はじめに
こんにちは。
セーフィー株式会社で画像認識エンジニアをしている柏木です。
こちらはセーフィー株式会社アドベントカレンダーの17日目の記事になります!
今回セーフィー社内で画像認識のコンペを行いました。
その内容についてまとめて紹介します!
事の発端
セーフィーでは現在開発中の解析プラットフォームというシステムがあります。作成したAIモデルをセーフィーのクラウド上で動作させ、カメラの映像を解析することができるサービスです。詳細はこちらの記事で紹介しているのでご覧ください。
解析プラットフォームを主に開発しているメンバーは、セーフィーのサーバーエンジニアになります。そのサーバーエンジニアから実際に自分たちでAIモデルを作成し、解析プラットフォーム上で動作させてみたいとのお話がありました。
そこで、画像認識エンジニアも協力しつつ、サーバーエンジニアの方々にモデルを開発してもらい、コンペ形式で性能を競うこととしました!
目的
- 弊社で開発の推論システムである解析プラットフォームを試す。
- 画像認識チーム以外のエンジニアに画像認識について触れてもらい知見を増やしてもらう。
- 画像認識チームが他部署に技術を教える経験を得る。
- 社内に画像分類のモデルの知見を増やす。
コンペ概要
コンペは画像認識の初心者でも比較的とっつきやすい画像分類のコンペとしました。
分類対象は弊社CTOの森本です。
セーフィー社内にはクラウドカメラが多数あります。そのため教師データが集めやすいです。また社内のカメラにすぐに適用させることができるため、動作確認がしやすいという利点もあります。
- 画像分類 (Image Classification)
- セーフィーCTO森本を画像分類で判定する。(森本か、そうでないかの2値分類)

画像分類モデルの調査
扱ってもらう画像分類モデルの調査は、画像認識エンジニアの方で行うことにしました。
要件としては以下のものを考えました。
- 使いやすいこと
画像認識以外のチームが使うため - モデルのサイズ
解析プラットフォームで簡易に動かすので小~中(20~50GFLOPS)くらいのものがよさそう - なるべく新しいもの?
後々社内に知見として残るため
画像分類のモデルの調査は以下の記事および表を参考にしました。
そして、実際に使ってもらうリポジトリを以下のものにしぼりました。
-
EfficientNet (2019)
Kaggle Notebookなので動作するまでの工程がわかりやすい。
https://www.kaggle.com/code/gpiosenka/yoga-f1-score-90 -
EfficientNetV2 (2021)
日本語の記事があるので使いやすそう 。
https://qiita.com/shimakon/items/13849d45ff93e7c99a20 -
ConvNeXt (CVPR2022)
公式リポジトリが充実してる。
https://github.com/facebookresearch/ConvNeXt
EfficientNetはやや古いですが、知名度が高くKaggle Notebookからの導入が比較的簡単そうなので選びました。そのほかはSOTAの中でも、リポジトリを見てみて、実際に使いやすそうなものを選んでいます。
学習データの収集
学習データは社内のクラウドカメラの映像から集めました。SafieViewerを使っています。
タイムラインからモーション検知で動いた箇所のみを閲覧することができ、ワンボタンで画像をキャプチャできるので、とても便利です。(唐突な宣伝)
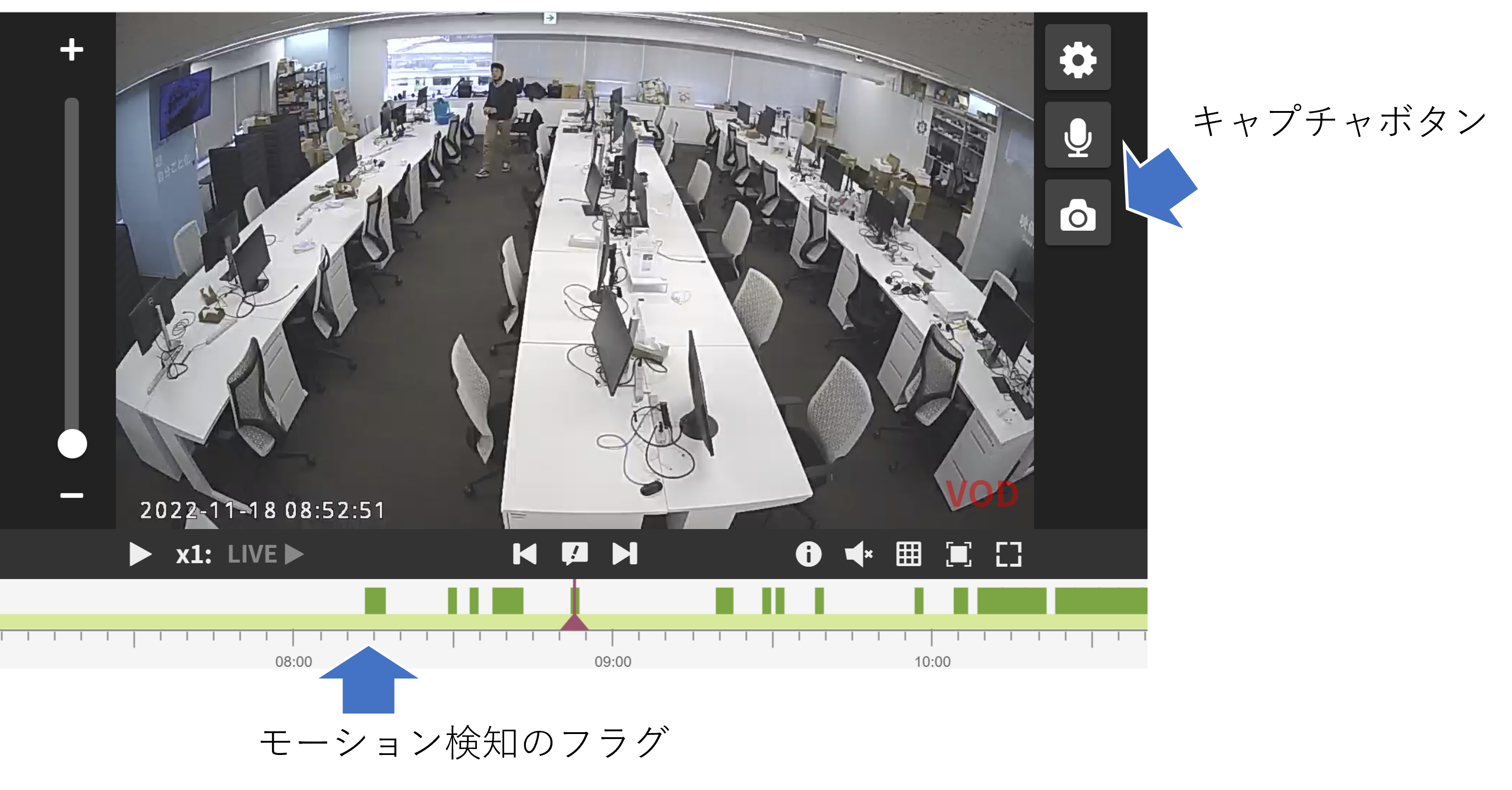
社内にある様々な画角のカメラから、森本が映っている画像、森本が映っていない画像を集め、学習データとしました。


