注意書き
この記事は,著者が個人開発の中で調べたことや試したことを整理した備忘録として書いています.
あわせて,技術記事という性格上実際に手元で試す場合は原典や実装,前提条件を確認したうえで各自の責任で扱ってください.
はじめに
前回までは,クーポン施策に対して 「平均するとどれくらい効いているのか」 を見てきました.
これは ATE を見るという意味で重要なのですが,現実の施策では 誰に対しても同じだけ効く とは限りません.
たとえば同じクーポンでも,
- もともと購買金額が高い人にはそこまで上乗せが出ない
- 中価格帯の人には強く効く
- 年齢や購買履歴によって効き方が変わる
といったことが普通に起こります.
そこで今回は,平均効果だけではなく 効果の分布そのもの を見に行きます.
扱うのは T-learner と呼ばれる素朴でわかりやすいアウトカム予測の方法です.
本記事では,前回までと同じクーポン施策のシミュレーションデータを使って
-
T-learnerによるアウトカム予測の考え方を確認する -
Y(1)とY(0)を別々に予測して個別効果tauを推定する - 単一実験で真の効果分布と推定効果分布のズレを見る
- データ数を変えたときに推定誤差がどう変わるかを確認する
という流れで見ていきます.
真の効果は分布である
因果推論では,個人 $ i $ に対する介入効果を
\tau_i = Y_i(1) - Y_i(0)
と書きます.1
ただし現実には,同じ人について Y(1) と Y(0) を同時に観測することはできません.
クーポンを配った場合の購買金額と,配らなかった場合の購買金額を,同じ顧客に対して同時に観測することは不可能だからです.
このため前回までは平均を取って
\mathrm{ATE} = \mathbb{E}[Y(1) - Y(0)]
を見ていました.これは平均的な施策効果を把握するには十分役立ちます.
一方で,施策を実務で使うことを考えると 「平均では効くが,どこに効いているのかはわからない」 では少し物足りません.
実際の効果は以下の図の右側のように顧客属性に影響を受けた分布になっている可能性があります.
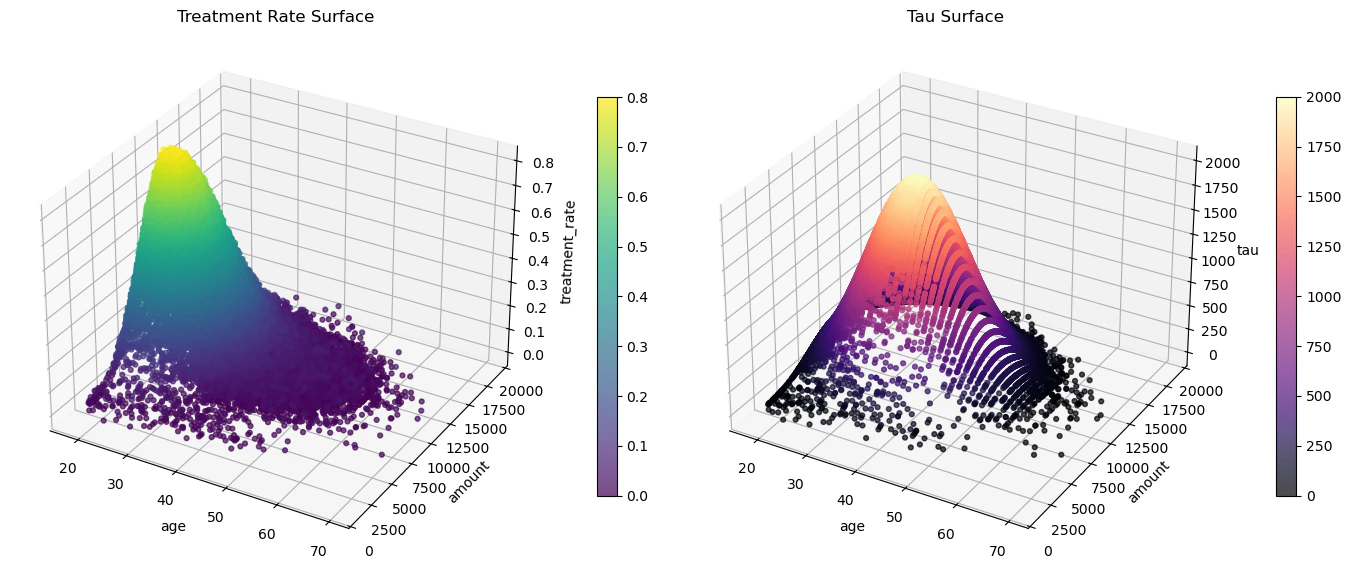
たとえば次のような問いは,ATE だけでは答えにくいです.
