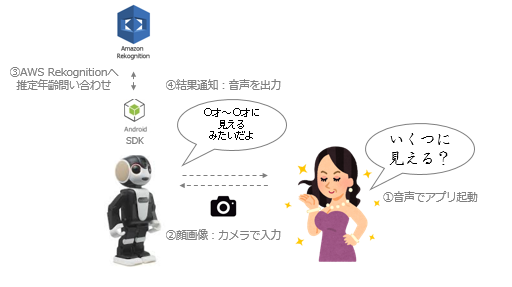
モバイル型ロボット電話 RoBoHoN に、AWS Rekognition APIを連携させ、ユーザーからの「私、いくつに見える?」という問いかけに返事をできるように実装しました。
環境
Windows 7 SP1 64bit
Android Studio 2.3.1
RoBoHoN_SDK 1.2.0
RoBoHon端末ビルド番号 02.01.00
AWS SDK for Android 2.6.9
AWS Mobile SDK for Android 導入
- 導入要件
Android 2.3.3 (API Level 10) or higher
RoBoHoN は Android 5.0.2 (API Level 21 (Lollipop))
- 参考
[AWS] Set Up the AWS Mobile SDK for Android
http://docs.aws.amazon.com/mobile/sdkforandroid/developerguide/setup.html
- Get the AWS Mobile SDK for Android.
- Set permissions in your AndroidManifest.xml file.
- Obtain AWS credentials using Amazon Cognito.
[qiita] Amazon Rekognitionで犬と唐揚げを見分けるアプリを作ってみた
https://qiita.com/unoemon/items/2bdf933127b6e225d036
- 追加ライブラリ
compile 'com.amazonaws:aws-android-sdk-core:2.6.9'
compile 'com.amazonaws:aws-android-sdk-rekognition:2.6.9'
compile 'com.amazonaws:aws-android-sdk-cognito:2.6.9'
RoBoHoN実装
RoBoHoN独自の発語用 VoiceUI 、撮影用ライブラリ、そして Rekognition 通信を行き来をする実装を書いていきます。
- Rekognition 通信部分参考
[AWS] Documentation » Amazon Rekognition » 開発者ガイド » Amazon Rekognition の開始方法 » ステップ 4: API の使用開始 » 演習 2: 顔の検出 (API)
http://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/get-started-exercise-detect-faces.html
- インターネット疎通とストレージパーミッション
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
- RoBoHonシナリオ関連定義類
/**
* Guess my age? シーン、accost、通知設定
*/
public static final String SCN_CALL = PACKAGE + ".guess.call";
public static final String SCN_RES = PACKAGE + ".guess.res";
public static final String ACC_CALL = ScenarioDefinitions.PACKAGE + ".guess.call";
public static final String ACC_RES = ScenarioDefinitions.PACKAGE + ".guess.res";
public static final String FUNC_CALL = "guess_call";
public static final String FUNC_RES = "guess_res";
/**
* memory_pを指定するタグ
*/
public static final String MEM_P_RES = ScenarioDefinitions.TAG_MEMORY_PERMANENT + ScenarioDefinitions.PACKAGE + ".res";
- HVML(ユーザーからの呼びかけで起動、年齢判定のための写真撮影の声かけ、年齢判定を通知する)
<?xml version="1.0" ?>
<hvml version="2.0">
<head>
<producer>com.dev.zdev.rekog</producer>
<description>いくつにみえる?のホーム起動シナリオ</description>
<scene value="home" />
<version value="1.0" />
<situation priority="78" topic_id="start" trigger="user-word">${Local:WORD_APPLICATION} eq
いくつにみえる
</situation>
<situation priority="78" topic_id="start" trigger="user-word">
${Local:WORD_APPLICATION_FREEWORD} eq いくつにみえる
</situation>
</head>
<body>
<topic id="start" listen="false">
<action index="1">
<speech>${resolver:speech_ok(${resolver:ok_id})}</speech>
<behavior id="${resolver:motion_ok(${resolver:ok_id})}" type="normal" />
<control function="start_activity" target="home">
<data key="package_name" value="com.dev.zdev.rekog" />
<data key="class_name" value="com.dev.zdev.rekog.MainActivity" />
</control>
</action>
</topic>
</body>
</hvml>
<?xml version="1.0" ?>
<hvml version="2.0">
<head>
<producer>com.dev.zdev.rekog</producer>
<description>Guess my age? 撮影呼びかけ</description>
<scene value="com.dev.zdev.rekog.guess.call" />
<version value="1.0" />
<accost priority="75" topic_id="call" word="com.dev.zdev.rekog.guess.call" />
</head>
<body>
<topic id="call" listen="false">
<action index="1">
<speech>お顔をよーく見せて……。写真を撮るよ…。<wait ms="300"/></speech>
<behavior id="assign" type="normal" />
</action>
<action index="2">
<control function="guess_call" target="com.dev.zdev.rekog"/>
</action>
</topic>
</body>
</hvml>
<?xml version="1.0" ?>
<hvml version="2.0">
<head>
<producer>com.dev.zdev.rekog</producer>
<description>Guess my age? 結果通知</description>
<scene value="com.dev.zdev.rekog.guess.res" />
