「Vulkan と HIP、どちらがいいのか?」 と、EVO-X2 (AMD Ryzen AI Max+ 395) のユーザー間で話題になったことがありますが、私の環境では、そもそも HIP が上手くビルド出来ず、長らく Vulkan 一本でした。Ubuntu 26.04 を導入して ROCm 7.2.2 環境になったことでやっと HIP が使えるようになった、というところからのスタートです。
その上で話題のローカルLLM 6 モデル × 2 バックエンドを比較した結果が本記事です。先に答えを言うと、ワークロードのプロンプト長と生成長で支配項が入れ替わるため、「どちらがいい」ではなく 「両方ビルドして使い分ける」が正解 という結論になりました。
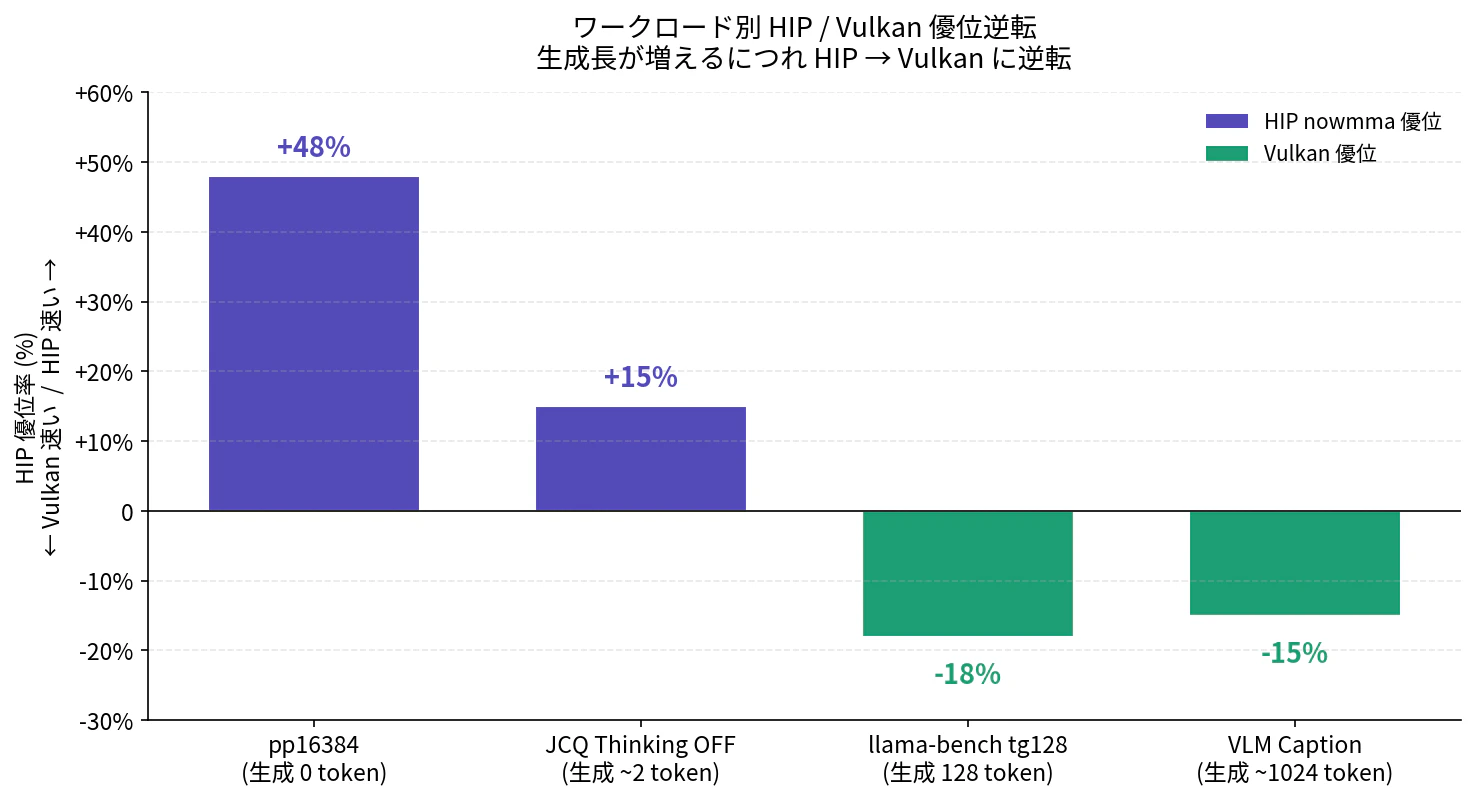
生成長 0 (pp16384) では HIP が +48% で大差勝ち、生成 ~2 token (JCQ) でも HIP が +15% でなお優位。ところが生成 128 token (tg128) で Vulkan に逆転 (-18%)、生成 ~1024 token (VLM Caption) でも Vulkan が +15% — 生成長が増えるにつれて HIP の優位が崩れて Vulkan が支配する、という綺麗な階段ができました。
過去記事 gemma4-vs-qwen35-evo-x2 の時点では、EVO-X2 (Ubuntu 25.10) で HIP バックエンドがビルドできず Vulkan 一択でした。理由は ROCm 7.x のシステムインストールがなく、TheRock の pip wheel には hipcc も hip-lang-config.cmake も含まれていなかったからです。
その後、Ubuntu 26.04 LTS が 2026 年 4 月にリリース、AMD 公式の noble リポジトリ (注: 26.04 ネイティブパッケージはまだ無く、24.04 noble をそのまま使う) から ROCm 7.2.2 を apt で導入できるようになりました。これで enable_language(HIP) が通る環境になり、HIP バックエンドが組めます。
「では HIP に乗り換えるのが正解か?」を確かめるため、6 モデル × 2 バックエンドで再検証しました。
llama.cpp とは — 改めて整理
llama.cpp は、Meta が公開した LLaMA を C/C++ で軽量に動かすために
ggerganov 氏が始めた OSS の推論エンジンです。元々は CPU だけで動かすことを目指したプロジェクトでしたが、現在は
- GGUF: モデルの重みを 1 つのファイルにまとめた量子化フォーマット (Q4_K_M、Q6_K、Q8_0、MXFP4 など多様な量子化レベルに対応)
- 多バックエンド対応: CPU、CUDA (NVIDIA)、HIP/ROCm (AMD)、Metal (Apple)、Vulkan、SYCL (Intel) など、ほぼすべての主要 GPU で動く
-
OpenAI 互換 API サーバー (
llama-server): ChatGPT 用の API スキーマで
ローカルモデルにアクセスできる -
マルチモーダル対応:
--mmprojでビジョンエンコーダを差し込むことで
Qwen3-VL、Gemma 3/4、LLaVA 系の VLM が動く
までカバーするローカル LLM 推論基盤の事実上の標準になっています。Ollama、LM Studio、Open WebUI など多くのツールが内部で llama.cpp を呼んでおり、
本記事のように直接ビルドして使うのは「最新機能をいち早く試したい」「量子化やバックエンドの細かい挙動を制御したい」用途が中心です。
モデル種別と推論の特性
本記事で扱うモデルの「種別」を整理しておきます:
-
Dense モデル: 全パラメータが各 token の処理で使われる古典的な構造
(例: LLaMA 3、Gemma 4 31B、Qwen 3.5-27B Dense) -
MoE (Mixture of Experts): 複数の専門家ネットワークから一部だけを動的に
選択して使う構造。「総 params は大きいが、各 token で実際に動く params (active params)は少ない」のが特徴。例: Qwen 3.5-35B-A3B = 総 35B / 活性 3B、Gemma 4 26B-A4B = 総 26B / 活性 4B -
GDN (Gated Delta Net): Qwen 3.5/3.6 系で導入された linear-attention の一種。
一部のレイヤーで通常の attention の代わりに使われ、long-context での計算量を抑える。Qwen 3.5 系は GDN:Attn = 1:9、Qwen 3.6 系は 3:1 と比率が変わっている
これらの構造の違いがバックエンドの得意/不得意に効いてくるのが、本記事の比較で見えた構図です。
最近の llama.cpp ビルド事情 (2026 年 4 月末時点)
llama.cpp は 1 日に数〜数十 commit が入る勢いで開発されていて、ビルド周りも
頻繁に変わります。本検証時点 (b8966、2026 年 4 月末) で押さえておくと役立つポイントを書いておきます。
-
タグは数日単位で進む:
b8966は 2026 年 4 月末の master 先端付近のタグ。
Vulkan / HIP のシェーダーやカーネルは継続的に最適化されており、たとえば
Qwen 3.5-27B Dense (Dense + GDN) は b8576 では Vulkan で 1.72 t/s と壊滅的でしたが、本検証 (b8966) では 12.7 t/s まで回復しています。ベンチ結果はビルドタグとセットで読むのが安全 です -
