0. はじめに
過去記事①(Gemma 4 vs Qwen 3.5 on DGX Spark) と過去記事② (同 EVO-X2 編) では、いずれも llama.cpp を中心にベンチを取ってきました。Gemma 4 が 2026-04-02 にリリースされ、同日に NVIDIA から nvidia/Gemma-4-31B-IT-NVFP4 が公開されました。build.nvidia.com/spark/vllm には DGX Spark 専用の vLLM 手順まで用意されており、いわゆる Day-1 サポートとしては理想的な状況でした。
以前 vLLM を試したときは「NVFP4 を読み込ませた瞬間に CUDA illegal instruction で落ちる」状態で、ARM64 + GB10 (SM 12.1) では公式に未サポート扱いだった経緯があり、「vLLMは不安定だからなぁ」と放置していました。
その後 4 月 10 日に NVIDIA が vllm/vllm-openai:gemma4-cu130 という Gemma 4 専用イメージを公式に push し、NVFP4 GEMM のパスや MoE のローダーが順次直っていきました。気にはなっていたものの、3週間ほど着手できずにいたのを、GW の連休で重い腰を上げて確認した、というのが今回の検証の発端です。
1. TL;DR
- DGX Spark + vLLM + Gemma 4 NVFP4 は、2026-05 時点で NVIDIA 公式コンテナ
vllm/vllm-openai:gemma4-cu130で動作する。 - 同じ Gemma 4 26B-A4B を vLLM (NVFP4) と llama.cpp (Q4_K_M) で測ると、c=1 では llama.cpp が速い (62 vs 49 tok/s) が、c=8 から vLLM が逆転して 3.35× 速い。並列処理を捌くなら vLLM、単発で速さを稼ぐなら llama.cpp、と明快に分かれた。
- Gemma 4 31B Dense (NVFP4) は本日のトップ精度 (JCQ 97.86%) だが、c=1 で 6.92 tok/s とメモリ帯域で頭打ちになり、対話用途では実用が厳しい。
-
VLM の構造化出力 (PPE detect) parse 成功率が 33.3% → 100% に改善。vLLM (NVFP4) +
--reasoning-parser gemma4の組み合わせで、構造化ワークロードが劇的に良くなった。 - 量・質・速度のバランスから、DGX Spark で現時点のベストなローカルLLMは Gemma 4 26B-A4B NVFP4 (vLLM) だと思います。
2. 検証環境
2-1. ハードウェア / OS
| 項目 | 値 |
|---|---|
| 機種 | NVIDIA DGX Spark (spark-82c2) |
| GPU | GB10 (Grace Blackwell, SM 12.1) |
| 統合メモリ | 128 GB LPDDR5X |
| メモリ帯域 | 273 GB/s |
| OS | Ubuntu 系 (Linux 6.14) |
| CUDA | 13.0 |
| Driver | 580.x |
DGX Spark は CPU と GPU が同じ 128GB の物理メモリを共有する統合メモリ構成で、200B クラスまでのモデルが GPU メモリ上に載る一方、帯域は LPDDR5X の 273 GB/s が上限になります。Dense 大規模モデルはここで頭打ちになる、というのが今回の検証でも繰り返し確認されました (詳細は 8 章)。
2-2. vLLM コンテナ
# NVIDIA が DGX Spark + Gemma 4 用に提供しているイメージ
docker pull vllm/vllm-openai:gemma4-cu130
- vLLM バージョン: 0.19.1.dev6+g6d4a8e6d2 (cu130 nightly ベース)
- 内部の PyTorch は CUDA 13.0 ARM64 ビルド済み
- Gemma 4 のヘテロ次元アテンション (head_dim=256 / global_head_dim=512) のために TRITON_ATTN backend を強制
- NVFP4 GEMM は
FLASHINFER_CUTLASSパスが選ばれる (Avarok の検証で言及されていた性能パスがデフォルトで効いている)
公式手順は https://build.nvidia.com/spark/vllm/instructions にあり、HF モデルカードに書かれている --tensor-parallel-size 8 (NVIDIA の H100 8 GPU 想定) は DGX Spark では 使えない ことに注意します。-tp 1 (省略時のデフォルト) で起動します。
2-3. 検証したモデル
| モデル | 量子化 | サイズ | ライセンス |
|---|---|---|---|
nvidia/Gemma-4-31B-IT-NVFP4 |
