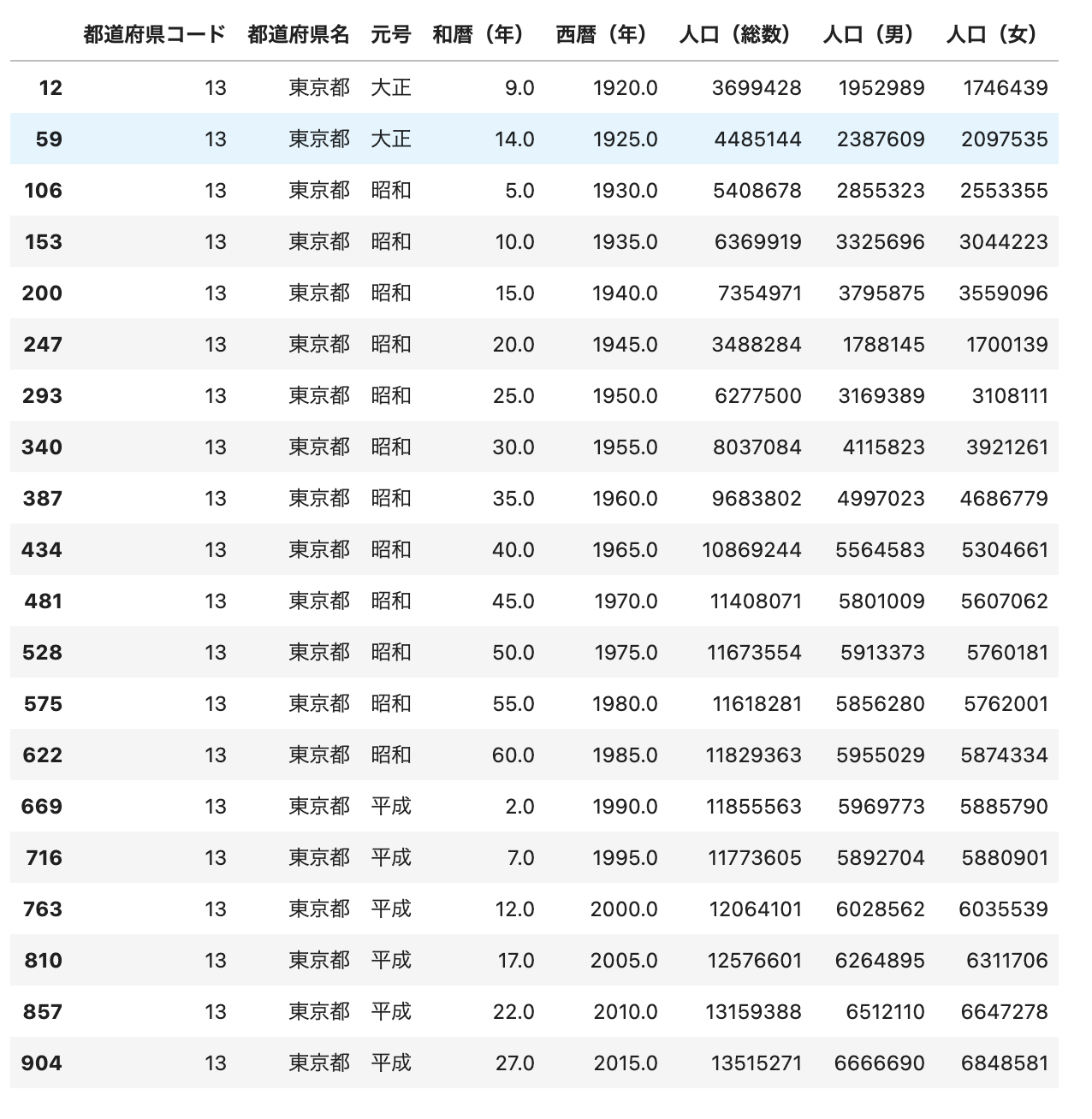
# 「都道府県」が「東京都」のデータのみを抽出
df_tokyo = df[df['都道府県名']=='東京都']
df_tokyo
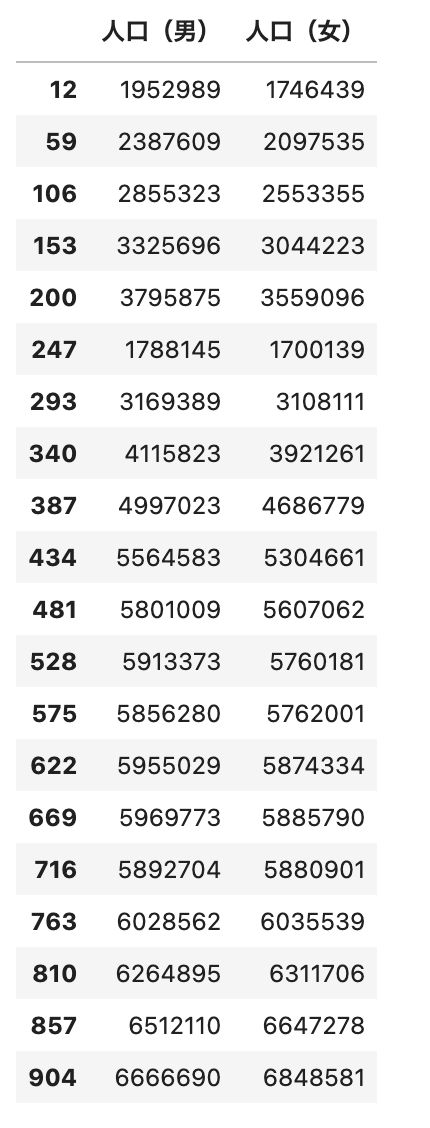
# 東京都の「人口(男)」, 「人口(女)」のデータを抽出
df_tokyo = df_tokyo[['人口(男)', '人口(女)']]
df_tokyo
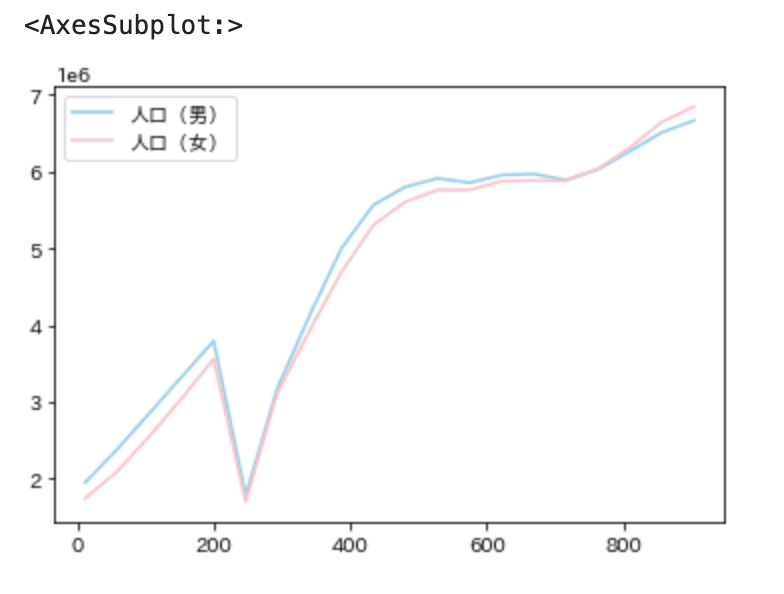
# 東京都の人口(男)、(女)の推移をグラフ化
df_tokyo.plot(color=['skyblue', 'pink'])
