こんにちは、nadareです。
機械学習エンジニアで、普段はレコメンド・検索関連のお仕事をしています。いろんな競技プログラミングが好きです。
最近はRetrieval-based-Voice-Conversion(以下RVC)という技術に関心を持ち、本家Retrieval-based-Voice-Conversion-WebUIやddPn08さん版RVC-WebUI、VC ClientにPR投げつつ勉強しています。
本記事では、RVCのモデルで綺麗な日本語に変換するための学習テクニックを紹介します。
2023/05/24 追記
続・RVCのモデルを日本語向けに事前学習するを公開しました。最新の内容にアップデートしたので、こちらもご参照ください。
2023/05/14 16:20追記
これまではITAコーパス読み上げ音声を10~30epoch学習させたもので比較していて、その時点では事前学習済みモデルでないと滑らかな音声は発音できなかったのですが、
試しにJPHuBERTをphone embedderに指定して100epoch学習させてみたところ、デフォルトの重みからでも十分明瞭な音声が作れました。
学習データの量に依存するとは思いますが、引き続き検証を続けていきます。
TL;DR
- このデータセットから事前学習済みの重みをDLする
-
ddPn08さん版RVC-WebUIで
-
Target sampling rateを48kにする -
f0 ModelをYesにする -
Using phone embedderをhubert-japanese-baseにする -
Embedding channelsを768にする
-
-
Target sampling ratePre trained generator pathとPre trained discriminator pathにDLしたファイルのパスを指定して長めに学習する- 滑らかさ重視ならreazonspeech事前学習版(f0D48k768_jphubert_reazonspeech_tuned.pth + f0G48k768_jphubert_reazonspeech_tuned.pth)
- 音声のきれいさ重視ならSHAREVOX:小春音アミチューニング事前学習版(f0D48k768_jphubert_tuned.pth + f0G48k768_jphubert_tuned.pth)
なんで日本語が不安定なの?
RVCの構成要素
RVCの日本語の発音が日本語の上手い英語話者っぽい感じであるのは、事前学習データに由来します。
RVCの構造は以下の図のような3パートに分かれています。
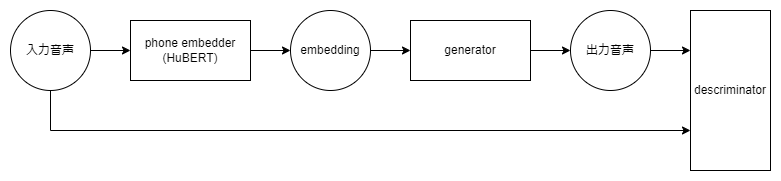
-
phone embedderはHuBERTというモデル構造を使った、ContentVecが使われています。ContentVecはLibrispeechという約1000hの英語の音声データセットで学習されたHuBERT-baseを、同じくLibrispeechを用いてさらに違う方式でトレーニングしなおしています。こちらはRVC中では学習を行わず、入力音声を中間のembedding(情報を持った密なベクトル)に変換します。 -
generatorはembeddingを音声の波形(wavファイル)に変換します。事前学習にはVCTKという50hの英語のデータセットで事前学習されています。これは109人の英語のネイティブスピーカーが約400の調整された文を読み上げるデータセットで、事前学習時は話者のidをヒントとして与えてあげることでEmbeddingから話者以外の情報を読み取ろうと学習を行います。RVCでG経やgeneratorと呼ばれているのはここの部分です。 -
descriminatorは入力音声と出力音声のどちらが本物かの学習を行います。Generative Adversarial Network(敵対的生成ネットワーク)と呼ばれていて、これで音声の質を上げています。RVCでD経やdescriminatorと呼ばれていて、セットで事前学習されています。
この三つのパーツはそれぞれ英語のデータセットで学習されているため、日本語で追加学習を行うと英語訛りが出てしまいます。
jp-hubert-baseの登場
