概要
「文字認識?そんなの AI サービスに投げれば終わりでしょ?」
確かにその通りです。Cloud Vision API などを使えば、どんな画像でも一瞬で高精度にテキスト化できます。しかし、一日 1,000 枚処理すれば月間で 43.5$ のコストがかかります。
「特定のゲーム画面の、この座標にある数字だけを読み取りたい」といった、用途が限定されたミクロなタスクに対して、それは本当に最適な解決方法でしょうか?
そこで本記事では、完全無料で OCR を実現する Tesseract.js と、弱点である精度の低さを補うための OpenCV.js を駆使した前処理をご紹介します。
前処理でこれを

↓
こうします
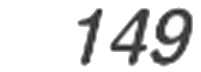
基本的な使い方
まずは基本的な使い方をご紹介します。
スクリプトタグと画像だけ実現可能です。
-
scriptで CDN を指定します<script src='https://cdn.jsdelivr.net/npm/tesseract.js@5/dist/tesseract.min.js'></script> -
scriptでworkerを作成します。workerとは Web ワーカーで実行されるTesseractのインスタンスを作成および管理するオブジェクトですconst worker = await Tesseract.createWorker(); -
worker.recognizeでimgの画像を OCR します。使用可能な画像フォーマットは bmp、jpg、png、pbm、webp、gif で、データタイプは File、Blob ですconst imgElement = document.getElementById('input'); const ret = await worker.recognize(imgElement); -
OCR 結果から読み取ったテキストを取得します
document.getElementById('result').innerText = ret.data.text; -
インスタンスを解放します
await worker.terminate();
コードの全量は下記のようになります。
<html>
<head>
<script src='https://cdn.jsdelivr.net/npm/tesseract.js@5/dist/tesseract.min.js'></script>
</head>
<body>
<img id="input" src="image.png"/>
<div id="result"></div>
<script>
(async () => {
const worker = await Tesseract.createWorker();
const imgElement = document.getElementById('input');
const ret = await worker.recognize(imgElement);
document.getElementById('result').innerText = ret.data.text;
await worker.terminate();
})();
</script>
</body>
</html>
tesseract の便利な機能
Tesseract.js に存在する便利な機能の一部をご紹介します。
言語設定
画像内に存在する文字の言語を設定できます。
デフォルトだとすべて英語として認識します。
const worker = await Tesseract.createWorker('jpn');
// 複数言語を認識させる場合は配列で指定
const multi = await Tesseract.createWorker(['jpn', 'chi_tra']);
なお、jpnに設定してもアルファベットは認識可能です。対応している言語はこちらをご覧ください。
ホワイトリスト
認識させたい文字を設定できます。
例えば数字だけ認識させたい場合は下記のように設定します。
const worker = await Tesseract.createWorker();
await worker.setParameters({
tessedit_char_whitelist: '0123456789',
});
ページセグメント
画像全体の文字をどのような単位で読み取るのか設定できます。
const worker = await Tesseract.createWorker();
await worker.setParameters({
tessedit_pageseg_mode: Tesseract.PSM.SINGLE_LINE,
});
設定可能な値と説明(原文)は下記のとおりです。
| 設定値 | 説明 |
|---|---|
| OSD_ONLY | Orientation and script detection only. |
| AUTO_OSD | Automatic page segmentation with orientation and script detection. (OSD) |
| AUTO_ONLY | Automatic page segmentation, but no OSD, or OCR. |
| AUTO | Fully automatic page segmentation, but no OSD. |
| SINGLE_COLUMN | Assume a single column of text of variable sizes. |
| SINGLE_BLOCK_VERT_TEXT | Assume a single uniform block of vertically aligned text. |
| SINGLE_BLOCK | Assume a single uniform block of text. (Default.) |
| SINGLE_LINE | Treat the image as a single text line. |
| SINGLE_WORD | Treat the image as a single word. |
| CIRCLE_WORD | Treat the image as a single word in a circle. |
| SINGLE_CHAR | Treat the image as a single character. |
| SPARSE_TEXT | Find as much text as possible in no particular order. |
| SPARSE_TEXT_OSD | Sparse text with orientation and script det. |
| RAW_LINE | Treat the image as a single text line, bypassing hacks that are Tesseract-specific. |
事前に読み取りたい文字が一列の単語だと分かっているなら SINGLE_WORD を設定することで、認識精度が上がる可能性かもしれません。
その他
その他にも内部処理の画像を出力する imageBinary、処理過程のメッセージを出力する logger などデバッグに便利な機能がたくさんありますが、ここでは紹介しきれないのでAPIをご参照ください。
汎用的な前処理
ここからは本題の前処理についてです。Tesseract は読み取る画像にノイズがあると認識精度がガタ落ちします。如何にノイズを除去するのかが重要になるわけですが、私がよく使う方法をご紹介します。
Tesseract でも内部で二値化(大津の手法)を行っていますが、背景が複雑だとノイズを文字として拾い上げてしまうため、適切な前処理が必要となります。
画像編集ライブラリ
画像編集を行うのに opencv.js を利用します。python 版と異なりメモリ管理を手動で行う必要がある点に注意してください。
基本的な使い方
opencv.js の読み込みを onRuntimeInitialized で待ち、cv.imread で画像を読み込みます。
<script src="../main/public/opencv.js" async></script>
<script>
var Module = {
// opencv.js が読み終わったら呼び出される関数
onRuntimeInitialized: async () => {
// 1. img 要素を取得
const imgElement = document.getElementById('image');
// 2. img 要素から cv.Mat インスタンス生成
const mat = cv.imread(imgElement);
// 3. 加工など
// 4. tesseract.js で使うために cv.Mat を canvas に書き出し
const canvas = document.createElement('canvas');
cv.imshow(canvas, mat);
// 5. 【重要】使用後はメモリ解放!
mat.delete();
}
};
</script>
以降のサンプルでは簡略化のために delete() は省略しています。
拡大
画像を拡大します。これだけでもかなり認識精度が高くなるのでお勧めです。
const src = cv.imread(imgElement);
const dst = new cv.Mat();
cv.resize(src, dst, new cv.Size(240, 120));