NVFP4 (Dense) | 31 GB | Apache 2.0 (Gemma 4) + NVIDIA Open Model License |
bg-digitalservices/Gemma-4-26B-A4B-it-NVFP4 |
NVFP4 (MoE) | 16 GB | Apache 2.0 (Gemma 4 派生) |
ggml-org/gemma-4-26B-A4B-it-GGUF (Q4_K_M) |
Q4_K_M (MoE) | 16 GB | Apache 2.0 (llama.cpp 比較用) |
26B-A4B は MoE (128 experts、active 8) で、active パラメータが 4B 弱と非常に軽量。31B Dense は active = 30.7B のため、メモリ帯域に対して重く出ます。
3. 動作確認の落とし穴
「動くようになった」と書いたものの、26B-A4B (MoE) の方は素直には動きませんでした。Dense と MoE で扱いが分かれます。
3-1. 31B Dense NVFP4 — 素直に動く
docker run -d \
--runtime nvidia --gpus all --shm-size=16g \
-v ~/models/gemma4-31b-it-nvfp4:/models/gemma4-31b-it-nvfp4 \
--name vllm-gemma4-31b -p 8000:8000 \
vllm/vllm-openai:gemma4-cu130 \
--model /models/gemma4-31b-it-nvfp4 \ # モデルパス (コンテナ内)
--quantization modelopt \ # NVFP4 を modelopt で読む
--reasoning-parser gemma4 \ # Thinking 出力を reasoning フィールドに分離
--served-model-name gemma4-31b-nvfp4 \ # API で見えるモデル名
--max-model-len 8192 # KV キャッシュサイズの抑制 (デフォルトは 256K)
起動ログで Using NvFp4LinearBackend.FLASHINFER_CUTLASS for NVFP4 GEMM が出ていることを確認します。
3-2. 26B-A4B NVFP4 (MoE) — --moe-backend marlin と patched.py が必須
vLLM 公式の Gemma 4 MoE ローダーには現時点で互換性の問題があり (Issue #38912)、bg-digitalservices/Gemma-4-26B-A4B-it-NVFP4 には patched 版の gemma4_patched.py が同梱されています。これをコンテナ内の vllm/model_executor/models/gemma4.py に上書きマウントする必要があります。
docker run -d \
--runtime nvidia --gpus all --shm-size=16g \
-v ~/models/gemma4-26b-a4b-nvfp4:/models/gemma4-26b-a4b-nvfp4 \
-v ~/models/gemma4-26b-a4b-nvfp4/gemma4_patched.py:/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/gemma4.py \ # ← MoE ローダーの差し替え
--name vllm-gemma4-26b -p 8000:8000 \
vllm/vllm-openai:gemma4-cu130 \
--model /models/gemma4-26b-a4b-nvfp4 \
--quantization modelopt \
--kv-cache-dtype fp8 \ # 帯域節約 (KV を FP8 で持つ)
--moe-backend marlin \ # SM 12.1 にネイティブ FP4 compute がないので Marlin で W4A16 fallback
--reasoning-parser gemma4 \
--served-model-name gemma4-26b-nvfp4 \
--max-model-len 8192
起動ログで以下が出ていることを確認します。
Using 'MARLIN' NvFp4 MoE backend
Using NvFp4LinearBackend.FLASHINFER_CUTLASS for NVFP4 GEMM
MARLIN でなく CUTLASS_FP4 が選ばれてしまうと、出力が NaN になり日本語が文字化けして返ります。日本語の試し問い合わせ (「日本の首都はどこですか」など) で 1 度確認しておくと安心です。
3-3. Thinking ON は --reasoning-parser gemma4
Gemma 4 の Thinking モードは、reasoning-parser を付けないと content 内に思考の生テキスト ("thought\n* Question: ..." のような) が混ざって返ってきます。後段の数字抽出など簡単なパーサで処理する場合、思考ブロックの中の数字を拾ってしまうため精度が出ません。
