AWS for Games Advent Calendar 2022 2日目の記事です。
はじめに
この記事では AWS が提供しているソリューションのゲーム分析パイプラインと今年 GA となったサーバーレスな DWH サービスである Amazon Redshift Serverless を組み合わせて、サーバーレスなゲーム分析環境の構築を試します。
なお、この記事はお手元の AWS アカウントでお試しいただけるハンズオン資料のような形式となっておりますが、実際に AWS サービスを使われる場合はサービス利用に応じた費用が発生しますので予めご了承ください。
今回構築するゲーム分析環境のアーキテクチャ
今回構築するゲーム分析環境のアーキテクチャは以下の通りです。
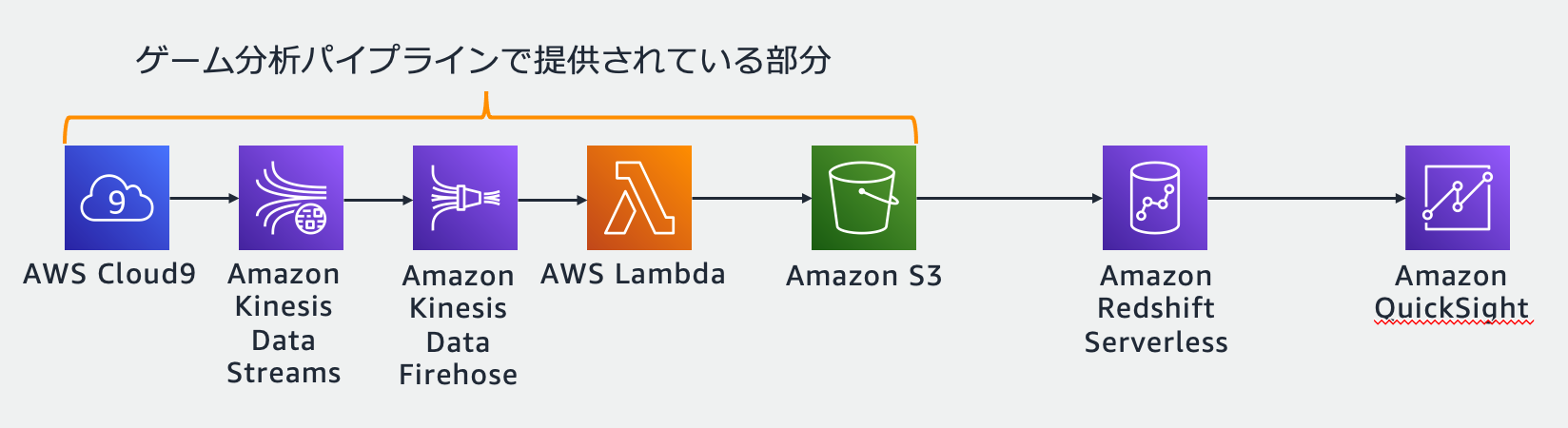
ゲーム分析環境を試すにあたっては当然、分析・集計対象となるサンプルデータが必要になりますので、そのサンプルデータは AWS Cloud9 から生成します。
AWS Cloud9 から生成されたデータは Amazon Kinesis Data Streams で収集され、Amazon Kinesis Data Firehose, AWS Lambda を経由して ETL 処理をされた上で Amazon S3 に保存されます。
ここまでは AWS ソリューションのゲーム分析パイプラインをデプロイすることで利用できる環境となっております。
そして、Amazon S3 に収集されたデータを Amazon Redshift Serverless にロードし集計、Amazon QuickSight で可視化するという流れになります。
もし、読者の方がゲーム開発に携わられている方で既にゲームの様々なログデータを Amazon S3 に収集されているならば、今回ご紹介する Amazon Redshift Serverless と Amazon QuickSight の利用方法を応用して、すぐに上記のようなゲーム分析環境を構築していただけるのではないかと思います。
ここからは実際に Amazon Redshift Serverless を使ったゲーム分析環境を構築し、簡単にゲームにおけるデータ分析を模したクエリ実行とその可視化を行いたいと思います。
1. ゲーム分析パイプラインのデプロイ
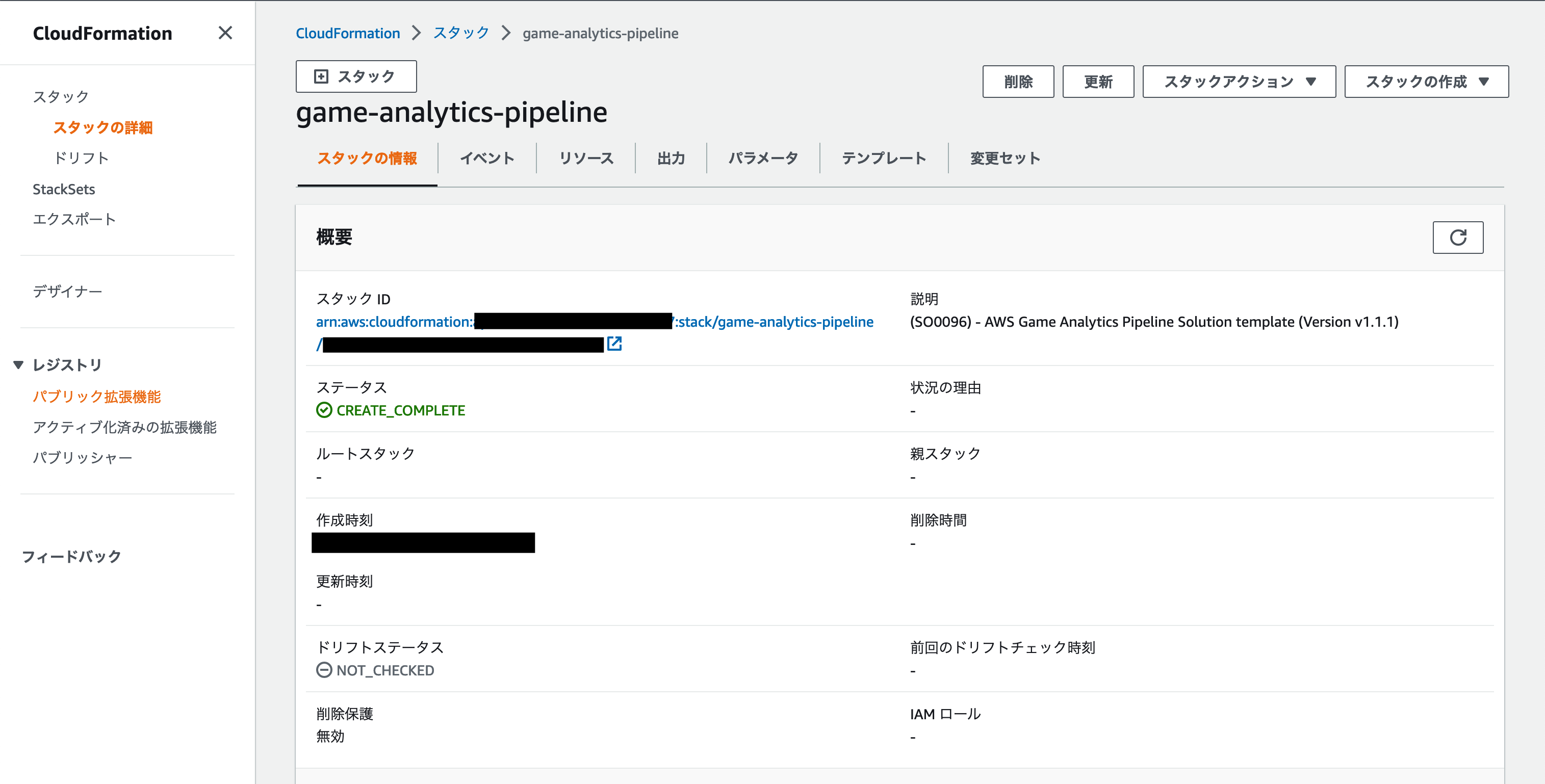
ゲーム分析パイプラインのデプロイについてはゲーム分析パイプラインの実装ガイドの17ページに「ソリューションの起動」というリンクがありますのでクリックします。そうしますと AWS CloudFormation のコンソール画面が開かれますので、実装ガイドの手順にしたがってゲーム分析パイプラインをデプロイしていきます。
最終的に以下のように AWS CloudFormation のスタックのステータスが CREATE_COMPLETE となっていればデプロイ成功です。
2. サンプルデータを生成する
既成のゲーム分析パイプラインの CloudFormation テンプレートを使用することでゲームデータログを収集する仕組みを簡単に構築することができました。
ここからは分析・集計対象となるサンプルデータを用意します。
引き続きゲーム分析パイプラインの実装ガイドの19ページに記載された手順にしたがってサンプルデータとなるゲームログを生成していきます。
ゲームログを生成する環境としてはローカル環境でも問題ありませんが、今回は AWS Cloud9 を使ってみたいと思います。
AWS Cloud9 の詳細については割愛しますが、AWS Cloud9 を使うことで今回のような検証目的の一時的な開発環境を簡単に用意し、不要となれば即座に破棄することができます。
AWS Cloud9 のセットアップは AWS コンソールから AWS Cloud9 の画面を開き「Create environment」をクリック、「Name」に AWS Cloud9 の環境名を入力してその他はデフォルトの設定のままで「Create」をクリックします。
しばらくすると AWS Cloud9 の画面が開かれますので、AWS Cloud9 上でターミナルを開きます。
ターミナルで以下のコマンドを実行し、GitHub上のゲーム分析パイプラインのリポジトリをクローンします。
$ git clone https://github.com/awslabs/game-analytics-pipeline.git