認識結果:""(認識されず)
↓

認識結果:"ABCDE"
切り出し
文字部分だけ切り出します。読み込む文字の位置がある程度固定されているときにお勧めです。
const src = cv.imread(imgElement);
const dst = src.roi(new cv.Rect(100, 120, 100, 40));
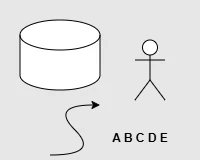
認識結果:"= %[he"("%"と"["の間に改行が入っていましたが削除しています)
↓

認識結果:"ABCDE"
なお、切り出しだけなら recognize 時の引数でも対応できます。
const src = cv.imread(imgElement);
const ret = await worker.recognize(src, { rectangle: {
left: 100, top: 120, width: 100, height: 40,
}});
// 認識結果: "ABCDE"
閾値処理
特定の閾値の色を抽出します。文字の色や濃さが明らかに異なる場合に使うと効果的です。
const src = cv.imread(imgElement);
const lower = new cv.Mat(src.rows, src.cols, src.type(), [0, 0, 128, 0]);
const upper = new cv.Mat(src.rows, src.cols, src.type(), [128, 128, 255, 255]);
const binary = new cv.Mat();
// 青文字が白く、背景が黒くなります
cv.inRange(src, lower, upper, binary);
const dst = new cv.Mat();
// 認識しやすいように色を反転して白地に黒文字にします
cv.bitwise_not(binary, dst);

認識結果: ""(認識なし)
↓

認識結果: "ABCDE"
特定の色の抽出なら HSV に変換して色相を使った方が分かりやすいです。
個別の前処理
ここからは特別な処理が必要なケースについてです。
例えば下記の画像から右下の数値を読み取りたい場合、大きく2つの問題が発生します。
- イラストと文字が重なっているので切り取っても読み取れない
- イラストと文字の色が似通っているため色の抽出ができない
汎用的な手法だけでは解決できそうにないので、別の手段を考える必要があります。
1. 文字の特徴を考える
画像の文字を見ると、文字の周りが白く縁どられていることが分かります。そこで白縁をうまく抽出し、文字だけを抜き出してみます。白縁の抽出には findCountours を使います。