GGUF v3 の multi-shard 対応: 大きいモデル (例: 122B-A10B Q4_K_M = 71 GiB) は複数ファイルに分割して配布されます。
-of-00003.gguf等を llama.cpp が自動認識するので、-mには 1 番目のファイルを指定するだけで動きます -
-fa引数の仕様変更: 以前は-faは単独フラグでしたが、b8966 時点では-fa on|off|autoのように値を取る形式に変わっています。古い記事のコマンドを
そのままコピペすると引数解釈エラーになることがあります -
-ub(ubatch_size): prompt processing 時に GPU に投げるバッチサイズ。
これを大きくすると pp 速度が上がりますが、大きすぎると逆に遅くなる場合や
特定の長さで非効率になる場合があります (本記事の付録 B 参照)。
Strix Halo では-ub 2048がだいたいスイートスポット -
-mmp 0(no-mmap): モデルファイルを mmap しない。VGM (BIOS で確保した
GPU 用メモリ) に明示的にロードしたい場合に重要。本検証では全ベンチで-mmp 0 -
マルチモーダルの分離: 旧来は
llava-cli等の専用バイナリでしたが、現在は
llama-server --mmproj <vision.gguf>で本体と同じサーバーで扱えます -
llama-benchのサブコマンド化: 速度ベンチはllama-bench、推論は
llama-cli、API サーバーはllama-server、変換はllama-quantizeのように
サブツールが分かれています。本記事の比較は全てllama-benchの数字です
ビルドオプションも頻繁に変わります。本検証で使った GGML_HIP_ROCWMMA_FATTN、
GGML_HIP_NO_VMM、GGML_HIP_MMQ_MFMA は HIP ビルドで効くオプションですが、
これも追加・削除・名前変更が時々起きるので、ビルド前に
cmake -LH | grep GGML_HIP で現状の選択肢を確認する習慣をつけると確実です。
Vulkan と HIP
llama.cpp が AMD GPU で使える主要なバックエンドは 2 つあります。
Vulkan
- もとは 3D グラフィックス用の API で、compute shader 拡張で汎用計算にも対応した
- ベンダー非依存で AMD / NVIDIA / Intel どの GPU でも動く汎用性が強み
- llama.cpp 側では
KHR_coopmat(Vulkan の協調行列演算拡張) で行列積を高速化 - GDN や Mamba 系の linear-attention カーネルも GLSL シェーダーで実装済み
- セットアップは
apt install libvulkan-dev程度で済む
HIP (ROCm)
- AMD GPU 専用の compute API。NVIDIA CUDA とほぼ同じ命令体系を持ち、CUDA 向けコードを HIP に変換しやすい (
hipifyツールがある) - llama.cpp の HIP バックエンドは CUDA バックエンドのコードベースを HIP に変換したもの。rocBLAS + Tensile (汎用 GEMM)、MMQ MFMA (量子化専用カーネル)、rocWMMA (Flash Attention)といった CUDA 由来の最適化経路をそのまま使える
- ROCm 7.2.2 で gfx1151 ネイティブ Tensile カーネルが同梱されたため、
HSA_OVERRIDE_GFX_VERSIONの hack が不要になった - セットアップは ROCm SDK (~3 GB) の導入が必要
ざっくり言うと、Vulkan は汎用で楽、HIP は AMD 専用で CUDA 由来の最適化が乗る、という性格の違いがあります。
「AMD GPU では Vulkan と HIP のどっちが速いのか?」は llama.cpp の AMD ユーザーで議論されてきたテーマで、GPU 世代やワークロードで結論が分かれていました。本記事はその比較を gfx1151 (Strix Halo) で 2026 年 4 月時点の最新状況で取った、というものです。
検証環境
| 項目 | 値 |
|---|---|
| ホスト | EVO-X2 (GMKtec) |
| CPU | AMD Ryzen AI Max+ 395 |
| GPU | Radeon 8060S Graphics (gfx1151, Strix Halo) |
| Unified memory | 128GB (BIOS で VGM=96GB に固定) |
| OS | Ubuntu 26.04 LTS |
| Kernel | 7.0.0-14-generic |
| ROCm | 7.2.2 (AMD 公式 noble repo) |
| llama.cpp | tag b8966、commit 7b8443ac7 |
| ビルド A |
vulkan-b8966 (KHR_coopmat) |
| ビルド B |
hip-b8966-nowmma (ROCWMMA_FATTN=OFF, HIP_NO_VMM=ON, MMQ_MFMA=ON) |
ビルドオプションの選定理由は本記事末尾の付録 A (rocWMMA は gfx1151 で逆効果) を参照してください。
検証モデル
公式 / Unsloth / ggml-org の標準版 GGUF を、量子化 Q4_K_M で揃えました。Q4_K_M を選んだのは、Strix Halo の VRAM 96 GB 帯で大型モデルまで含めて全部載せられる現実解だからです。
| ラベル | モデル | 種別 | params | size | 出所 |
|---|---|---|---|---|---|