ここからはゲーム分析パイプラインの実装ガイドの19,20ページの手順と同じですが、以下のコマンドを実行しサンプルゲームイベントを生成するスクリプトの実行環境をセットアップします。
$ python3 -m pip install --user --upgrade pip
$ python3 -m pip install --user virtualenv
$ python3 -m venv env
$ source env/bin/activate
$ pip install boto3 numpy uuid argparse
そして AWS Cloud9 のターミナルで game-analytics-pipeline/source/demo/ フォルダに移動しサンプルゲームイベントを生成するスクリプトを実行します。
$ cd game-analytics-pipeline/source/demo/
$ python3 publish_data.py --region <aws-region> --stream-name
<GameEventsStream> --application-id <TestApplicationId>
<aws-region> は AWS CloudFormation でゲーム分析パイプラインのスタックをデプロイした AWS リージョンコードに、<GameEventsStream> と <TestApplicationId> を AWS CloudFormation の出力タブから確認できる値に置き換えます。
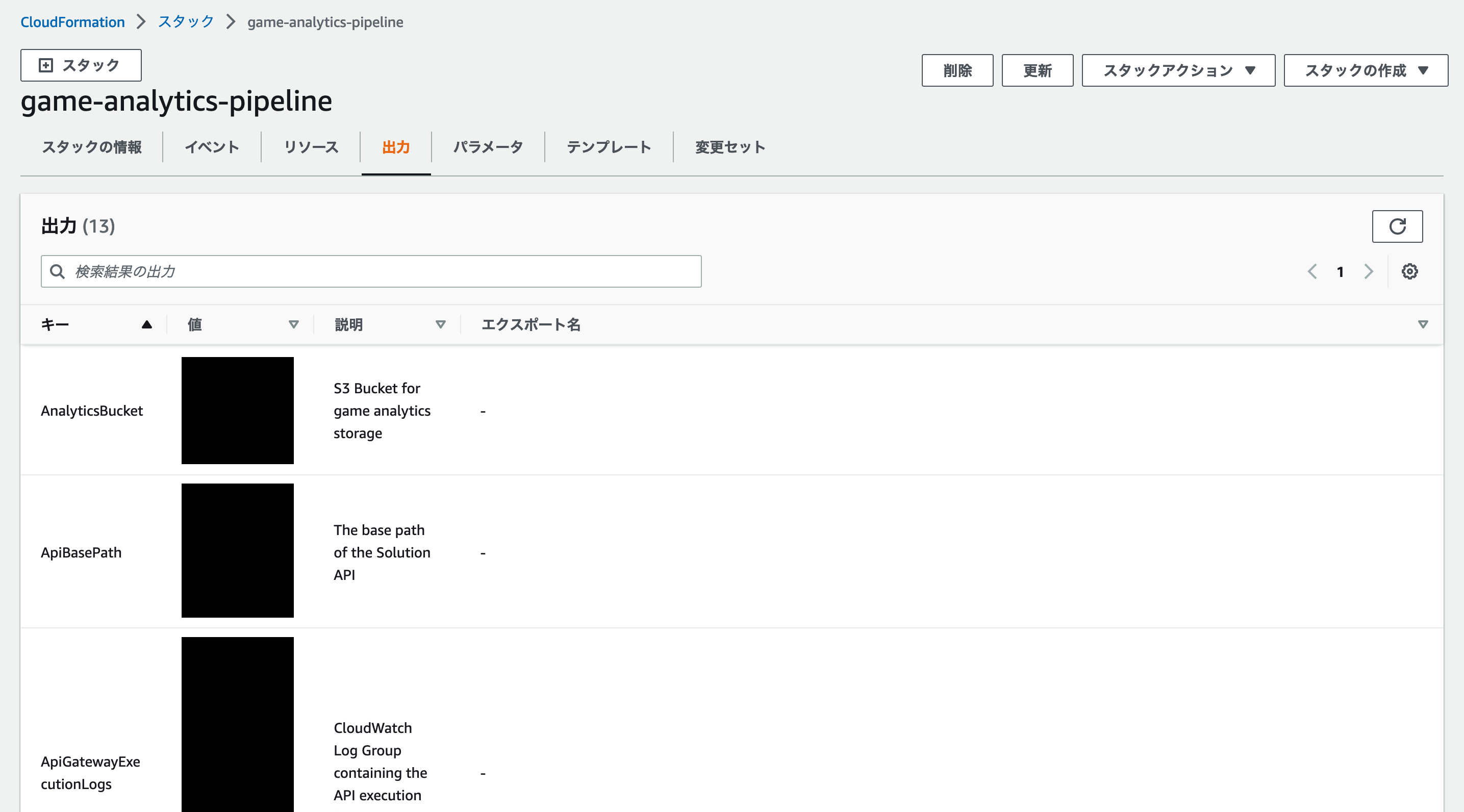
スクリプトは数時間実行していただくことで、様々なゲームイベントログを大量に Amazon S3 に収集することが可能です。
スクリプトで自動生成されるサンプルデータがどのようなデータであるかについては、ゲーム分析パイプラインのデベロッパーガイドの5ページ目から始まる「Events」の説明にある通りとなります。
後ほど、ログインユーザーの集計を試す際にログインデータのサンプルを示しながらご紹介します。
以上でこれから構築するゲーム分析環境で利用するサンプルデータを Amazon S3 に用意できました。
3. Amazon Redshift Serverless のセットアップ
Amazon Redshift Serverless は AWS が兼ねてから提供してきた DWH のマネージドサービスである Amazon Redshift のサーバーレスオプションになります。
サーバーレスであるため従来のようなクラスター運用は不要となり、Amazon Redshift が提供する各種機能を使ったデータ分析にフォーカスしていただけるサービスとなっております。
Amazon Redshift Serverless の利用開始にあたっては AWS コンソールから Amazon Redshift のコンソールを開き、「Amazon Redshift サーバーレスを試す」をクリックします。

そうすると「Amazon Redshift サーバーレスの使用を開始する」というページが開かれるので、「デフォルトの設定を使用」という項目を選択します。
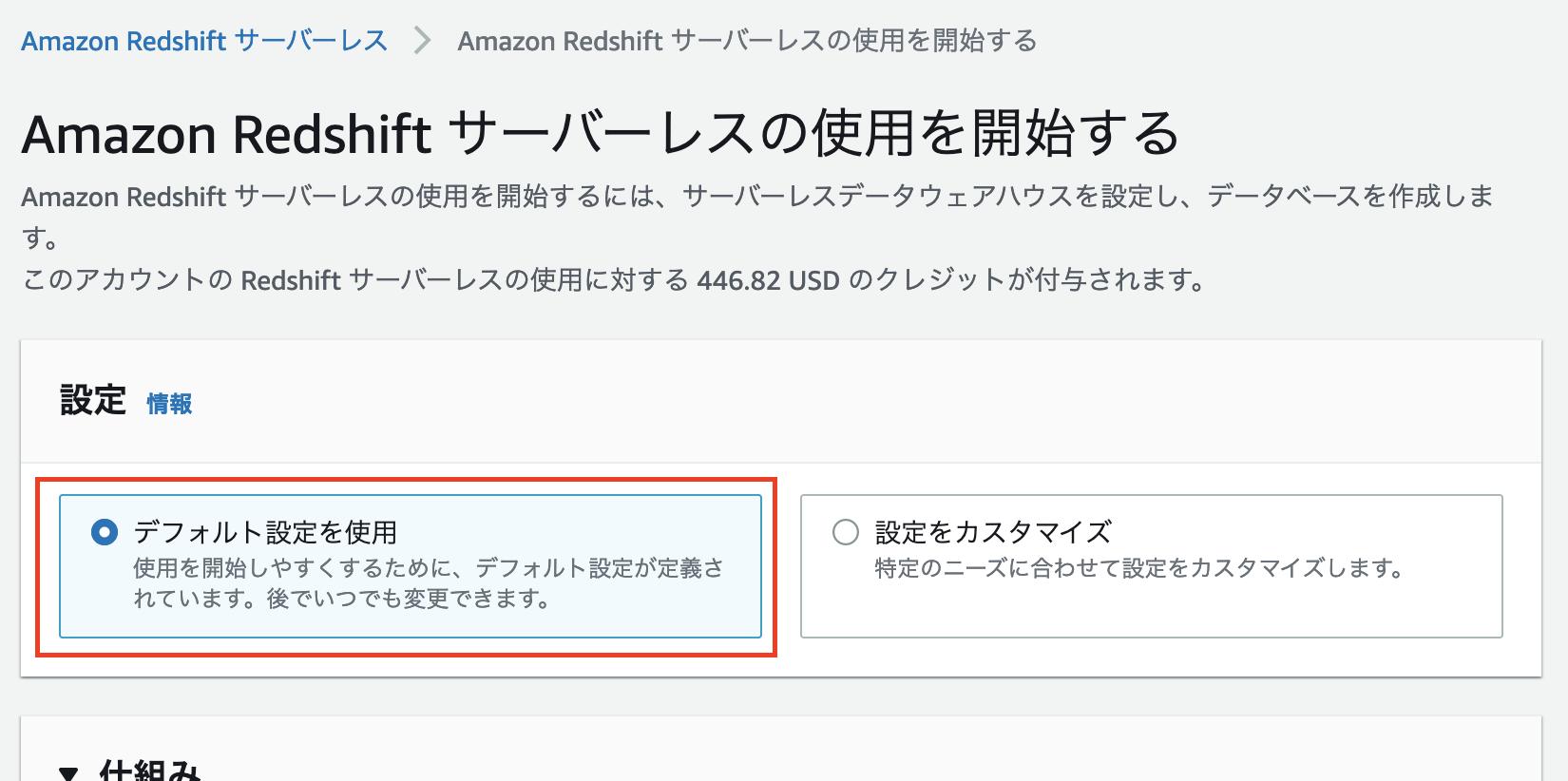
下にスクロールすると「名前空間」という項目が出てきますので、その中の「関連付けられた IAM ロール」にある「IAM ロールの管理」をクリックします。そこで「IAM ロールの作成」というボタンが出てくるので、それをクリックします。
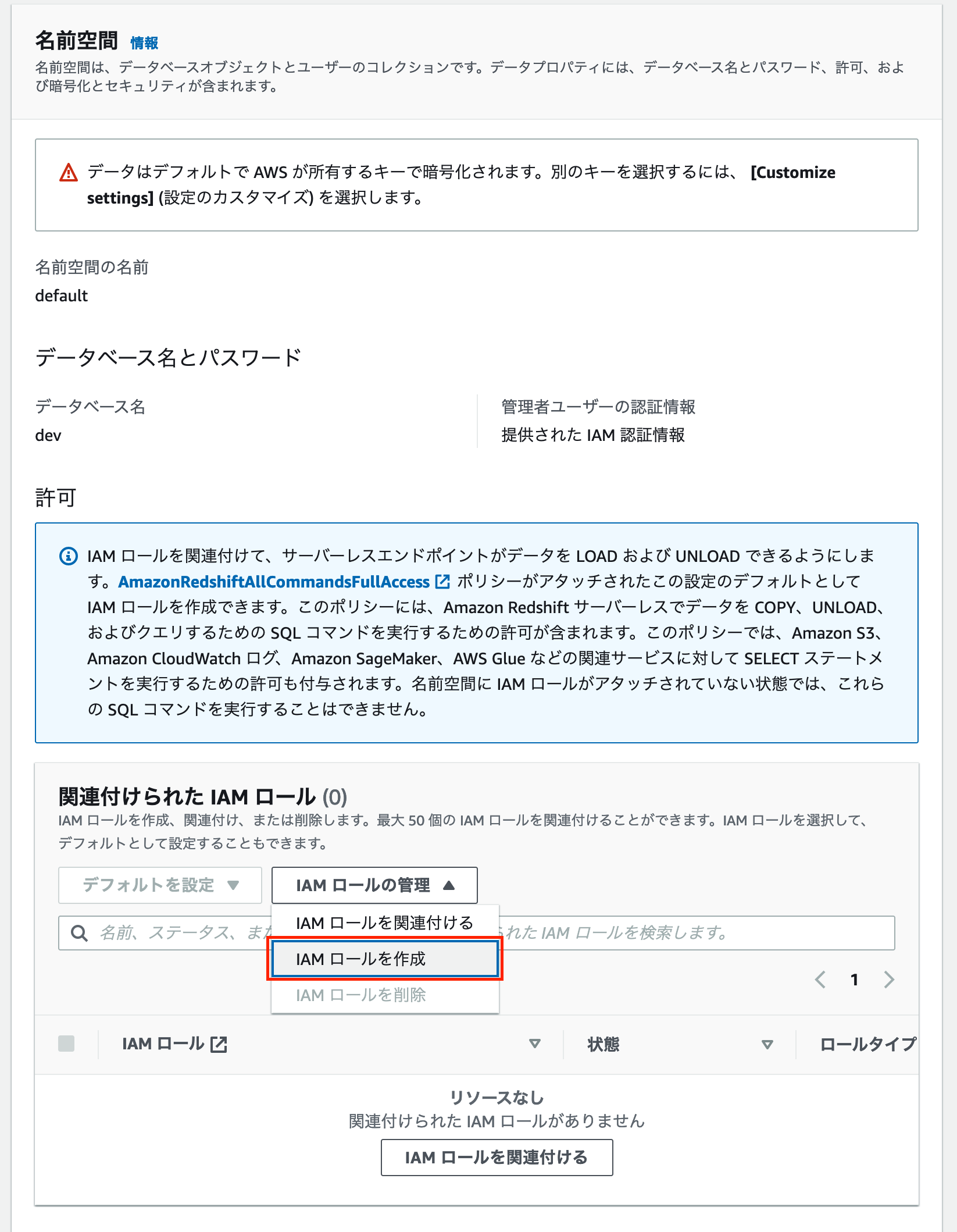
そうすると「デフォルトの IAM ロールを作成する」というポップアップが表示されます。
ここで作成する IAM ロールは Amazon S3 から Amazon Redshift Serverless にデータをロードする際に使用するものとなります。
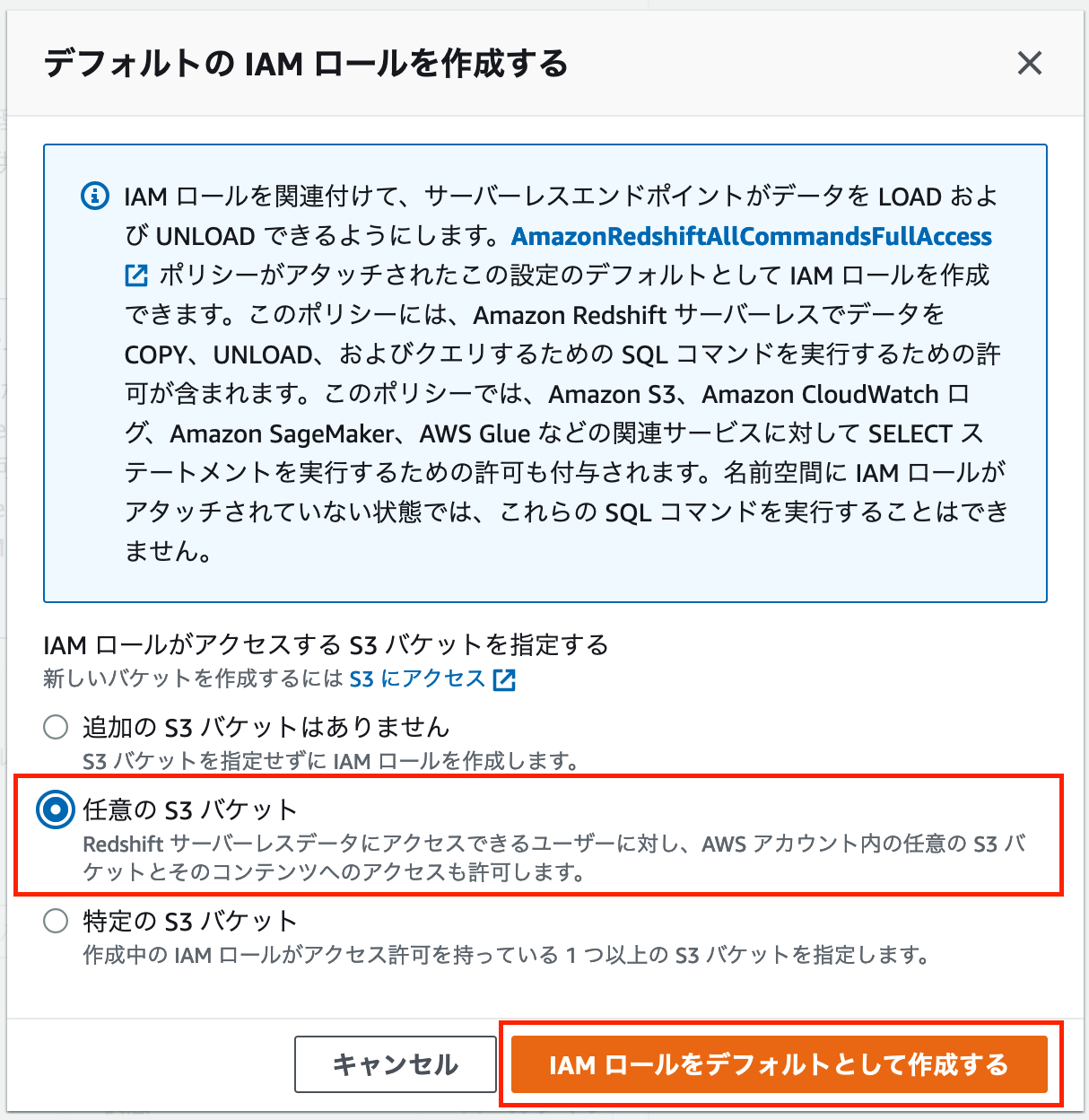
今回は検証のため「任意の S3 バケット」という項目を選択し、「IAM ロールをデフォルトとして作成する」をクリックします。
その後、IAM ロールが作成され「Amazon Redshift Serverless の使用を開始する」ページに戻りますので、ページ下部の「設定を保存」というボタンをクリックします。
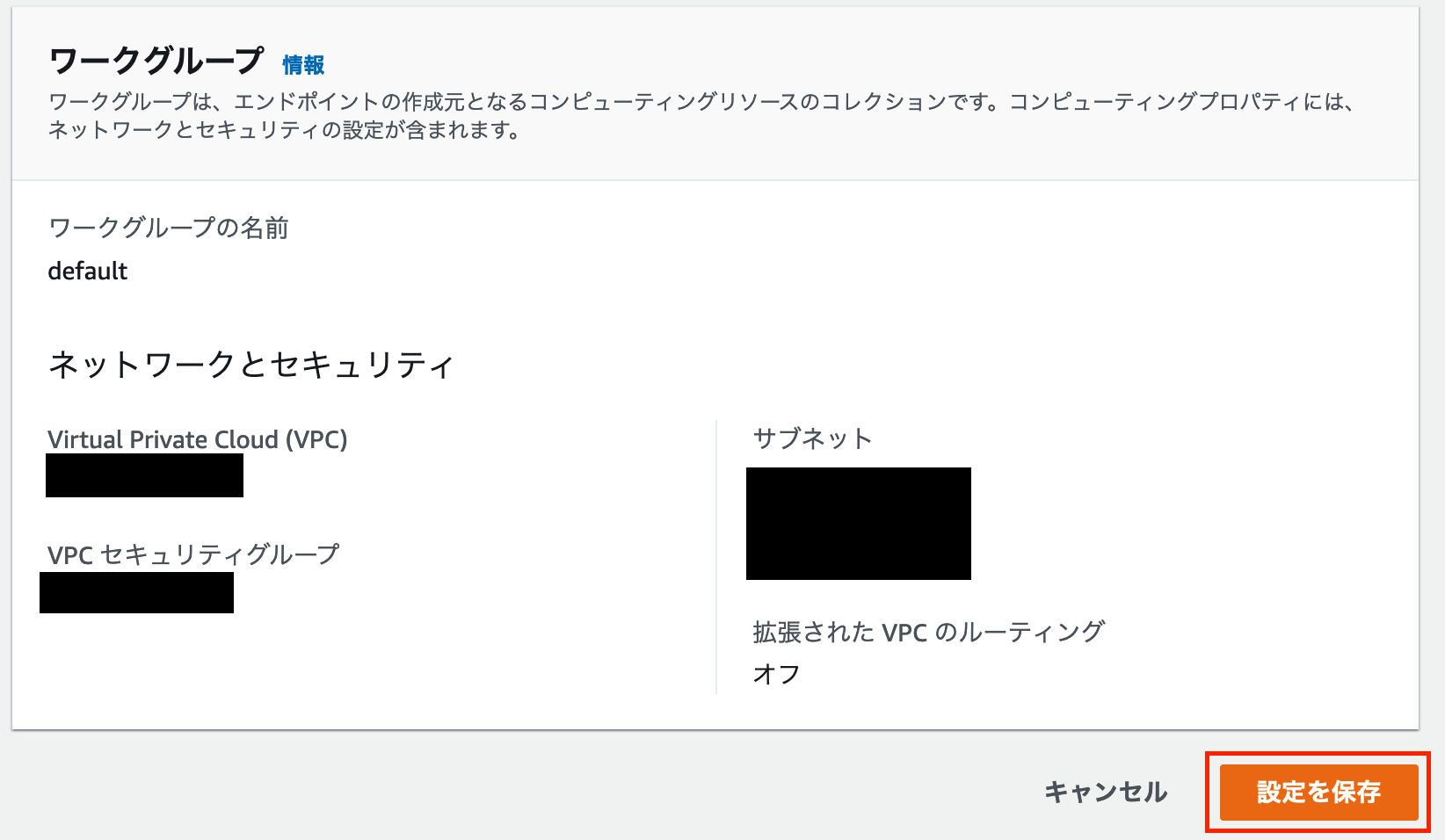
「設定を保存」をクリックするとすぐに Amazon Redshift Serverless のセットアップが始まります。