2. 文字を切り出す
文字全体が入るよう切り出します。数値の増減により位置が左右に振れることも考慮し、広めに切り出しています。
const x = Math.floor(src.cols * 0.33);
const y = Math.floor(src.rows * 0.77);
const w = src.cols - x;
const h = src.rows - y;
const roi = src.roi(new cv.Rect(x, y, w, h));

3. 二値化する
輪郭抽出の前準備として、二値化を行います。ここは通常通りの二値化です。縁はかなり白いので、thresholdの閾値も高めにします。ここで、切り出した画像が小さいので拡大します。グレースケール化後に拡大することでデータ量が抑えられます。
const gray = new cv.Mat();
cv.cvtColor(roi, gray, cv.COLOR_RGBA2GRAY);
const resizedGray = new cv.Mat();
cv.resize(gray, resizedGray, new cv.Size(gray.cols * 3, gray.rows * 3), 0, 0, cv.INTER_CUBIC);
const binary = new cv.Mat();
cv.threshold(resizedGray, binary, 220, 255, cv.THRESH_BINARY_INV);

4. 輪郭抽出する
findCountoursを使い、輪郭を抽出します。最も外枠の輪郭(RETR_EXTERNAL)を単純化(CHAIN_APPROX_SIMPLE)して取得する設定です。詳しくはContours in OpenCV.jsをご参照ください。
const contours = new cv.MatVector();
const hierarchy = new cv.Mat();
cv.findContours(binary, contours, hierarchy, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE);

赤線が抽出された輪郭です。よく見て頂くと、数字部分とイラストやノイズが別の輪郭となっていることが判ると思います。
5. 数字らしき輪郭をフィルタする
抽出した輪郭には文字以外にも背景イラストやノイズの輪郭が混ざっています。文字の輪郭条件を設けて、それ以外の輪郭を除外します。
for (let i = 0; i < contours.size(); i++) {
const cnt = contours.get(i);
// 輪郭を矩形にする
const rect = cv.boundingRect(cnt);
// 1. 輪郭が画像端でないこと
const isInner = 2 < rect.x && rect.x < (binary.cols - 2) && 2 < rect.y && rect.y < (binary.rows - 2);
// 2. 輪郭のアスペクト比が1:1以上であること
const isAspect = (rect.height / rect.width) >= 1.0;
// 3. 縦幅が画像の0.5~0.9
const isHeight = (binary.rows * 0.5) <= rect.height && rect.height <= (binary.rows * 0.9);
// 4. 矩形が画像の中央付近(Y座標のみ)
const centerY = rect.y + rect.height / 2;
const isCenterY = (binary.rows * 0.3) <= centerY && centerY <= (binary.rows * 0.7);
}

数字だけがうまく抜けています。
6. 数字輪郭のマスクを作成する
黒(0)背景に数字部分を白(255)で塗りつぶしたマスクを作成します。drawContoursを使って抽出した数字の輪郭の内側を塗りつぶします。
const mask = cv.Mat.zeros(binary.rows, binary.cols, cv.CV_8UC1);
for (let i = 0; i < contours.size(); i++) {
// 中略
if (isInner && isAspect && isHeight && isCenterY) {
cv.drawContours(mask, contours, i, new cv.Scalar(255), -1, cv.LINE_8, hierarchy, 0);
}
}

7. マスクとグレースケール画像を合成する
グレースケール画像とマスクを合成し、数字部分のみを抽出した画像を生成します。二値化画像を使用することも可能ですが、グレースケールのままの方が OCR の認識精度が向上する結果を得られました。
const dst = new cv.Mat(resizedGray.rows, resizedGray.cols, cv.CV_8UC1, new cv.Scalar(255));
resizedGray.copyTo(dst, mask);
認識結果:149
ここまでするとほぼ完ぺきな数字のみの画像を得られます。
上述したよう明らかに汎用性がなくなっているため、この手段が使えるのはこの種の画像だけです。
最後に
ブルーアーカイブの装備画像から所持数を抽出する際にかなり手こずりましたが、試行錯誤の末に納得のいく結果を得ることができました。AIサービス全盛のご時世ですが、無料で使用可能なライブラリは依然として強力な選択肢だと思います。