--reasoning-parser gemma4 を付けて、リクエスト側で chat_template_kwargs: {"enable_thinking": true} を渡すと、message.reasoning (vLLM 流儀) に思考が分離されます。llama-server 流儀の reasoning_content ではないので、既存スクリプトを使う場合は両対応にしておくのが楽です。
4. 計測方法 — 方式4 (vllm bench serve 統一)
4-1. なぜ benchmark_serving.py か
llama.cpp の llama-bench と vLLM の vllm bench serve は、見た目近そうに見えて実は測っているものが違います。
| ツール | 測定対象 | 想定シナリオ |
|---|---|---|
llama-bench |
pp / tg、単一スレッド・合成プロンプト | 純粋な計算速度の上限 |
vllm bench serve |
TTFT, TPOT, ITL, req/s、並列リクエスト・実データセット | 実運用のスループット |
vLLM は continuous batching + PagedAttention で複数リクエスト同時処理が真骨頂で、llama-bench 側の指標 (pp/tg 単発) では vLLM の強みが見えません。逆に llama-bench を vLLM 側で再現することも難しいです。
そこで本記事では、両サーバを同じ vllm bench serve で叩く方式を採りました。vllm bench serve (= benchmark_serving.py、サブコマンド名は serve、vLLM 0.19 系) は OpenAI 互換 API を想定したクライアントツールで、--backend openai-chat で /v1/chat/completions を叩きます。llama-server も同じエンドポイントを実装しているので、URL を差し替えるだけで同じ条件のベンチが取れます。
過去シリーズで使ってきた llama-bench は計算速度の上限を測る指標で、実運用の体感とは少しズレがあると感じていました。今後の速度ベンチは vllm bench serve に一本化しようと思っています。
4-2. llama.cpp 側を vLLM コンテナで叩く
llama.cpp 側の計測のためだけにホストに vLLM を pip install するのも煩雑なので、vLLM コンテナを クライアント専用 で動かしました。
docker run --rm -it \
--network host \ # ホストの localhost:8080 (llama-server) にアクセス
-v ~/datasets:/datasets \
-v ~/bench-results:/bench-results \
-v ~/models/gemma4-26b-a4b-nvfp4:/tokenizer \ # tokenizer は同モデルの NVFP4 ディレクトリを流用
--entrypoint vllm \ # デフォルトの `vllm serve` を上書きして bench を起動
vllm/vllm-openai:gemma4-cu130 \
bench serve \
--backend openai-chat \
--base-url http://localhost:8080 \
--endpoint /v1/chat/completions \
--model gemma-4-26B-A4B-it-Q4_K_M.gguf \
--tokenizer /tokenizer \
--dataset-name sharegpt \
--dataset-path /datasets/sharegpt/ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 200 \
--max-concurrency 1 \
--save-result \
--result-dir /bench-results/llamacpp \
--result-filename gemma4-26b-q4km-c1.json
これで vLLM 側 (port 8000) と llama.cpp 側 (port 8080) を同じツール・同じデータセット・同じプロンプト数で叩けます。
4-3. データセットとパラメータ
vllm bench serve は実プロンプトをサーバに投げてレスポンス時間を測るため、計測には実際の会話プロンプトのデータセットが必要になります。llama-bench のように合成プロンプト (連続トークン) で済まないのはこのためです。データセットの選び方で測定値が変わるので、過去多くのベンチマークで使われている ShareGPT をそのまま採用しました。