<version value="1.0" />
<accost priority="75" topic_id="call" word="com.dev.zdev.rekog.guess.res" />
</head>
<body>
<topic id="call" listen="false">
<action index="1">
<speech>${memory_p:com.dev.zdev.rekog.res}にみえるみたいだよ</speech>
<behavior id="assign" type="normal" />
</action>
<action index="2">
<control function="guess_res" target="com.dev.zdev.rekog"/>
</action>
</topic>
</body>
</hvml>
- MainActivity(各所抜粋)
private boolean hascall;
//onCreate ファンクション にカメラ連携起動結果取得用レシーバー登録
mCameraResultReceiver = new CameraResultReceiver();
IntentFilter filterCamera = new IntentFilter(ACTION_RESULT_TAKE_PICTURE);
registerReceiver(mCameraResultReceiver, filterCamera);
//onResume ファンクション にScenn有効化追記
VoiceUIManagerUtil.enableScene(mVoiceUIManager, ScenarioDefinitions.SCN_CALL);
VoiceUIManagerUtil.enableScene(mVoiceUIManager, ScenarioDefinitions.SCN_RES);
//onResume ファンクション にScenn有効化後、即時発話(初回のみ)
if (mVoiceUIManager != null && !hascall) {
VoiceUIVariableListHelper helper = new VoiceUIVariableListHelper().addAccost(ScenarioDefinitions.ACC_CALL);
VoiceUIManagerUtil.updateAppInfo(mVoiceUIManager, helper.getVariableList(), true);
}
//onPause ファンクション にScene無効化
VoiceUIManagerUtil.disableScene(mVoiceUIManager, ScenarioDefinitions.SCN_CALL);
VoiceUIManagerUtil.disableScene(mVoiceUIManager, ScenarioDefinitions.SCN_RES);
//onDestroy ファンクション にカメラ連携起動結果取得用レシーバー破棄
this.unregisterReceiver(mCameraResultReceiver);
/**
* VoiceUIListenerクラスからのコールバックを実装する.
*/
@Override
public void onExecCommand(String command, List<VoiceUIVariable> variables) {
Log.v(TAG, "onExecCommand() : " + command);
switch (command) {
case ScenarioDefinitions.FUNC_CALL:
// 写真呼びかけ状況設定
hascall =true;
//写真を撮る
sendBroadcast(getIntentForPhoto(false));
break;
case ScenarioDefinitions.FUNC_RES:
finish();
break;
case ScenarioDefinitions.FUNC_END_APP:
finish();
break;
default:
break;
}
}
/**
* カメラ連携の結果を受け取るためのBroadcastレシーバー クラス
* それぞれの結果毎に処理を行う.
*/
private class CameraResultReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
String action = intent.getAction();
Log.v(TAG, "CameraResultReceiver#onReceive() : " + action);
switch (action) {
case ACTION_RESULT_FACE_DETECTION:
int result = intent.getIntExtra(FaceDetectionUtil.EXTRA_RESULT_CODE, FaceDetectionUtil.RESULT_CANCELED);
break;
case ACTION_RESULT_TAKE_PICTURE:
result = intent.getIntExtra(ShootMediaUtil.EXTRA_RESULT_CODE, ShootMediaUtil.RESULT_CANCELED);
if(result == ShootMediaUtil.RESULT_OK) {
// 1. 撮影画像ファイルパス取得
final String path = intent.getStringExtra(ShootMediaUtil.EXTRA_PHOTO_TAKEN_PATH);
Log.v(TAG, "PICTURE_path : " + path);
Thread thread = new Thread(new Runnable() {public void run() {
try {
// 2. APIリクエスト、レスポンス取得
String res = (new GetAge()).inquireAge(path, getApplicationContext());
Log.v(TAG, "onExecCommand: RoBoHoN:" + res);
int ret = VoiceUIVariableUtil.setVariableData(mVoiceUIManager, ScenarioDefinitions.MEM_P_RES, res);
VoiceUIManagerUtil.stopSpeech();
// 3. RoBoHon 結果発話
if (mVoiceUIManager != null) {
VoiceUIVariableListHelper helper = new VoiceUIVariableListHelper().addAccost(ScenarioDefinitions.ACC_RES);
VoiceUIManagerUtil.updateAppInfo(mVoiceUIManager, helper.getVariableList(), true);
}
} catch (Exception e) {
Log.v(TAG, "onExecCommand: Exception" + e.getMessage());
};
}});
thread.start();}
}
break;
case ACTION_RESULT_REC_MOVIE:
result = intent.getIntExtra(ShootMediaUtil.EXTRA_RESULT_CODE, ShootMediaUtil.RESULT_CANCELED);
break;
default:
break;
}
}
}
- AWS Rekognition通信
package com.dev.zdev.rekog;
/**
* Created by zdev on 2017/12/10.
