概要
前回作成した牌検出モデルにおいて、ultralytics YOLO のモデルやバージョンごとに精度差があるか確認したので、結果を紹介します。
TD;DR
YOLOのバージョン差はほぼないが、モデル差は顕著である。

今回の検証の目的
学習・推論の効率と精度のバランスを踏まえて、使用するモデルやバージョンを選定する。
前提
下記の条件で比較を行いました。
- ベースとするYOLOのモデル、バージョン
- Version: v5、v8、v11
- Model: n(nano), s(small), m(medium)
- l(large), x(xlarge)は除外
- 正確には v5 の n/s/m は nu/su/mu が使用される
- 実行環境
- CPU: Core i7-9700F (3.0GHz)
- Mem: 32GB
- GPU: RTX2070 Super (VRAM: 8GB)
- 学習時のハイパーパラメータ
- epochs: 100
- patience: 50
- batch: 8
- imgsz: 640
- 学習データ数: 549枚
検証結果
学習時間
まずは学習に掛かった時間です。縦軸の単位は分になります。

バージョン、モデルごとに大きな差が出ています。
モデルに関しては nano < small << medium 、バージョンでは v5 < v11 < v8 という順番で学習時間が掛かりました。特に medium モデルは他のモデルの2倍近い学習時間になるため、それに見合った精度が必要となりそうです。
精度(mAP50-95)
valの画像に対しての mAP50-95(※)です。
バージョンによる差はほぼ見られませんが、モデルは nano < small <= medium の順番で精度が高くなりました。推論する牌の種類が少ない影響か、small と medium に差がないのは印象的です。
※mAP50-95: 0.50から0.95までのさまざまなIoU閾値で計算された平均適合率の平均。さまざまなレベルの検出難易度におけるモデルのパフォーマンスの包括的なビューを提供します。)
推論時間
学習したモデルを使い推論を行った際の計算時間です。GPU と CPU の2パターンで測定しました。縦軸の単位はミリ秒です。
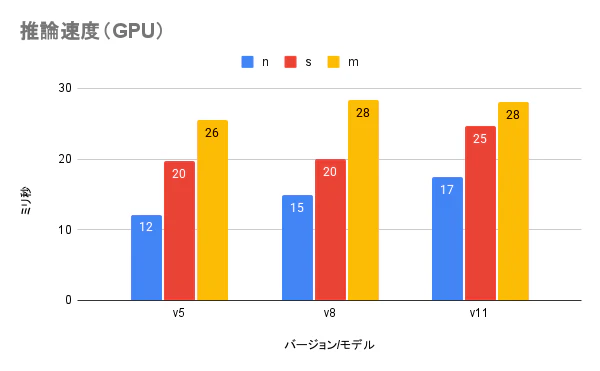
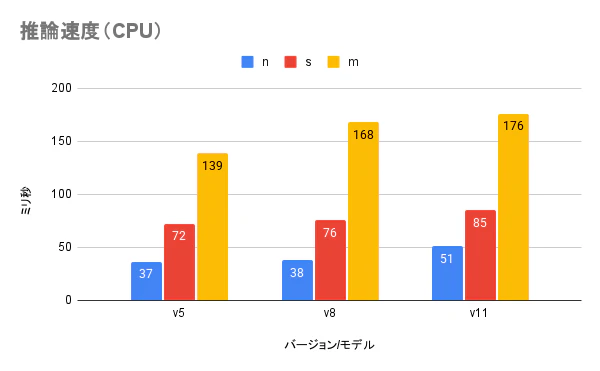
モデルは nano < small < medium で、バージョンは v5 < v8 < v11 という順番で推論時間が掛かりました。学習時間と同じグラフになると思いましたが、モデル差はより顕著に、バージョン差に関しては v8 と v11 の関係が逆転しています。特に medium モデルかつ CPU を使用した時の170msという推論時間は、リアルタイムでの推論には向きません。
リアルタイムでの推論について
ここで推論時間が20msや170msと聞くと高速に聞こえますが、FPS換算だと20msは50FPS、170msは6FPSにしかなりません。仮に60FPSで推論するなら最低でも16.6msの処理速度が必要となります。これは nano を使用して GPU を搭載したマシンで実行しないと実現が難しそうです。更に言えば、一般的な GPU 非搭載のスマホなどでは nano を使ったとしても10~20FPS程度が限界かもしれません。
新規画像に対する推論精度
学習画像とかけ離れた新しい画像に対して、どの程度の精度が出るのか確認しました。定量的な評価をしていないので、実際に推論した画像を載せます。

バージョン差はあまり感じませんが、モデル差は nano の精度が著しく低いように感じます。small、mediumの差は相変わらずほぼないですね。valに対する精度は nano が small、medium よりも10%低い結果になりましたが、新規画像に関してはそれ以上に精度差があるように感じます。
考察
バージョンごとに精度差は無かったので、学習時間と推論時間の短いv5が今回の用途に適しているようです。更にモデルに関しては small がバランスがよさそうです。nano は精度的に劣っており、medium は学習時間と推論時間の割りに精度差がないためです。
この結論は今回の用途に限った話だと思います。実際にはバージョンやモデルごとにレイヤー数(※)やパラメータ数(※)が大きく異なっているため、その差が用途によっては精度に大きく影響することがあるはずです。まずは事前に小さなデータセットで各バージョンごとのモデルを検証してベストなモデルを選出して本番の学習に挑むのが良いと思います。