| qwen35-35b-a3b | Qwen 3.5-35B-A3B | MoE+GDN, A3B | 34.66 B | 20.49 GiB | Unsloth |
| gemma4-26b-a4b | Gemma 4 26B-A4B-it | MoE 純 | 25.23 B | 15.63 GiB | ggml-org |
| qwen35-27b-dense | Qwen 3.5-27B Dense | Dense+GDN | 26.90 B | 15.58 GiB | Unsloth |
| gemma4-31b-dense | Gemma 4 31B-it | Dense 純 | 30.70 B | 17.39 GiB | ggml-org |
| qwen36-35b-a3b | Qwen 3.6-35B-A3B | MoE+GDN, A3B (3:1) | 34.66 B | 19.91 GiB | Qwen 公式 |
| qwen35-122b-a10b | Qwen 3.5-122B-A10B | 大型 MoE+GDN, A10B | 122.11 B | 71.27 GiB | Unsloth |
「GDN」= Gated Delta Net (Qwen 3.5/3.6 系の linear-attention 経路)。
結論先取り: 4 つのワークロード軸
| ワークロード | プロンプト | 生成 | 優位 | 差分 |
|---|---|---|---|---|
| llama-bench pp16384 | 16k token | 0 | HIP | +48% |
| JCQ Thinking OFF | ~280 token | ~2 token | HIP | +15% |
| llama-bench tg128 | 0 | 128 token | Vulkan | +18% |
| VLM Caption (画像 + 生成) | ~3k token | ~1024 token | Vulkan | +15% |
読み方: 上から下に進むにつれて、ワークロードの「生成長」が増えていきます。生成 0 (pp16384) では HIP が +48% の大差で勝ち、生成が増えるにつれ HIP の優位が縮み、生成 128 を超えると Vulkan が逆転します (冒頭のグラフ参照)。
つまり、
- prompt processing が支配的なワークロードでは HIP
- generation が支配的なワークロードでは Vulkan
これが本記事の最大の発見です。「llama.cpp の合成指標 (pp16384 / tg128) は実ワークロード性能に直接対応する」と読めるので、合成ベンチをそのまま実用判断に使える、というのは技術的にも嬉しいポイントです。
ベンチマーク結果
ベンチ条件
llama-bench -m <model> -ngl 99 -fa 1 -mmp 0 \
-p 512,2048,8192,16384 -n 128 \
-ub 2048 -r 3
生 t/s (3 反復平均、太字は同モデル内で速い側)
| ラベル | バックエンド | pp512 | pp2048 | pp8192 | pp16384 | tg128 |
|---|---|---|---|---|---|---|
| qwen35-35b-a3b | vulkan-b8966 | 1103.20 | 799.49 | 833.61 | 758.14 | 62.19 |
| qwen35-35b-a3b | hip-nowmma | 1137.13 | 1414.92 | 1256.52 | 1122.31 | 52.73 |
| gemma4-26b-a4b | vulkan-b8966 | 1301.63 | 1568.03 | 1339.37 | 1181.42 | 65.94 |
| gemma4-26b-a4b | hip-nowmma | 1302.80 | 1700.90 | 1386.28 | 1205.09 | 57.64 |
| qwen35-27b-dense | vulkan-b8966 | 365.08 | 308.50 | 275.64 | 247.11 | 12.67 |
| qwen35-27b-dense | hip-nowmma | 366.46 | 327.02 | 316.16 | 293.26 | 12.05 |
| gemma4-31b-dense | vulkan-b8966 | 299.53 | 287.62 | 240.63 | 161.16 | 11.25 |
| gemma4-31b-dense | hip-nowmma | 317.96 | 302.99 | 261.60 | 232.38 | 10.44 |
| qwen36-35b-a3b | vulkan-b8966 | 1091.83 | 821.39 | 851.06 | 766.14 | 69.39 |
| qwen36-35b-a3b | hip-nowmma | 1015.97 | 1333.26 | 1208.61 | 1082.27 | 58.52 |
| qwen35-122b-a10b | vulkan-b8966 | 315.74 | 400.25 | 395.94 | 366.46 | 23.10 |
| qwen35-122b-a10b | hip-nowmma | 362.67 | 494.06 | 458.66 | 414.84 | 21.38 |
標準偏差は概ね 1% 未満、再現性は高いです。
long-context prefill (pp16384) — モデル別の HIP 優位度
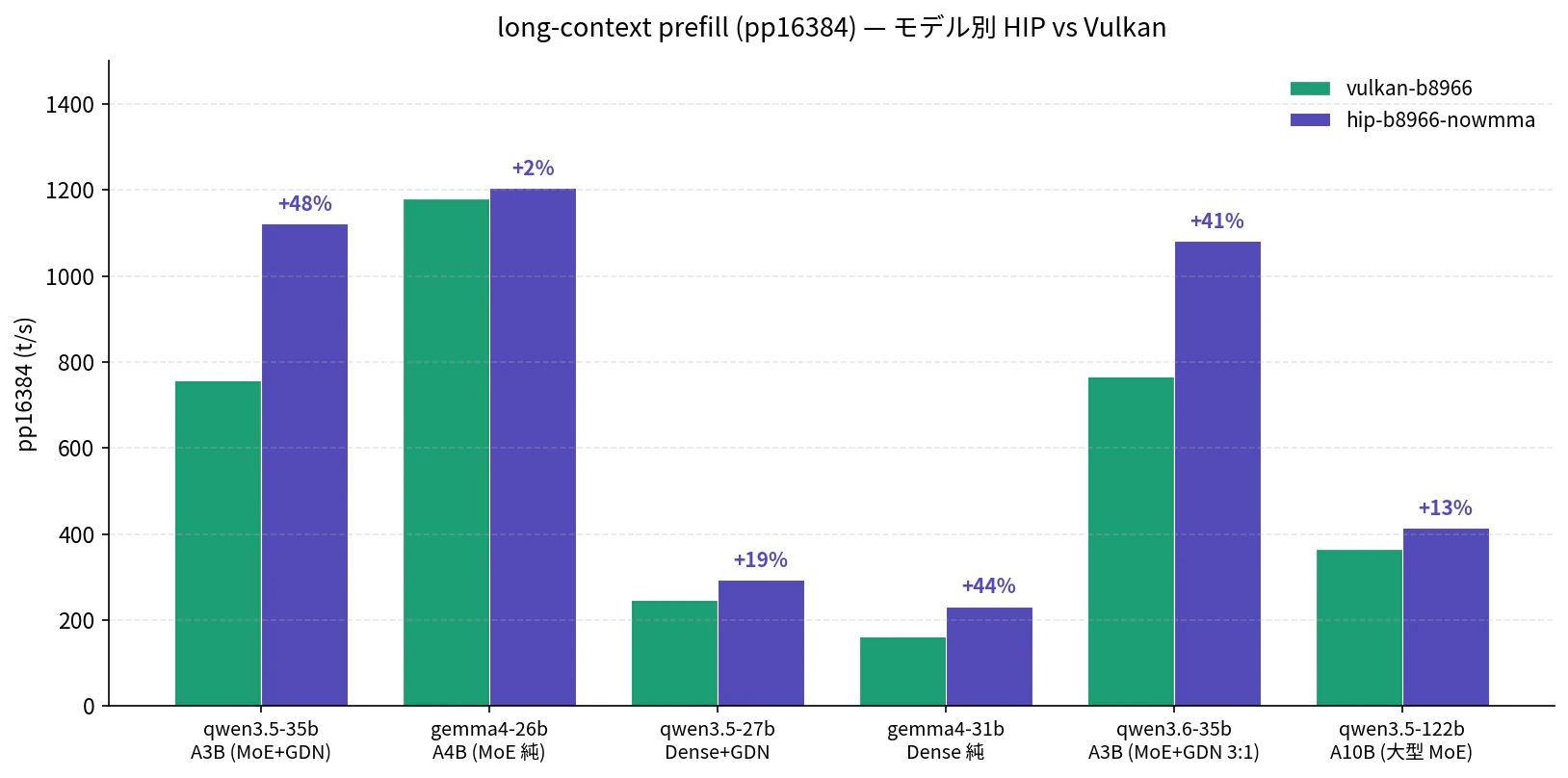
pp16384 で HIP が大きく勝つのは qwen35-35b-a3b (+48%)、gemma4-31b-dense (+44%)、qwen36-35b-a3b (+41%) の 3 モデル。一方 gemma4-26b-a4b はわずか +2% で、HIP の優位がほぼ消失します。これは GDN 経路の有無が効いている、という仮説が立ち上がる入り口です (次節)。