- どの顧客層で効果が大きいのか
- どの顧客層ではほとんど効かないのか
- 効果が高い人を優先して施策対象にできないか
こうした問いに近づくための1つの考え方が,まず潜在アウトカムそのもの Y(1) と Y(0) を予測し,その差分として効果を作るという方法です.
データ
今回も以下の記事で作成したクーポン施策のシミュレーションデータを使います.
主な列は以下の通りです.
| 列名 | 意味 |
|---|---|
gender, age, recency, frequency, amount
|
事前に観測できる顧客属性 |
treatment |
実際に介入されたかどうか |
outcome |
実際に観測されたアウトカム |
tau |
真の個別介入効果 |
y0, y1
|
非介入時・介入時の潜在アウトカム |
シミュレーションデータなので tau, y0, y1 の真値をあとから確認できますが,実務データでは通常ここは見えません.
今回の目的は,この見えている真値を答え合わせに使いながら アウトカム予測がどの程度うまく効くか を確認することです.
アウトカム予測
アウトカム予測とは
アウトカム予測の発想はかなり素朴です.
- 介入群だけを使って
Y(1)を予測するモデルを作る - 非介入群だけを使って
Y(0)を予測するモデルを作る - 各サンプルに対して両方を予測し,差分を個別効果とみなす
数式で書くと,予測モデルを
\hat{\mu}_1(x) \approx \mathbb{E}[Y \mid X=x, T=1]
\hat{\mu}_0(x) \approx \mathbb{E}[Y \mid X=x, T=0]
として学習し,
\hat{\tau}(x) = \hat{\mu}_1(x) - \hat{\mu}_0(x)
で効果を作る,という形です.
このように treatment ごとに別々のモデルを学習するので,T-learner と呼ばれます.2
直感的には,それぞれの群の中で 「この特徴を持つ人なら,その世界線ではどのくらい買いそうか」 を学習し,最後に2つの世界線の差を取っています.
アウトカム予測の実装
今回は gender, age, recency, frequency, amount を説明変数にして,介入群用と非介入群用にそれぞれ XGBoost 回帰モデルを作ります.
カテゴリ変数 gender は OneHotEncoder で展開し,age, recency, frequency, amount はそのまま使います.
feature_cols = ["gender", "age", "recency", "frequency", "amount"]
categorical_features = ["gender"]
numeric_features = ["age", "recency", "frequency", "amount"]
def make_regression_pipeline(random_state=42):
preprocess = ColumnTransformer(
transformers=[
(
"cat",
OneHotEncoder(handle_unknown="ignore", sparse_output=False),
categorical_features,
),
("num", "passthrough", numeric_features),
]
)
return Pipeline(
steps=[
("preprocess", preprocess),
(
"model",
XGBRegressor(
n_estimators=300,
max_depth=4,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
objective="reg:squarederror",
eval_metric="mae",
random_state=random_state,
),
),
]
)
各行について y0_hat と y1_hat を作る処理は以下です.