ShareGPT_V3_unfiltered_cleaned_split.json は、ShareGPT で公開された ChatGPT との会話データを集めて、英語以外の混入や HTML タグ等を取り除いて整形したもので、約 90,000 会話 / 642 MB の規模があります。Vicuna の学習データとして整理されたもので、vLLM 公式の benchmark_serving.py が デフォルトで参照するデータセット でもあります。vllm bench serve --dataset-name sharegpt --dataset-path <ファイル> の形で指定すると、内部でランダムサンプリング (シードあり) してプロンプト列を組み立てます。今回はこのうち先頭から --num-prompts 200 で 200 件を取り出して使いました。
| 項目 | 値 |
|---|---|
| データセット | ShareGPT_V3_unfiltered_cleaned_split.json (642 MB) |
| サンプル数 | 200 prompts/run (--num-prompts 200) |
| concurrency スイープ | 1, 2, 4, 8, 16, 32 (--max-concurrency) |
| 長さ分布 | input 平均 ~230 tok、output 平均 ~230 tok (ShareGPT 自然分布) |
各パラメータについて補足します。
-
--num-prompts 200— 投げるプロンプトの本数。少なすぎると統計的に不安定になり、多すぎると測定時間が伸びます。c=1 のような単発実行では 200 件で 15 分から 1 時間半ほどかかりますが、200 件あれば TPOT の P99/Mean が 1.02 程度に収束し、再現性のある数字が取れます。経験的に 200 が落としどころだと感じています。 -
--max-concurrency N— 同時にサーバに投げるリクエストの上限本数。c=1 は 1 件投げて応答を待ってから次を投げる単発実行、c=32 は最大 32 件を並列で抱えながら処理する形になります。vLLM の continuous batching の効きを見るには、c=1 から c=32 まで段階的に振るのが定番です。 -
長さ分布 — ShareGPT の自然分布で、入力・出力ともに 100〜500 tok 程度に集中する形になります。極端な長文 (4K+) は少なめなので、長文 RAG や巨大ログ解析の用途を測るには別のデータセット (例: ランダムサンプリング系の
randomデータセット指定) が向いていると思います。
5. スループット計測
ここからは vllm bench serve の実測値を見ていきます。「ある concurrency でどれだけのトークン処理能力が出るか」を測っているもので、Output token throughput (tok/s) が並列処理時の総合スループット、TPOT (ms) が「1 ユーザーあたりの体感速度」と読み替えられます。
5-1. Gemma 4 26B-A4B NVFP4 (vLLM) — c=1 から c=32 までフルスイープ

図1: Gemma 4 26B-A4B / 31B Dense (vLLM, NVFP4) と 26B-A4B (llama.cpp, Q4_K_M) のスループット。横軸は log2 スケール。
| concurrency | Output tok/s | Peak tok/s | TPOT (ms) | TTFT Mean (ms) | duration |
|---|---|---|---|---|---|
| c=1 | 48.88 | 52 | 20.08 | 96 | 15:45 |
| c=2 | 87.44 | 94 | 22.29 | 109 | 8:51 |
| c=4 | 136.05 | 152 | 28.35 | 100 | 5:40 |
| c=8 | 207.48 | 248 | 35.94 | 252 | 3:41 |
| c=16 | 302.85 | 368 | 53.96 | 152 | 2:32 |
| c=32 | 441.14 | 574 | 61.74 | 192 | 1:44 |
- 26B-A4B NVFP4 は c=1 → c=32 でアグリゲートが 9.0× にスケールしています。完璧な continuous batching の効き方で、vLLM の真骨頂と言える数字です。
- TPOT は 20ms → 62ms に伸びていますが、c=32 でも 16 tok/s/req に相当するため、対話 UI として十分実用域です。
- c=1 の 48.88 tok/s は、ai-muninn のコミュニティ報告 (52 tok/s) と一致しており、現状の DGX Spark + 26B-A4B NVFP4 の素の数字としては再現性が取れていると思います。
5-2. Gemma 4 31B Dense NVFP4 (vLLM) — c=1 / c=8 / c=32
| concurrency | Output tok/s | Peak tok/s | TPOT (ms) | TTFT Mean (ms) | duration |