qwen35-122b-a10b は絶対値が低い (366 → 415 t/s) ものの、+13% の HIP 優位を維持します。
token generation (tg128) — 全モデルで Vulkan 優位
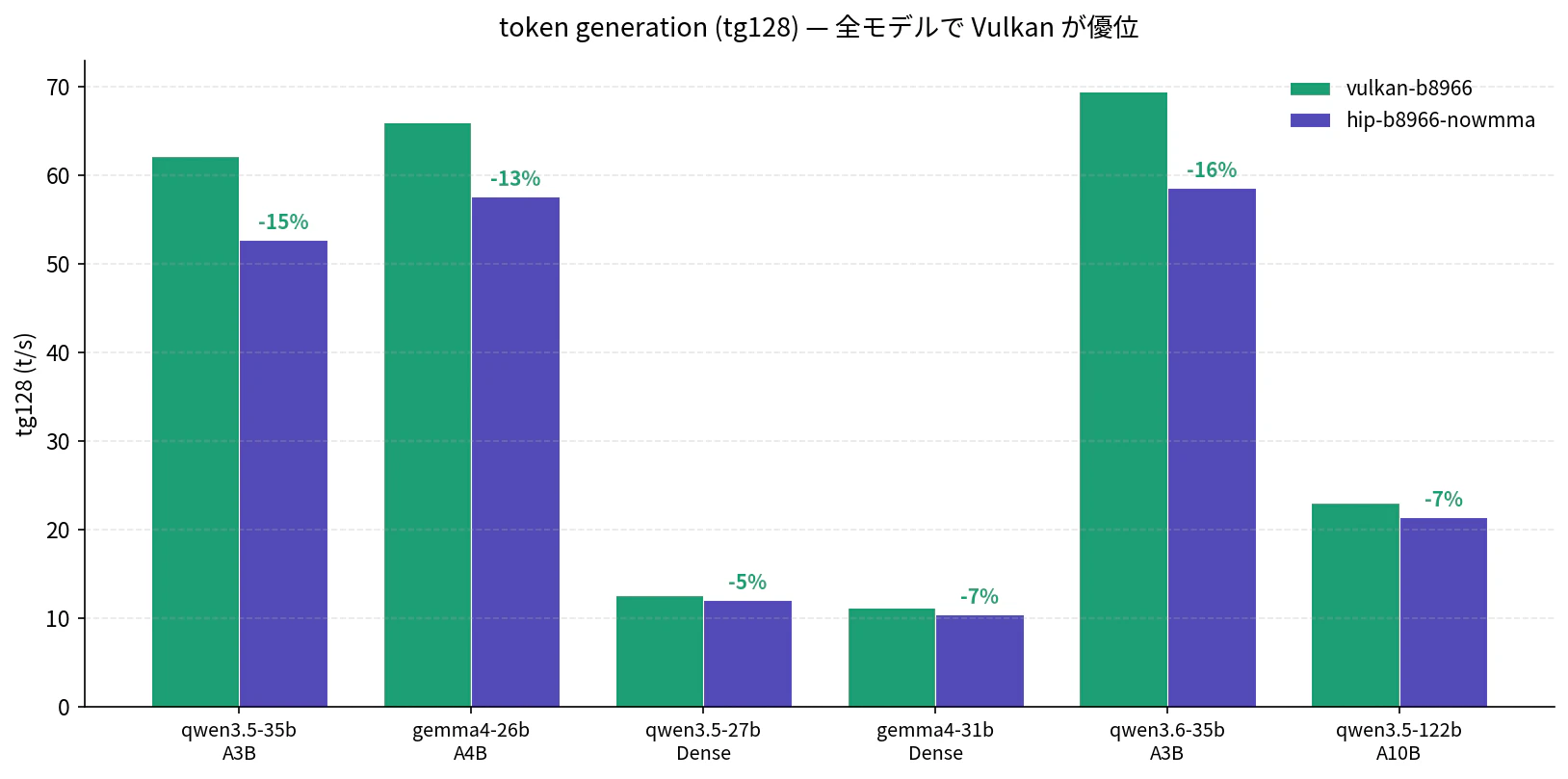
tg128 は 全 6 モデルで Vulkan が +5〜+19% 速い、という綺麗に揃った結果。MoE / Dense / GDN の有無を問わず、生成フェーズでは Vulkan が安定して優位です。これが「生成が長くなれば Vulkan」の根拠になります。
long-context スケーリング (pp512 → pp16384)
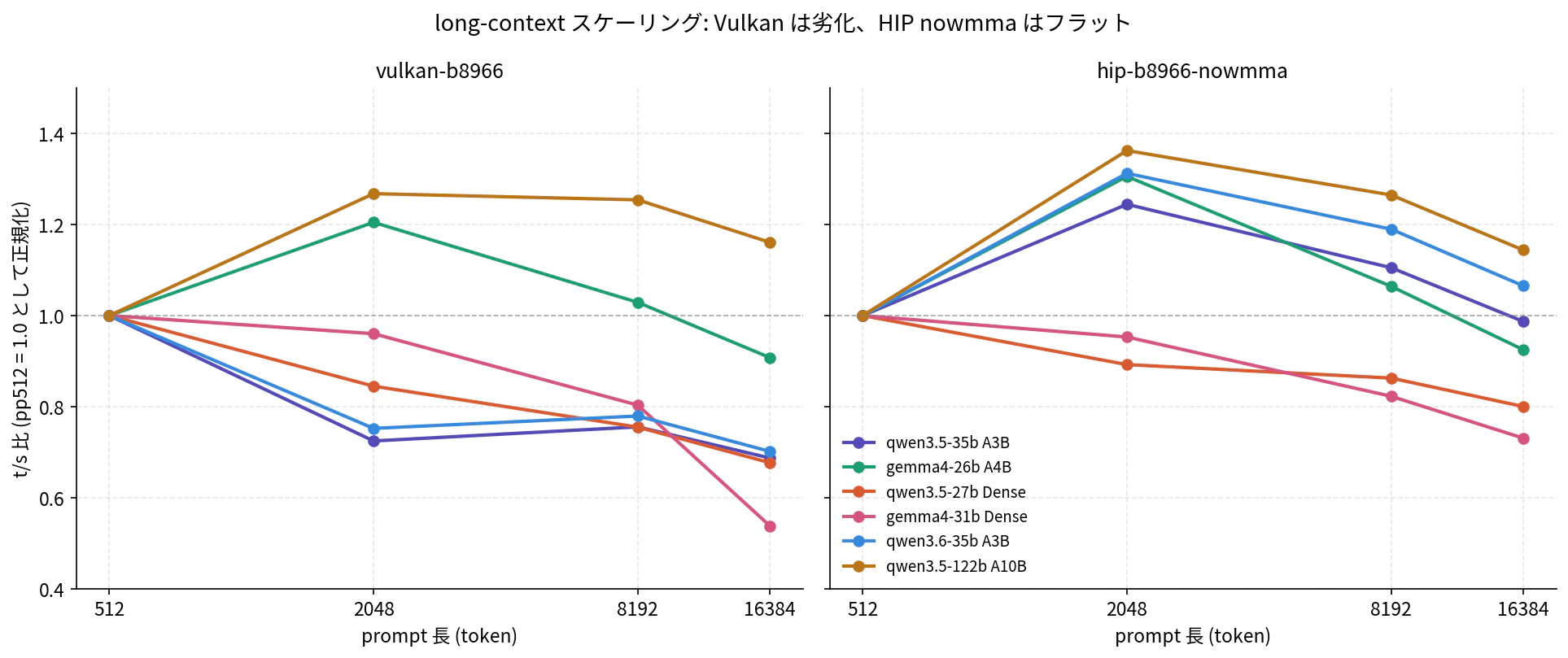
各モデルで pp512 を 1.0 に正規化し、prompt 長を 512 → 2048 → 8192 → 16384 と伸ばしたときの t/s 比をプロットしました。
Vulkan 側 (左): qwen35-35b-a3b (紫)、qwen36-35b-a3b (青)、gemma4-31b-dense (ピンク) が pp16384 で 0.55〜0.70 まで急降下、つまり pp512 の半分前後まで遅くなる。gemma4-26b-a4b (緑) と qwen35-122b-a10b (茶) だけが例外的に維持〜上昇。
HIP 側 (右): 同じモデル群が pp16384 でも 0.99〜1.07 と pp512 を維持〜上回る。Dense + GDN な qwen35-27b-dense (オレンジ) と gemma4-31b-dense (ピンク) は HIP でも下がりますが、Vulkan の同モデルよりは緩やかです。
96GB UMA を活かす: Qwen 3.5-122B-A10B (71GB)
EVO-X2 の VGM=96GB を最大限に活かすケースとして、Qwen 3.5-122B-A10B Q4_K_M (71GB) を載せて測定しました。71GB のモデル + KV cache (16k context) + working memory が 96GB VGM 内に収まり、OOM なく動きます。ロード時間は ~1 分、pp16384 でも OOM は発生しませんでした。
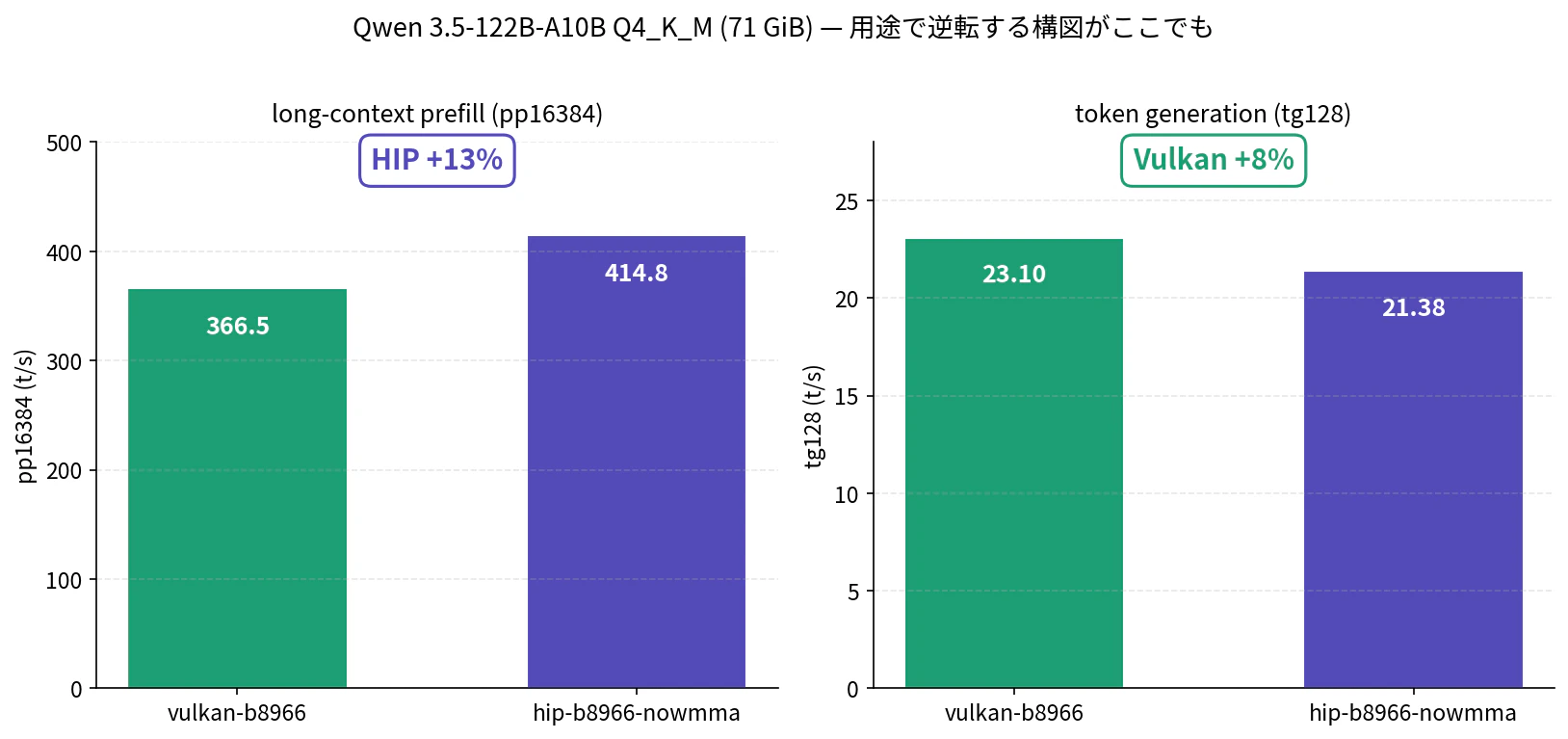
ベンチ結果は他のモデル群と同じ構図 — pp16384 は HIP nowmma が +13%、tg128 は Vulkan が +8% で、本記事の主旋律 (long prompt → HIP / long generation → Vulkan) がここでも再現されています。tg 21〜23 t/s はチャット応答が読みやすい速度 (ChatGPT より少し遅いくらい)。長文を投げる用途では HIP が一枚優れます。
家庭用環境で 122B クラスを実用速度で動かせる、という点で Strix Halo の本領が出るユースケースです。
品質 sanity check: JCQ + VLM
「速度はバックエンドで変わるが品質は変わらない」を実証するため、qwen35-35b-a3b で同条件の品質ベンチを取りました。
JCQ (JCommonsenseQA, 1119 問 Thinking OFF)
JCQ は 日本語常識推論ベンチマーク で、5 択問題 1119 問を解かせて正解率を測ります。
たとえば「電車に乗るときに必要なものは? 1: 切符 2: 定規 3: ...」のような問題で、
人間にとっては当たり前だがモデルにとっては「常識を踏まえた推論」が必要な問いを集めたデータセットです。本検証では Thinking OFF (短く 1 文字で答える) モードで実施、1 問あたり生成 ~2 token、prompt 長 ~280 token と「短プロンプト + 短生成」の典型的なワークロードになります。
| 指標 | vulkan-b8966 | hip-nowmma | 差分 |
|---|---|---|---|
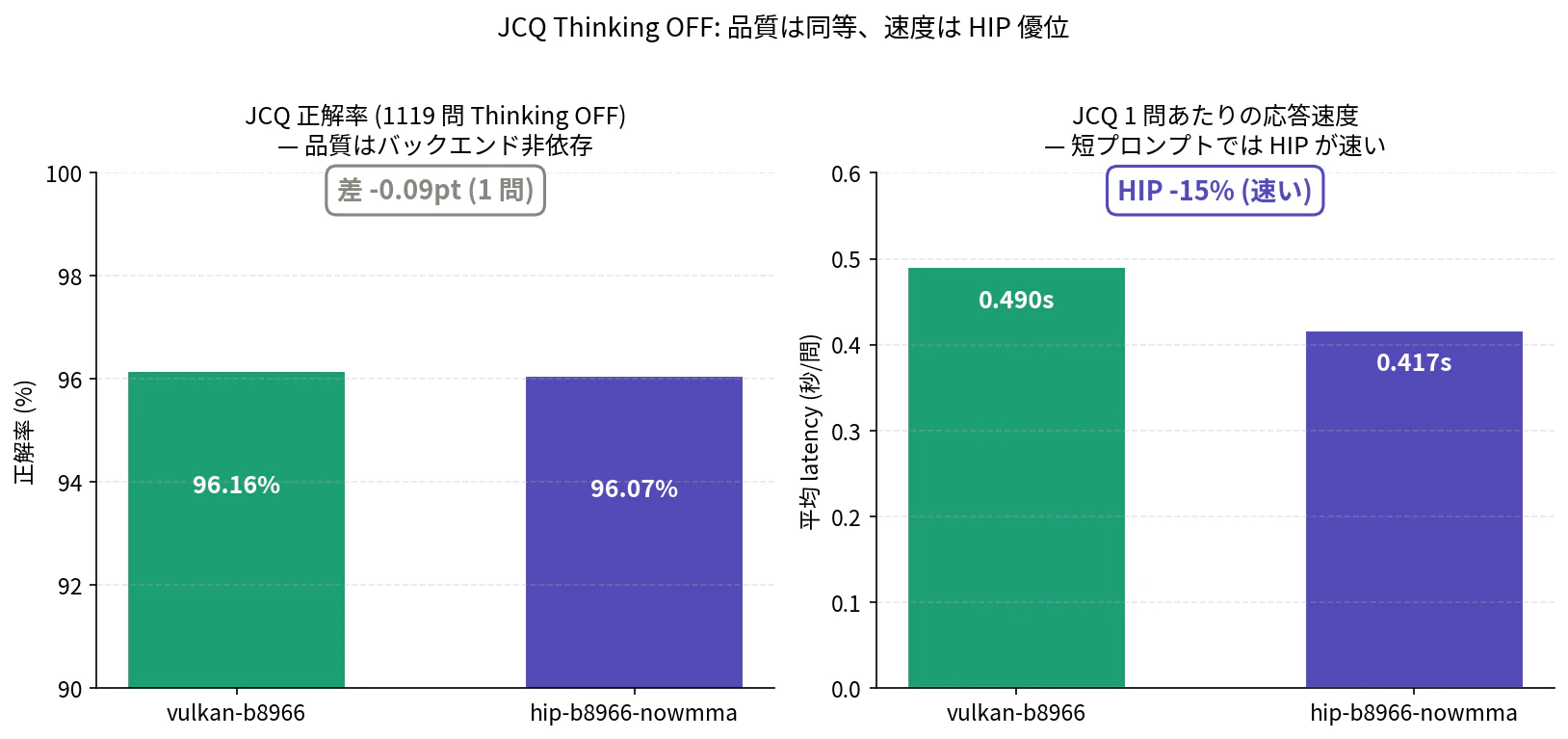
| 正解率 | 96.16% (1076/1119) | 96.07% (1075/1119) | -0.09pt (1 問差) |
| 平均 latency | 0.490 s | 0.417 s | HIP -15% (速い) |
| 平均 tok/s | 93.1 | 88.5 | -5% |
正解率の差は 1 問のみで、temp=0.7 のサンプリング揺れの範囲内です。バックエンド
切替で JCQ 品質には有意差なし。
なお、この 96.16% という数値は過去記事 (DGX Spark, GB10, CUDA + MXFP4 量子化、別ハード別量子化) でも同じ Qwen 3.5-35B-A3B で 96.16% と完全一致しました。JCQ 正解率はハード / 量子化 / バックエンドに依存しないモデル固有の品質指標として機能していることが分かります。
副次的な発見として、JCQ では HIP が latency -15% で勝ちます。JCQ は短い prompt(~280 token) + 短い生成 (~2 token) のワークロードで、prompt processing が支配的になるため、合成 pp512 で同等以下の HIP が実用では速くなる、という構図です。これは冒頭の 4 軸表 (上から 2 番目) とも整合します。
VLM (画像 8 枚 × 3 タスク)