同じデータを学習にも予測にも使うと楽観的になるので,StratifiedKFold を使って out-of-fold 予測にしています.
def evaluate_t_learner(df_input, random_state=42):
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=random_state)
oof_y0_hat = np.zeros(len(df_input))
oof_y1_hat = np.zeros(len(df_input))
X_all = df_input[feature_cols].copy()
treatment_all = df_input["treatment"].copy()
for fold, (train_idx, valid_idx) in enumerate(cv.split(X_all, treatment_all), start=1):
train_df = df_input.iloc[train_idx].copy()
valid_X = df_input.iloc[valid_idx][feature_cols].copy()
train_treated = train_df[train_df["treatment"] == 1]
train_control = train_df[train_df["treatment"] == 0]
y1_model = make_regression_pipeline(random_state=random_state + fold)
y0_model = make_regression_pipeline(random_state=random_state + 100 + fold)
y1_model.fit(train_treated[feature_cols], train_treated["outcome"])
y0_model.fit(train_control[feature_cols], train_control["outcome"])
oof_y1_hat[valid_idx] = y1_model.predict(valid_X)
oof_y0_hat[valid_idx] = y0_model.predict(valid_X)
df_outcome = df_input.copy()
df_outcome["y0_hat"] = oof_y0_hat
df_outcome["y1_hat"] = oof_y1_hat
df_outcome["tau_hat"] = df_outcome["y1_hat"] - df_outcome["y0_hat"]
return df_outcome
ここで重要なのは,各サンプルについて
- 実際に観測された側のアウトカム
- 観測されなかった反実仮想側のアウトカム
の両方を予測している点です.
介入された顧客に対しては y1 側は事実に近い世界で,y0 側は未観測の反実仮想です.
非介入顧客に対しては逆になります.
この意味で T-learner は,平均効果を直接作るというより 反実仮想を補完して差分を作る手法 と見ると理解しやすいです.
単一実験とデータ数実験では,主に以下の指標を見ます.
| 指標 | 意味 |
|---|---|
counterfactual_mae |
観測されていない側の潜在アウトカムをどれくらい正確に補完できたかを見る誤差 |
tau_mae |
真の個別効果 tau と推定個別効果 tau_hat のずれを見る誤差 |
真の ATE
|
シミュレーション上で既知の平均介入効果 |
推定 ATE
|
tau_hat を平均して得た平均介入効果の推定値 |
ATE の絶対誤差 |
真の ATE と推定 ATE の差の大きさ |
counterfactual_mae は反実仮想そのものの補完精度を,tau_mae は個別効果の推定精度を,ATE の絶対誤差は平均効果の推定精度を表しています.
単一実験の結果
まずは n=50,000,介入率 0.3 の1回の実験を見ます.
このときの介入群は 15,000 件,非介入群は 35,000 件でした.
評価指標は以下の通りです.
| 指標 | 値 |
|---|---|
counterfactual_mae |
94.711 |
tau_mae |
108.441 |
真の ATE
|
960.308 |
推定 ATE
|
975.191 |
ATE の絶対誤差 |
14.884 |
それでも ATE の推定値は 975.191 で,真の ATE 960.308 にかなり近い値になりました.
一方で個別効果そのものの誤差を表す tau_mae は 108.441 あるので, 平均はかなり合うが個票レベルではまだズレる という見方ができます.
以下は真の効果 tau と推定効果 tau_hat を3D散布図で比較したものです.大まかな山をとらえることはできているように見えます.
