はじめに
こんにちは!
今年は「Kubernetesを基礎から理解して、GKEで運用できるようになる」ことを目標に、アドベントカレンダーでまとめながら学習していこうと思います!
これまで「なんとなく難しそう」と避けてきたk8sですが、この機会にゼロから本気で学び直します。
前提知識
- コンテナ技術の基礎知識がある方
- Dockerを使った経験がある方(
docker run,docker-compose等を使ったことがある) - Dockerコンテナを本番環境で運用した経験、または運用を検討している方
- Dockerはわかるけど、k8sは何から始めればいいかわからないという方
この連載では、Dockerの基本を理解している方が、次のステップとしてKubernetesを学ぶ際に「どこから手をつければいいのか」を明確にして、基礎的な部分から理解しながら進めていきます。
1. そもそも Kubernetes (k8s) って何?
名前の由来
まず、「Kubernetes」という名前についてです。

Kubernetes(クーベネティス、クバネティス) は、ギリシャ語で 「舵取り」「操舵手」 を意味し、コンテナという「船」を操舵するイメージから名付けられたようです。
公式ロゴを見ると船の舵輪になっていますが、この語源が関係しているようです。(言われて初めて気づきました)
また、KubernetesのKとsの間に8文字あることから「k8s」という略称が付けられています。
コンテナを「オーケストレーション」する
Dockerを使えば簡単にアプリケーションをコンテナ化できますが、本番環境で大量のコンテナを動かすとなると、新たな課題が出てきます。
例えば、以下のような課題です
1. 障害時の自動復旧
あるコンテナがクラッシュした時、誰かが気づいて手動で再起動する必要があります。深夜2時にコンテナが落ちたら、誰が起きて対応するのでしょうか?ヘルスチェックと自動再起動の仕組みが必要です。
2. スケーリングの手間
アクセスが急増してサーバーが高負荷になった時、手動でコンテナを増やして、各サーバーに配置して、ロードバランサーの設定を変更して...という作業を素早く行う必要があります。逆にアクセスが減ったら、無駄なコンテナを停止してコストを削減したいですよね。
3. リソースの効率的な配置
10台のサーバーがあって、100個のコンテナを動かす場合、「どのサーバーにどのコンテナを配置すれば、CPU・メモリを無駄なく使えるか」を人間が計算するのは現実的ではありません。
4. サービス間の通信管理
マイクロサービス構成だと、コンテナAがコンテナBと通信する際、コンテナBのIPアドレスはどうやって知るのか?コンテナは再起動するたびにIPが変わる可能性があります。
5. ローリングアップデート
新しいバージョンのアプリをデプロイする際、いきなり全部を入れ替えるとサービスが止まります。段階的に少しずつ入れ替えて、問題があれば即座にロールバックする仕組みが必要です。
マイクロサービスになっていくと、これらを全て人間が手動で管理していくのは非効率的ですし現実的ではありません。そこで登場するのが Kubernetes です。
k8sは、「大量のコンテナの配備、スケーリング、管理を自動化する(オーケストレーションする)」ためのプラットフォームです。
Docker と Kubernetes の違い
- Docker: コンテナを「作る」「動かす」技術(単体)
- Kubernetes: 複数のコンテナを「管理する」「維持する」技術(集合体)
2. アーキテクチャの全体像
そもそも「クラスタ」とは?
Kubernetesを理解する上で、まず「クラスタ」という概念を押さえておきます。
クラスタ(Cluster) とは、複数のサーバー(ノード)が集まって、1つのシステムとして協調しながら動作する集合体のことです。
Kubernetesの大きな特徴は、クラスタ単位でコンテナを管理する点です。
1台のサーバーで個別にコンテナを動かすのではなく、複数のサーバーをクラスタとして束ねて、その中でコンテナを柔軟に配置・管理します。
Kubernetesクラスタの構成
まずは、公式ドキュメントから引用したKubernetesクラスタのアーキテクチャ図を見てみます。

出典: Kubernetes公式ドキュメント - Cluster Architecture
...正直、この図だけ見てもまだ全くピンと来ません
Kubernetesは抽象的な概念が多くそれぞれで深い理解が求められますね...