|---|---|---|---|---|---|
| c=1 | 6.92 | 8 | 144.00 | 219 | 1:49:34 |
| c=8 | 48.25 | 57 | 151.76 | 690 | 15:44 |
| c=32 | 143.01 | 194 | 174.73 | 658 | 5:19 |
- 31B Dense は c=1 で 6.92 tok/s という、対話用途では実用が厳しい数字です。これは GB10 上の Dense 31B としては理論計算とよく合う数字 (詳細は 8 章)。
- TPOT が 144ms → 175ms とほとんど変わらないのが特徴的です。これは 1 トークン生成のたびに 31B の重みをほぼ全部 GPU メモリから読み出す必要があり、その時間がメモリ帯域でほぼ決まってしまうためです。
- アグリゲートは c=1 → c=32 で 20.66× スケールしており、batching は確かに効いていますが、TPOT が動かないので「速くなった気がしない」体感になります。バッチ処理でしかメリットが出ません。
5-3. Gemma 4 26B-A4B Q4_K_M (llama.cpp b8672) — c=1 / c=8 / c=32
| concurrency | Output tok/s | Peak tok/s | TPOT (ms) | TTFT Mean (ms) | duration |
|---|---|---|---|---|---|
| c=1 | 61.98 | 69 | 15.44 | 202 | 12:21 |
| c=8 | 61.95 | 105 | 124.80 | 609 | 12:21 |
| c=32 | 154.43 | 299 | 170.18 | 1490 | 4:55 (1 件 failed) |
llama.cpp は --parallel 32 -c 262144 -ngl 99 -fa on で起動しています。
-
c=1 と c=8 で Output throughput がほぼ同じ (61.98 ≒ 61.95) という不思議な挙動が出ました。llama.cpp の
--parallel Nは計算リソースを N 個に分割して使う仕組みで、vLLM のような continuous batching ではありません。TPOT が 8 倍に伸びる代わりに同時に 8 ユーザー処理する、という動きをします。アグリゲート総和は据え置き。 - c=32 で 154 tok/s に伸びるのは、KV cache が分割されて並列度を上げた効果です。それでも vLLM 26B-A4B c=32 (441 tok/s) の 35% 相当でしかありません。
5-4. 同モデル・別ランタイムで何が変わるか
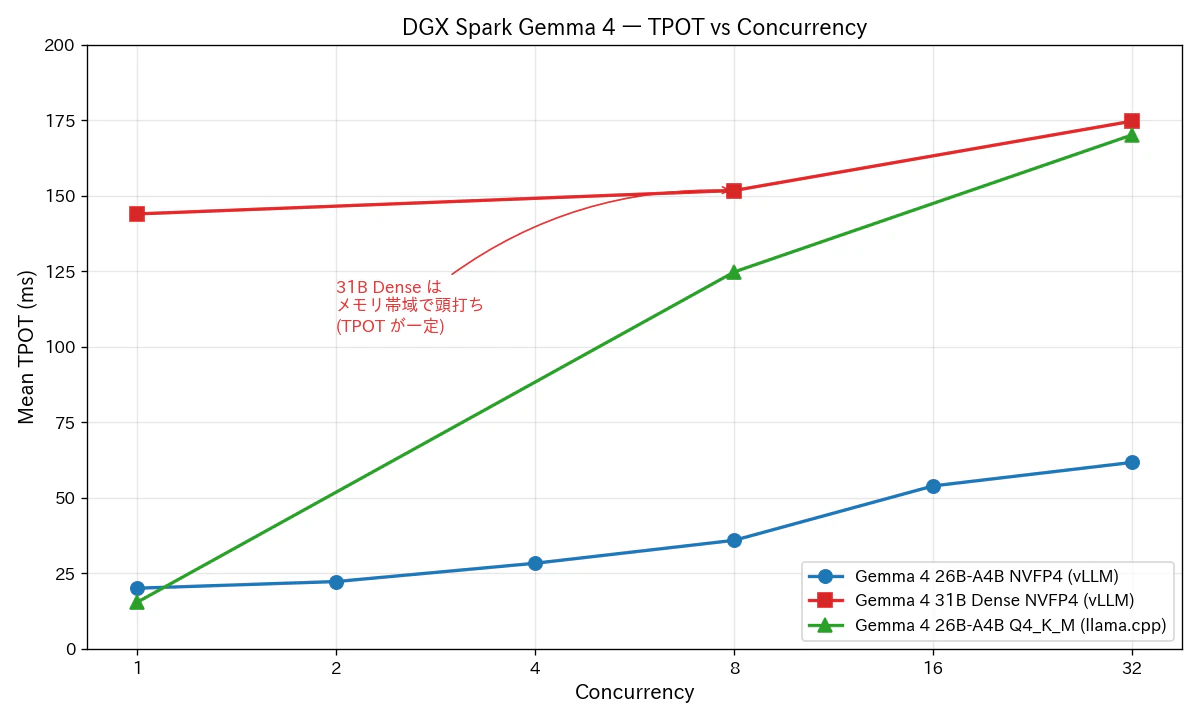
図2: TPOT (Mean Time Per Output Token) の concurrency スイープ。1 ユーザーあたりの体感速度。
| concurrency | vLLM NVFP4 | llama.cpp Q4_K_M | 勝者 | 倍率 |
|---|---|---|---|---|
| c=1 | 48.88 tok/s | 61.98 tok/s | llama.cpp | 1.27× |
| c=8 | 207.48 tok/s | 61.95 tok/s | vLLM | 3.35× |
| c=32 | 441.14 tok/s | 154.43 tok/s | vLLM | 2.86× |
- c=1 では llama.cpp の方が速い: 単発 decode の効率は llama.cpp の軽量実装が勝ります。TPOT 15.4 ms vs 20.1 ms。これは予想通りで、llama.cpp の素のカーネル速度の強さが出る領域。
- c=8 から vLLM が逆転、3.35× の差: ここで vLLM の continuous batching と PagedAttention が活きます。llama.cpp 側はこの領域で足踏みします。
- TTFT (prefill) は終始 vLLM の方が速いです。FlashInfer + cuBLAS のプリフィル経路が貢献している印象です。
- TPOT 安定性 (P99/Mean) は vLLM が 1.02、llama.cpp が 1.10〜1.44。vLLM の方が「ばらつきが少ない」ので、SLA を引きたいワークロードでは vLLM が安全です。
実用観点でまとめると、ローカルで自分一人が使うなら llama.cpp、複数ユーザー / エージェント並列 / バッチ処理なら vLLM という棲み分けで、両者を排他で考える必要はないと思っています。
6. JCQ (JCommonsenseQA v1.1, 1,119 問, 3-shot)
JCQ は日本語の常識問題 1,119 問を 5 択で答える評価セットで、過去シリーズで継続的に追っている指標です。3-shot の few-shot を与えて、max_tokens=8 (Thinking OFF) または max_tokens=2048 (Thinking ON) で答えを出させます。