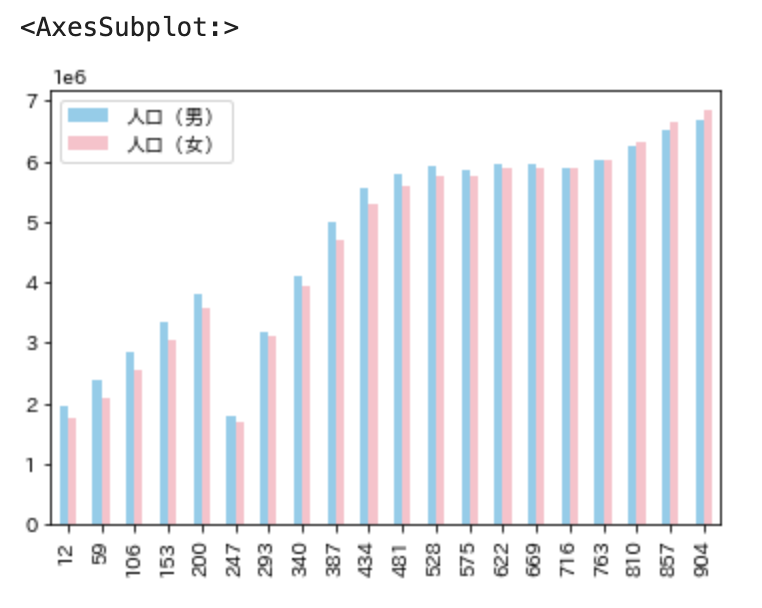
ポイント
plot()の中に引数としてkindにbarを指定すると棒グラフを表示することができます。
df_tokyo.plot(kind='bar', color=['skyblue', 'pink'])
【おわりに】
今回は、Pandasの基本的な使い方を紹介しました。他にも様々な関数が用意されています。特に機械学習に興味のある方は、Pandasを利用すると、効率的に進めることができます。
これからも、Pythonのライブラリや関数の使い方について紹介していきます。
今回、使用したCSVファイルやJupyter NotebookはGitHubに公開しています。
参考にして見てください。