VLM (Vision Language Model) は 画像を入力に取って、画像の内容についてテキストで応答するタスクです。Qwen 3.5-35B-A3B + mmproj-F16.gguf (ビジョンエンコーダ) の構成で、3 種類の異なる難易度のタスクを評価しました:
-
Caption: 画像 (展示会・カンファレンス写真 5 枚) を見て自然言語で説明する。
自由記述なので生成 token 数が多く (~1024 token 完走)、生成フェーズの速度が効く - JSON Extract: 同じ画像から「会場名・ブース名・参加者数」など 6 フィールドを構造化された JSON で抽出する。短い JSON 出力、parse 成功率で品質を評価
- PPE Detect: 作業員写真 3 枚から保護具着用状態 (ヘルメット・ベスト・マスク等)を検出して、ネスト構造を持つ JSON で出力する。最も難しい構造化タスク
| 指標 | vulkan-b8966 | hip-nowmma |
|---|---|---|
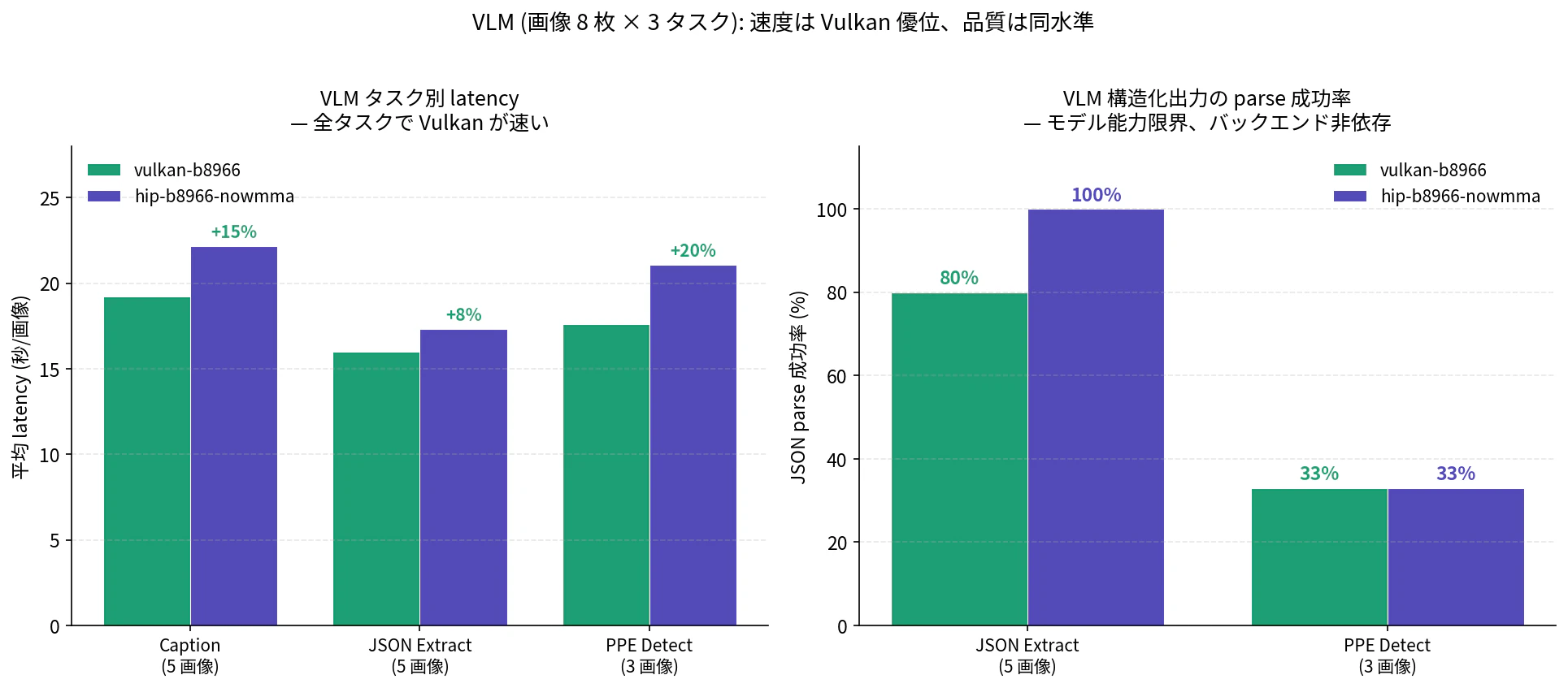
| Caption 平均 latency | 19.24 s | 22.17 s (+15% 遅い) |
| Caption tok/s | 59.7 | 51.7 |
| JSON Extract parse rate | 80% (4/5) | 100% (5/5) |
| PPE Detect parse rate | 33% (1/3) | 33% (1/3) |
-
速度: 全タスクで Vulkan が +8〜+20% 速い。VLM は画像 base64 (~3000 token 相当) + 生成 (~1024 token、Caption 系) という「中プロンプト + 長生成」のワークロードで、generation が支配項になるため
tg128で観測した Vulkan 優位がそのまま出ます - PPE parse rate 33% (両者同点) は Qwen 3.5-35B-A3B + mmproj 側の能力限界を示しており、バックエンド非依存。「PPE のネストした JSON スキーマがモデルにとって難しい」という、モデル選定の課題が見えます (どちらのバックエンドでも 33% で同じ)
-
JSON Extract の Vulkan 80% / HIP 100% は 5 件中 1 件の差で、
temp=1.0のサンプリング揺れの範囲。決定的な品質差とは言えません - llama.cpp Issue #21497 (Vulkan + Gemma 4 VLM crash) は、本検証では Qwen 3.5 を使ったため発火せず、両バックエンドとも安定動作を確認
JCQ と VLM の両方で、「品質はバックエンド非依存、速度はワークロード次第で逆転」 という本記事の主張がもう一段裏付けられました。
全体を通しての考察
ベンチ + 品質テストの全結果を踏まえて、5 つの軸で整理してみます。
考察 1: 4 つのワークロード軸で HIP/Vulkan が階段状に逆転する
生成 token 数が増えるにつれて HIP の優位が崩れ、Vulkan に逆転する。
冒頭で示したグラフを再掲します:
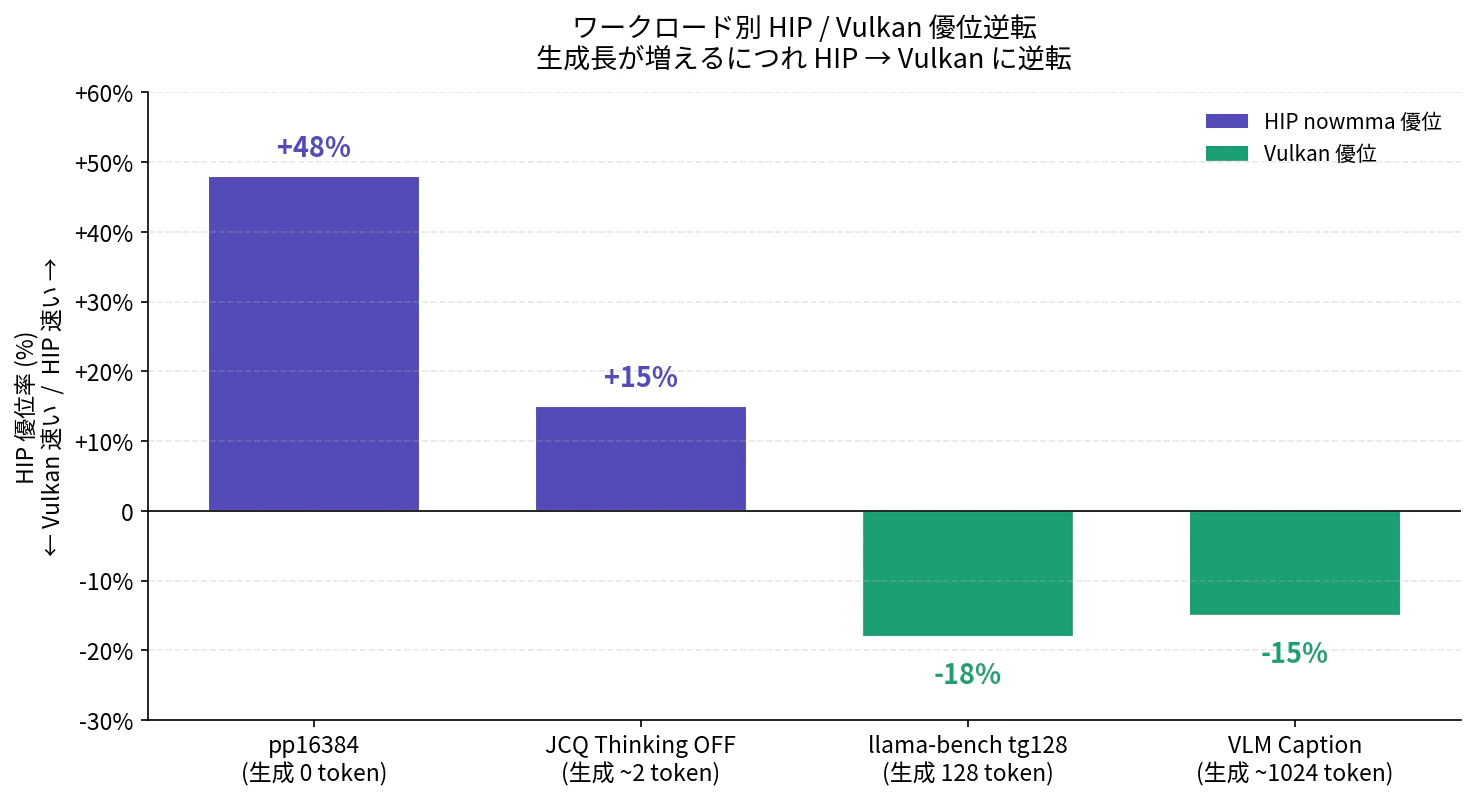
| ワークロード | 生成 token | 結果 |
|---|---|---|
llama-bench pp16384 (合成 prefill) |
0 | HIP +48% |
| JCQ Thinking OFF (短プロンプト + 短生成) | ~2 | HIP +15% |
llama-bench tg128 (合成 generation) |
128 | Vulkan +18% |
| VLM Caption (中プロンプト + 長生成) | ~1024 | Vulkan +15% |
つまり、
- prompt processing が支配的なワークロード (RAG、長文要約の冒頭、コード補完、JCQ 系) では HIP
- generation が支配的なワークロード (チャット、Caption、創作) では Vulkan
合成ベンチ (pp16384 / tg128) の数字がそのまま実用ワークロード (JCQ / VLM Caption)の優劣に対応していたのは、技術的に嬉しい結果と思います。llama-bench の数字を見れば、ワークロードに応じてどちらを選ぶべきかが事前に予測できることになります。
考察 2: prefill では大規模モデルほど HIP の優位が大きい
35B 以上の MoE+GDN A3B と Dense 純で +40% を超える HIP 優位が出る。
pp16384 (long-context prefill) で HIP が大きく勝つのは大規模モデル群です:
| モデル | 規模 | HIP 優位 (pp16384) |
|---|---|---|
| qwen3.5-35b A3B | 35B (活性 3B) | +48% |
| qwen3.6-35b A3B | 35B (活性 3B) | +41% |
| gemma4-31b Dense | 31B | +44% |
| qwen3.5-122b A10B | 122B (活性 10B) | +13% |
| qwen3.5-27b Dense+GDN | 27B | +19% |
| gemma4-26b A4B (MoE 純) | 26B (活性 4B) | わずか +2% |
35B 以上の MoE+GDN A3B (Qwen 3.5/3.6) と Dense 純 (Gemma 4 31B) で +40% を超える HIP 優位が出ます。Dense モデルの巨大な行列積で MMQ_MFMA パスや gfx1151 ネイティブ Tensile カーネルが効いて、long-context での演算密度が高まるほど HIP が有利になる、という構図のように見えます。