Kubernetesクラスタは、大きく分けて2つの要素で構成されています
- Control Plane(コントロールプレーン、別名:Master Node): クラスタ全体を管理する司令塔
- Worker Node(ワーカーノード): 実際にアプリケーション(Pod)が動作する作業現場
次の章で港と船に例えて、これらの関係性を主要概念の概要を押さえながら確認していきます。
3. k8sの主要概念
主要リソース一覧表
主要な概念を一覧でまとめました。
理解しやすくするために、Kubernetesを「港」と「船」に例えて考えてみることにします。
| カテゴリ | リソース名 | 概要 | 港の例え |
|---|---|---|---|
| クラスタ構成 | Control Plane | クラスタ全体を管理する司令塔。API Server、Scheduler、Controller Managerなどで構成 | 港湾管制センター |
| Worker Node | 実際にPodが動作するサーバー。Kubeletが常駐してControl Planeからの指示を実行 | 埠頭(バース) | |
| アプリケーション実行 | Pod | k8sにおける最小のデプロイ単位。1つ以上のコンテナをまとめたもの | コンテナ船 |
| Deployment | Podを管理するリソース。レプリカ数の指定や段階的アップデートを実現 | 船舶管理会社 | |
| ReplicaSet | Podのレプリカ数を維持(通常はDeploymentが自動管理) | - | |
| StatefulSet | ステートフルなアプリケーション(データベースなど)用のリソース | - | |
| Job / CronJob | バッチ処理やスケジュール実行を行うリソース | チャーター船 | |
| ネットワーク・通信 | Service | 複数のPodを1つのエンドポイントとして公開。負荷分散を提供 | 固定埠頭番号 |
| Ingress | HTTP/HTTPSレベルのルーティング。パスベースの振り分けが可能 | 入港管理センター | |
| 設定・機密情報 | ConfigMap | 設定情報(環境変数、設定ファイル)をコンテナから分離管理 | 航海マニュアル |
| Secret | パスワードやAPIキーなどの機密情報を安全に管理 | 船舶証明書 | |
| データ永続化 | Volume | コンテナ内データの永続化 | 貨物倉庫 |
| PersistentVolume/PVC | クラウドディスクサービスと連携した本格的なストレージ管理 | 専用倉庫 | |
| その他 | Namespace | クラスタ内リソースの論理分割(開発/本番環境の分離など) | 港湾エリア |
| kubectl | k8sクラスタを操作するCLIツール | 港湾管制端末 |
リソース同士の連携フロー
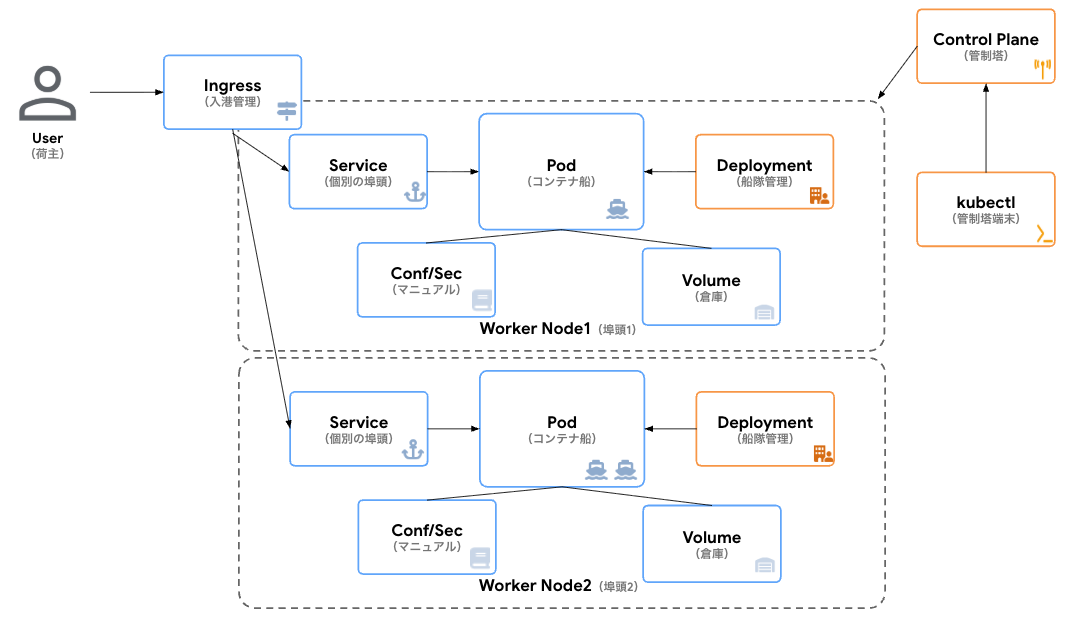
ユーザーがアプリにアクセスする流れ
-
👤 荷主(ユーザー)が依頼
- ユーザーがアプリにHTTPリクエストを送信
-
🏢 入港管理センター(Ingress)がルーティング
-
/api→ 1番埠頭(Service A)へ -
/web→ 2番埠頭(Service B)へ
-
-
⚓ 埠頭(Service)が振り分け
- 複数のコンテナ船(Pod)に負荷分散
- 船が入れ替わっても、同じ埠頭番号でアクセス可能
-
🚢 コンテナ船(Pod)がサービス提供
- 実際にアプリケーションが動いて、レスポンスを返す
- Podの中には複数のコンテナがあります
-