*/
import android.util.Log;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import com.amazonaws.auth.CognitoCachingCredentialsProvider;
import com.amazonaws.regions.Regions;
import com.amazonaws.services.rekognition.AmazonRekognitionClient;
import java.io.ByteArrayOutputStream;
import java.nio.ByteBuffer;
import java.util.List;
import com.amazonaws.services.rekognition.model.DetectFacesRequest;
import com.amazonaws.services.rekognition.model.DetectFacesResult;
import com.amazonaws.services.rekognition.model.FaceDetail;
import com.amazonaws.services.rekognition.model.AgeRange;
import com.amazonaws.services.rekognition.model.Image;
public class GetAge {
private static final String TAG = GetAge.class.getSimpleName();
private static int newWidth = 326;
private static int newHeight = 244;
private String resMsg = "ゼロさいからひゃくさいの間 ";
AmazonRekognitionClient amazonRekognitionClient = null;
private Bitmap resizeImag(String path){
return Bitmap.createScaledBitmap(BitmapFactory.decodeFile(path), newWidth, newHeight, true);
};
private void setAmazonRekognitionClient(Context appcontext){
// Amazon Cognito 認証情報プロバイダーを初期化します
CognitoCachingCredentialsProvider credentialsProvider = new CognitoCachingCredentialsProvider(
appcontext,
"us-east-1:XXXXXXXXXXXX", // ID プールの ID
Regions.US_EAST_1 // リージョン
);
this.amazonRekognitionClient = new AmazonRekognitionClient(credentialsProvider);
};
public synchronized String inquireAge(String path, Context appcontext) throws Exception {
try {
Bitmap img = resizeImag(path);
if (this.amazonRekognitionClient == null) {
setAmazonRekognitionClient(appcontext);
}
ByteBuffer imageBytes = null;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
img.compress(Bitmap.CompressFormat.JPEG, 100, baos);
imageBytes = ByteBuffer.wrap(baos.toByteArray());
DetectFacesRequest request = new DetectFacesRequest()
.withImage(new Image()
.withBytes(imageBytes))
.withAttributes("ALL");
DetectFacesResult result = amazonRekognitionClient.detectFaces(request);
List<FaceDetail> faceDetails = result.getFaceDetails();
Log.v(TAG, "inquireAge: " + faceDetails.toString());
for (FaceDetail face: faceDetails) {
if (request.getAttributes().contains("ALL")) {
AgeRange ageRange = face.getAgeRange();
Log.v(TAG, "inquireAge: " + ageRange.getLow().toString() + " and " + ageRange.getHigh().toString() + " years old.");
this.resMsg = ageRange.getLow().toString() + " さいから " + ageRange.getHigh().toString() + " さいの間 ";
} else { // non-default attributes have null values.
Log.v(TAG, "inquireAge: " + "Here's the default set of attributes:");
}
}
return this.resMsg;
} catch (Exception e) {
Log.v(TAG, "inquireAge: exception: " + e.toString());
return this.resMsg;
}
}
}
実行の様子と感想
年末も近いし、色々とひとが集まる機会に使えたらいいな、と、パーティアプリにしたく、実装しました。
(Microsoft「How-Old.net」が流行ったときのように、1~2回/人 試して場が沸いたら上出来!という)
家族で試したところ、下記のようになりました。
- 30代後半男性: 45 ~ 63 才 (!)の間
- 30代後半女性: 26 ~ 38 才の間
- 9才 … 6 ~ 13 才の間
- 4才 … 4 ~ 7 才の間、4 ~ 9 才の間
私(30代後半)は 「14 ~ 23 才の間」というスコアも叩き出せたので、家族が沸き「ロボホンがひいきしてる!(子供たちの声)」「なんか匙加減して実装してない?」など、”結果をロボホンが発声する”1 という文脈も楽しめました。
-
ロボホンSDK内規定(0201_SR01MW_Personality_and_Speech_Regulations_V01_00_01)には "ロボホンはユーザに対して誠実です。ユーザを裏切ることはありません(中略) 不確実な情報を話すときは、それとわかる言い回しをする(例:「雨になるよ」→「予報によると、雨になるみたいだよ」" があります。そのため、今回も結果通知の語尾に「~才にみえるよ」でなく「~才にみえるみたいだよ」とつけています。(また、同規定書には "主観を持たない"というくだり("ロボホンはロボットです 。ロボットは 、基本的に プログラムされたとおりに動くものです 。ロボホン自身の主観(好き嫌いや感想など ロボホン自身の主観(好き嫌いや感想など 、人によって感じ方が変わるもの 、人によって感じ方が変わるもの )は 持たないのが基本的考え方です 。")ともあります) ↩