122B-A10B が +13% に留まるのは、活性 10B が比較的小さいことに加え、絶対値が他モデルより低い (366→415 t/s) ことから、kernel launch overhead など別の要因が支配しているためと思います。
考察 3: GDN なし MoE では HIP の prefill 優位がほぼ消える
Gemma 4 26B-A4B (GDN なし) では HIP 優位はわずか +2.0%。GDN の有無が効いている。
Gemma 4 26B-A4B (GDN を持たない MoE 純) では、pp16384 の HIP 優位はわずか +2.0% しか出ませんでした。同じく 35B-A3B 系 (MoE+GDN) で +48% 出ているのと対照的です。GDN 経路の処理特性が HIP の prefill 優位の主因の一つになっている可能性があります。Vulkan 側でも GDN シェーダーは実装されていますが、long-context スケーリングが弱い、という構図のように見えます。
ただし考察 2 で見た Gemma 4 31B Dense (GDN なし) で +44% 出ている事実とも合わせると、「HIP 優位 = GDN 経路」と単純化はできない。GDN の有無が一因だが、モデル規模や Dense / MoE 構造、活性パラメータ数も絡む複合要因と見るのが正確だと思います。
考察 4: Dense+GDN はバックエンド問わず Strix Halo の苦手ワークロード
Qwen 3.5-27B (Dense+GDN) は両バックエンドで 12 t/s 程度、他モデルの 1/4 速度。
Qwen 3.5-27B Dense (Dense + GDN) は過去 Vulkan b8576 / b8672 で「1.72 t/s で壊滅」と報告されていましたが、本検証 (b8966) では
- Vulkan
tg128= 12.67 t/s - HIP
tg128= 12.05 t/s
絶対値で他モデルの 1/4 程度。Vulkan 側はシェーダー実装が進んで b8966 で大幅に回復しましたが、HIP に切り替えても救われません。Dense + GDN の組み合わせは Strix Halo では避けるのが現実解と思います。
llama.cpp の Vulkan 開発が「壊滅的に遅い」状態を「実用ぎりぎり」まで持ち上げた事実は評価したいですが、それでも他モデル群の半分以下の速度。Qwen 3.5-27B のような Dense+GDN モデルを使いたい場合は、別ハード (CUDA 機) を検討するのが筋になりそうです。
考察 5: 品質はバックエンド・ハード・量子化に依存しない
JCQ 正解率は Vulkan 96.16% / HIP 96.07% で 1 問差、過去 DGX Spark とも完全一致。
JCQ Thinking OFF で Vulkan 96.16% / HIP 96.07% (差 -0.09pt = 1 問差)。
さらに過去記事 (DGX Spark, GB10, CUDA + MXFP4 量子化) でも同じ Qwen 3.5-35B-A3B で 96.16% と完全一致しました。
VLM の構造化出力 (PPE Detect) でも parse 成功率は両バックエンドとも 33% 同点。これは Qwen 3.5-35B-A3B + mmproj 側の能力限界 (PPE のネスト JSON スキーマが難しい)で、バックエンド非依存と思います。
つまり 「速度はバックエンド・ワークロード次第で大きく変わるが、品質は
モデル固有の指標として安定している」。実用上の含意としては、
- 速度最適化のためのバックエンド切替は安心して行える (品質劣化を心配しなくてよい)
- モデル選定 (どのモデルを使うか) と バックエンド選定 (どう動かすか) は独立した判断軸
として扱える
ということが考えられます。
用途別バックエンド推奨
| ワークロード | モデル例 | 推奨 | 理由 |
|---|---|---|---|
| 日常チャット (短文応答) | qwen36-35b-a3b, gemma4-26b-a4b | Vulkan | tg128 が +14〜+19% 速い |
| RAG / 長文要約 (16k+ 入力) | qwen35/36-35b-a3b, gemma4-31b-dense | HIP nowmma | pp16384 で +41〜+48% |
| コード生成 (中 prompt + 長 gen) | 同上 | Vulkan | 生成が支配的 |
| VLM Caption / 画像理解 | qwen35-35b-a3b + mmproj | Vulkan | 生成が支配的、+15% |
| VLM 構造化出力 (JSON / PPE) | 同上 | 同等 | parse rate に有意差なし |
| 大型 MoE 122B (チャット) | qwen35-122b-a10b | Vulkan (tg) or HIP (バッチ) | tg128 +8% Vulkan、pp +13〜+23% HIP |
| Dense+GDN | qwen35-27b-dense | (避ける) | 両バックエンドとも遅い |
筆者の本番運用 llama-server-q6k.service (Qwen 3.5-35B-A3B Q6_K abl 版を Vulkan で常駐) は、短文チャットのレイテンシ最適化を取った構成で、本記事の tg128 優位データと整合しています。
長文処理を頻繁にやる場合は「読みは HIP、生成は Vulkan」に切り替えるか、両方ロードしておいてリクエストを振り分ける構成が現実的になります。
DGX Spark との比較