📋 船舶管理会社(Deployment)が隻数管理
- 「常に2隻配備する」という指示を維持
- 1隻が故障したら、自動で代替船を手配
-
🎛️ 港湾管制端末(kubectl)が全体を指揮
- 管理者がkubectlで「この航路は船を3隻に増やせ」などと指示
-
📖 航海マニュアル(ConfigMap)/ 🔒 船舶証明書(Secret)
- コンテナ船(Pod)に必要な設定情報や認証情報を提供
-
📦 貨物倉庫(Volume)
- 船が出港しても、データは失われずに保管
このように、各リソースが役割分担しながら連携することで、アプリケーションが安定して動作します!
アーキテクチャ図の振り返り
ここまで港の例えを使って、Kubernetesの各リソースを説明してきました。
- Control Plane:港湾管制センター(kubectl、API Server、Scheduler、Controller Manager)
- Nodes:実際にコンテナ船(Pod)が停泊する埠頭
最初は複雑に見えた図も、少しイメージが湧いてきたのではないでしょうか?
Kubernetesはコンテナを活用したアプリケーションを統合的に管理運用するためのプラットフォーム(オーケストレーションツール)ということがわかりました。
フローの中では「常に2隻配備する」という指示を受けて、自動で調整していましたが、これがKubernetesの最大の特徴である「宣言的設定」です。
4. 「宣言的設定(Declarative)」という考え方
従来のシステム管理と、Kubernetesの管理方法には大きな違いがあります。
命令的 vs 宣言的
命令的(Imperative)な管理
「サーバーAでコンテナを起動しろ」「コンテナBを停止しろ」「コンテナCを3個増やせ」と、やるべきアクションを一つずつ指示します。
宣言的(Declarative)な管理
「Webサーバーは常に3台動いている状態にする」というあるべき姿(Desired State)を宣言します。
自己修復(Self-healing)の仕組み
k8sの優れているところは、自動的に「あるべき状態」を維持してくれる点にあります。
例えば、「Podを3つ動かす」というDeploymentを作成したとします。
以下のように障害検知され復旧されていきます。
- 正常時: Pod が 3つ動いている
- 障害発生: 1つのPodがクラッシュ → Pod が 2つに減る
- 自動修復: Kubernetesが「設定は3つなのに2つしかない!」と検知
- 自動回復: 自動的に新しいPodを起動 → Pod が 3つに戻る
人間が何もしなくても、Kubernetesが勝手に「あるべき状態」に戻してくれます。
まさにこれが Self-healing(自己修復) 機能です。
書き方については後々の工程で記載予定のためここでは省略します。
出典: Kubernetes公式ドキュメント - Kubernetes の自己修復
まとめと次回予告
- Kubernetesはコンテナの「オーケストレーション」ツール。
- 「Control Plane」と「Node」で構成されている。
- 「宣言的」に記述することで、あるべき状態を勝手に維持してくれる。
- 主要なリソースには、Pod、Deployment、Service、Ingressなどがある。
k8sが舵取りという言葉から来ているとおり、港と船の例えで確認すると個人的にはわかりやすかったです。
次回 は、「Pod / Deployment / Service」というk8sの基本リソースを図解し、実際にどうやってアプリが動くのかを深掘りしていきたいと思います!
それでは、また明日!