フューチャー Advent Calendar 2020の10日目の記事です。
この記事では今年の9月にリリースされたばかりのライブラリ、TensorFlow Recommendersについての紹介を行います。
レコメンドタスクの特徴について
レコメンドタスクでは、あるユーザーに対して万単位や億単位のアイテムの中からユーザーが気に入りそうなアイテムを選び、順位付けしてアイテムを提示します。そのため、基本的にはユーザーと候補のアイテムをそれぞれ入力カテゴリとして購入するかどうかの二値分類や、レビューの回帰問題として予測し並び替えることが多いです。しかしレコメンドタスクには、一般的な機械学習の分類問題や回帰問題と比較した際にいくつかの特徴と難しい点があります。
- たくさんのユーザー・アイテムの特徴・相性をそれぞれ上手く数値化しないといけない
- ユーザー×アイテムの総数はとても多いが、実際に観測できる組み合わせの数はとても少ない
- ユーザーの好みが明示的にわかるレビューの数はもっと少ないか手に入らない
- 比較的多く手に入るユーザーがアイテムを閲覧したかどうか、購入したかどうかの情報は正例しかない
- 未知のアイテム・ユーザーに対しても予測を行いたい
これらの問題を、tensorflow recommendersでは解決することができます。
2-tower modelについて
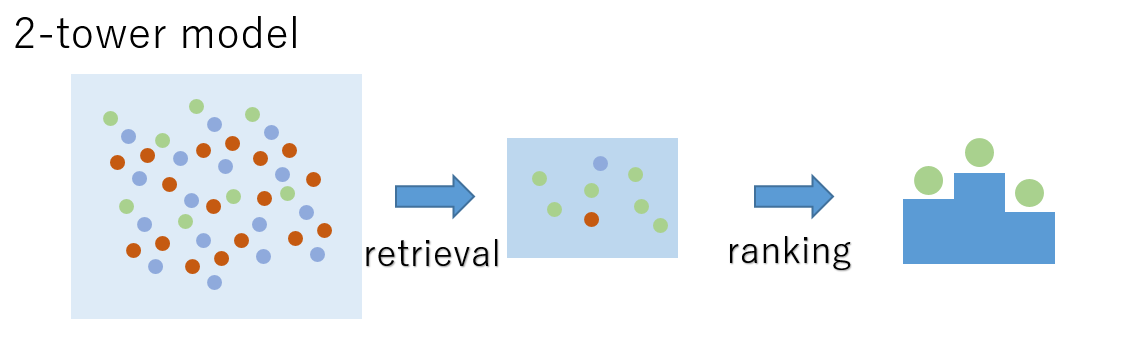
TensorFlow Recommendersはレコメンドタスクを以下の二つに分解してモデル化します。
- たくさんの候補の中からアイテムを絞り込むRetrieval(検索)タスク
- 選んだ候補をより精度高く並び替えをするRanking(順位付け)タスク
精度は荒くても高速に実行できる前者と、計算時間がかかっても正確な結果を出せる後者の二つに分解することにより、計算コストとパフォーマンスの両立を達成することができます。後者は比較的普通の回帰問題を解くので、今回は前者のRetirievalタスクについて紹介します。
Embeddingについて
カテゴリの特徴を表す方法として、一般的にはone-hot encoding(カテゴリごとに01で扱う)やtarget encoding(カテゴリを予測値の平均で表す)が用いられますが、深層学習ではカテゴリをK次元のベクトルで表すEmbedding(埋め込み)を用いることが多いです。このEmbeddingとは色を赤色や黄色の名前で表すのではなく、RGB値やHSV値で表すようなものです。この手法を活用することで、膨大な数のカテゴリをk次元のベクトルとしてあらわすことができます。
Retrieval taskについて
Retrievalタスクでは推薦対象のユーザーと推薦するアイテムの情報を上記のEmbeddingなどを用いてそれぞれk次元のベクトルで表し、その二つの内積の大きさでユーザーに対してアイテムがクリック・購入された組み合わせを1、そうでなかった組み合わせを0で予測します。これにより
- たくさんのユーザー・アイテムをそれぞれ上手く特徴化できる
- 観測したことの無いユーザーxアイテムの組み合わせでも予測できる
- たくさんある正例しかないクリックデータも活用できる
- アイテムのベクトルを事前計算しておけば、高速に多数の組み合わせを評価できる
- 数が豊富なクリックデータで得たEmbeddingを他の学習(ランキング等)に転用できる
といった利点がうまれます。また、k次元のベクトルはそれぞれユーザー・アイテムのembeddingだけでなく、他に付随した情報(カテゴリ・数値・画像・テキストなど)を全結合層などを用いて組み合わせて表現してもよいので
- 未知のユーザー・アイテムに対しても予測することができる
という利点もあります。
学習は一度にN個の組み合わせについて同時に学習を行います。ユーザーのベクトルとアイテムのベクトルをそれぞれNxkの行列で表し、行列積を計算します。行列の対角成分を1、それ以外を0としたラベルで学習を行い、内積はsigmoid softmax関数(2020/12/10修正)で0-1に変換します。
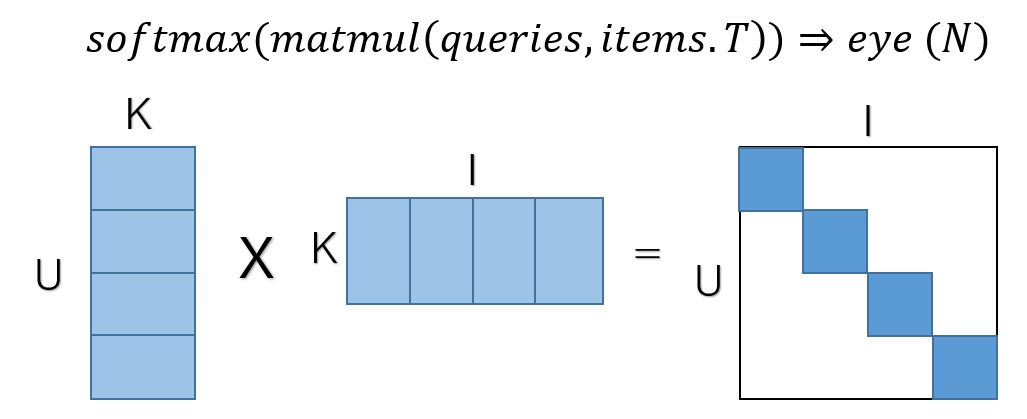
検索については、すべての組み合わせについて内積を計算してもよいのですが、ANN(近似近傍探索)を用いるとより効率的に求めることができます。tensorflow recommendersにはScaNNというgoogle謹製の近似近傍探索の手法が手軽に使えるよう実装されています。
実装について
tensorflow recommendersではモデルをkerasのように容易に構築することができます。トップページの例を見ると分かるのですが、上記のretrieval taskについてこれだけの実装で手軽に実行できるようになっています。
感想
tensorflow recommendersはシンプルに書けて、かつtensorflowの豊富なライブラリでカスタマイズできるので使い勝手が良さそうに感じました。今はv0.3.0ですが、ScaNNの他にも最新の推薦モデルが手軽に使えるよう実装される予定らしいので今後も動向をチェックしていきたいと思います。