ここまで EVO-X2 上での Vulkan vs HIP でしたが、DGX Spark (NVIDIA GB10 Grace Blackwell) との比較をしてみました。DGX Spark は約 60 万円、EVO-X2 (GMKtec) は約 47 万円。約 1.28 倍の価格差があります。DGX Spark は Qwen 3.5/3.6 で MXFP4_MOE、Gemma 4 で F16 (DGX Spark の 128 GB 統合メモリを活かしてフル精度)。EVO-X2 は本記事の主役である Q4_K_M で揃えています。
long-context prefill (pp16384) — DGX Spark が圧勝
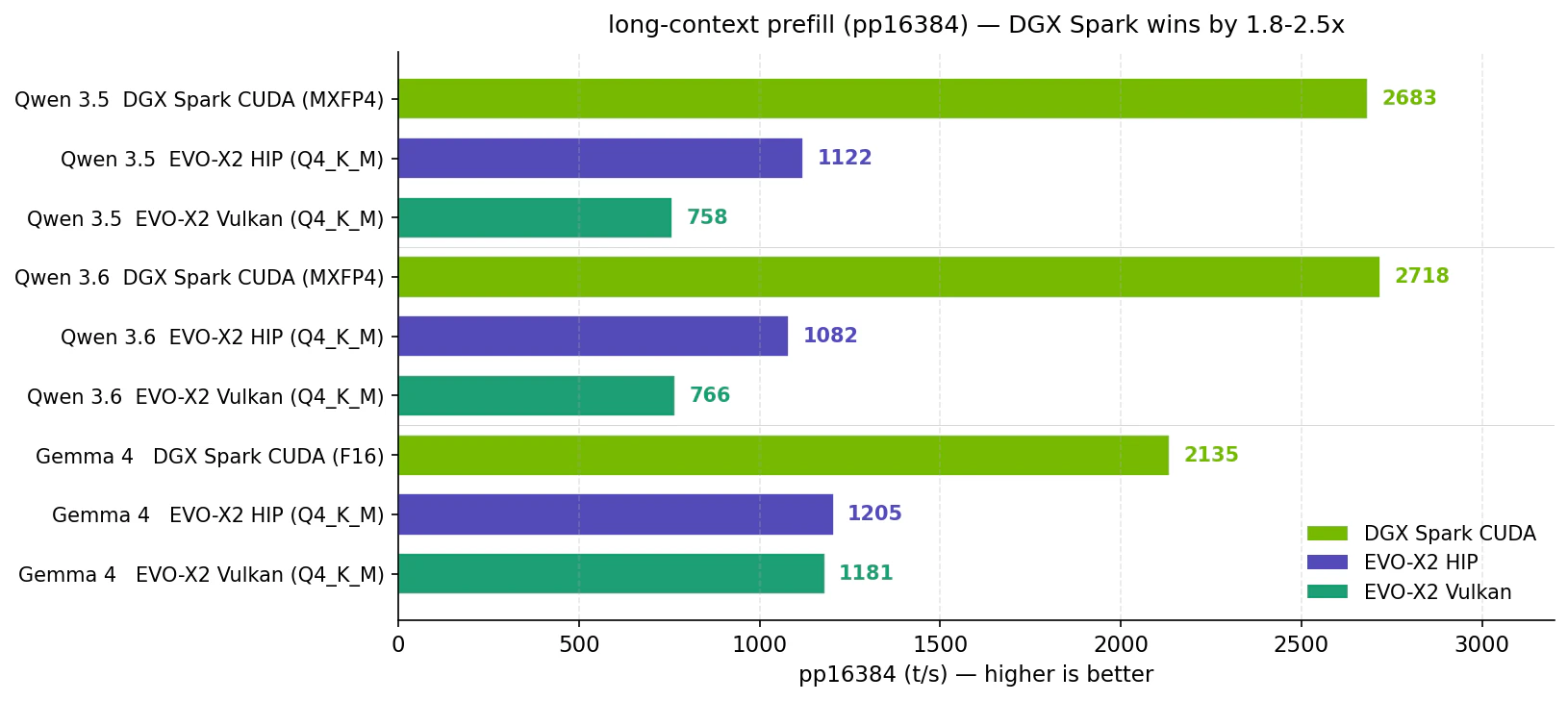
pp16384 で見ると DGX Spark は EVO-X2 の最速側 (HIP) に対して 1.8〜2.5 倍 速いです。RAG / 長文要約 / 大規模コードベースの解析のように、入力が大きい用途では Tensor Core の演算性能が直接効きます。価格差 1.28 倍を超える速度差が出ているので、長文処理が主用途なら DGX Spark の投資価値は素直に出る、と言えそうです。
token generation (tg128) — EVO-X2 が逆転

tg128 は構図が反転して、3 モデル全てで EVO-X2 (Vulkan) が DGX Spark より速い という結果でした。
- Qwen 3.5: EVO-X2 +20% (62.2 vs 51.6)
- Qwen 3.6: EVO-X2 +11% (67.5 vs 60.7)
- Gemma 4: EVO-X2 +149% (65.9 vs 26.5)
Gemma 4 で差が極端に大きいのは、DGX Spark が F16 (47 GiB) を読みに行くのに対し、EVO-X2 は Q4_K_M (16 GiB) で済むからです。tg は基本的にメモリ帯域律速なので、重みサイズが小さいほうが圧倒的に有利になります。「DGX Spark の 128 GB メモリでフル精度を載せる」という選択肢が、tg では裏目に出る形になりました。
Qwen 3.5/3.6 は DGX Spark の MXFP4 (~20 GiB) と EVO-X2 の Q4_K_M (~20 GiB) で
重みサイズが近いので差は小さくなりますが、それでも EVO-X2 が +10〜+20% 速い、という結果です。EVO-X2 の LPDDR5X (~256 GB/s) と DGX Spark の LPDDR5X (273 GB/s)で帯域はほぼ同等、ここまで来ると llama.cpp バックエンドのカーネル効率が効いてくる、というところまで踏み込めそうです。
価格差 1.28 倍 + 用途別の速度差を踏まえると、
- 長文 prefill が主用途 (RAG / 要約 / コード補完): DGX Spark が価格対性能でも合理的
- チャット応答 / VLM Caption / 創作: EVO-X2 で十分以上、むしろ DGX Spark より速い
という整理になります。本記事の主旋律「プロンプト処理寄りなら HIP / 生成寄りなら Vulkan」を、ハードウェア選定にまでスケールアップした構図ですね。「自分のワークロードが prefill 寄りか generation 寄りか」が、バックエンドだけでなくハード選びの判断軸に
直結する、というのは個人的には興味深い観察でした。
(なお DGX Spark は llama.cpp b8672 + CUDA、EVO-X2 は b8966 + Vulkan/HIP で測定しているため、ビルドタグが微妙に違います。あくまで参考値としてお考えください。)
Ubuntu 26.04 + ROCm 7.2.2 セットアップメモ
ここからはビルド環境の話です。「やってみよう」という方向け。
1. ROCm 7.2.2 を AMD 公式 noble repo から導入
26.04 ネイティブの ROCm パッケージはまだ無いため、noble (24.04) のリポジトリをそのまま追加します。
sudo apt-key del AC4A0B6B
wget -qO - https://repo.radeon.com/rocm/rocm.gpg.key | \
sudo gpg --dearmor -o /usr/share/keyrings/rocm.gpg
echo 'deb [arch=amd64 signed-by=/usr/share/keyrings/rocm.gpg] \
https://repo.radeon.com/rocm/apt/7.2.2 noble main' | \
sudo tee /etc/apt/sources.list.d/rocm.list
sudo apt update
sudo apt install -y rocm-hip-sdk rocwmma-dev
amdgpu-dkms は使わず、26.04 inbox の amdgpu (kernel 7.0.0-14-generic) をそのまま使います。HSA_OVERRIDE_GFX_VERSION も不要 (gfx1151 は ROCm 7.2.2 で Tensile カーネルがネイティブ提供されています)。
2. lld 依存ライブラリ ABI ミスマッチへの対処 (重要)
ROCm 7.2.2 の lld バイナリは noble (24.04) 時代の SONAME に依存しているため、26.04 上では HIP コンパイラの内部リンクで not found が連鎖します。
実測で発生した連鎖:
-
lld→libxml2.so.2(noble libxml2 2.9 / 26.04 は libxml2 2.15/.so.16) -
libxml2.so.2.9→libicuuc.so.74,libicui18n.so.74,libicudata.so.74(noble libicu74 / 26.04 は libicu78)