6-1. 26B-A4B NVFP4 — Thinking OFF / ON
| Thinking | Accuracy | Avg latency | 所要時間 |
|---|---|---|---|
| OFF | 96.34% (1078/1119) | 0.087 s/問 | 1m38s |
| ON | 93.48% (1046/1119) | 6.55 s/問 | 2h2m |
- NVFP4 量子化による品質劣化は -0.17pt (vs F16 96.51%)、ほぼ誤差レベル。NVFP4 は十分使える量子化、と思っています。
- Thinking ON で
<unused49>の大量出力バグは出ませんでした (F16 GGUF + llama.cpp で出ていた現象)。NVFP4 + vLLM の組み合わせでは正常に reasoning を生成して終了します。 - ただし精度は -2.86pt 劣化。Qwen 3.5 (-6.88pt) よりはマシですが、Qwen 3.6 (+0.45pt) のような Thinking 改善型ではない、と読めます。Gemma 4 系の Thinking 学習はまだ余地がありそうに見えます。
6-2. 31B Dense NVFP4 — Thinking OFF / ON サンプル
| Thinking | Accuracy | Avg latency | 所要時間 |
|---|---|---|---|
| OFF | 97.86% (1095/1119) | 0.455 s/問 | 8m30s |
| ON (10 問サンプル) | 100% (10/10) | 37.29 s/問 | 6m12s |
- OFF で 97.86%。これは過去に測った中で Nemotron 3 Super 120B Q4_K と同点 (どちらも 97.86%) で、本日のトップ精度タイです。30B 級のモデルが 120B 級と同じ品質を出しているのは、Dense モデルの密度効果と Gemma 4 の素の言語性能の良さが効いている、と理解しています。
- ON は 1 問あたり 37.29 秒もかかり、1119 問換算 11.6 時間。実用は厳しいので 10 問サンプルだけ取りました。10 問では全問正解で、参考値として「31B Dense の Thinking には品質劣化はない (むしろ改善している可能性)」と言えそうですが、サンプル 10 問では断定はできません。
6-3. 過去測定との並列比較
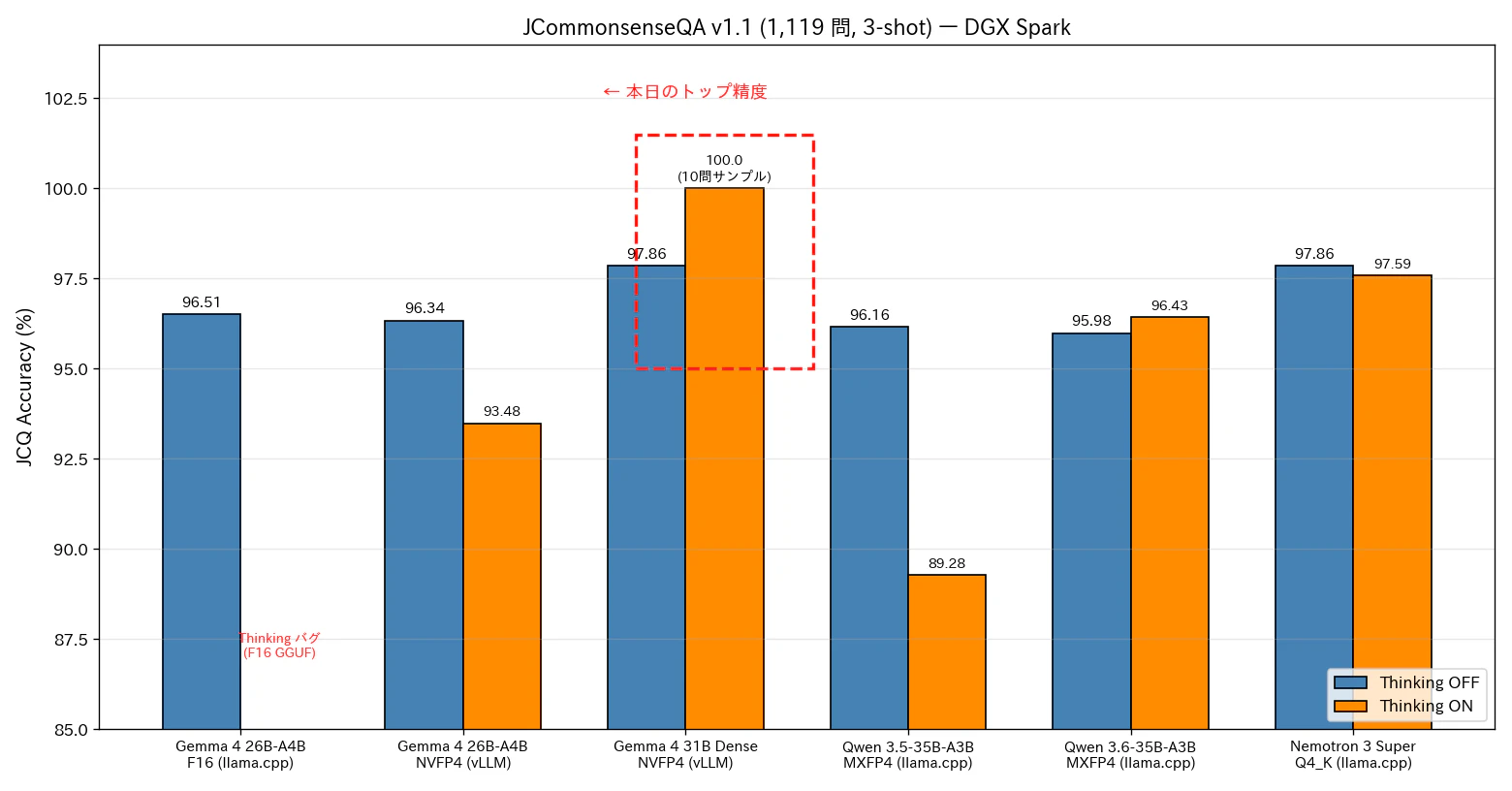
図3: JCQ Accuracy 比較。本日測定の Gemma 4 系 (NVFP4 + vLLM) と、過去測定 (llama.cpp) の Qwen / Nemotron / Gemma 4 F16 を並べたもの。
| モデル | 量子化 | ランタイム | OFF | ON |
|---|---|---|---|---|
| Gemma 4 26B-A4B | F16 | llama.cpp | 96.51% | バグ (<unused49>) |
| Gemma 4 26B-A4B | NVFP4 | vLLM | 96.34% | 93.48% |
| Gemma 4 31B Dense | NVFP4 | vLLM | 97.86% | (10 問 100%) |
| Qwen 3.5-35B-A3B | MXFP4 | llama.cpp | 96.16% | 89.28% |
| Qwen 3.6-35B-A3B | MXFP4 | llama.cpp | 95.98% | 96.43% |
| Nemotron 3 Super 120B | Q4_K | llama.cpp | 97.86% | 97.59% |
- Gemma 4 31B Dense (NVFP4) が 30B 級のトップ精度。サイズ・速度・品質のトレードオフで、品質を最優先するなら 31B Dense + NVFP4 という選択肢が現実的になりました (速度を許容できれば、ですが)。
- 26B-A4B NVFP4 (vLLM) は OFF 96.34%、量子化での品質劣化が極めて小さいことを再確認しました。
- Thinking ON で精度が伸びるのは Qwen 3.6 と Nemotron 3 Super のみ。Gemma 4 と Qwen 3.5 は ON で劣化する側です。Thinking 学習の質はモデルファミリ間でかなり差がある、というのが今回も見えました。
7. VLM (Caption + JSON extract + PPE detect)
VLM (Vision Language Model) のベンチは過去シリーズと同じ vlm_bench.py を流用して、3 タスクを測ります。
- Caption: 画像 5 枚 (展示会・イベント写真) に対して詳細な日本語キャプションを生成
- JSON extract: 画像 5 枚から
{location, event_type, subjects, technologies, ...}の構造化 JSON を抽出 - PPE detect: 画像 3 枚 (作業員) から