初回は数分程度セットアップに時間がかかりますが、すぐに Amazon Redshift の機能が利用可能なサーバーレス環境が立ち上がります。
セットアップが完了し上図のポップアップの「次へ」ボタンが有効になったらそれをクリックします。
そうすると以下のサーバーレスダッシュボードというページが開かれます。
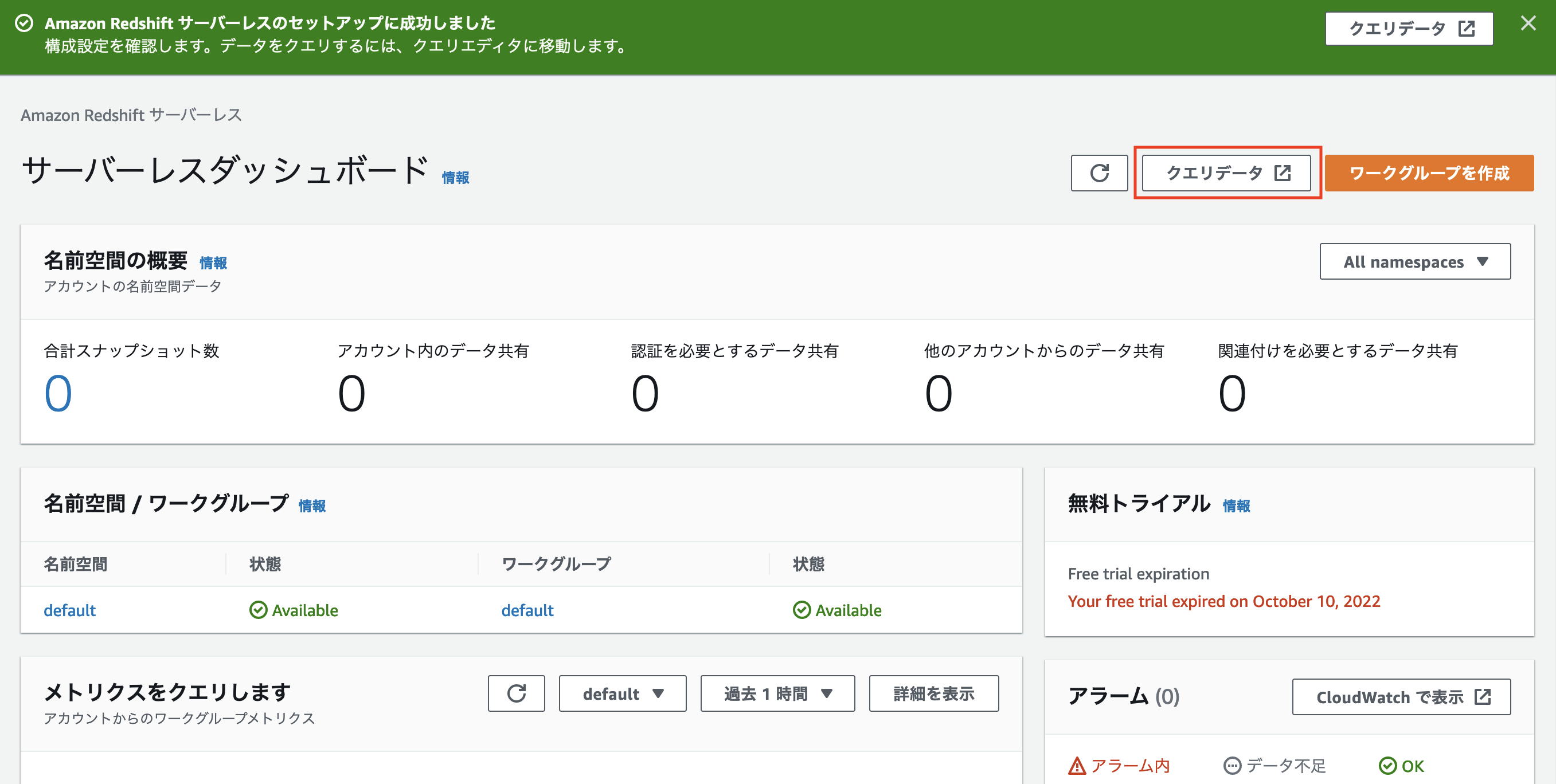
「クエリデータ」と書かれたボタンがありますが、これは Amazon Redshift が提供するブラウザベースのクエリエディタである Redshift query editor v2 を開くボタンとなっています。
この「クエリデータ」をクリックし、Redshift query editor v2 を開くと以下の画面になります。
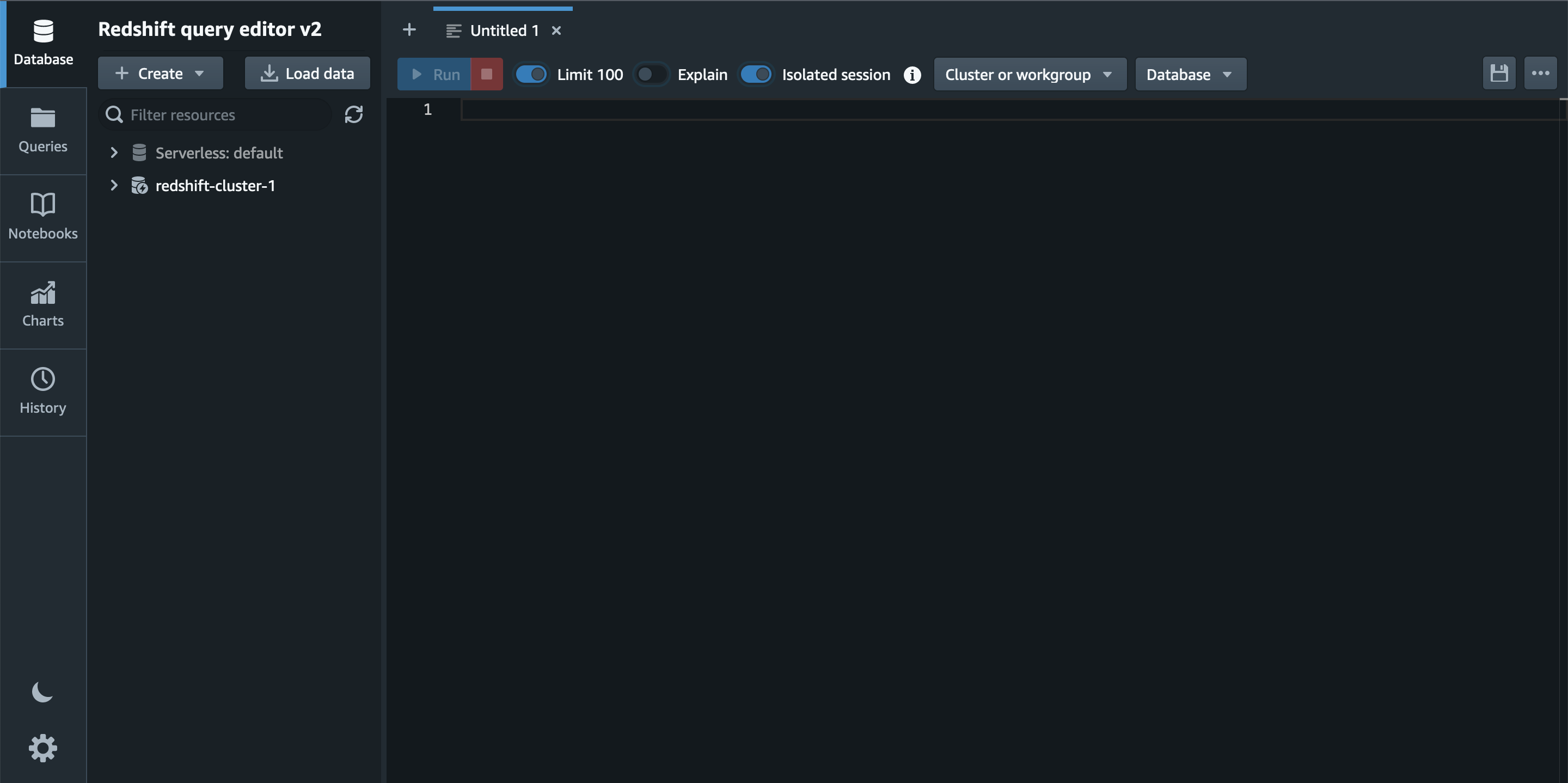
ここからは Amazon Redshift Serverless へ Amazon S3 に保存されたサンプルデータをロードし、クエリを実行してデータ集計を行いたいと思います。
4. Amazon Redshift Serverless でクエリを実行する
クエリの実行にあたってはまず Amazon S3 から Amazon Redshift へデータをロードする必要があります。
またデータのロード先となるテーブルを作成することも必要となります。
これらの操作を Redshift query editor v2 から行う方法についてご紹介します。
まずテーブルの作成ですが、左上の「Create」メニューから「Table」を選択しクリックします。
そうするとテーブル作成のためのポップアップが表示されます。
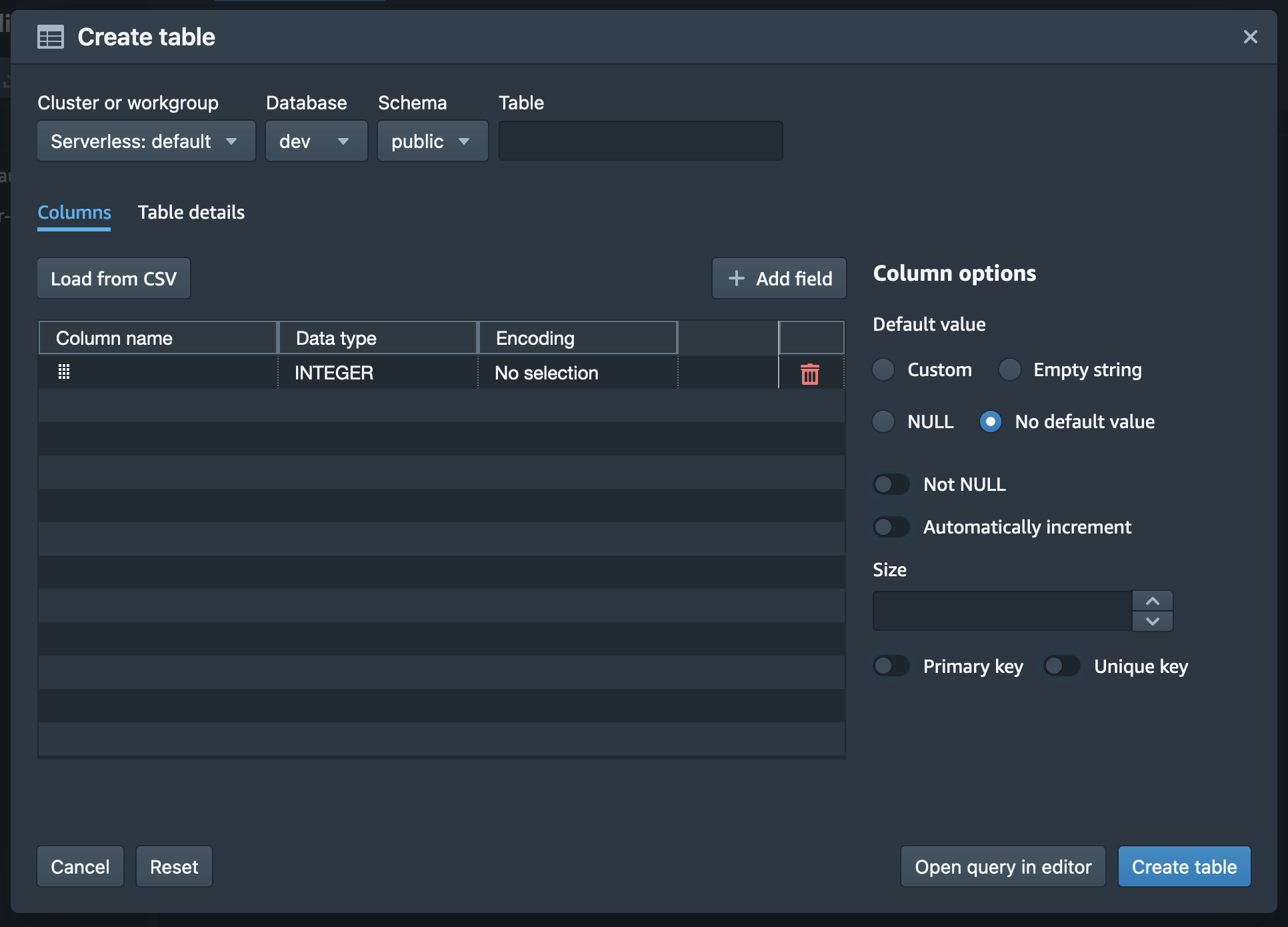
今回はデフォルトの環境となりますので、「Cluster or workgroup」では「Serverless: default」を選択、「Database」では「dev」を選択、「Schema」では「public」を選択します。
「Table」に入力するテーブル名については、後の手順で SUPER 型への変換を行うための一時テーブルとなるため、「tmp_raw_events」とします。
テーブルのカラムについては「Add field」でカラムを増やしそれぞれのカラム名、型、エンコーディングを指定することが可能です。
また、Amazon S3 から Amazon Redshift Serverless にロードするデータのヘッダー付き CSV ファイルがお手元にある場合は、「Load from CSV」というボタンをクリックし、その CSV ファイルをアップロードすることができます。そうするとアップロードされた CSV ファイルのカラム名と各データの型を読み取りカラム情報が自動的に入力されます。
ここまでの内容と今回扱うサンプルデータの構造を踏まえてテーブル作成のために必要な設定情報を一通り入力すると以下のようになります。
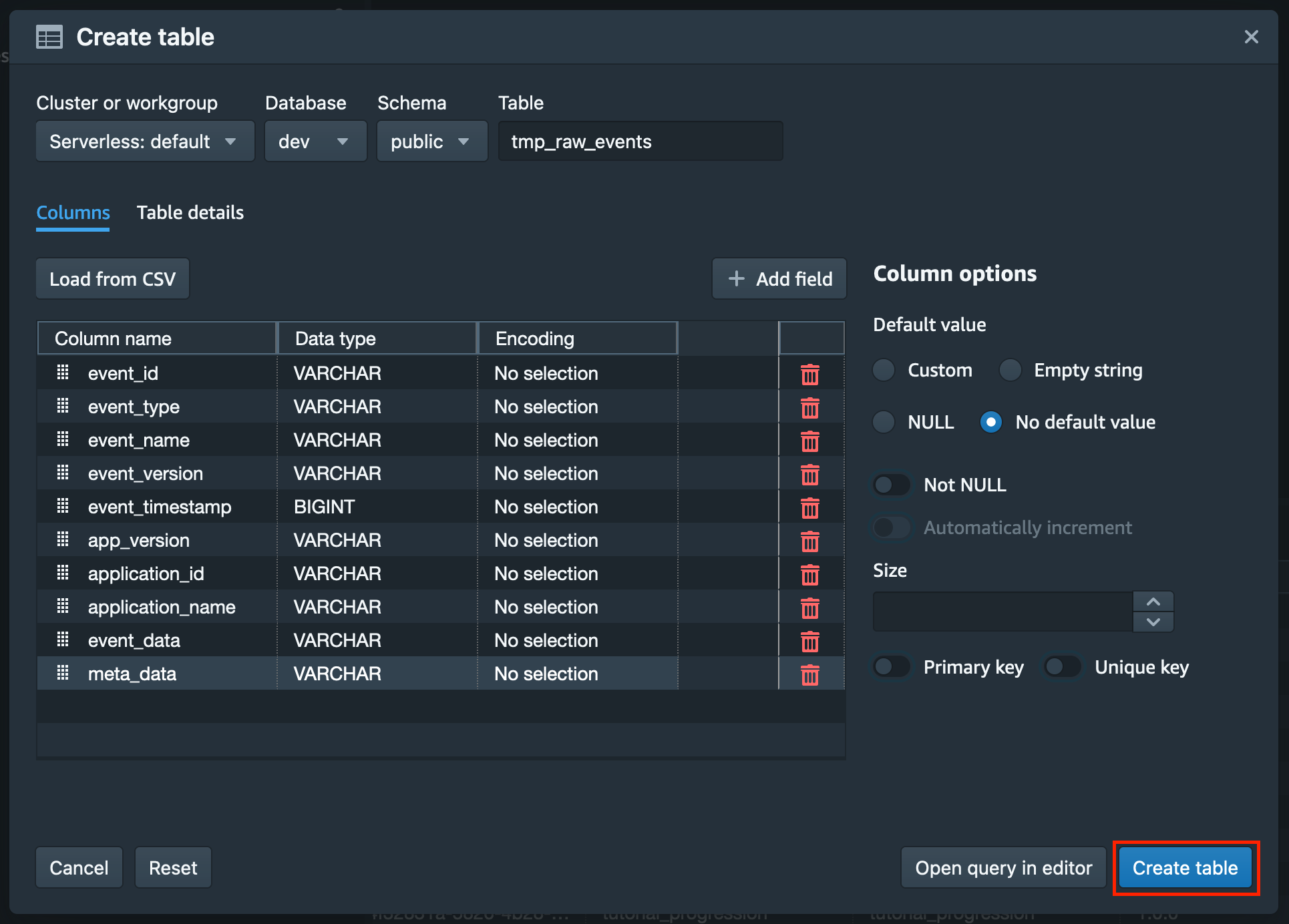
これらのテーブルの設定情報を一通り入力し終えたら、ポップアップ右下の「Create table」ボタンをクリックします。
次に Amazon S3 に保存されているサンプルデータを先ほど作成したテーブルにロードします。
データのロードを操作するにあたっては左上の「Load data」ボタンをクリックします。
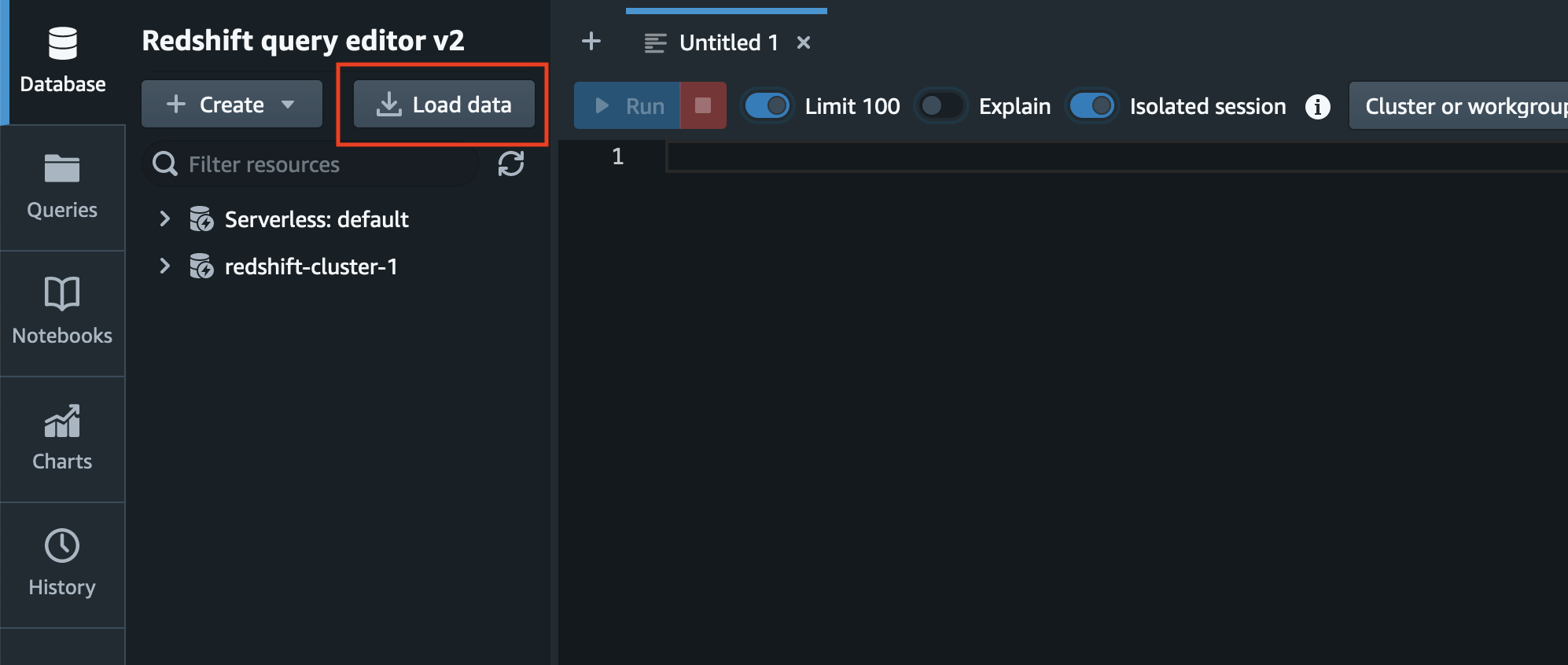
そうすると以下のようなポップアップが表示されます。
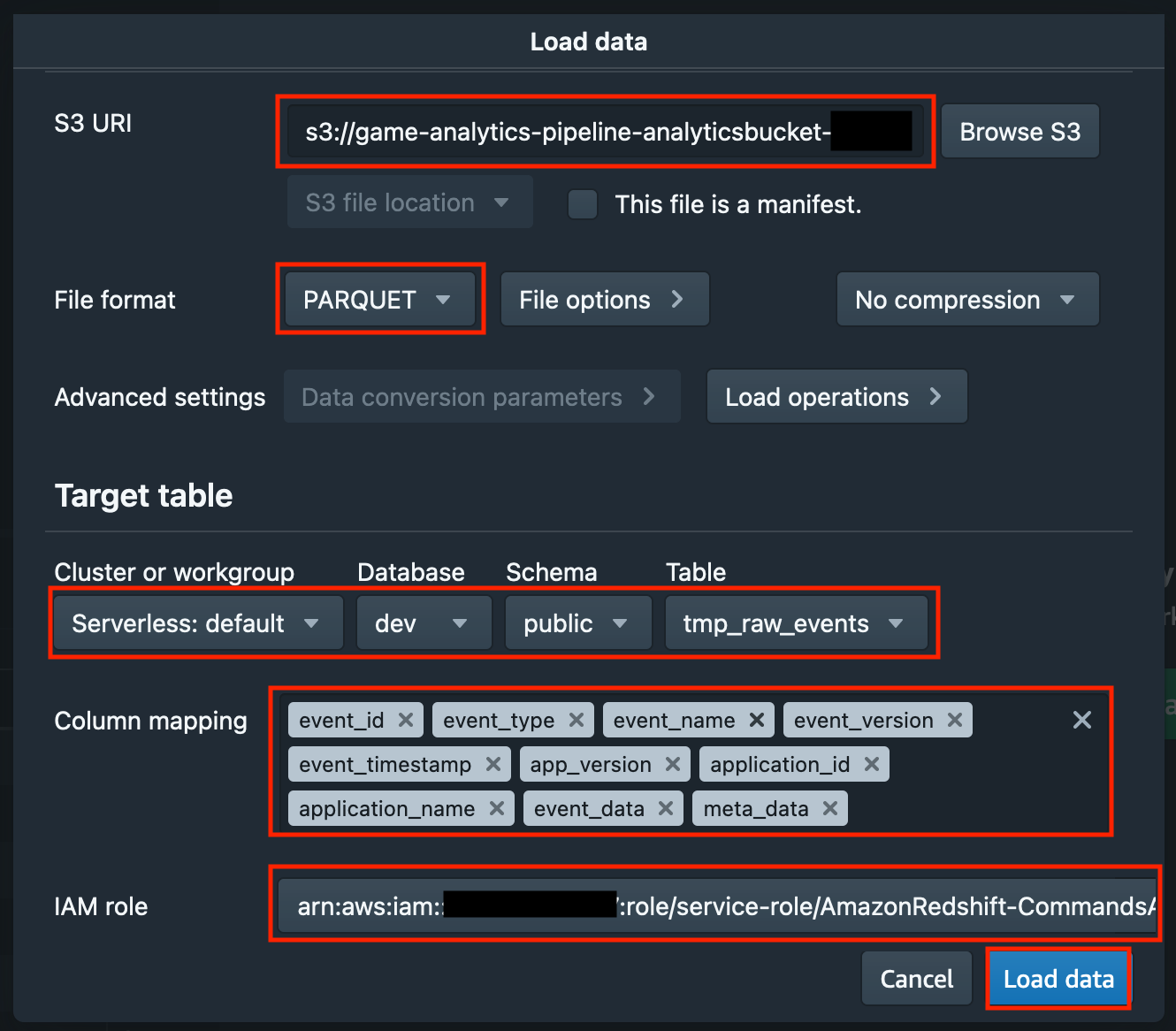
S3 URI については「Browse S3」をクリックすると Amazon S3 のバケット一覧を確認できます。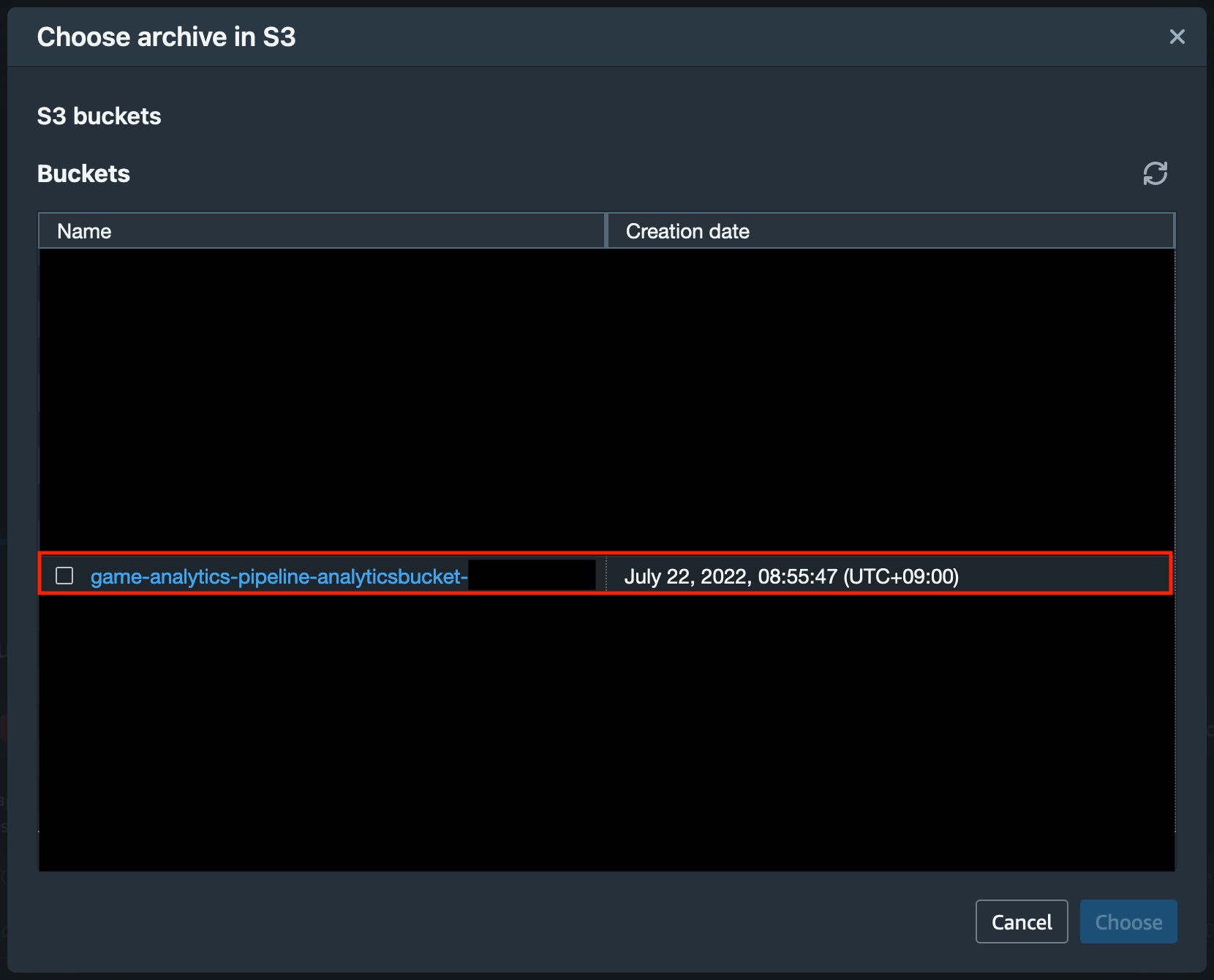
ゲーム分析パイプラインに関連しそうな S3 バケットとしては、おそらく {CloudFormation Stack名}-analyticsbucket-XXXXXX と {CloudFormation Stack名}-solutionlogbucket-XXXXXX という2種類のバケットが表示されるかと思いますが、{CloudFormation Stack名}-analyticsbucket-XXXXXX の方をクリックします。
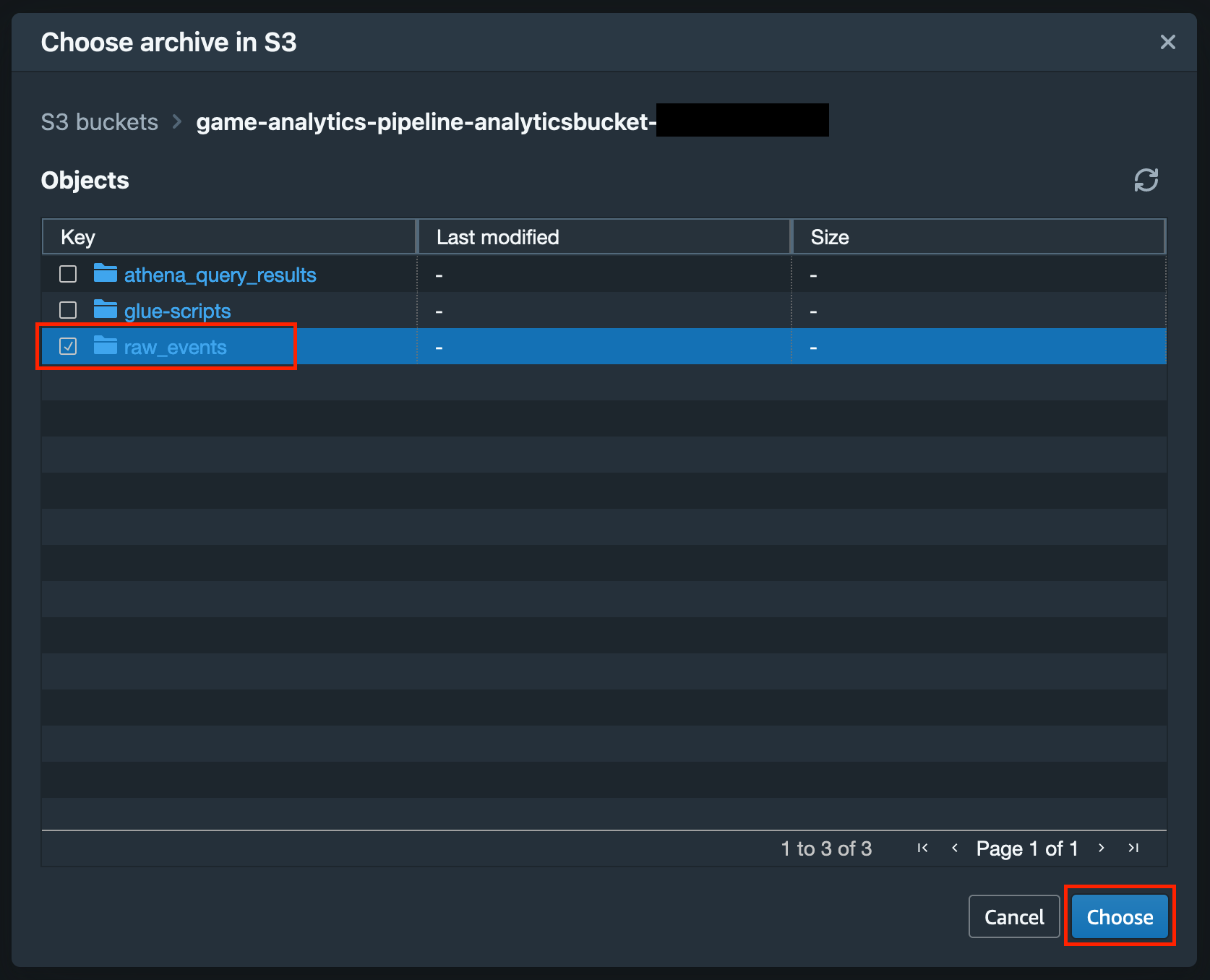