回避策は noble の deb から該当 .so のみ抽出して /opt/rocm-7.2.2/lib/ に配置するだけ:
cd /tmp
# libxml2
wget http://archive.ubuntu.com/ubuntu/pool/main/libx/libxml2/libxml2_2.9.14+dfsg-1.3ubuntu3_amd64.deb
dpkg-deb -x libxml2_*.deb /tmp/libxml2-extract/
sudo cp /tmp/libxml2-extract/usr/lib/x86_64-linux-gnu/libxml2.so.2.9.14 /opt/rocm-7.2.2/lib/
sudo ln -sf libxml2.so.2.9.14 /opt/rocm-7.2.2/lib/libxml2.so.2
# libicu74
wget http://archive.ubuntu.com/ubuntu/pool/main/i/icu/libicu74_74.2-1ubuntu3_amd64.deb
dpkg-deb -x libicu74_*.deb /tmp/libicu74-extract/
sudo cp /tmp/libicu74-extract/usr/lib/x86_64-linux-gnu/libicu*.so.74* /opt/rocm-7.2.2/lib/
# 確認
ldd /opt/rocm-7.2.2/lib/llvm/bin/lld | grep -E 'libxml2|libicu'
# → いずれも /opt/rocm-7.2.2/lib/ 配下で解決されていれば OK
/opt/rocm-7.2.2/lib/ は lld の rpath 配下なので ldconfig 設定不要、システム側の apt や他アプリ (faster-whisper など) には影響しません。
関連: ROCm/ROCm Issue #6046 (2026-03 報告、執筆時点未解決)
3. llama.cpp の HIP ビルド
cd ~/llama.cpp
git checkout b8966
export HIPCXX="$(hipconfig -l)/clang"
export HIP_PATH="$(hipconfig -R)"
cmake -S . -B hip-b8966-nowmma \
-DGGML_HIP=ON -DGPU_TARGETS=gfx1151 \
-DGGML_HIP_ROCWMMA_FATTN=OFF \
-DGGML_HIP_NO_VMM=ON \
-DGGML_HIP_MMQ_MFMA=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build hip-b8966-nowmma --config Release -j8
ビルド時間は EVO-X2 で -j8 で約 2 分半。Vulkan (-DGGML_VULKAN=ON) ビルドより速いくらいです。
ROCWMMA_FATTN=OFF がポイントで、ON にすると逆に遅くなります (詳細は付録 A)。
付録 A: rocWMMA は gfx1151 で逆効果
Discussion #21526 で gfx1100 (RDNA 3) について「rocWMMA OFF が速い」という報告がありますが、本検証で gfx1151 (Strix Halo, RDNA 3.5) でも同じ反例が成立 することを確認しました。
Qwen 3.5-35B-A3B Q4_K_M で 3 バリアント (rocWMMA ON / OFF / GRAPHS) を比較した結果:
| ビルド | pp512 | pp2048 | pp16384 | tg128 |
|---|---|---|---|---|
| hip-wmma (rocWMMA ON) | 936 | 1079 | 425 | 61.7 |
| hip-nowmma (rocWMMA OFF) | 1047 | 1368 | 1092 | 61.9 |
| hip-graphs (wmma + GRAPHS) | 974 | 1077 | 425 | 61.5 |
pp16384 で OFF は ON の +157% という大差。rocWMMA は CDNA 系 (MFMA を持つ) を主ターゲットに最適化されており、RDNA 3.5 の WMMA 命令での実装は十分にチューニングされていない可能性が高いです。
GGML_HIP_GRAPHS=ON は本ワークロードでは ±1% 以内の差で無効果でした。HIP Graphs は kernel launch overhead を削るための機構なので、個々の kernel が十分大きい MoE Q4_K_M ではゲインが見えなかったと解釈できます。
付録 B: Vulkan の pp512 → pp2048 異常
Qwen 3.5/3.6-35B-A3B (MoE+GDN A3B) で、Vulkan の pp2048 が pp512 より遅くなる現象を観測しました:
- qwen35-35b-a3b vulkan: pp512=1103 → pp2048=799 (-28%)
- qwen36-35b-a3b vulkan: pp512=1092 → pp2048=821 (-25%)
HIP では同じモデルで pp512=1137 → pp2048=1415 と +24% 上昇するため、これは Vulkan 固有の挙動です。-ub 2048 (ubatch_size) と prompt 長 2048 が一致したときに起きるため、Vulkan バックエンドの GDN 関連カーネル選択ロジックの問題と推測しています。
llama.cpp の Vulkan 側にフィードバックする価値のある観察ですが、原因切り分けには -ub 1024 や -ub 4096 でずらしたときの挙動も必要で、今回はそこまでは深掘りしていません。