最終的に収集した画像は403枚になりました。
学習の様子
学習の様子についてはサーバーチームの方に記事にしてもらったので、以下を参考にお願いします。
- EfficientNet
AIモデル作成は簡単ではなかった
評価データの収集
評価については私が会社の映像や、インタビュー映像などから収集しプライベートなデータセットとしました。
学習してもらっているメンバーには公開しないデータセットを利用することで、よりKaggleチックにやっています。内容としては森本の画像50枚、森本以外の画像50枚の100枚としました。
評価と問題発生
参加者から学習が完了したとの報告を受けたので、テストデータを使って評価しました。このとき、参加者の方々にはテストしやすいようなDocker環境を作ってもらっています。
そして実際に評価してみると、なんとaccuracyが0.5程度しかありませんでした…!
2値分類でaccuracyが0.5だと勘で言うのとほとんど変わりません…
それぞれ学習データのバリデーションだと0.9近く出ていたのになぜ…
改めてデータセットを見てみるとカメラの画角のバリエーションが多すぎることが原因のように感じました。
400枚のデータセットですが、設置しているカメラは様々で、森本の角度も様々です。



さすがに400枚程度の学習ではバリエーションが多すぎたように思います。
画像データとテストデータの変更
このままでは解析プラットフォームにデプロイしてもあまり使えそうもありません…。そこで学習およびテストのカメラを一つに絞ることにしました。こちらは冷蔵庫の上に設置してあるカメラです。また、人もかなり近くまで寄るので人物の分類もできそうです。


こちらの画像は600枚ほど収集しました。
評価結果
テストデータもこちらのカメラから80枚ほど収集し、テストしました(収集する日時を変えることで同じデータは入らないようにしています)。その結果、評価結果は以下のようになりました。
Efficientnet:
precision: 0.68, recall: 0.90
EfficientnetV2:
precision: 0.56, recall: 0.85
まだまだ精度向上できるところはあると思いますが、前回からはステップアップした結果となったと思います。
また、元画像認識チームのメンバーが既存の顔認識モデルを利用した方法で分類した結果、さらに良い精度で分類することができました!詳細はこちらをご覧ください!
【社内ハッカソン】 社内カメラでCTO検出機を作ってみた
終わりに
今回は画像認識のコンペを行いました。未経験の人にやってもらうということで、思ったように動かなかったり精度が出なかったりしましたが、面白い経験になったのではないかと思います。
このようにセーフィーではチーム外でも積極的に技術交流を行っております。興味がありましたら、ぜひ採用サイトへの応募お願いします!