{workers_count, ppe_items: [...]}の構造化 JSON を抽出
「parse rate」は、生成された JSON が json.loads で問題なくパースできた割合です。100% が望ましく、これが低いと後段で扱いにくい応答が混じることになります。
7-1. 31B Dense NVFP4
| タスク | 平均時間 | parse rate |
|---|---|---|
| Caption (5 枚) | 72.27 s/枚 | - |
| JSON extract (5 枚) | 20.25 s/枚 | 100.0% |
| PPE detect (3 枚) | 34.29 s/枚 | 100.0% |
- 31B Dense NVFP4 (vLLM) は JSON / PPE ともに 100% parse。Caption は 72 秒/枚と決して速くありませんが、構造化出力の信頼性は最高クラス。
7-2. 26B-A4B NVFP4
| タスク | 平均時間 | parse rate |
|---|---|---|
| Caption (5 枚) | 10.74 s/枚 | - |
| JSON extract (5 枚) | 2.76 s/枚 | 100.0% |
| PPE detect (3 枚) | 5.03 s/枚 | 100.0% |
- 26B-A4B NVFP4 は Caption 10.74 秒/枚と圧倒的に速く、構造化出力 (JSON / PPE) もどちらも 100%。
- JSON extract が 2.76 秒は短い JSON 出力で TTFT がそのまま全体時間にきいている領域。vLLM の prefill 速度 (FlashInfer / cuBLAS) が活きています。
7-3. 過去 (llama.cpp) との比較で見える改善
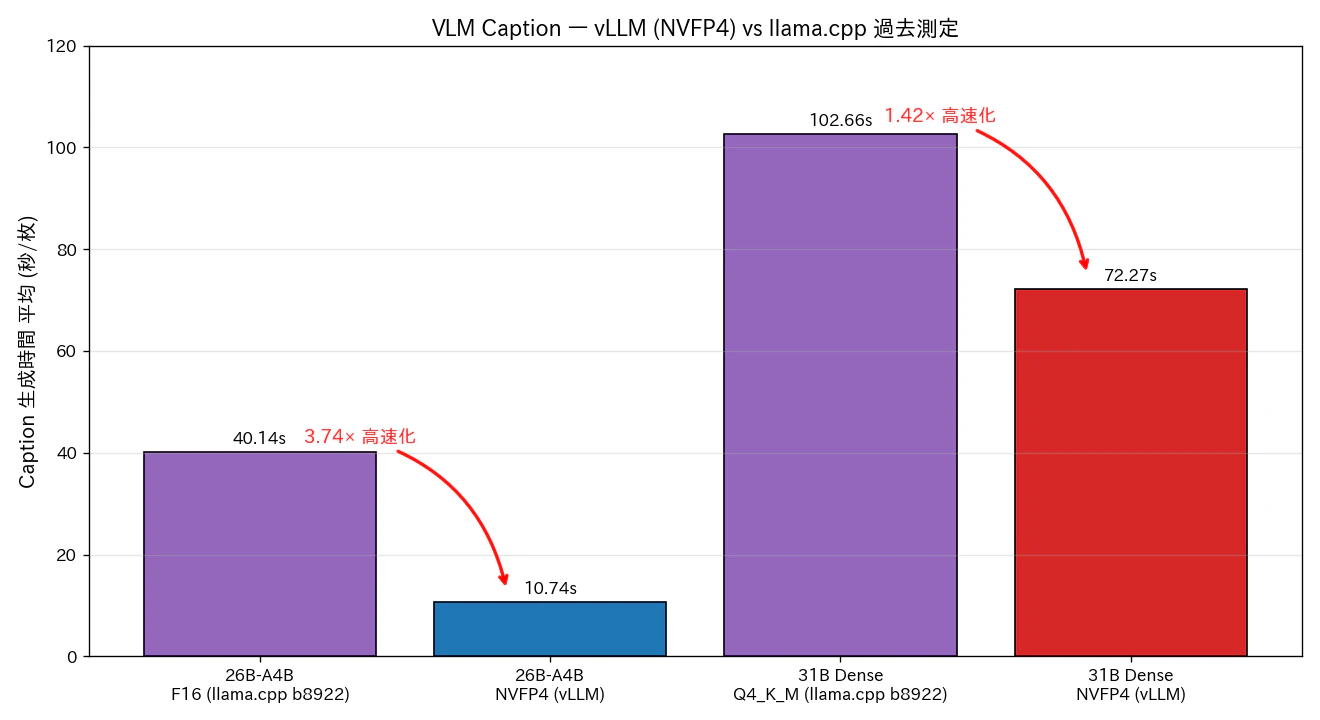
図4: VLM Caption 生成時間。同じモデル系列でも、ランタイムと量子化を vLLM + NVFP4 にすると Caption が顕著に速くなる。
| 環境 / モデル / 量子化 | Caption (s) | JSON parse | PPE parse |
|---|---|---|---|
| DGX Spark / 26B-A4B / F16 (llama.cpp b8922) | 40.14 | 40.0% | 33.3% |
| DGX Spark / 26B-A4B / NVFP4 (vLLM) | 10.74 | 100% | 100% |
| 速度比 | 3.74× 速い | 同 | 3× 改善 |
| DGX Spark / 31B Dense / Q4_K_M (llama.cpp b8922) | 102.66 | 100% | 33.3% |
| DGX Spark / 31B Dense / NVFP4 (vLLM) | 72.27 | 100% | 100% |
| 速度比 | 1.42× 速い | 同 | 3× 改善 |
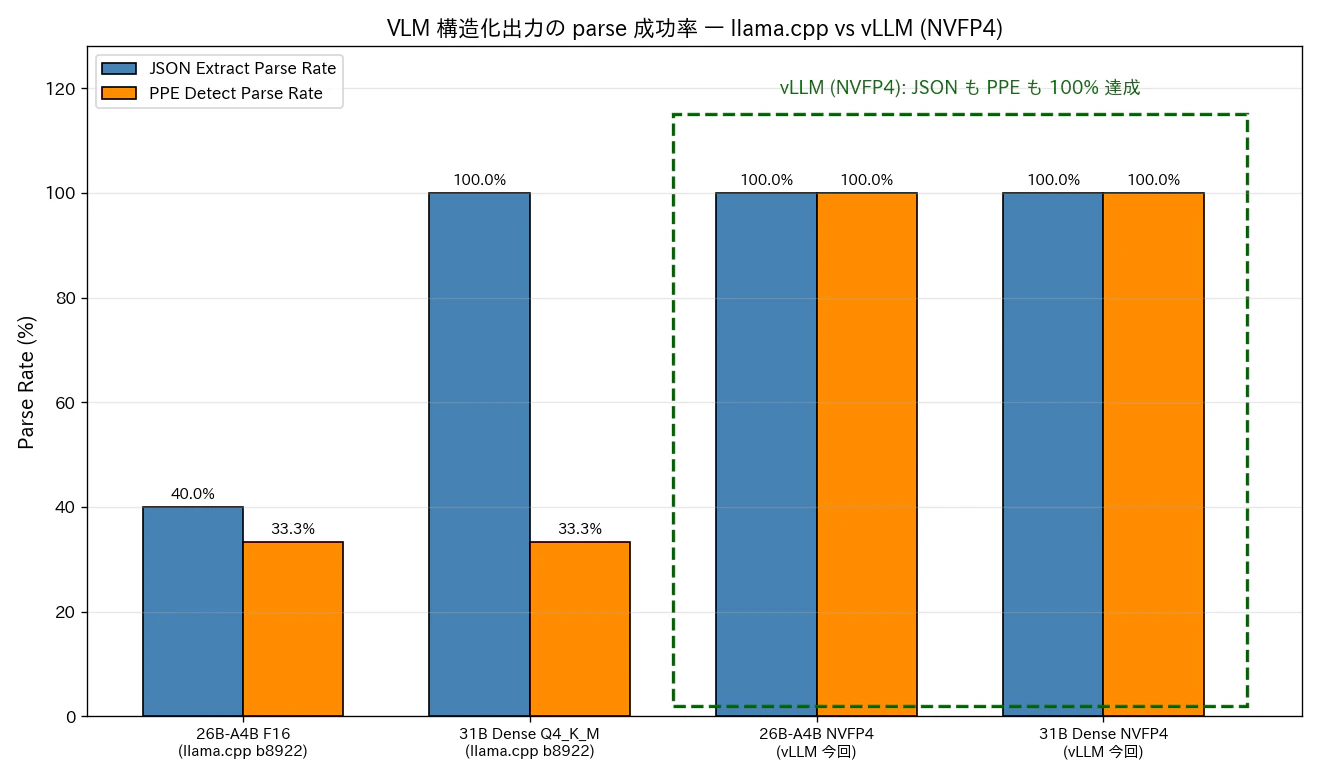
図5: VLM 構造化出力の parse 成功率。過去 llama.cpp 環境で最大の弱点だった PPE detect が、vLLM (NVFP4) で 100% に到達。
- MoE で 3.74× 高速化: vLLM の MoE expert routing 最適化と、Caption (1024 token 上限) のような長尺 decode で continuous batching の効果が積み重なっている、と理解しています。
- Dense でも 1.42× 高速化: TTFT (vLLM 速い) と decode 効率の合算。
-
PPE parse が 33.3% → 100%: 過去シリーズで一番の弱点だった項目です。vLLM +
--reasoning-parser gemma4+ NVFP4 の組み合わせで、構造化出力の安定性が劇的に改善しました。要因の切り分けは別記事のテーマになりそうですが、運用面では「vLLM (NVFP4) の方が JSON が安定する」と覚えておけば実用上は十分だと思います。 - 構造化出力ワークロード (RAG・エージェント・JSON 抽出) では、vLLM (NVFP4) を選ぶ動機がここに集約されると思っています。
8. Active Parameter 数とトークン生成速度 (理論 vs 実測)
DGX Spark の GB10 はメモリ帯域が 273 GB/s で、ここが Dense モデルの c=1 トークン生成速度を決定的に支配します。NVFP4 で重みが 1 パラメータあたり 0.5 byte と仮定すると、
理論上限 (tok/s) = メモリ帯域 / (active params × 0.5 byte)
31B Dense (active 30.7B): 273 GB/s ÷ (30.7B × 0.5) = 17.6 tok/s