そうするとこのような画面となり、{CloudFormation Stack名}-analyticsbucket-XXXXXXという S3 バケットに含まれる Object 一覧が出てきますので、raw_events のチェックボックスを有効にし、「Choose」ボタンをクリックします。
「Load data」のポップアップに戻り、「File format」についてはサンプルデータの都合から PARQUET を選択します。
「Target table」の「Cluster or workgroup」「Database」「Schema」「Table」については先ほどテーブル作成した際の指定の通り「Serverless: default」「dev」「public」「tmp_raw_events」を選択します。
「Column mapping」においては全てのカラムを選択します。(※カラムの選択順については画像の通りにしてください。)
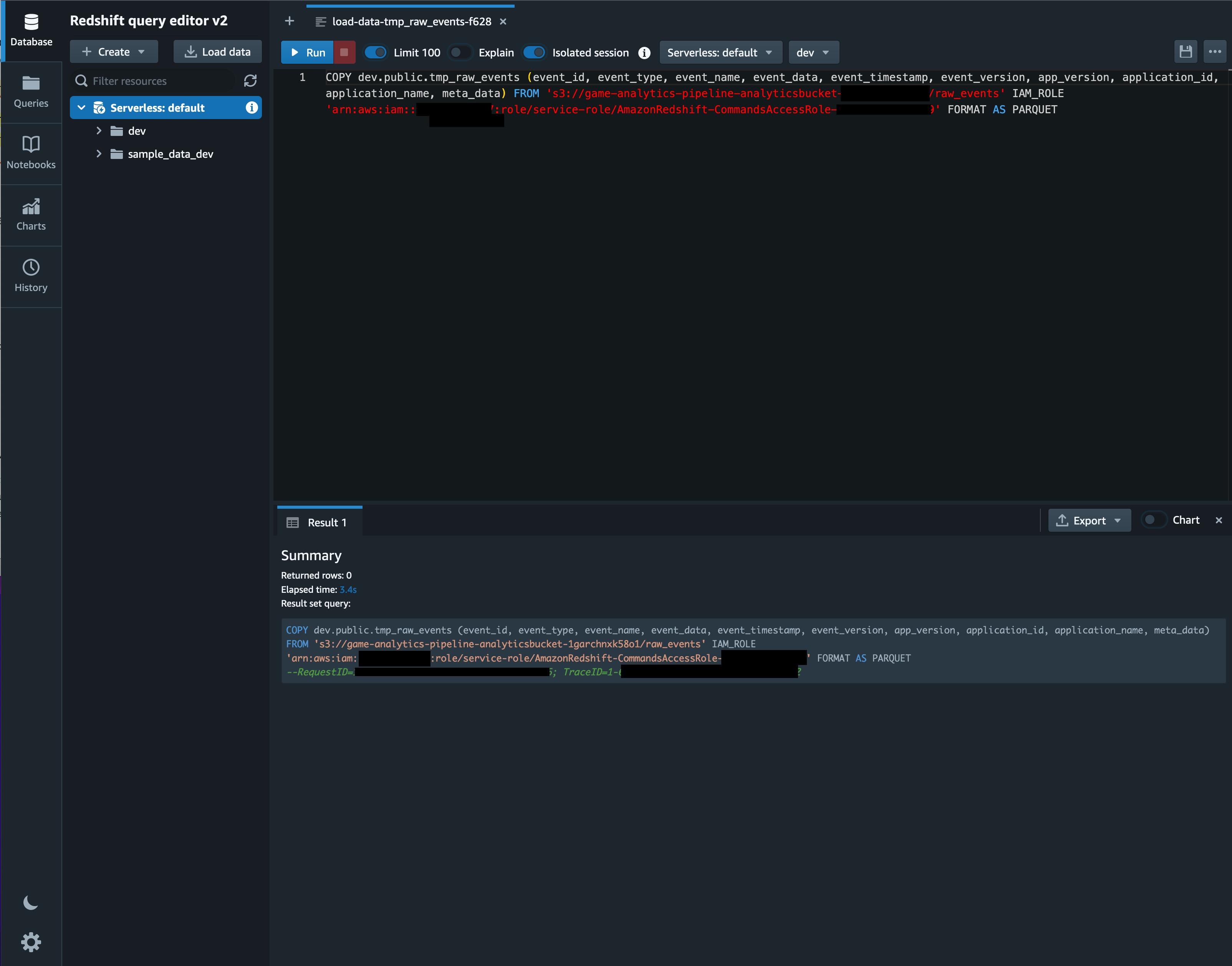
各項目の指定が完了したら「Load data」をクリックします。
「Load data」をクリックすると以下のように COPY クエリが自動で生成され、自動実行されます。
データのロードが完了したら、JSON データが含まれるカラムの型を SUPER 型に変更するため、以下のクエリを実行します。
CREATE TABLE raw_events AS
SELECT
event_id,
event_type,
event_name,
event_version,
event_timestamp,
app_version,
application_id,
application_name,
JSON_PARSE(event_data) AS event_data,
JSON_PARSE(meta_data) AS meta_data
FROM tmp_raw_events;
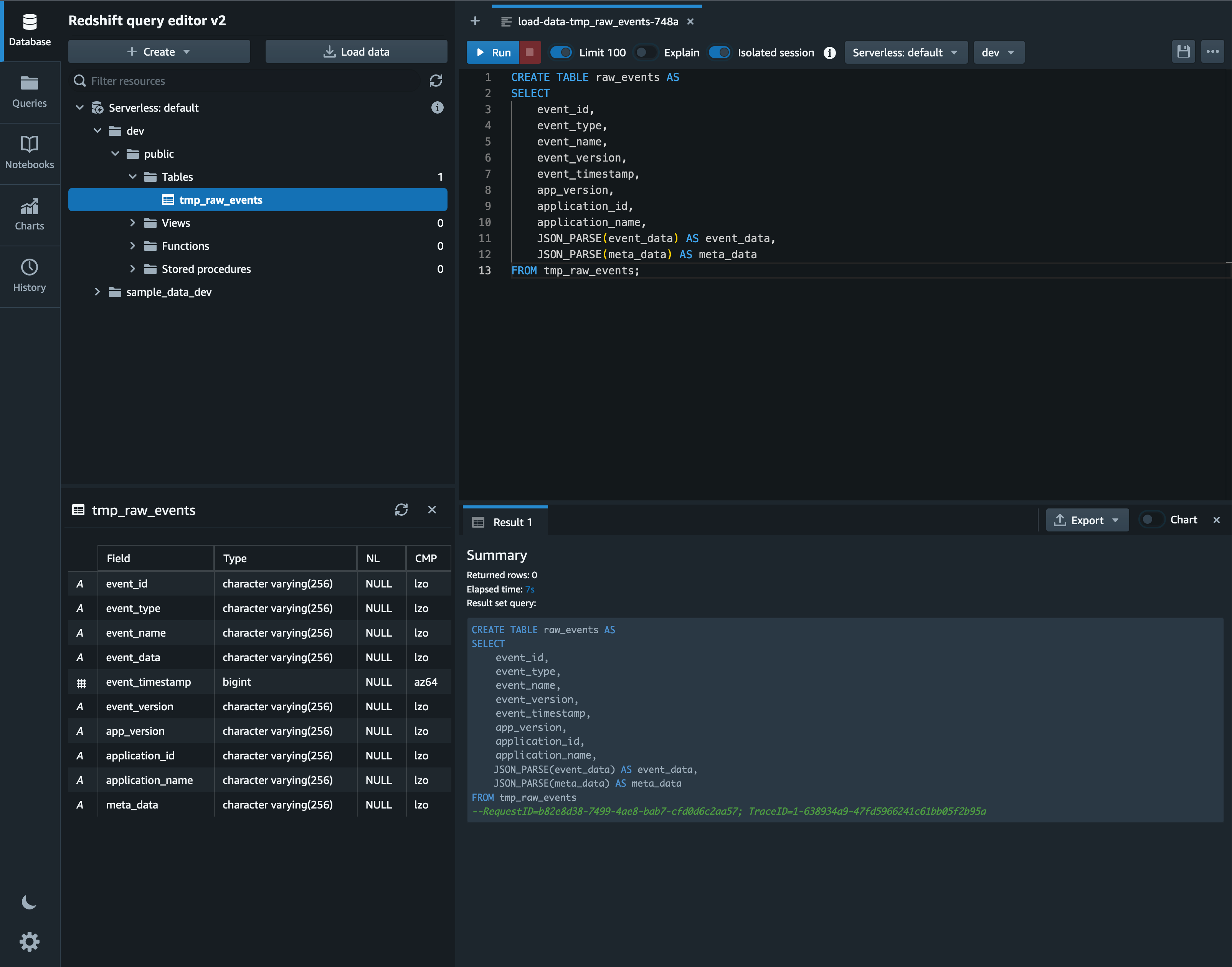
ここで SUPER 型について簡単にご紹介すると、SUPER 型とは Amazon Redshift が半構造化データをサポートするための型であり、例えば多くのメンバーを含む JSON データを扱う際にメンバーの数に応じたカラムを用意することなく単一の SUPER 型のカラムに挿入するだけで済ませられるといった利点があります。
そして今回 SUPER 型を利用する理由はサンプルデータの仕様にあります。
今回用意したサンプルデータのうち、例えばログインデータに関するログの構造は以下のようになっています。
{
"event_id": "ef37b266-1f09-4e9f-8076-fc3afd45f251",
"event_type": "login",
"event_name": "login",
"event_data": {
"last_login_time": 1657188799,
"platform": "iOS"
},
"event_timestamp": 1658707319,
"event_version": "1.0.0",
"app_version": "1.0.0",
"application_id": "e2a67660-cd2b-4f2e-857c-ea61801fdb12",
"application_name": "default_app",
...
}
また、課金履歴に関するログの構造は以下のようになっています。
{
"event_id": "a4bd93e0-ef7e-4d48-9912-056d902ff433",
"event_type": "iap_transaction",
"event_name": "iap_transaction",
"event_data": {
"country_id":"AUSTRALIA",
"currency_amount":7,
"currency_type":"USD",
"item_amount":1,
"item_id":"2b4fd6be-e93d-4399-a9d3-8f4cb8ed1ae5",
"item_version":2,
"transaction_id":"0dc95b57-c757-49fe-88bb-ef2c91474091”
},
"event_timestamp": 1658707319,
"event_version": "1.0.0",
"app_version": "1.0.0",
"application_id": "e2a67660-cd2b-4f2e-857c-ea61801fdb12",
"application_name": "default_app",
...