これまではgeneratorとdescriminatorはまだしも、HuBERTを個人で学習するのは困難なためここがネックになっていました。しかし、2023.04.28にrinna株式会社が日本語の音声に特化した事前学習モデルHuBERTを公開しました。これはReazonSpeechという日本語の約19,000時間の商用利用可能な日本語音声コーパスで学習されていて、モデルもHugging FaceにApache-2.0 Licenseで公開されています。
これにより、日本語の特徴を多く含んだEmbeddingを得られるようになりました。ただgeneratorに入力するembeddingが大きく変化したため、generatorがその違いを学びきるのにはたくさんのデータと学習時間を必要するので、RVCでの実用まではもう一歩必要でした。
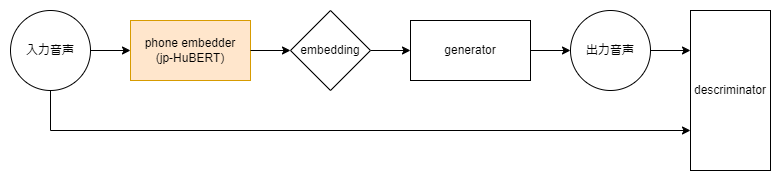
RVCを日本語で事前学習する2つのアプローチ
jp-hubert-baseのembeddingに対応させるため、generatorとdescriminatorを日本語の商用可能なデータセットで再トレーニングを行いました。jp-hubertで無理やり学習させた音声を聞いていると日本語の発音部分を学習しきれていないように感じたので、とにかくたくさんの種類の発音を学べるよう以下の2つのアプローチをとりました。
- VOICEVOXやSHAREVOXといった合成音声読み上げソフトのうち、合成音声を機械学習に利用可能なキャラクターにITAコーパスやJSUTコーパスといった営利利用可能なコーパスを読み上げてもらい学習データに使うアプローチ
- ReazonSpeechから変換したい音声に似た声をPyAnnoteのembeddingモデルで取得し、Ultimate Vocal Removerで声を抽出してから学習させるアプローチ
合成音声読み上げソフトを用いるアプローチ
ITAコーパスの読み上げ音声(424文)の音声はそれなりに公開されていますが、generatorの学習には不十分でした。そこでJSUTコーパスのbasic5000と合わせた5424文を、SHAREVOXの小春音アミさんの4つのstyle(ノーマルv2、喜びv2、怒りv2、悲しみv2)に読ませた21969文(約10GB)を作成しました。(作成スクリプト: https://www.kaggle.com/datasets/nadare/rvc-webui-tuned-weights?select=generate_random_voice.py)
こちらの方法は元の音声が綺麗なので音がクリアになりますが、合成音声の機械らしさが若干残ります。
ReazonSpeechを用いるアプローチ
合成音声読み上げソフトの音声を事前学習に用いた場合、合成音声の機械らしさが若干残るのが課題でした。そこでReazonSpeechの音声から、PyAnnoteのembeddingモデルを用いて変換したい声に近い音声を集めて事前学習に用いました。(抽出用notebook: https://github.com/nadare881/voice-changer-vector-search/blob/main/notebook/ReazonSpeechSimilarVoiceRetrieval.ipynb)
ReazonSpeechはワンセグ放送にアノテーション付けたデータセットなのでBGMや効果音が多く入っていたものの、Ultimate Vocal Removerでボーカルのみを抽出し、学習を行いました。
こちらの方法はワンセグの音声かつ16000Hzの音声でチューニングした影響か若干音が曇るものの、滑らかな日本語を発音できるようになりました。
日本語チューニング版を上手く使うコツ
私が公開しているjp-hubert-base対応版の重みは暫定的なもので、単一話者で学習している影響か、元の話者の影響が残ってしまいます。これはnpyファイルとindexファイルを指定することで改善します。
この辺りは少し古めですがRealtime Voice Changer Client for RVC チュートリアルとして書いたので参考にしてください。
まとめ
RVCを日本語向けに商用利用可能なライセンスのデータセットでチューニングした話を書きました。
今後も事前学習モデルの改善に加え、RVC-WebUIやVC Clientの改善もできる範囲で貢献したいなーと思うので応援のほどお願いします。
また、RVC等ボイスチェンジャー系AIで使える音声を探すためのリポジトリも作成中です。こちらも応援していただければ幸いです。