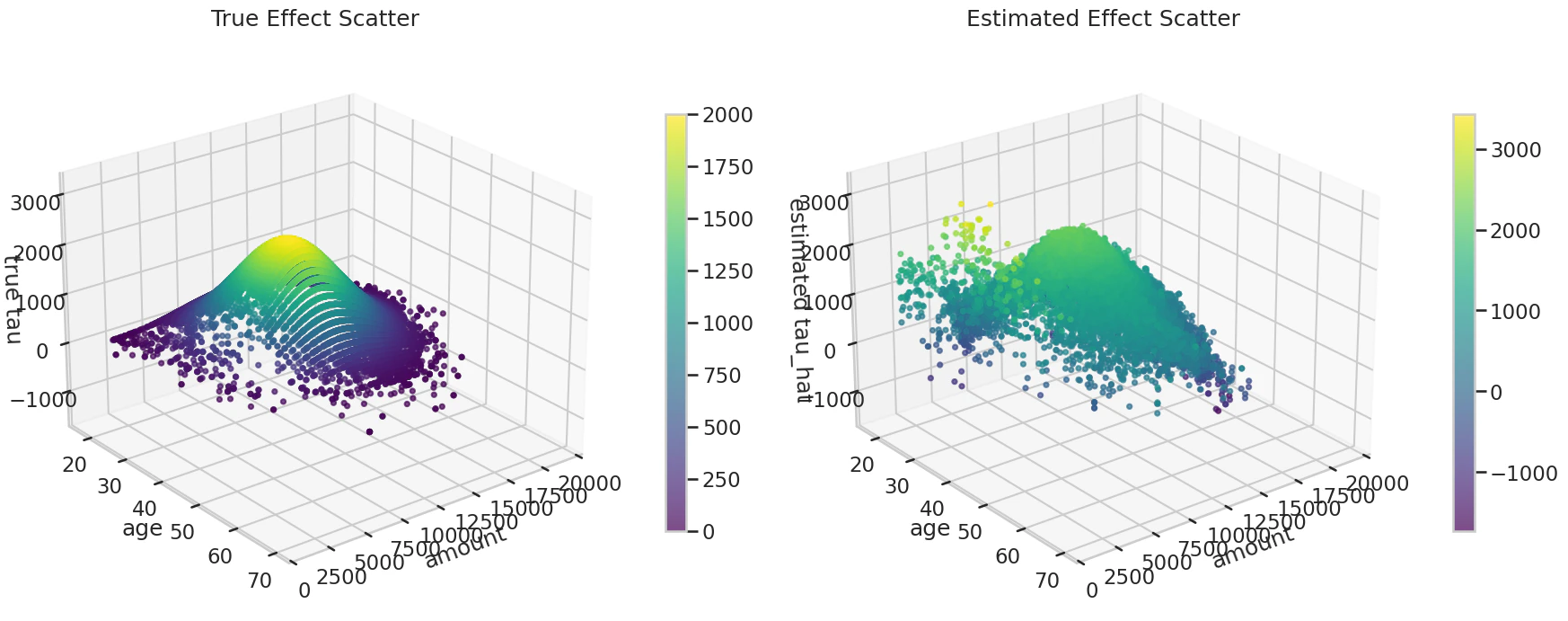
何が嬉しいのか
ここまで来ると,T-learner の嬉しさは平均値よりもむしろ 分布を持った効果を扱えること にあります.
たとえば tau_hat が作れれば,
- 効果が大きそうな顧客を優先して配布する
- 効果が小さそうな顧客を除外する
- どの特徴量空間で効果が高いかを可視化する
といった次の施策判断につなげやすくなります.
もちろん,推定された tau_hat をそのまま真実とみなしてよいわけではありません.
ただ,平均値1本だけを持つよりは 「誰に効きそうか」 という問いに踏み込めるようになる点は大きいです.
データ数を変えた場合の挙動
次に,treated 比率を 0.3 に固定したままサンプルサイズだけを変えてみます.
試したのは 100, 1,000, 5,000, 10,000, 50,000 の5条件です.
結果は以下でした.