}
このように今回使用するサンプルデータは、様々なゲーム内イベントログが同じ形式の JSON で出力され、データ内の event_name event_type でイベントログの種類を識別し、event_data に含まれるデータの構造がそのイベントログの種類によって異なる仕様となっています。
そこでevent_dataのカラムを SUPER 型として様々なイベントログをそのまま保存することで、分析用のデータを一つのテーブルにまとめて収集しながら、event_type/event_nameで分類できる各種データとその詳細情報である event_data を柔軟にクエリできます。
もちろんイベントログの種類によってテーブルを分ける運用をされることが一般的かと思いますが、例えば分析用データをとりあえず出力して狙い通りの分析ができるかどうか試行錯誤したい場合には、このように SUPER 型を活用する余地もあるかと思います。
ここからは実際のゲーム運営における分析に見立てて上記のログインユーザーのログデータと課金履歴のログデータの集計を試します。
まずログインユーザーのログデータを集計します。
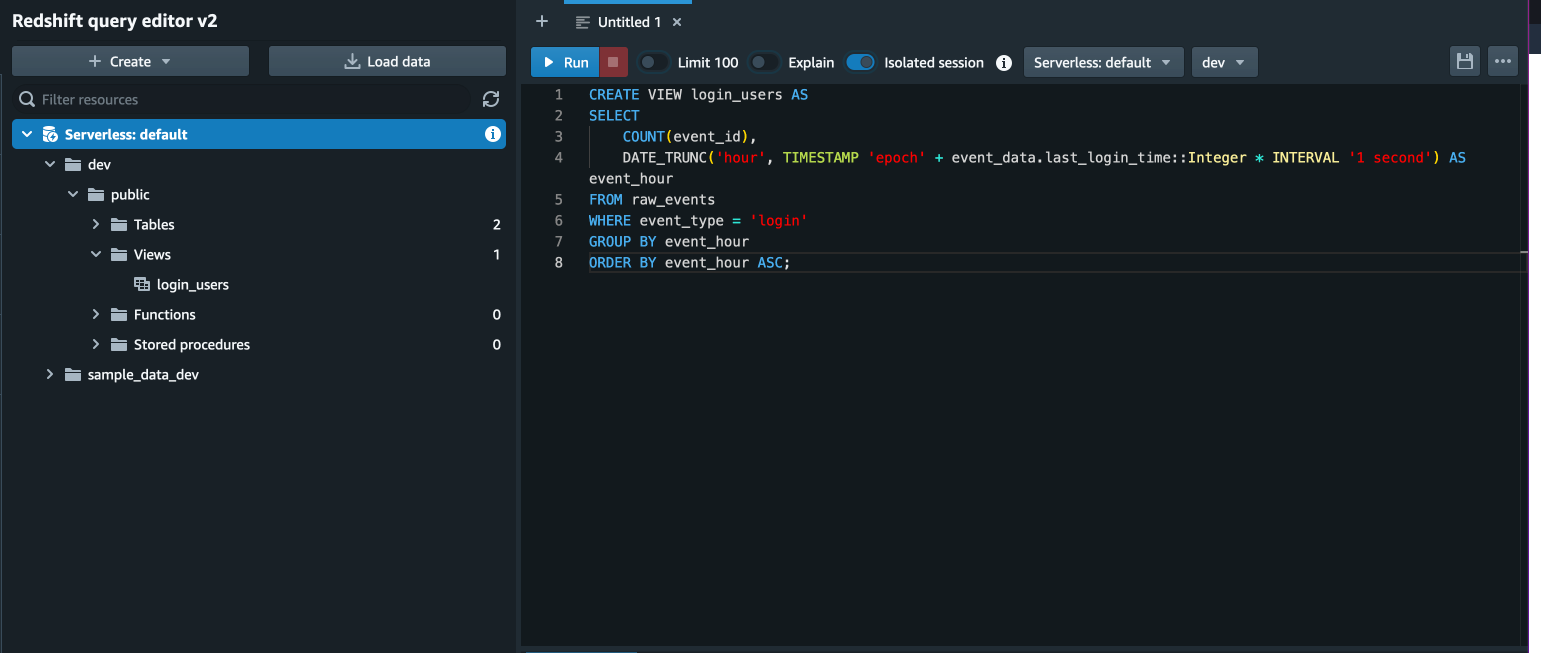
例えば今回のサンプルデータに対して、1時間毎のログインユーザーの推移を集計するためには以下のクエリを実行します。
SELECT
COUNT(event_id),
DATE_TRUNC('hour', TIMESTAMP 'epoch' + event_data.last_login_time::Integer * INTERVAL '1 second') AS event_hour
FROM raw_events
WHERE event_type = 'login'
GROUP BY event_hour
ORDER BY event_hour ASC;
クエリを実行するとこのような画面となり、画面下部の Result タブ内に集計結果が表示されます。
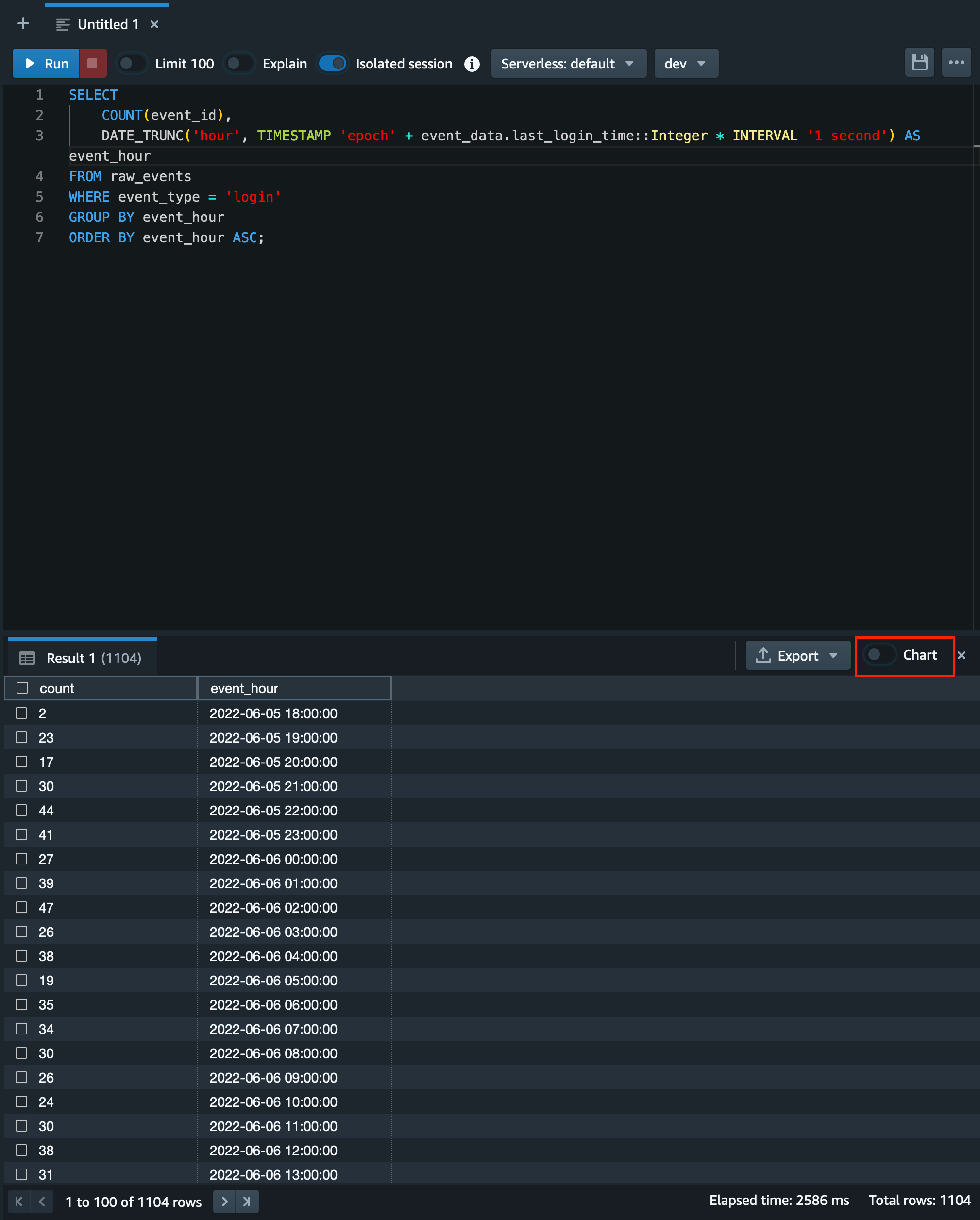
Redshift query editor v2 では集計結果をすぐに簡単に可視化することが可能です。
可視化にあたってはResult タブの右上部にある「Chart」というトグルをオンにします。
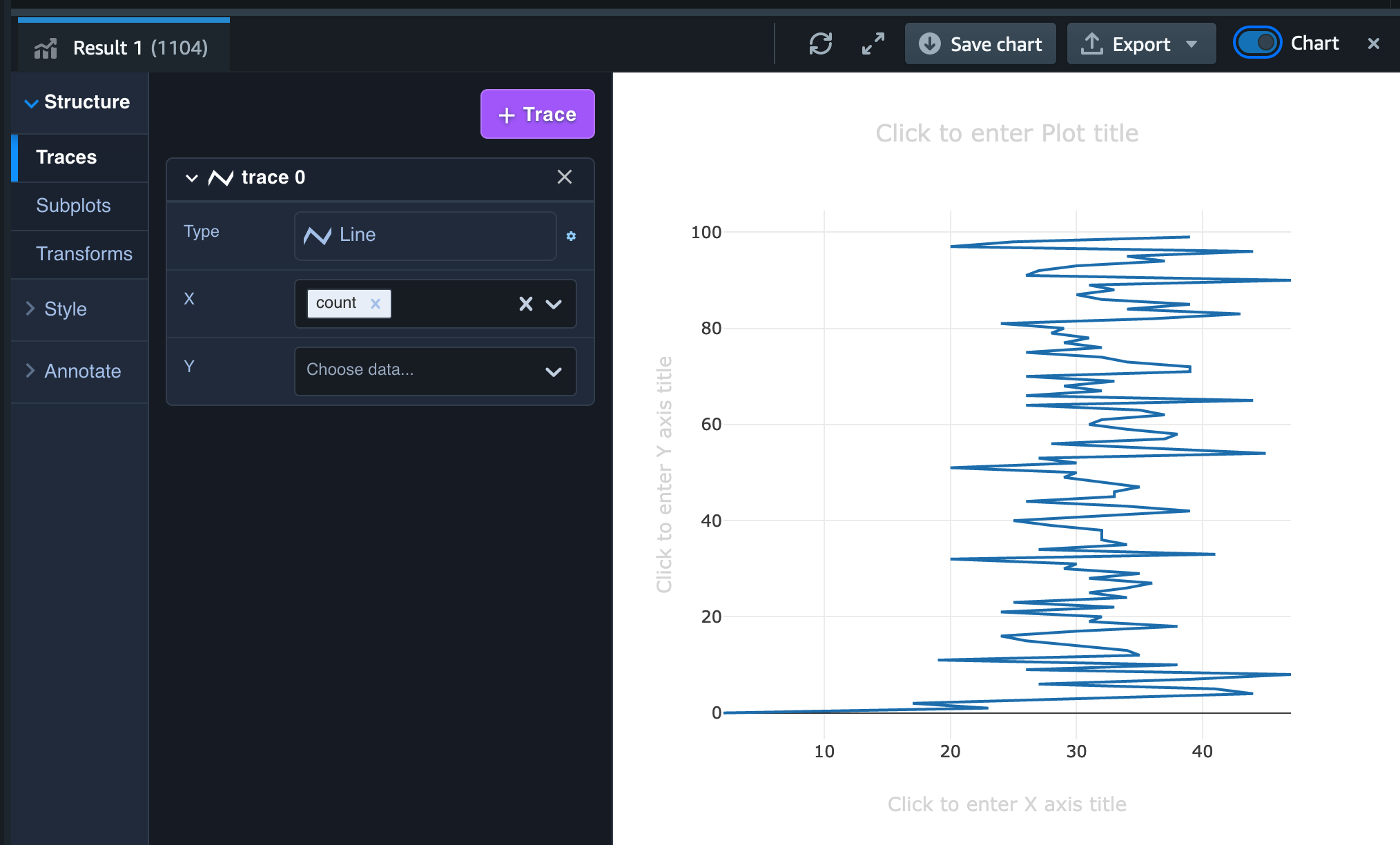
最初はこのようなぐちゃぐちゃのグラフが表示されますが、左のメニューの Type を Line、 X を event_hour、Y を count に変更すると以下のようなグラフになります。
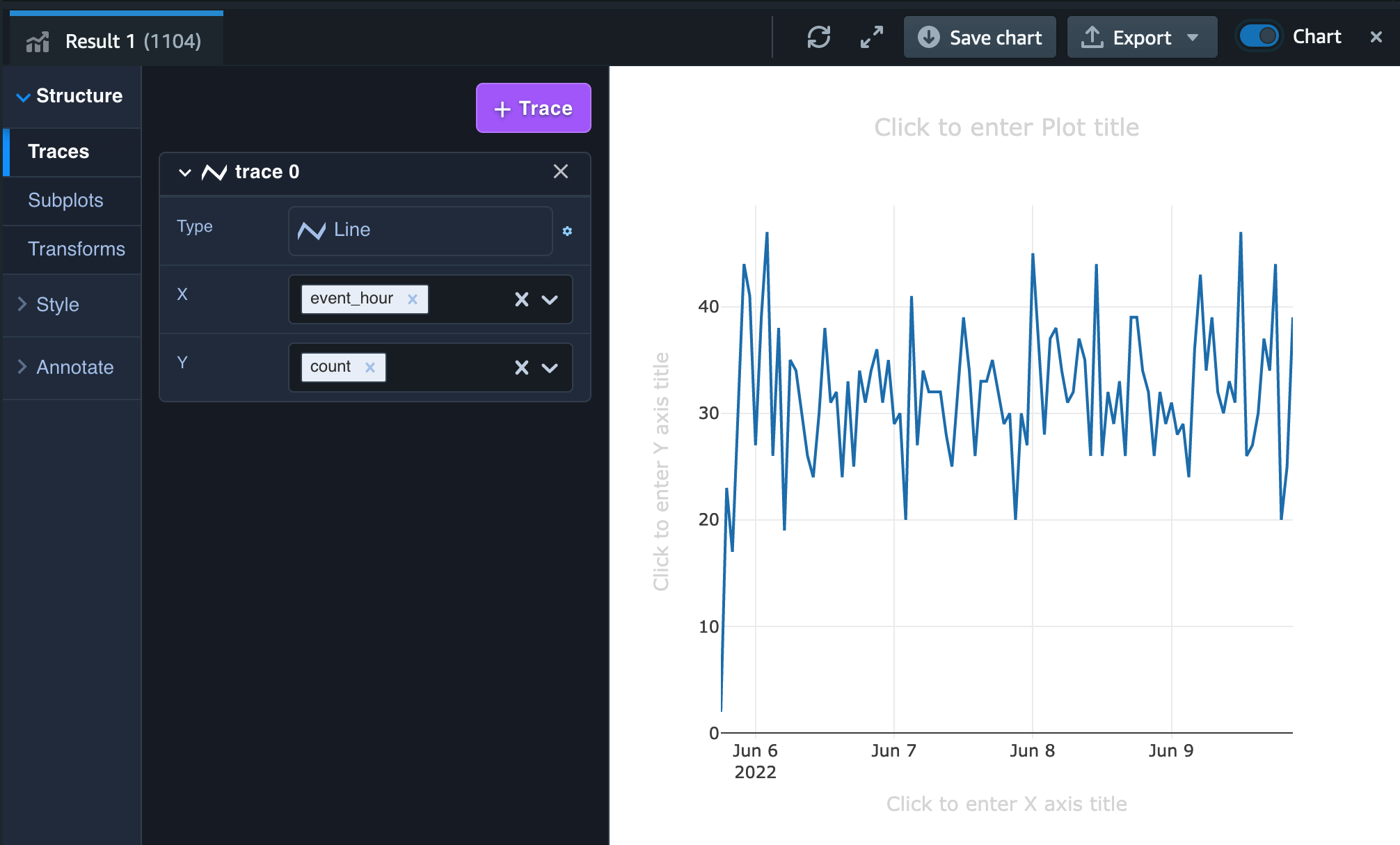
サンプルデータの生成数やそのデータの内容によってグラフそのものの形は異なってきますが、このように1時間毎のログインユーザーの推移を簡単に集計し可視化できることが確認できました。
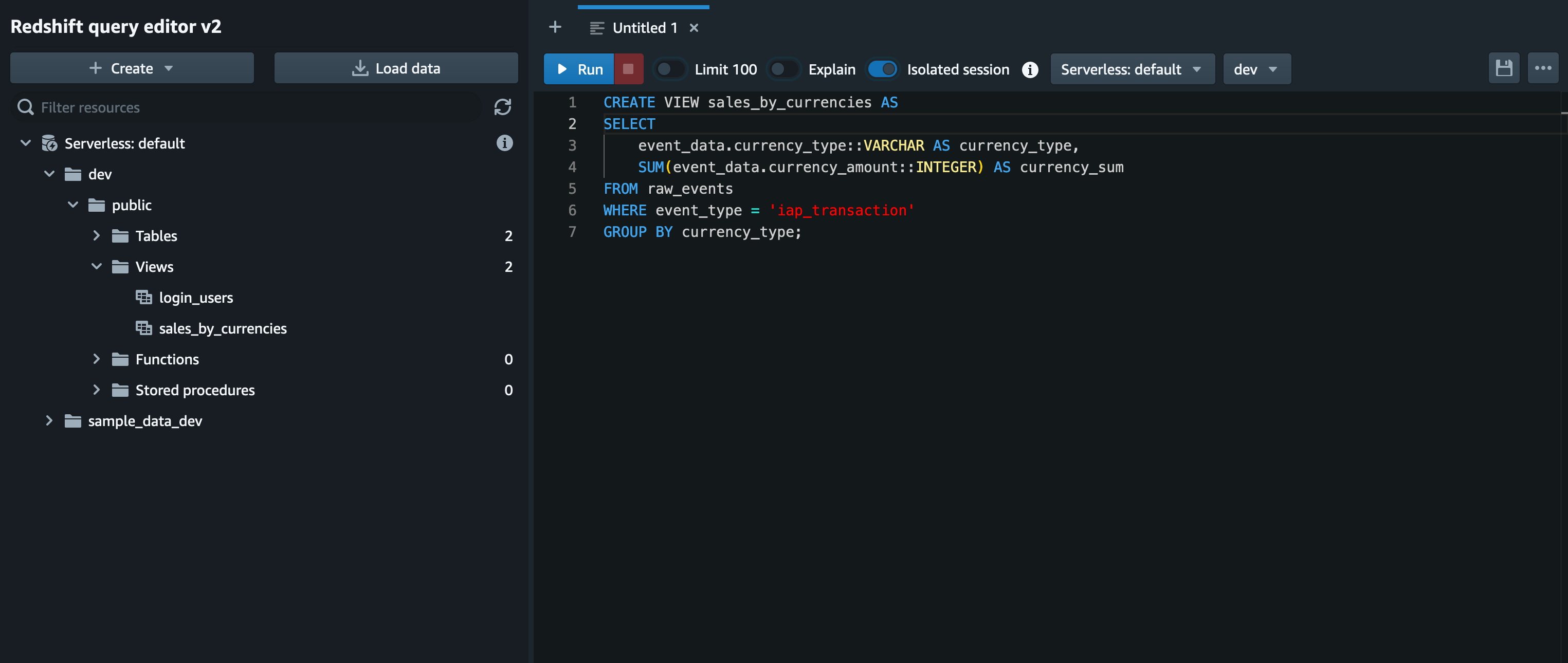
このクエリで得られた結果については、後ほど Amazon QuickSight でも可視化しダッシュボードを共有するというシナリオでも利用するため、以下のクエリを実行し View として保存します。
CREATE VIEW login_users AS
SELECT
COUNT(event_id),
DATE_TRUNC('hour', TIMESTAMP 'epoch' + event_data.last_login_time::Integer * INTERVAL '1 second') AS event_hour
FROM raw_events
WHERE event_type = 'login'
GROUP BY event_hour
ORDER BY event_hour ASC;
同様に課金履歴のログデータの集計も試します。