26B-A4B (active 4B ): 273 GB/s ÷ (4B × 0.5) = 136.6 tok/s
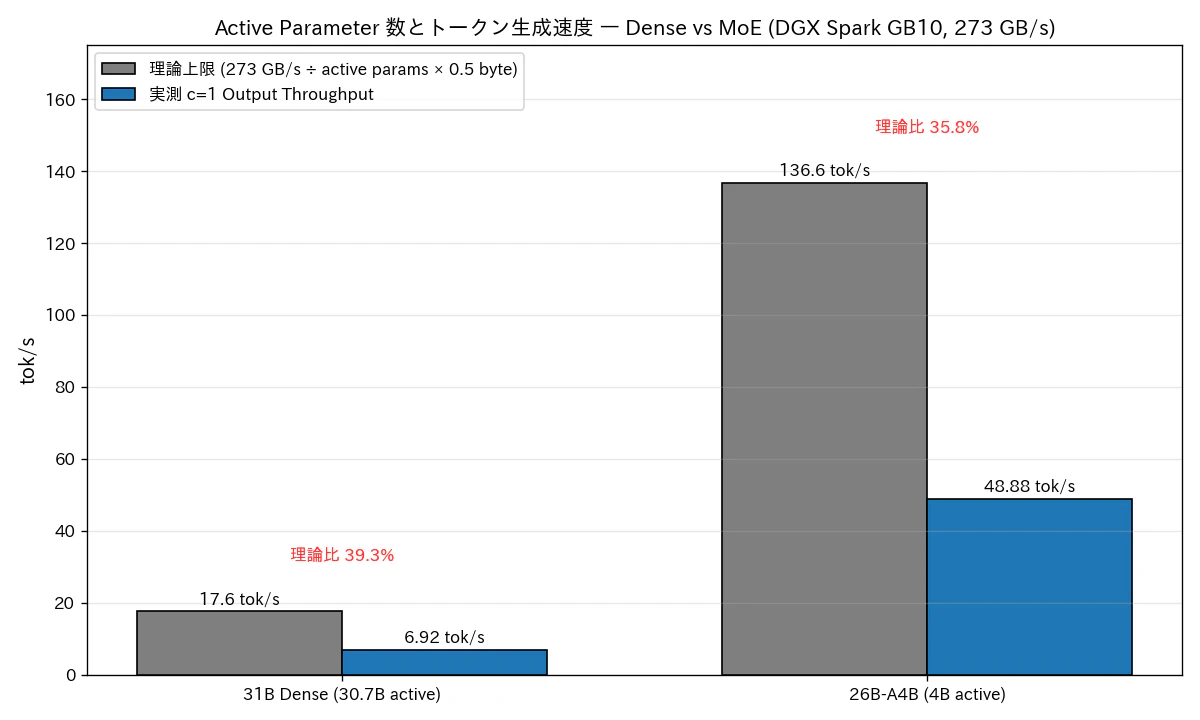
図6: 理論上限 (グレー) と実測 c=1 Output Throughput (青) の比較。Dense は理論の 39.3%、MoE は 35.8% を達成。
| モデル | 理論上限 | 実測 c=1 | 達成率 |
|---|---|---|---|
| 31B Dense (30.7B active) | 17.6 tok/s | 6.92 tok/s | 39.3% |
| 26B-A4B (4B active) | 136.6 tok/s | 48.88 tok/s | 35.8% |
- 達成率はどちらも 35-39%。残り 60% は attention 計算 / activation memory / KV cache I/O / kernel launch overhead 等のオーバーヘッドだと思っています。これは別途プロファイリングして詰めるテーマで、今回は理論との相対関係だけ見ておきます。
- 重要なのは 絶対値の差ではなく比率で、active パラメータ数の比 30.7B / 4B = 7.68× が、実測比 48.88 / 6.92 = 7.07× とほぼ一致します。Dense vs MoE のトークン生成速度はほぼ完全に active パラメータ数で決まる、という見立てです。
- これは DGX Spark に固有の話ではなく、EVO-X2(AMD Ryzen AI Max+ 395) のような帯域 256 GB/s 級の統合メモリ機にも共通する制約です。「128GB メモリがあるから 31B Dense も載る」という事実とは別に、「実用速度で動かせるかは active 数次第」という補助線が必要、というのが今回の検証で再確認できたポイントだと思っています。
9. DGX Spark でどのモデルを選ぶか
日常の対話・コード補助
-
Gemma 4 26B-A4B NVFP4 (vLLM) — 一人使いなら llama.cpp Q4_K_M でも可
- vLLM c=1 で 48.88 tok/s、TPOT 20ms
- llama.cpp c=1 で 61.98 tok/s、TPOT 15ms
- 単発体感はやや llama.cpp、JSON 系の安定性は vLLM、と使い分け
- BF16 / F16 を選ぶ理由は今回の結果では見つかりませんでした。NVFP4 量子化での精度劣化は -0.17pt 程度で、ほぼ誤差です。
並列処理 / エージェント / バッチ
-
Gemma 4 26B-A4B NVFP4 (vLLM) 一択
- c=8 で 207 tok/s、c=32 で 441 tok/s
- 同モデルの llama.cpp は c=32 で 154 tok/s (vLLM の 35% 相当)
構造化出力 (RAG / JSON 抽出 / エージェント)
-
Gemma 4 26B-A4B NVFP4 (vLLM) が速度・品質ともにベスト
- JSON / PPE ともに parse rate 100%、Caption 10.74 秒/枚
- 31B Dense NVFP4 は parse 信頼性は同等で、より重い長文を扱うなら検討
最高品質 (バッチ処理 / 評価タスク / 合成データ生成)
- Gemma 4 31B Dense NVFP4 (vLLM) — JCQ 97.86% (30B 級トップ、Nemotron 3 Super 120B と同点)
- 速度は c=1 で 6.92 tok/s と遅いので、バッチでまとめて流す前提
- Nemotron 3 Super 120B (66 GB) を載せられない / 載せたくない場合の上位代替
10. 参考リンク
- build.nvidia.com/spark/vllm — NVIDIA 公式の DGX Spark + vLLM 手順
- nvidia/Gemma-4-31B-IT-NVFP4 (HF)
- bg-digitalservices/Gemma-4-26B-A4B-it-NVFP4 (HF)
- vLLM Issue #38912 (Gemma 4 MoE loader)
- ai-muninn: Gemma 4 26B NVFP4 52 toks — DGX Spark + 26B-A4B NVFP4 の独立検証
- 過去記事①: Gemma 4 vs Qwen 3.5 on DGX Spark (qiita.com/nabe2030/items/fc3db819470edcca5aee)
- 過去記事②: Gemma 4 vs Qwen 3.5 on EVO-X2 (qiita.com/nabe2030/items/519345bfedf9231eda57)
- 過去記事③: Qwen 3.6 vs 3.5 (DGX Spark) (qiita.com/nabe2030/items/f61bc3627bb92a0388e5)
- GitHub: nabe2030/gemma4-vs-qwen35-dgx-spark — 本記事の数値を追記予定