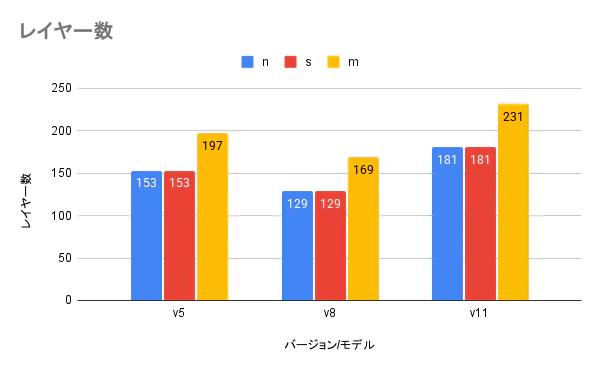
※パラメータ数は v5 < v11 < v8、レイヤー数は v8 < v5 < v11 となっている。どのバージョンでも nano より small の方がパラメータ数は多い一方でレイヤー数が同一な点は興味深い。
おまけ
計測したものの特に有用な結果を得られなかったデータ集です。
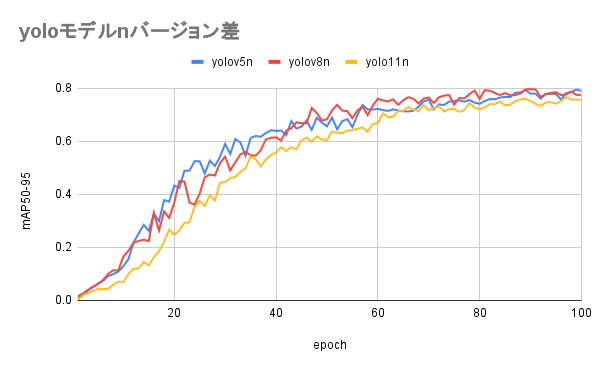
epoch ごとの mAP の推移
epochが増えるにつれて、mAPがどのように推移していくのか計測した結果です。バージョン、モデルによっては素早く集束して学習が終わるかと期待しましたが、特にそういう事はなかったです。
モデルごと
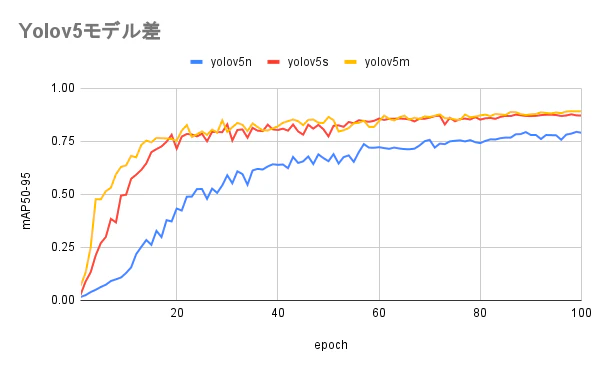


バージョンごと


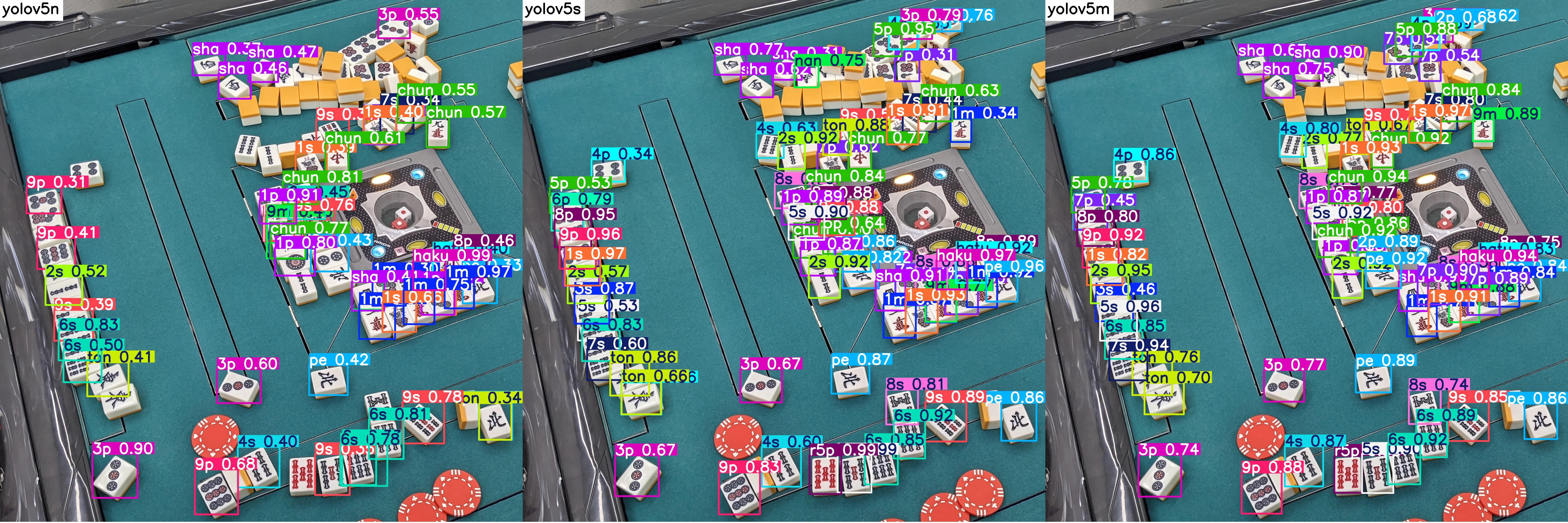
val画像の推論結果
学習データのvalに対して推論した画像になります。 nano は画像右上の牌をほとんど認識できませんでした。


別の新規画像に対する推論結果
学習データとは別の場所で撮影した画像に対する推論結果です。v11 の推論結果が悪く、特に nano は一つも検出されませんでした。逆に v8 は nano でもそれなりに検出できています。このようにバージョンやモデルの相性が顕著に出ることもあります。