今回のサンプルデータにおける課金履歴には通貨情報も含まれているため、ここでは通貨別の売上を集計したいと思います。
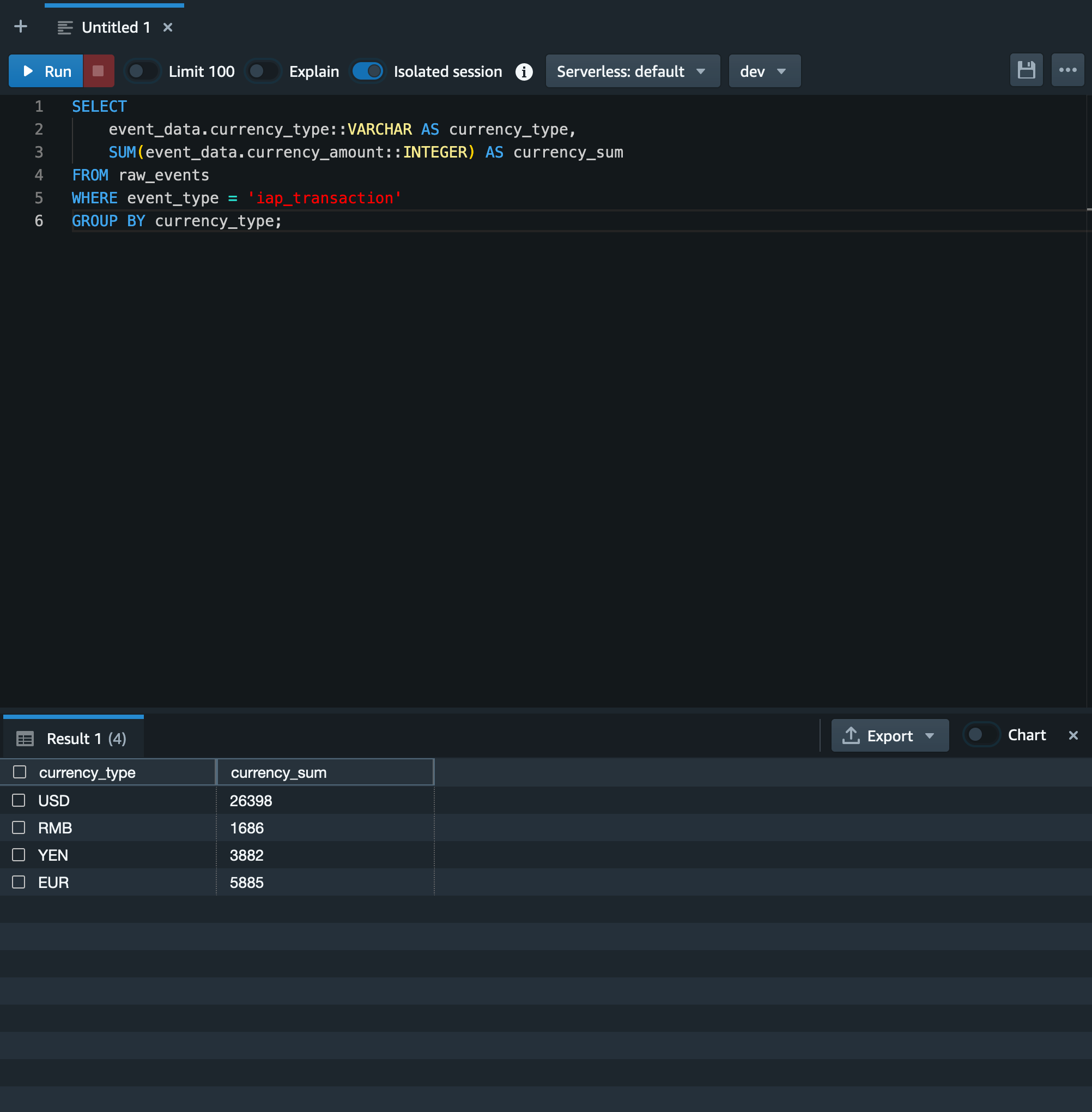
以下のクエリを実行します。
SELECT
event_data.currency_type::VARCHAR AS currency_type,
SUM(event_data.currency_amount::INTEGER) AS currency_sum
FROM raw_events
WHERE event_type = 'iap_transaction'
GROUP BY currency_type;
そうすると以下のような結果になります。
今回のクエリ結果についても簡単に可視化するために「Chart」トグルをオンにします。
通貨別の売上については棒グラフで表現し通貨毎の総売上を横並びで比較したいため、左のメニューの Type を Bar、X を currency_type、Y を currency_sum、Orientation を Vertical にします。
そうすると以下のようなグラフに変わります。
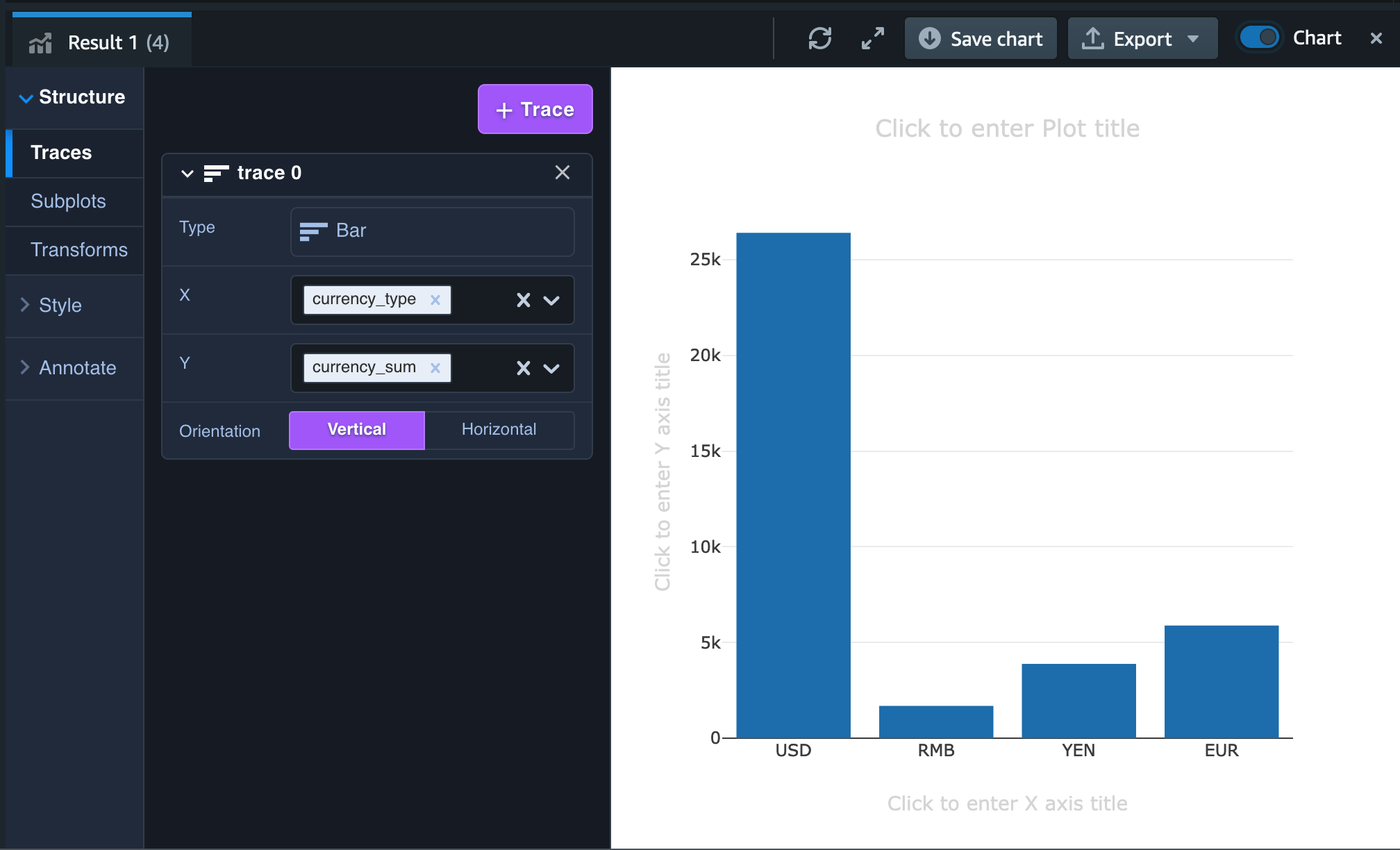
実際にはこれらの通貨を日本円相当で揃えて表示するクエリを作成することが望ましいかと思いますが、今回はこのままで View にしたいと思います。
以下のクエリを実行します。
5. Amazon QuickSight で可視化する
Redshift query editor v2 でクエリを実行し可視化することは既にできていましたが、Amazon QuickSight に集計結果を連携しダッシュボードを作成することで、組織内の多くのメンバーに可視化された分析結果を共有することが可能になります。
今回はそのようなシナリオを想定し、Amazon Redshift Serverless での集計結果を Amazon QuickSight で可視化する手順をご紹介します。
Amazon QuickSight のセットアップはこちらとなりますので、本記事では割愛します。
Amazon QuickSight のセットアップが完了したら右上部のユーザーメニューから「QuickSightの管理」というメニューを開きます。
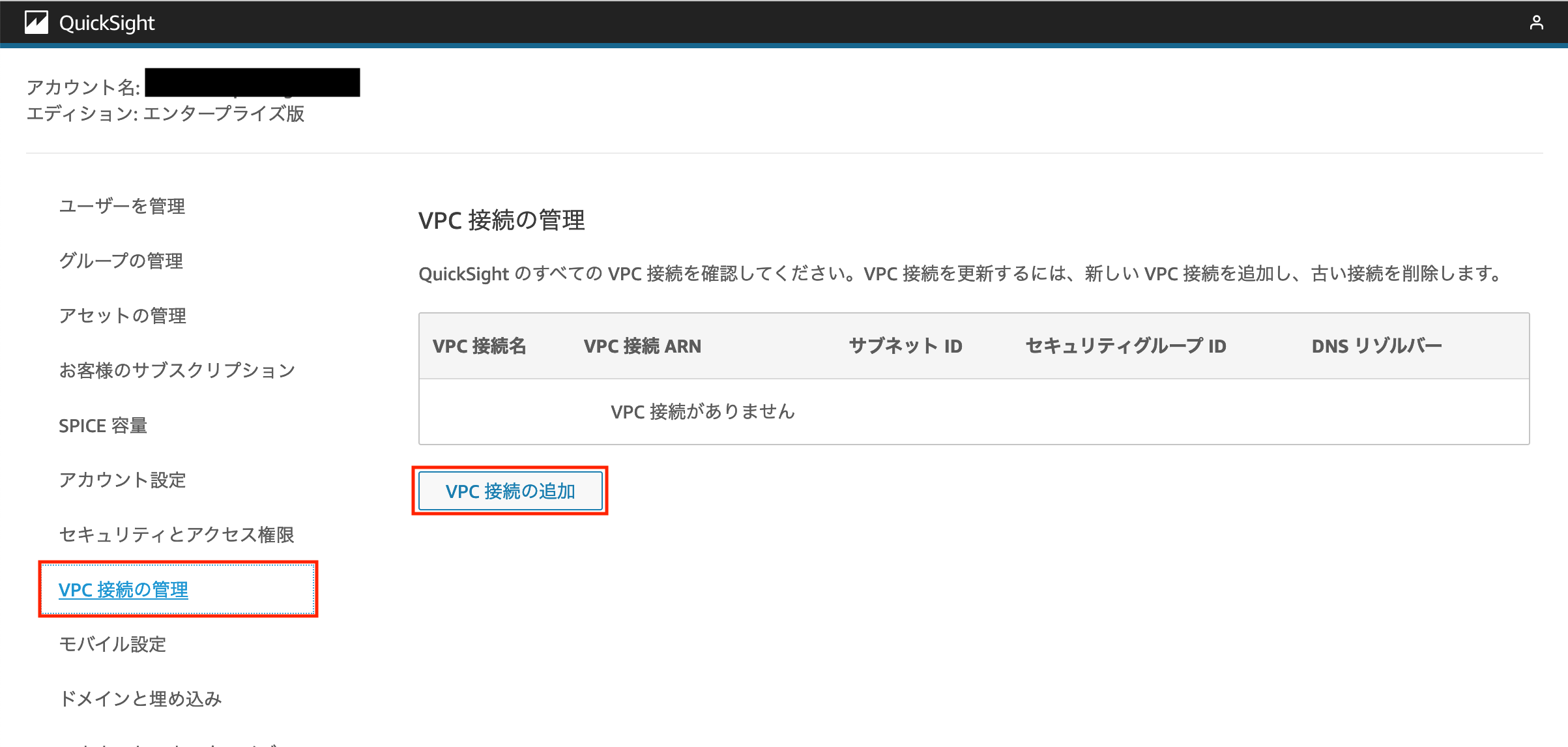
管理メニューにある「VPC 接続の管理」という項目を開き、「VPC 接続の追加」をクリックします。
Amazon QuickSight と Amazon Redshift (Serverless) との接続においては VPC を経由して接続することでそれぞれの接続エンドポイントをパブリックにすることなく、プライベートなネットワークで接続できます。
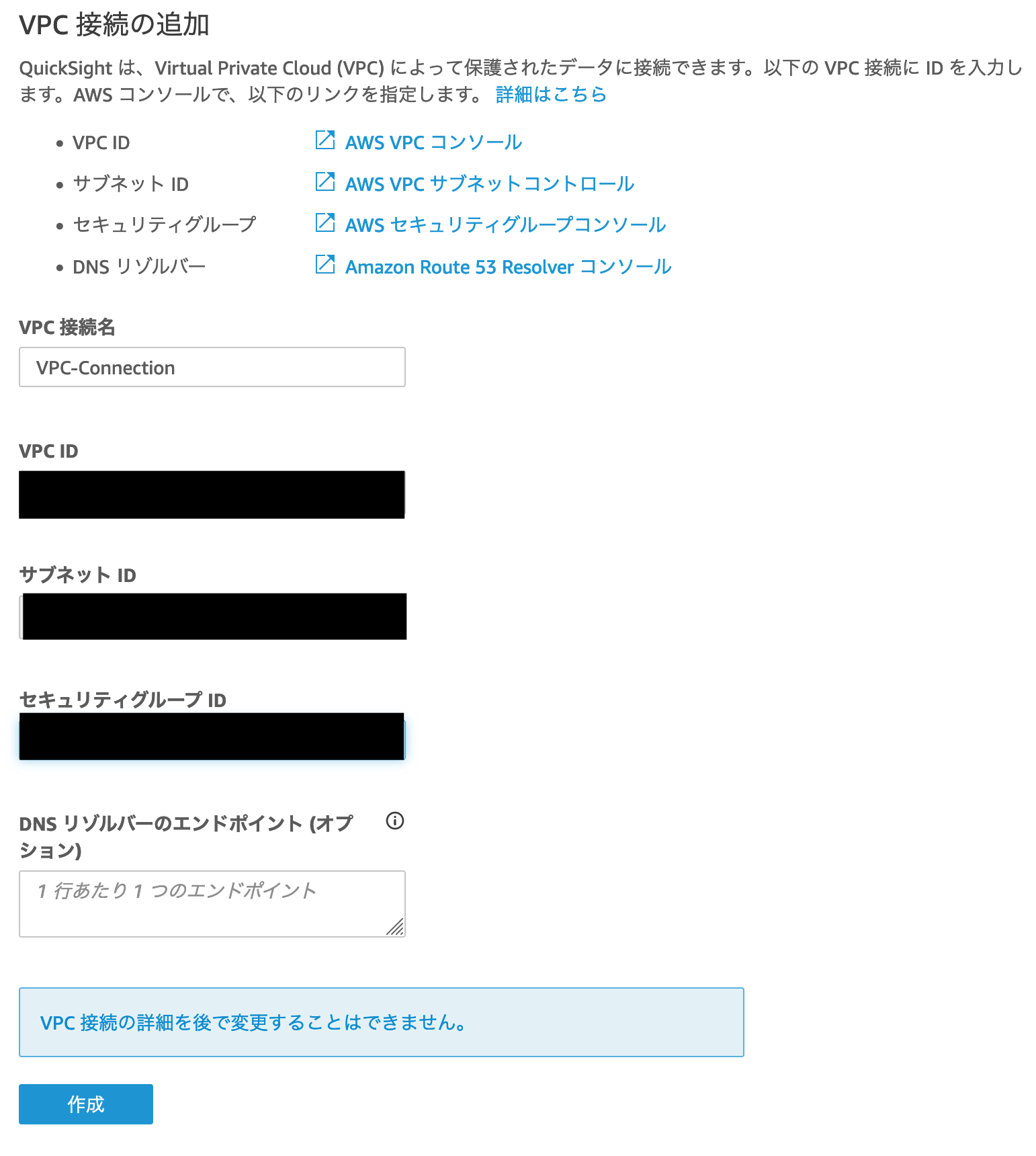
「VPC 接続の追加」における「VPC ID」「サブネット ID」「セキュリティグループ ID」については任意のもので問題ありませんが、後ほど Amazon Redshift Serverless の VPC 接続設定でも同じ VPC、サブネット、セキュリティグループを使うため、どのような設定をしたか覚えておいてください。
Amazon QuickSight で VPC 接続の追加が完了したら、Amazon Redshift Serverless でも同様に VPC 接続に向けた設定を行います。
Redshift query editor v2 から Redshift のコンソール画面に戻り、サーバーレスダッシュボードを開きます。
そこからワークグループのリンクをクリックするとワークグループの設定画面が開けます。
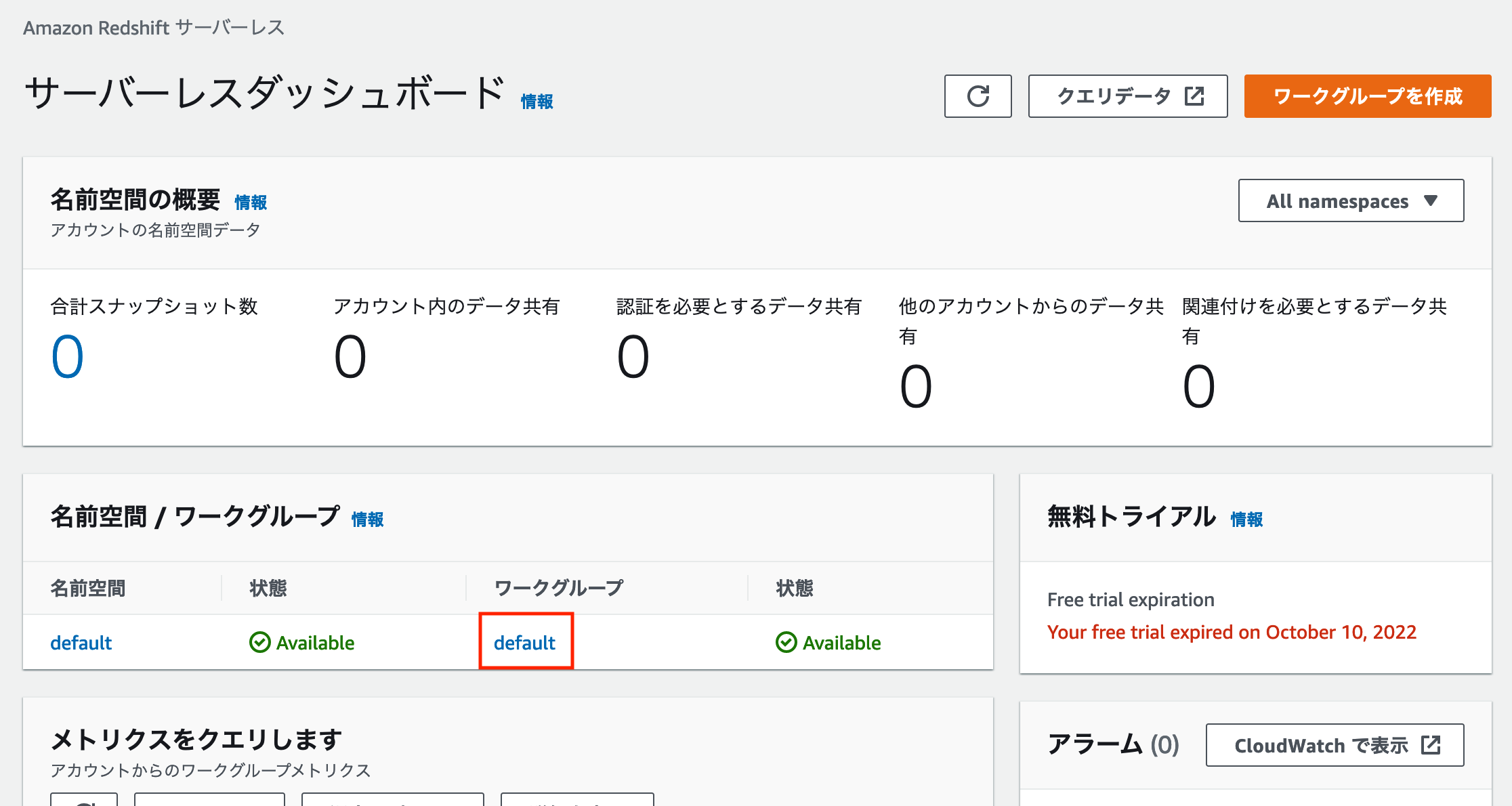
ワークグループの設定画面から「Redshift マネージド VPC エンドポイント」を作成します。
