はじめに
こんにちは、nadareです。
機械学習エンジニアで、普段はレコメンド・検索関連のお仕事をしています。いろんな競技プログラミングが好きです。
最近はRetrieval-based-Voice-Conversion(以下RVC)という技術に関心を持ち、本家Retrieval-based-Voice-Conversion-WebUIやddPn08さん版RVC-WebUI、VC ClientにPR投げつつ勉強しています。
5/14にRetrieval-based-Voice-Conversion-WebUI(以下本家RVC)のv2バージョンが公開されました。v2バージョンではより高品質な音声変換が可能になっており、VCClientも5/21にv2に対応、5/22にはddPn08さんのRVC-webUIでもv2の学習が可能になりました。
前回の記事『RVCのモデルを日本語向けに事前学習する』ではjp-HuBERTに合わせてRVCの事前学習を行いましたが、環境の変化やその後の色々な実験に合わせてよりよい事前学習済みmodelが作れるようになったので、その方法と学習済みのweightを公開したいと思います。
事前学習済みモデルにのみ興味がある方へ
v1に比べv2は日本語の発音もきれいになったので、公式のv2を使うのが一番簡単です。
学習データは量よりも質にこだわり、整った環境で録音されたデータを学習させましょう。
公式で2023/5/24現在配布されているのはcontentvecに対応した40kの重みのみです。
48kで学習したい、JPHuBERTの重みを使いたい人は以下のリンクから学習済みの重みをDLできます。
https://www.kaggle.com/datasets/nadare/rvc-webui-tuned-weights
- f0X48k768_contentvec_v2はContentVec用の事前学習済みモデルです。安定して元の声質に寄せることが可能ですが、日本語の発音が少しだけ苦手です。
- f0X48k768_jphubert_v2はrinna社のjp-hubert-baseに対応した事前学習済みモデルです。日本語の発音が明瞭にはなりますが、変換がやや不安定で、声質を寄せるのもindex ratioを0.8 ~ 1.0にする必要があります。
v1からv2への変更点
RVCの構造は以下の図のような3パートに分かれています。
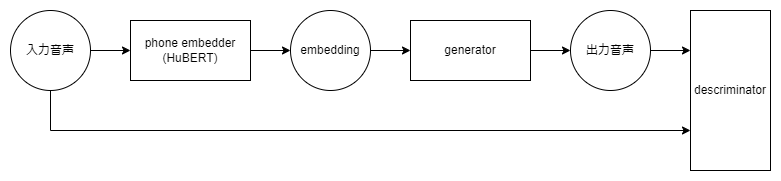
v1からv2へは以下の変更がありました。
- phone embedderにHuBERTの9層目を256次元にprojectした出力から、12層目の768次元の出力をそのまま用いるようになった
- generatorの入力を756次元対応させた
- discriminatorにおいてperiodというパラメーターを2層分追加し強化した。
v2のアップデートにおいては特にdescriminatorの強化が強力と考えています。discriminatorのパラメータはHiFi GANのパラメータから持ってきていると思われますが、これは22050Hz向けにチューニングされたものでした。v2ではMultiPeriodDiscriminatorのperiodを追加し、より高解像度の音声を見分けられるようになったのが品質を上げたカギだと思われます。また、これにより学習データの発音の誤りも見分けられるようになり、英語のみで学習を行ったpretrainの重みでもある程度日本語の発音が明瞭にできるようになりました。
事前学習
データセットの方針
前回の記事では16000kHZのReazonSpeechのデータを用いるとがくぐもってしまう問題がありました。また、v2における変化から言語よりも高品質な音声データを集めて学習を行うことが重要であるとわかりました。そこで、事前学習のデータセットを108人の英語のネイティブスピーカーに対し合計約50hの録音を行った48kHzのCSTR VCTK Corpusを用いて事前学習を実施しました。
学習方法の変更
ddPn08さんのRVC-webUIにおいて複数の話者に対応した学習が行えるようにアップデートが入っていたので、これを用いることにしました。話者の情報をidとして教えることでより話者に関係ない発話の内容を取得するように学習が進むようになります。
ddPn08さんのRVC-webUIにはもともとcontentvecの768次元で事前学習を行った事前学習済みの重みも提供されていたので初期に以下の重みを指定してチューニングを行いました。
- generatorにv1のf0G48kの重み
- descriminatorにv2のf0D40kの重み
学習についてはバッチサイズを32にし、ConentVecとjp-HuBERTのそれぞれに対して10epochの学習を行いました。
(RTX3090でおよそ3hかかりました)
音声の変換結果に対する考察
ContentVecをphone embedderに用いたモデルではindexを用いなくても高品質な音声変換が可能でした。これはContentVecが音声変換に向けてHuBERTから話者性を除くような対照学習を行っているからであると思われます。
一方jp-HuBERTは日本語に特化しているものの、より一般的な用途に向けて学習されているのでembeddingに話者情報が多く含まれていてモデルに影響していそうです。jp-HuBERTでもContentVecと同様の学習を行えばより高品質な日本語での音声変換が可能になるのではと思います。
おわりに
新しくなったRVCに向けて事前学習済みのモデルを訓練しました。日に日にモデルは進化していて、とても面白い分野だと思います。ぜひ試してみてください。
RVCはとても優れたボイスチェンジャーですが、声の権利者を無視したモデルも多くみられます。モデルの学習を行う際はデータセットの規約をよく確認した上でクレジット表記や発言のルール等を守り、楽しい目的につかわれるといいですね。
宣伝ですが機械学習への利用が可能な音声データを声から探すためのリポジトリを作成しています。(https://github.com/nadare881/voice-changer-vector-search )
現在はモデルの進化が早いので学習用音声データのみの収集を行っていますが、自身の配布・販売している音声を載せてもいいよという方はご連絡ください。
また、RVCの軽量化も開発中です。今回の事前学習済みモデルを配布しているページではあみたろの声素材工房さんのITAコーパス読み上げ音声を用いて学習したモデルをデモとして作成していますが、このnpy、indexにはkmeansを用いてファイルサイズを小さくしたものを用いています。kmeansを用いてベクトルのサイズを小さくしても品質はほぼ変わらないので、手軽に利用できるよう提案・貢献できればなと思っています。
それでは楽しい音声変換ライフを!!