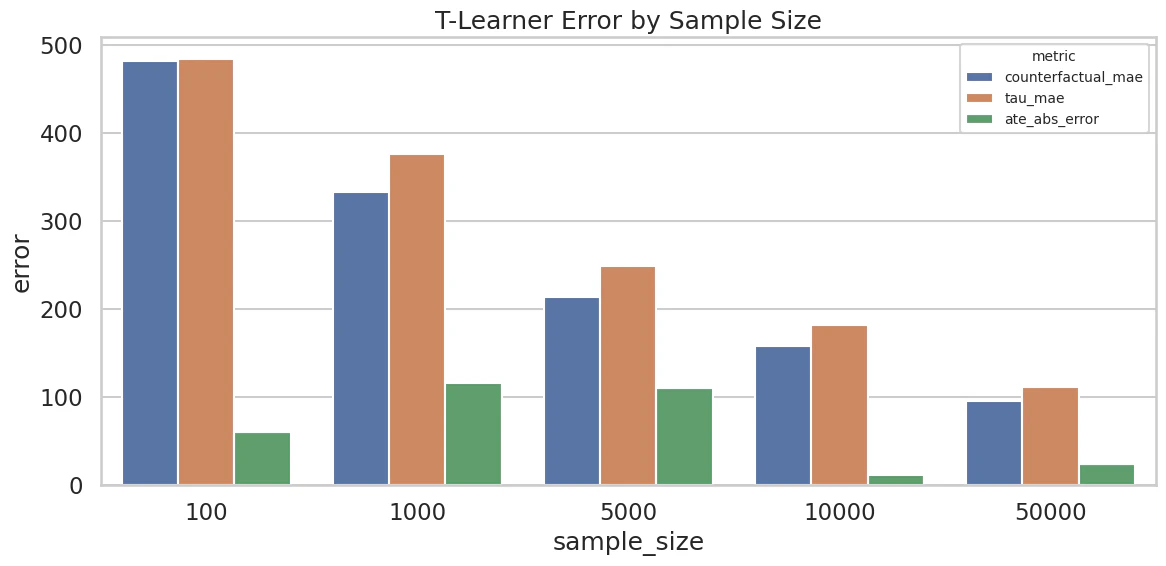
| サンプルサイズ | counterfactual_mae |
tau_mae |
真の ATE
|
推定 ATE
|
ATE の絶対誤差 |
|---|---|---|---|---|---|
100 |
481.750 |
484.246 |
969.770 |
909.418 |
60.352 |
1,000 |
332.573 |
376.213 |
983.784 |
1099.257 |
115.473 |
5,000 |
213.709 |
248.921 |
958.215 |
1068.567 |
110.353 |
10,000 |
158.296 |
181.467 |
955.948 |
967.108 |
11.161 |
50,000 |
95.432 |
111.136 |
961.062 |
984.524 |
23.462 |
全体としては,サンプルサイズが大きくなるほど counterfactual_mae と tau_mae が下がっており,反実仮想の補完が安定していく様子が見えます.
一方で ATE の絶対誤差は単調には下がっていません.
1,000 や 5,000 ではまだ上下にぶれていますし,10,000 でかなり良くなったあと 50,000 で少し戻っています.
ここから見えてくるのは,
- 個別効果の推定は平均効果の推定より難しい
- サンプル数が少ないと反実仮想の予測がかなり不安定になる
-
ATEがたまたま近くても,個別効果まで正確とは限らない
という点です.
つまり 「平均が合ったから安心」ではなく,個票レベルの誤差や分布の形も見る必要がある ということです.
まとめ
今回は T-learner によるアウトカム予測を使って,クーポン施策の個別効果分布を見てみました.
-
T-learnerはY(1)とY(0)を別々に予測し,差分からtau_hatを作る - 単一実験では真の
ATE960.308に対して推定ATEは975.191とかなり近かった - 一方で
tau_maeは108.441あり,個別効果の推定は平均効果より難しい - サンプルサイズが増えると,反実仮想予測や個別効果推定は概ね安定する
平均効果を見るだけなら ATE で十分な場面もありますが,施策を 「誰に打つか」 まで考えるなら効果の分布を扱えることが重要になります.