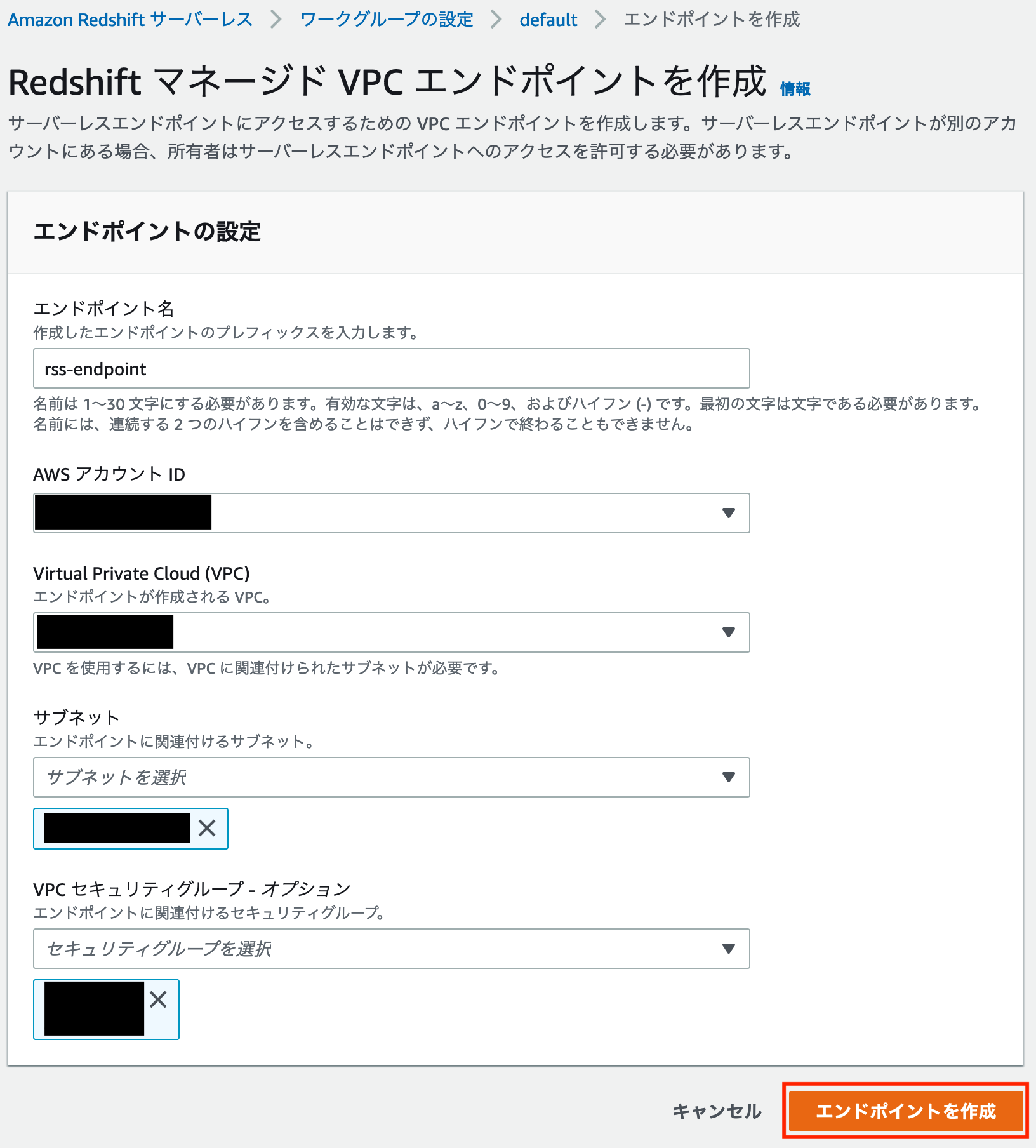
「エンドポイントの作成」というボタンをクリックし、「エンドポイントの設定」の各項目を入力します。
※この時、ワークグループの設定画面に表示されている「エンドポイント」の情報を手元に控えておきます。後ほど Amazon QuickSight から Redshift マネージド VPC エンドポイントに接続する際に利用します。
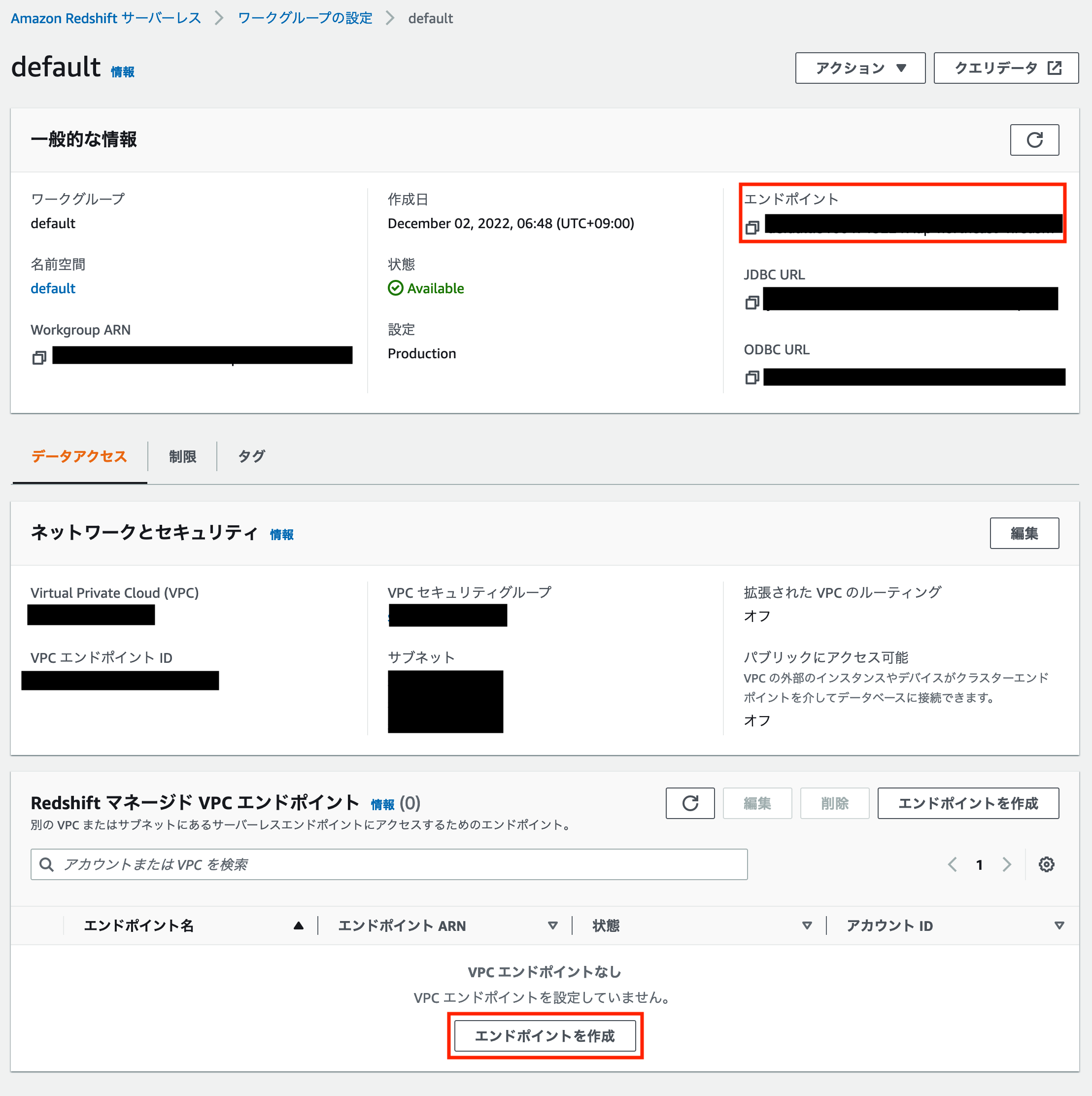
この時、VPC やサブネット、VPC セキュリティグループについては Amazon QuickSight の VPC 接続と同様の設定をします。
設定が完了したら「エンドポイントを作成」をクリックします。
また、VPC 接続をする際には Amazon Redshift のユーザー名とパスワードも必要となりますので、それらを設定します。
ワークグループの設定と同様にサーバーレスダッシュボードから「名前空間」のページを開きます。
「名前空間の設定」ページ上部にある「管理者パスワードを変更」をクリックし、管理者ユーザー名とパスワードを設定します。
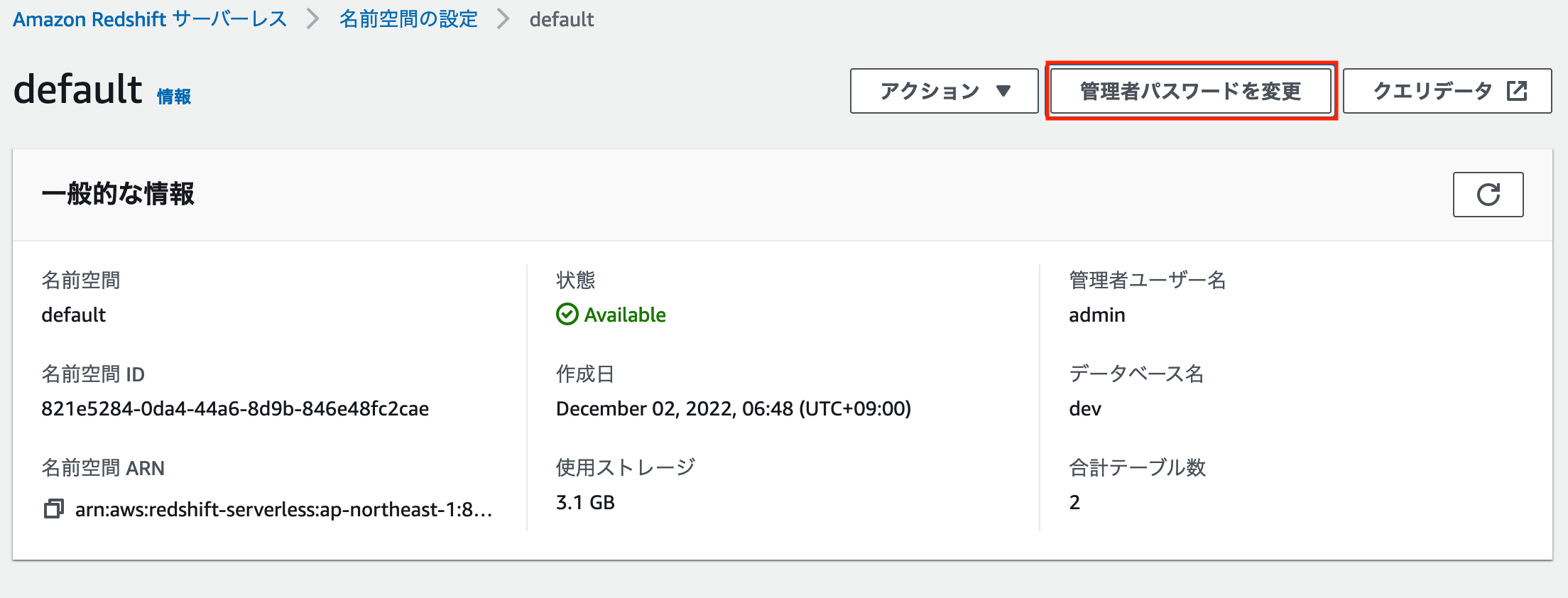
管理者ユーザー名とパスワードの設定が完了したら、Amazon QuickSight のコンソール画面に戻ります。
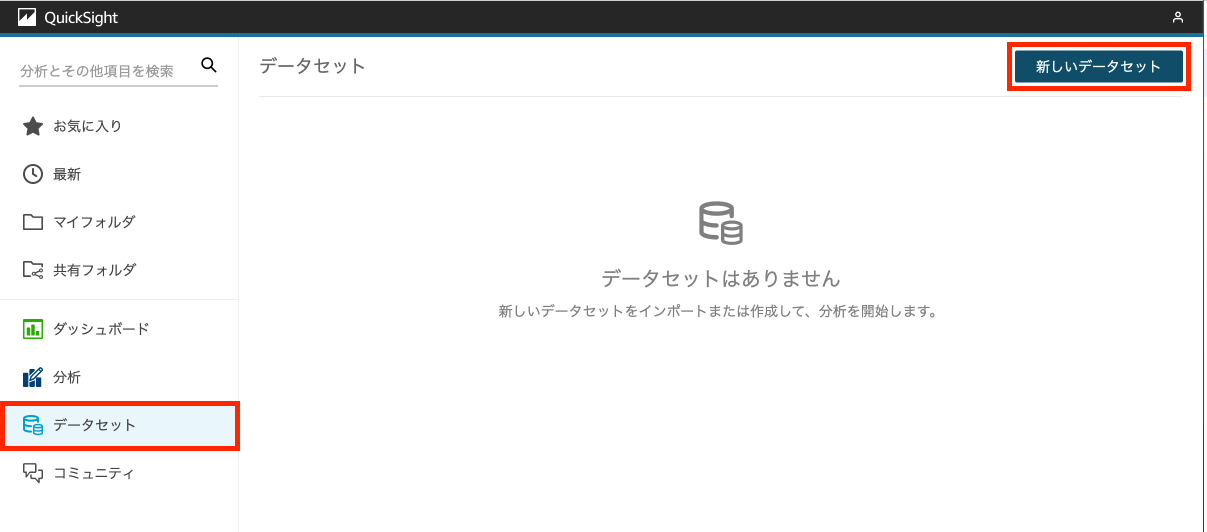
Amazon QuickSight のコンソールの左メニューにある「データセット」を開き、「新しいデータセット」というボタンをクリックします。
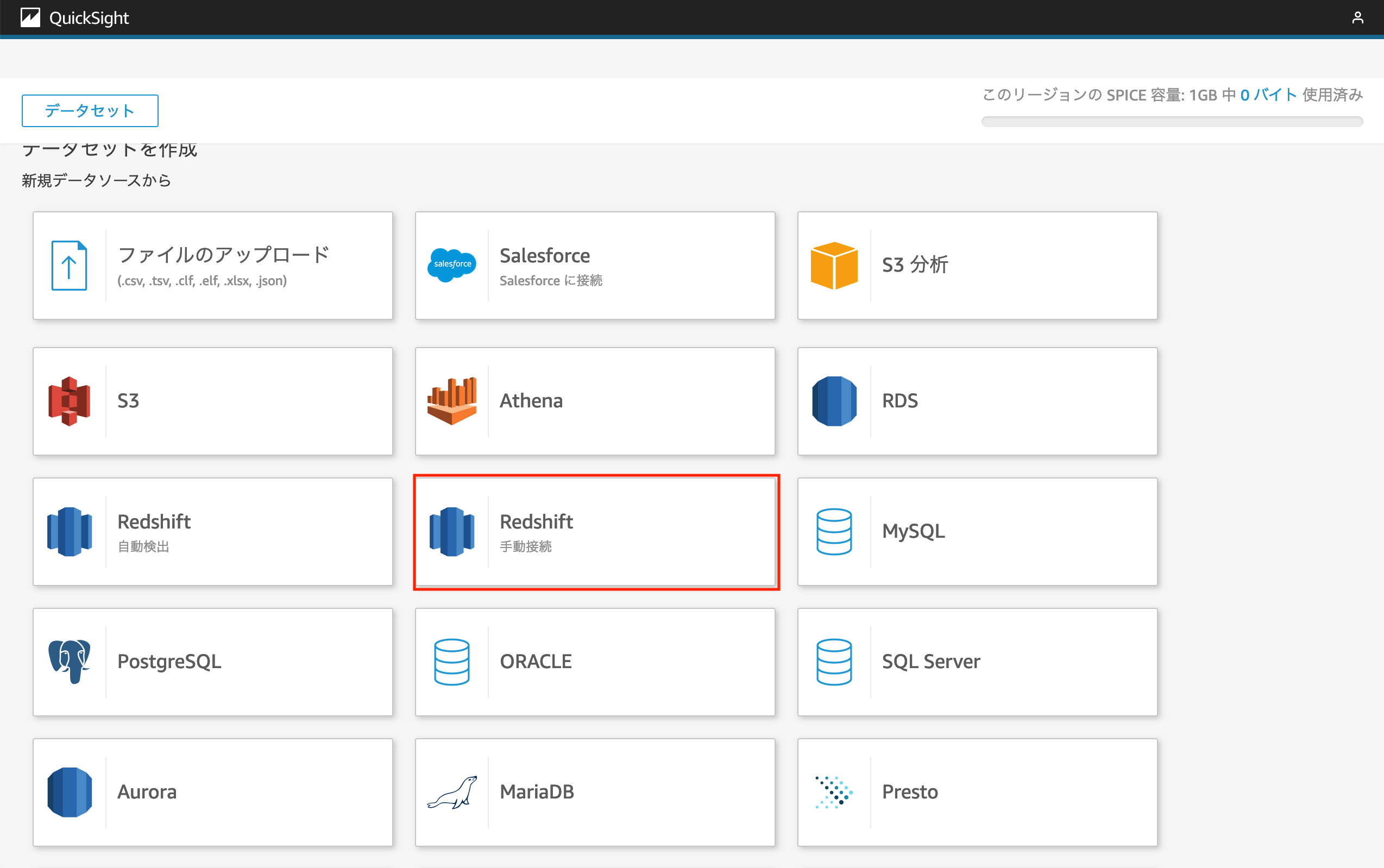
データセットの作成画面では直接 Amazon QuickSight に手元のファイル(CSV, TSV, Excel, JSONなど)をアップロードし Amazon QuickSight での可視化に繋げられる他、Amazon RDS や今回取り上げている Amazon Redshift に保存されているデータを可視化するための設定を行うことができます。
今回は Amazon Redshift Serverless に保存されているデータにアクセスしたいため、「Redshift - 手動管理」をクリックします。
そうすると以下の「新規 Redshift データソース」というポップアップが出てきますので、以下内容を入力します。
- データソース名: 今回使用している Amazon Redshift Serverless を識別するための任意の名称
- 接続タイプ: Amazon QuickSight の管理画面から設定した VPC 接続の接続名を選択
- データベースサーバー: Amazon Redshift Serverless のワークグループの設定画面に表示されていたエンドポイント情報を入力(その際、末尾に
:5439/devという文字列が入るため、それは除外する) - ポート:
5439を入力 - データベース名:
devを入力 - ユーザー名: 先ほど Amazon Redshift Serverless の「管理者パスワードを変更」で設定した管理者ユーザー名
- パスワード: 上記ユーザー名に対応するパスワード
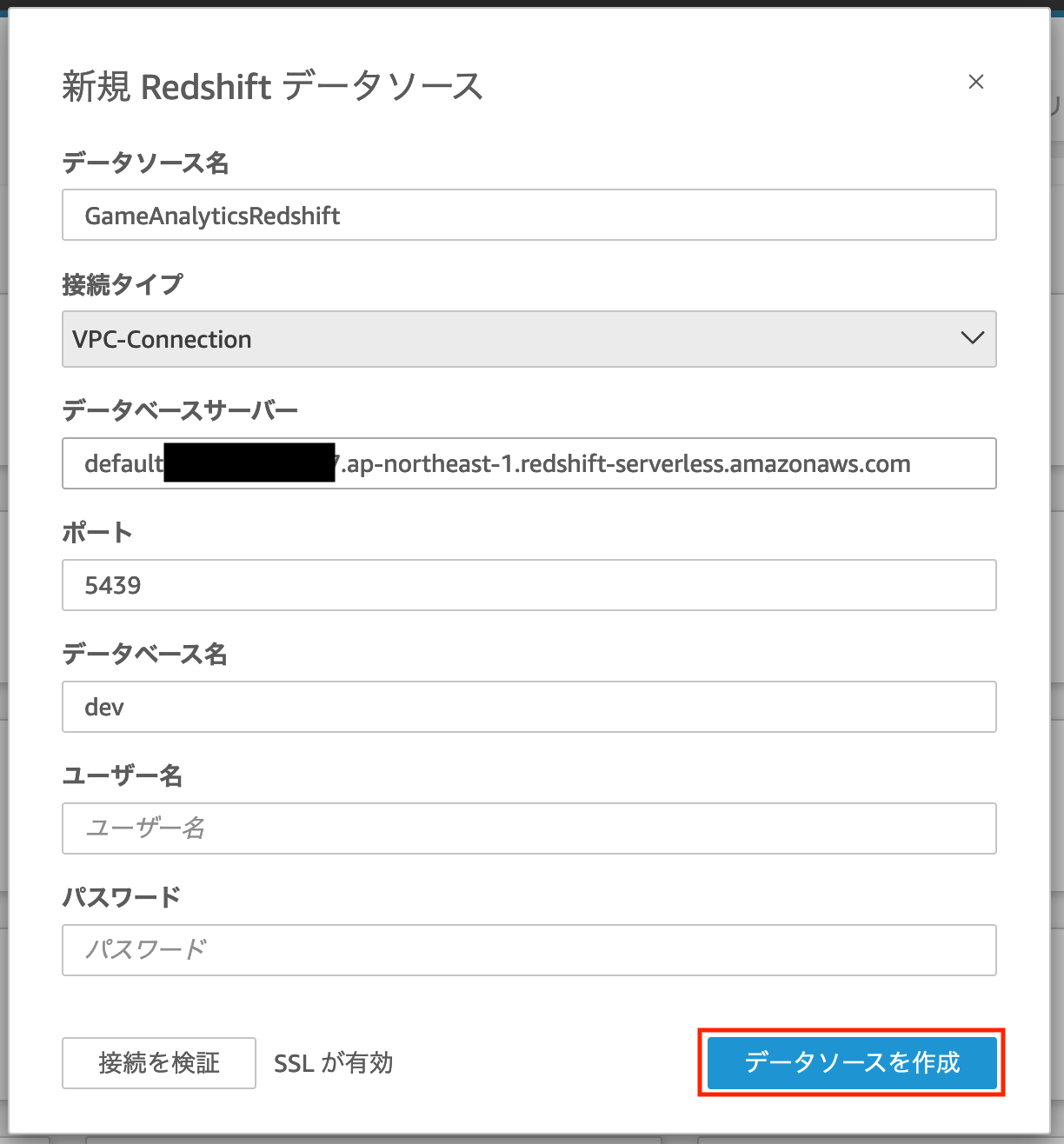
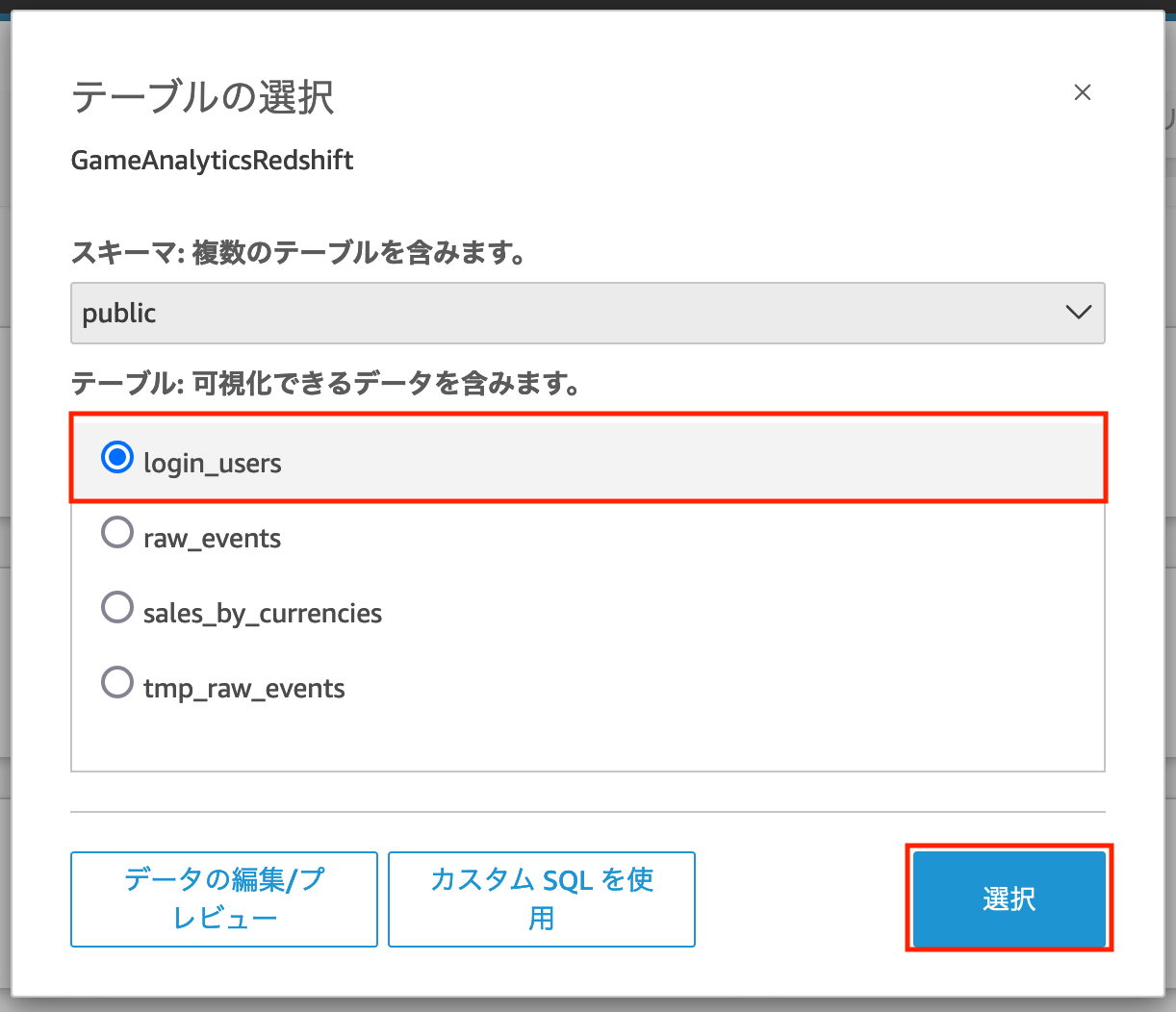
これらの項目を入力し「データソースを作成」をクリックすると以下のような「テーブルの選択」というポップアップが表示されます。
ここでは先ほど Amazon Redshift Serverless で View として保存したクエリも選択できるため、login_usersを選択し「選択」ボタンをクリックします。
そうすると以下のような「データセット作成の完了」というポップアップが表示されますので、右下の「Visualize」ボタンをクリックし、可視化を行います。
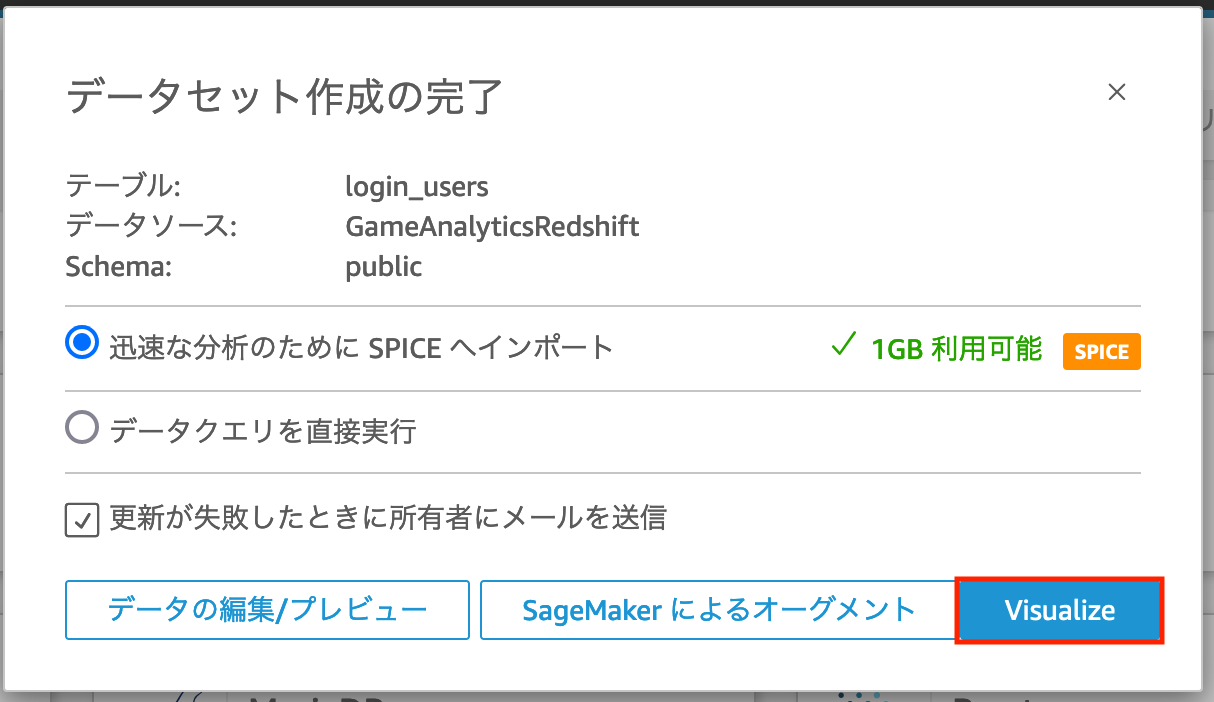
補足ですが、「データセット作成の完了」に表示されている「迅速な分析のために SPICE へインポート」という選択肢の SPICE とは Amazon QuickSight が持つインメモリエンジンであり、Amazon Redshift などのデータソースから取得したデータセットを保存することで、可視化を行う度にデータソースへのアクセスを行わず SPICE に保存されたデータセットへ高速にアクセスすることが可能となります。
一度のデータセットの作成につき、1つのテーブル(View)のみ選択できるため、login_usersと同様にsales_by_currenciesを選択したデータセットを作成します。
一度データソースとして作成されているデータソースを利用する場合は、データセットの作成画面の下部にある「既存データソースから」という箇所にそのデータソースが表示されており、接続情報を毎回入力する必要はありません。
最後に「データセット作成の完了」から「Visualize」をクリックした後、グラフの作成を行う方法についてご紹介します。
Amazon QuickSight では分析の作成と表現されますが、以下のような画面でデータセットとビジュアルタイプを指定し、グラフのフィールド(X軸, 値など)を指定することで簡単にデータの可視化を行えます。
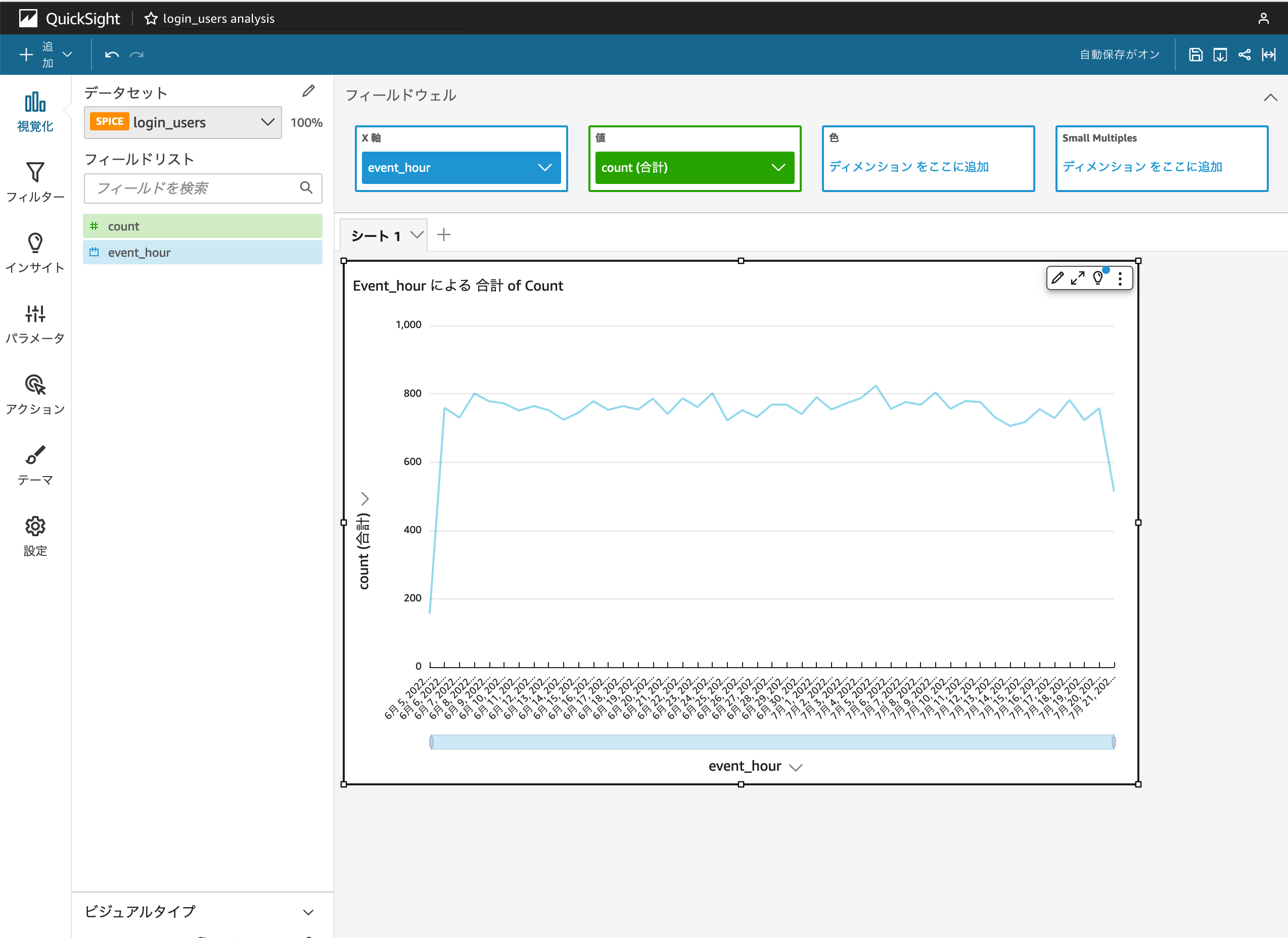
例えばデータセットlogin_usersを選択した場合は、ビジュアルタイプで折れ線グラフを選択し、X軸にevent_hour、値にcountを選択すると以下のような1時間毎のログインユーザー数の推移のグラフを作成できます。
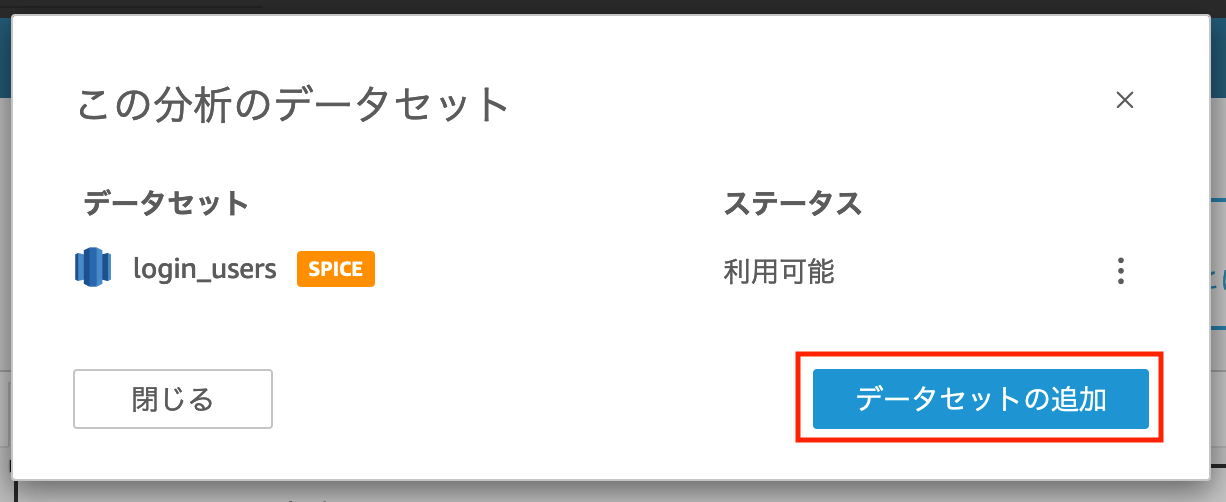
また、データセットsales_by_currenciesを同じ分析に追加することも可能です。
データセット名が表示されている箇所の右上にある鉛筆マークをクリックすると、以下のようなポップアップが表示されますので、「データセットの追加」をクリックすると任意のデータセットを追加できます。
sales_by_currenciesも同様に垂直棒グラフで可視化をすると以下のようになります。
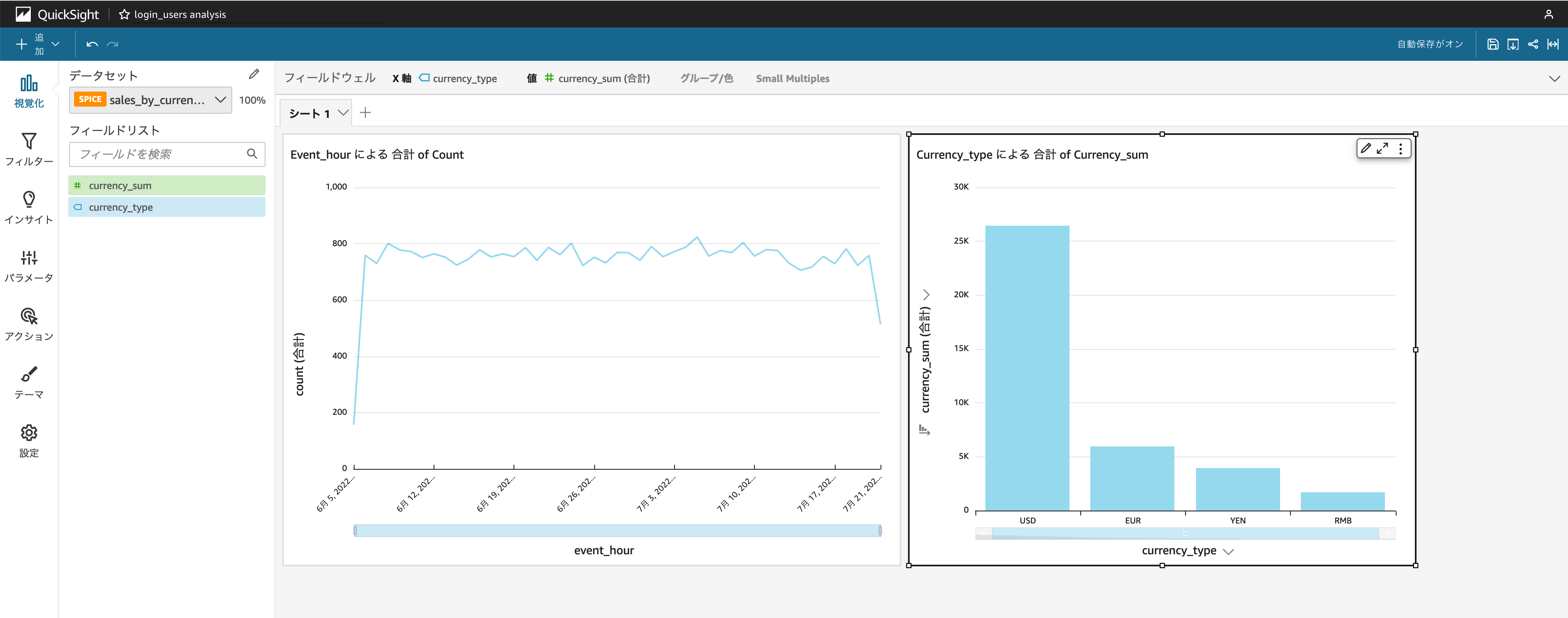
今回は簡単な集計結果をシンプルなグラフにしたのみですが、Amazon QuickSight は様々なグラフを使った高い表現力による可視化が可能となっていますので、お手元にデータがあればぜひ一度 Amazon QuickSight をお試しください。
一通り可視化したグラフが揃ったら、右上の「共有」メニューから「ダッシュボードの公開」をし、AWS アカウントを持たない他のメンバーにも可視化したダッシュボードを共有することができます。
以上が ゲーム分析パイプラインで生成したサンプルデータを元に Amazon Redshift Serverless と Amazon QuickSight を使ったゲーム分析環境の構築例となります。
最後に
ここまでご覧いただきまして、ありがとうございました。
本記事を通して、Amazon Redshift Serverless と Amazon QuickSight を使えばインフラストラクチャの管理は必要なくブラウザベースで Amazon S3 上にあるデータをすぐに集計し、可視化して他のメンバーに分析ダッシュボードを共有できるサービスであるということをご紹介しました。
今後のゲーム分析に、Amazon Redshift Serverless や Amazon QuickSight をお役立ていただけましたら幸いです。